

Alibaba a open source un nouveau grand modèle, ce qui est très excitant~
Après Tongyi Qianwen-7B(Qwen-7B), Alibaba Cloud a lancé modèle de langage visuel à grande échelle Qwen-VL, et ce sera open source directement dès sa mise en ligne.

Qwen-VL est un grand modèle multimodal basé sur Tongyi Qianwen-7B. Plus précisément, il prend en charge plusieurs entrées telles que des images, du texte et des cadres de détection, et peut non seulement produire du texte, mais également des cadres de détection. sortie
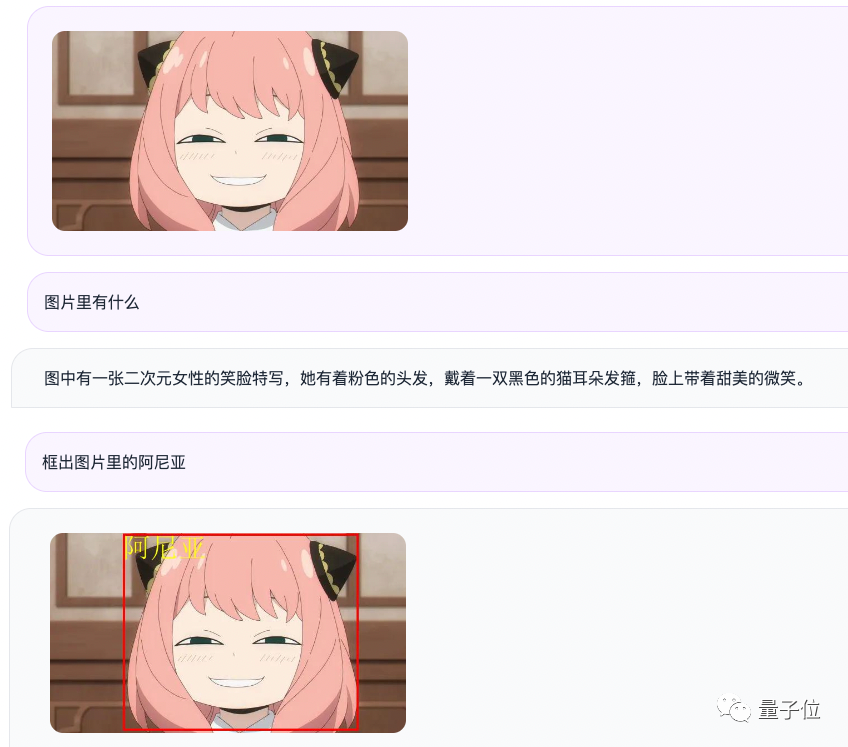
Par exemple, nous saisissons une image d'Aniya sous forme de questions et de réponses, Qwen-VL-Chat peut résumer le contenu de l'image et localiser avec précision Aniya dans l'image
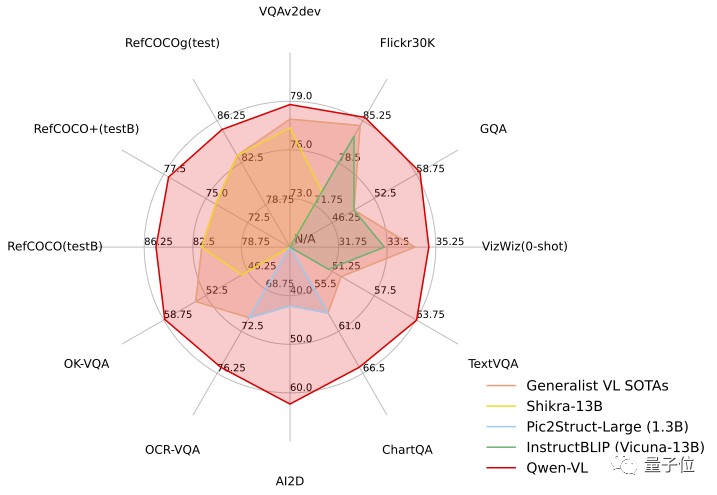
Dans la tâche de test, Qwen-VL a démontré la force du "Hexagonal Warrior", se classant premier dans l'évaluation standard anglaise des quatre grandes catégories de tâches multimodales (Zero-shot Caption/VQA/DocVQA/Grounding).
Dès que la nouvelle de l'open source est sortie, elle a immédiatement attiré l'attention du plus grand nombre

Jetons un coup d'œil aux performances spécifiques !
Tout d'abord, jetons un coup d'œil global aux caractéristiques des modèles de la série Qwen-VL :
Par exemple, un ami étranger ne comprend pas Lorsque vous allez à l'hôpital voir un médecin en chinois et que vous êtes confus par la carte de navigation et que vous ne savez pas comment vous rendre au service correspondant, vous pouvez directement donner les photos et des questions à Qwen-VL et laissez-le agir comme un traducteur basé sur les informations de l'image
 Entrez à nouveau la saisie multi-images Et test de comparaison
Entrez à nouveau la saisie multi-images Et test de comparaison
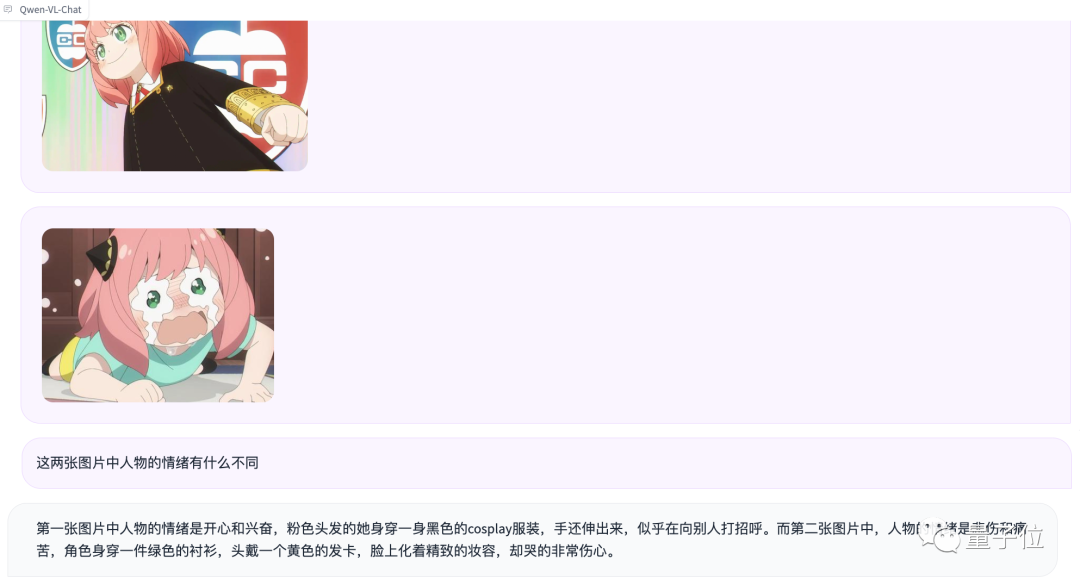 Bien qu'Aniya n'ait pas été reconnue, le jugement émotionnel était en effet assez précis (tête de chien manuelle)
Bien qu'Aniya n'ait pas été reconnue, le jugement émotionnel était en effet assez précis (tête de chien manuelle)
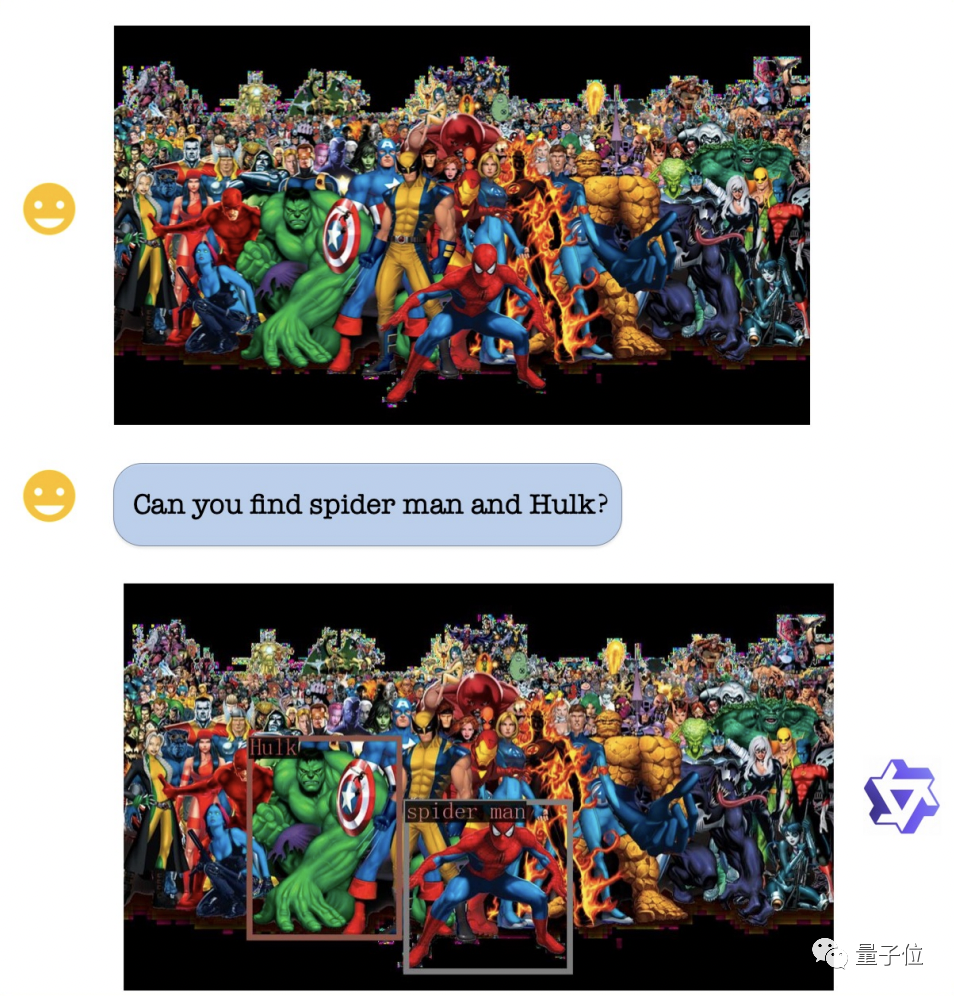
En termes de capacité de positionnement visuel, même si l'image est très complexe et qu'il y a de nombreux personnages, Qwen-VL peut toujours fonctionner selon les exigences Identifier avec précision Hulk et Spider-Man
 Qwen-VL utilise Qwen-7B comme modèle de langage de base dans les détails techniques, et en introduisant l'encodeur visuel ViT et l'adaptateur de langage visuel sensible à la position, le modèle peut prendre en charge l'entrée de signal visuel
Qwen-VL utilise Qwen-7B comme modèle de langage de base dans les détails techniques, et en introduisant l'encodeur visuel ViT et l'adaptateur de langage visuel sensible à la position, le modèle peut prendre en charge l'entrée de signal visuel
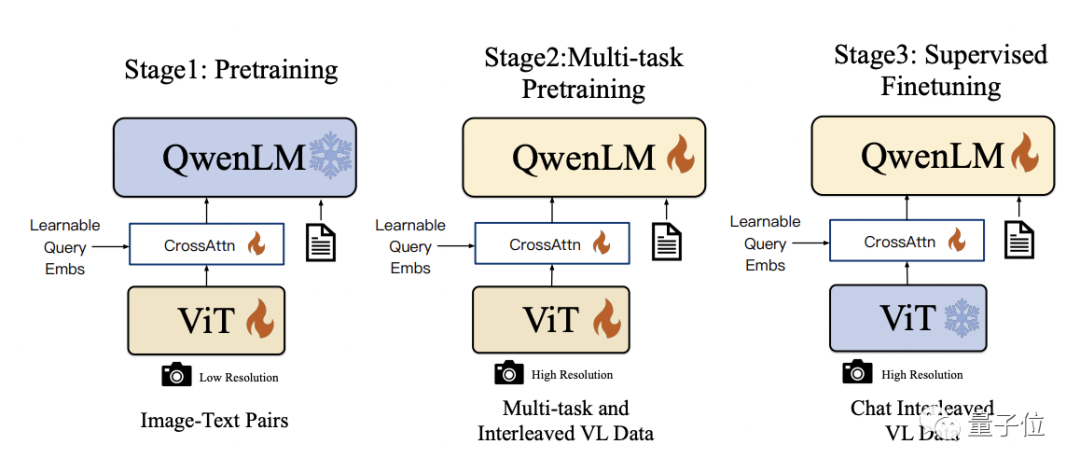
Le processus de formation spécifique est divisé en trois étapes :
Dans l'évaluation standard en anglais de Qwen-VL, les chercheurs ont testé quatre grandes catégories de tâches multimodales (Zero-shot Caption/VQA/DocVQA/Grounding)
Selon les résultats, Qwen-VL Le meilleur les résultats ont été obtenus en comparant avec un LVLM open source de même taille
De plus, les chercheurs ont construit un ensemble de tests TouchStone basé sur le mécanisme de notation GPT-4.


Qwen-VL-Chat a atteint la technologie de pointe (SOTA) dans ce test comparatif
Si Qwen-VL vous intéresse, vous pouvez retrouver la démo sur la communauté magique et huggingface Venez l'essayer directement. Le lien est fourni à la fin de l'article
Qwen-VL soutient les chercheurs et les développeurs pour le développement secondaire et permet une utilisation commerciale. Mais il convient de noter que si vous souhaitez l'utiliser commercialement, vous devez d'abord remplir le formulaire de demande de questionnaire
Lien du projet : https://modelscope.cn/models/qwen/Qwen-VL/summary
https://modelscope .cn/models/qwen/Qwen-VL-Chat/summary
https://huggingface.co/Qwen/Qwen-VL
https://huggingface.co/Qwen/Qwen -VL-Chat
https://github.com/QwenLM/Qwen-VL
Veuillez cliquer sur le lien suivant pour consulter l'article : https://arxiv.org/abs/2308.12966
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment résoudre le problème des caractères tronqués lors de l'ouverture d'une page Web
Comment résoudre le problème des caractères tronqués lors de l'ouverture d'une page Web
 Quels sont les types de trafic ?
Quels sont les types de trafic ?
 Comment passer un appel sans afficher votre numéro
Comment passer un appel sans afficher votre numéro
 Que signifie DHCP ?
Que signifie DHCP ?
 Comment déclencher un événement de pression de touche
Comment déclencher un événement de pression de touche
 gt540
gt540
 Les étincelles Douyin peuvent-elles être rallumées si elles sont éteintes depuis plus de trois jours ?
Les étincelles Douyin peuvent-elles être rallumées si elles sont éteintes depuis plus de trois jours ?
 Comment se connecter à la base de données en utilisant VB
Comment se connecter à la base de données en utilisant VB
 Logiciel d'évaluation de serveur
Logiciel d'évaluation de serveur








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



