
 développement back-end
C++
Différence entre la file d'attente de tableau et la file d'attente de liste chaînée
développement back-end
C++
Différence entre la file d'attente de tableau et la file d'attente de liste chaînée
Différence entre la file d'attente de tableau et la file d'attente de liste chaînée

Présentation
Une file d'attente est une structure de données linéaire qui insère et supprime des éléments de file d'attente dans un ordre spécifique. Nous pouvons implémenter des files d'attente en C++ en utilisant des tableaux et des listes chaînées. Les deux implémentations de files d'attente ont leurs propres avantages et utilisations. Dans ce didacticiel, nous ferons la différence entre les files d'attente basées sur des tableaux et les files d'attente basées sur des listes chaînées.
Qu'est-ce qu'une file d'attente ?
Une file d'attente est une série d'éléments qui utilisent le principe FIFO (premier entré, premier sorti) pour l'insertion et la suppression d'éléments. Les files d'attente en informatique sont similaires aux files d'attente dans la vie réelle, la première personne à entrer dans la file d'attente sera supprimée en premier.
Le processus de suppression des données de la file d'attente s'appelle deQueue. L'opération d'ajout de données à la file d'attente est appelée enQueue.
La file d'attente comporte deux points -
After - Les éléments de la file d'attente sont insérés à partir d'ici.
Front - L'élément dans la file d'attente sera supprimé d'ici.
Nous pouvons implémenter des files d'attente de deux manières -
File d'attente basée sur un tableau
File d'attente basée sur une liste ou file d'attente de liste chaînée
File d'attente basée sur un tableau
La file d'attente implémentée à l'aide de tableaux est appelée file d'attente basée sur un tableau. Il utilise deux pointeurs : Front et Rear, qui représentent respectivement le point de suppression et le point d'insertion dans la file d'attente.
Dans cette implémentation, la taille du tableau est prédéfinie avant d'insérer les données. Il s'agit du moyen le plus simple d'insérer et de supprimer des données de file d'attente.

File d'attente basée sur une liste
Dans la file d'attente basée sur une liste ou la file d'attente basée sur une liste chaînée, la liste chaînée est utilisée pour l'implémentation de la file d'attente. Chaque nœud de file d'attente se compose de deux parties : une partie est utilisée pour stocker les données et l'autre partie est la partie liaison ou la partie mémoire.
Chaque élément de file d'attente est connecté à la mémoire de l'élément de file d'attente suivant. Il y a deux pointeurs dans une file d'attente basée sur une liste -
Pointeur précédent - Représente la mémoire du dernier élément de la file d'attente.
Pointeur arrière - mémoire représentant le premier élément de la file d'attente.
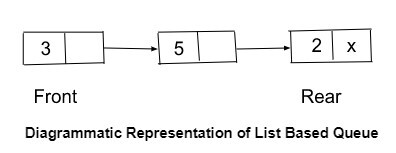
La différence entre la file d'attente de tableau et la file d'attente de liste chaînée
S.No | est : Numéro de série |
File d'attente basée sur un tableau |
File d'attente basée sur une liste chaînée |
|
|---|---|---|---|---|
1 |
Complexité |
Il est facile à mettre en œuvre et à effectuer des opérations. |
Ce n’est pas facile à mettre en œuvre. |
|
2 |
Processus de recherche |
Cela permet de rechercher facilement et rapidement. |
Recherche lente et difficile. |
|
3 |
Taille de la file d'attente |
Définissez la taille de la file d'attente au moment de l'initialisation. |
Pas besoin de définir la taille de la file d'attente lors de l'initialisation de la file d'attente. |
|
4 |
Opérations d'insertion et de suppression |
Il est difficile d'insérer des données au début, mais il est facile d'insérer des données à la fin de la file d'attente. |
Il permet une insertion simple de données aux deux extrémités de la file d'attente. |
|
5 |
Accès aux données |
Accès aléatoire aux données. |
Il fournit un accès séquentiel aux éléments de la file d'attente. |
|
6 |
Ajustement de la taille de la file d'attente |
Modifier la taille de la file d’attente est difficile. |
Ajuster la taille de la file d’attente est facile. |
|
7 |
Utilisation de la mémoire |
Il consomme moins de mémoire. |
Cela consomme plus de mémoire. |
|
8 |
Avantages |
|
|
|
9 |
Inconvénients |
|
|
Utilisez des files d'attente basées sur des tableaux et des files d'attente basées sur des listes chaînées
Si votre file d'attente a une taille fixe et qu'il n'est pas nécessaire de modifier la taille de la file d'attente, vous pouvez implémenter la file d'attente à l'aide d'un tableau. Les files d'attente basées sur des tableaux sont également utiles lorsque la recherche est rapide et consomme moins de mémoire.
L'implémentation de file d'attente basée sur une liste chaînée est très utile lorsque la taille de la file d'attente est dynamique et que les éléments de la file d'attente sont insérés et supprimés plusieurs fois. Bien qu'il consomme plus de mémoire, il convient aux applications à grande échelle
Conclusion
L'utilisation de files d'attente basées sur des tableaux et de files d'attente basées sur des listes chaînées dépend des exigences. Dans les applications à grande échelle, les files d'attente basées sur des tableaux échouent et des files d'attente de liste chaînée sont utilisées à la place.
Les files d'attente basées sur des tableaux utilisent moins de mémoire mais gaspillent beaucoup de mémoire car après l'insertion d'éléments dans le backend, il reste de la mémoire inutilisée avant le premier élément.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 La différence entre char et wchar_t dans le langage C
Apr 03, 2025 pm 03:09 PM
La différence entre char et wchar_t dans le langage C
Apr 03, 2025 pm 03:09 PM
Dans le langage C, la principale différence entre Char et WCHAR_T est le codage des caractères: Char utilise ASCII ou étend ASCII, WCHAR_T utilise Unicode; Char prend 1 à 2 octets, WCHAR_T occupe 2-4 octets; Char convient au texte anglais, WCHAR_T convient au texte multilingue; Le char est largement pris en charge, WCHAR_T dépend de la prise en charge du compilateur et du système d'exploitation Unicode; Le char est limité dans la gamme de caractères, WCHAR_T a une gamme de caractères plus grande et des fonctions spéciales sont utilisées pour les opérations arithmétiques.
 La différence entre le multithreading et le C # asynchrone
Apr 03, 2025 pm 02:57 PM
La différence entre le multithreading et le C # asynchrone
Apr 03, 2025 pm 02:57 PM
La différence entre le multithreading et l'asynchrone est que le multithreading exécute plusieurs threads en même temps, tandis que les opérations effectuent de manière asynchrone sans bloquer le thread actuel. Le multithreading est utilisé pour les tâches à forte intensité de calcul, tandis que de manière asynchrone est utilisée pour l'interaction utilisateur. L'avantage du multi-threading est d'améliorer les performances informatiques, tandis que l'avantage des asynchrones est de ne pas bloquer les threads d'interface utilisateur. Le choix du multithreading ou asynchrone dépend de la nature de la tâche: les tâches à forte intensité de calcul utilisent le multithreading, les tâches qui interagissent avec les ressources externes et doivent maintenir la réactivité de l'interface utilisateur à utiliser asynchrone.
 Quelle est la fonction de la somme du langage C?
Apr 03, 2025 pm 02:21 PM
Quelle est la fonction de la somme du langage C?
Apr 03, 2025 pm 02:21 PM
Il n'y a pas de fonction de somme intégrée dans le langage C, il doit donc être écrit par vous-même. La somme peut être obtenue en traversant le tableau et en accumulant des éléments: Version de boucle: la somme est calculée à l'aide de la longueur de boucle et du tableau. Version du pointeur: Utilisez des pointeurs pour pointer des éléments de tableau, et un résumé efficace est réalisé grâce à des pointeurs d'auto-incitation. Allouer dynamiquement la version du tableau: allouer dynamiquement les tableaux et gérer la mémoire vous-même, en veillant à ce que la mémoire allouée soit libérée pour empêcher les fuites de mémoire.
 Quelles sont les exigences de base pour les fonctions de langue C
Apr 03, 2025 pm 10:06 PM
Quelles sont les exigences de base pour les fonctions de langue C
Apr 03, 2025 pm 10:06 PM
Les fonctions de langue C sont la base de la modularisation du code et de la construction de programmes. Ils se composent de déclarations (en-têtes de fonction) et de définitions (corps de fonction). Le langage C utilise des valeurs pour transmettre les paramètres par défaut, mais les variables externes peuvent également être modifiées à l'aide d'adresse Pass. Les fonctions peuvent avoir ou ne pas avoir de valeur de retour et le type de valeur de retour doit être cohérent avec la déclaration. La dénomination de la fonction doit être claire et facile à comprendre, en utilisant un chameau ou une nomenclature de soulignement. Suivez le principe de responsabilité unique et gardez la simplicité de la fonction pour améliorer la maintenabilité et la lisibilité.
 Quelle est la différence entre char et char non signé
Apr 03, 2025 pm 03:36 PM
Quelle est la différence entre char et char non signé
Apr 03, 2025 pm 03:36 PM
Le char et le char non signé sont deux types de données qui stockent les données des caractères. La principale différence est le moyen de gérer les nombres négatifs et positifs: plage de valeur: char signé (-128 à 127), et Char non signé Unsigned (0 à 255). Traitement du nombre négatif: le char peut stocker des nombres négatifs, le char non signé ne peut pas. Mode bit: Char le bit le plus élevé représente le symbole, un bit non signé non signé. Opérations arithmétiques: le char et le char non signé sont signés et non signés, et leurs opérations arithmétiques sont différentes. Compatibilité: char et char non signé
 La différence entre H5 et mini-programmes et applications
Apr 06, 2025 am 10:42 AM
La différence entre H5 et mini-programmes et applications
Apr 06, 2025 am 10:42 AM
H5. La principale différence entre les mini programmes et l'application est: Architecture technique: H5 est basé sur la technologie Web, et les mini-programmes et l'application sont des applications indépendantes. Expérience et fonctions: H5 est légère et facile à utiliser, avec des fonctions limitées; Les mini-programmes sont légers et ont une bonne interactivité; Les applications sont puissantes et ont une expérience fluide. Compatibilité: H5 est compatible multiplateforme, les applets et les applications sont limités par la plate-forme. Coût de développement: H5 a un faible coût de développement, des mini-programmes moyens et une application la plus élevée. Scénarios applicables: H5 convient à l'affichage d'informations, les applets conviennent aux applications légères et les applications conviennent aux fonctions complexes.
 Quelles sont les différences et les connexions entre C et C #?
Apr 03, 2025 pm 10:36 PM
Quelles sont les différences et les connexions entre C et C #?
Apr 03, 2025 pm 10:36 PM
Bien que C et C # aient des similitudes, ils sont complètement différents: C est une gestion manuelle de la mémoire manuelle et un langage dépendant de la plate-forme utilisé pour la programmation système; C # est un langage orienté objet, des ordures et un langage indépendant de la plate-forme utilisé pour le bureau, l'application Web et le développement de jeux.
 Comment utiliser XPath pour rechercher à partir d'un nœud DOM spécifié en JavaScript?
Apr 04, 2025 pm 11:15 PM
Comment utiliser XPath pour rechercher à partir d'un nœud DOM spécifié en JavaScript?
Apr 04, 2025 pm 11:15 PM
Explication détaillée de la méthode de recherche XPATH sous les nœuds DOM en JavaScript, nous devons souvent trouver des nœuds spécifiques de l'arbre Dom basé sur les expressions XPath. Si vous avez besoin de ...
