
 Périphériques technologiques
IA
Utilisez BigDL-LLM pour accélérer instantanément des dizaines de milliards d'inférences de paramètres LLM
Périphériques technologiques
IA
Utilisez BigDL-LLM pour accélérer instantanément des dizaines de milliards d'inférences de paramètres LLM
Utilisez BigDL-LLM pour accélérer instantanément des dizaines de milliards d'inférences de paramètres LLM

Nous entrons dans une nouvelle ère d'IA pilotée par Large Language Model (LLM). LLM joue un rôle de plus en plus important dans diverses applications telles que le service client, les assistants virtuels, la création de contenu, l'aide à la programmation, etc.
Cependant, à mesure que l'échelle du LLM continue de croître, la consommation de ressources nécessaire à l'exécution de grands modèles augmente également, ce qui rend son fonctionnement de plus en plus lent, ce qui pose des défis considérables aux développeurs d'applications d'IA.
À cette fin, Intel a récemment lancé une bibliothèque open source de grands modèles appelée BigDL-LLM[1], qui peut aider les développeurs et les chercheurs en IA à accélérer l'optimisation des grands modèles de langage sur la plate-forme Intel® et à améliorer L'expérience de l'utilisation de grands modèles de langage sur la plateforme Intel ® .

Ce qui suit montre le modèle de langage large de 33 milliards de paramètres Vicuna-33b-v1.3[2] qui est accéléré à l'aide de BigDL-LLM sur une machine équipée d'Intel® Xeon® Platinum 8468. Le processeur exécute les effets en temps réel sur le serveur.
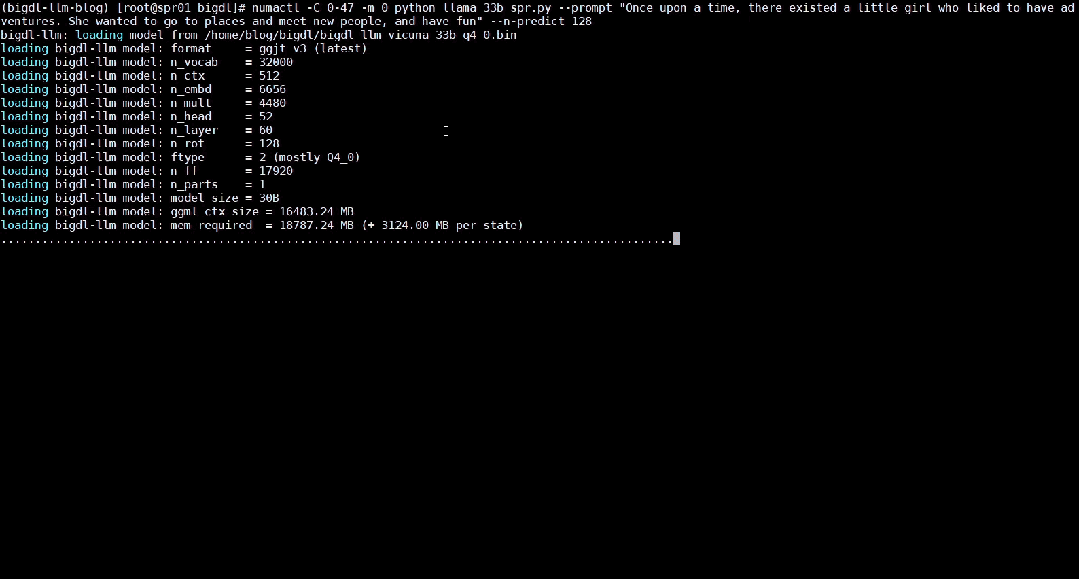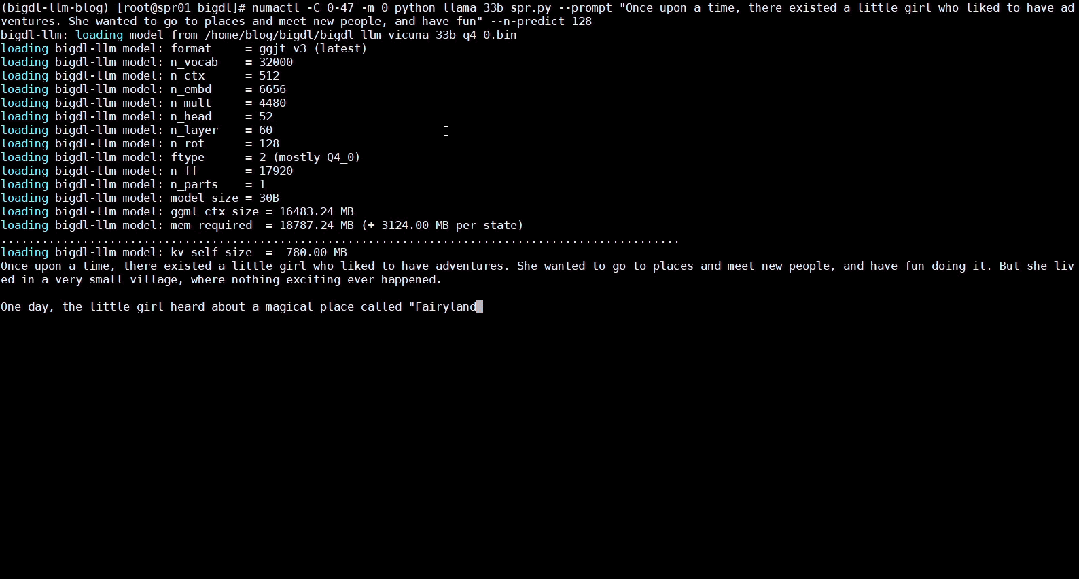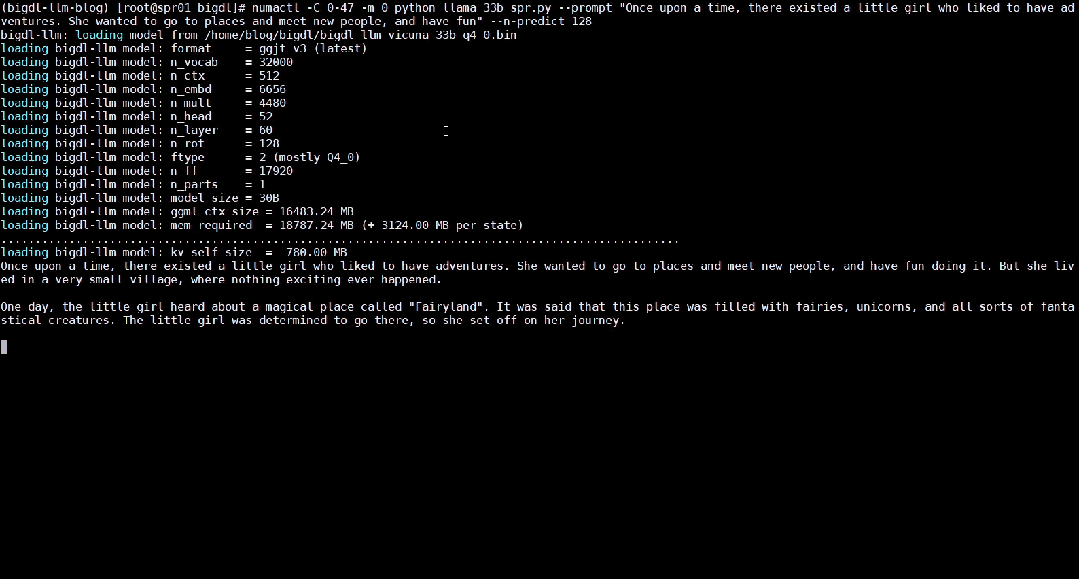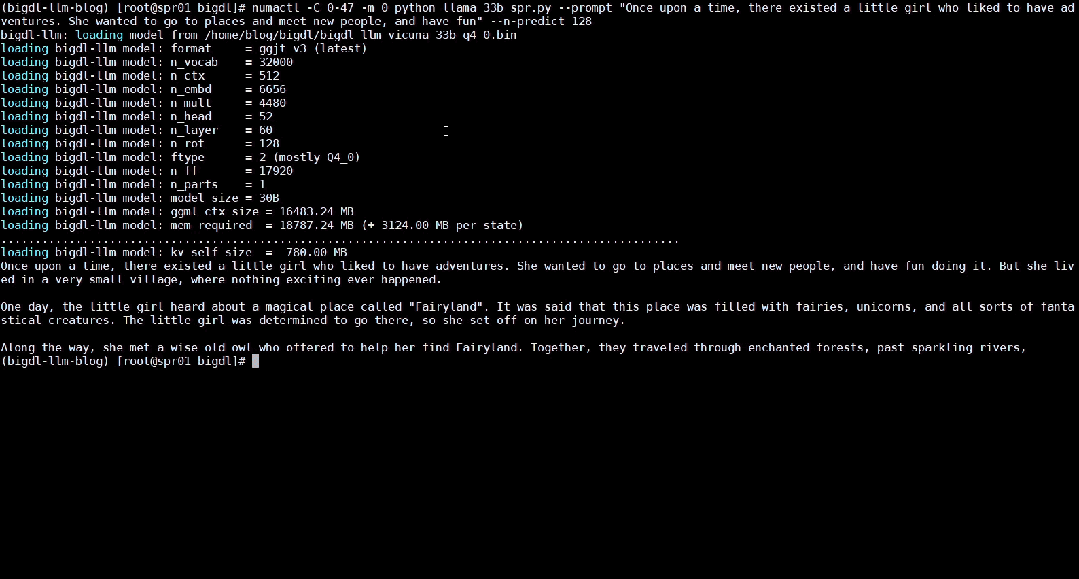
△Vitesse réelle d'exécution d'un grand modèle de langage de 33 milliards de paramètres sur un serveur équipé d'un processeur Intel® Xeon® Platinum 8468 (enregistrement d'écran en temps réel)
BigDL-LLM : Intel® Bibliothèque d'accélération de grands modèles de langage open source sur la plate-forme
BigDL-LLM est une bibliothèque open source axée sur l'optimisation et l'accélération de grands modèles de langage. Elle fait partie de BigDL et est publiée sous la licence Apache 2.0
Elle fournit une variété de modèles de langage faibles. niveau d'optimisation de précision (telle que INT4/INT5/INT8), et peut utiliser une variété de technologies d'accélération matérielle intégrées au processeur Intel® (AVX/VNNI/AMX, etc.) et la dernière optimisation logicielle pour permettre de grands modèles de langage sur Intel® Obtenez une optimisation plus efficace et un fonctionnement plus rapide sur la plate-forme.
Une caractéristique importante de BigDL-LLM est que pour les modèles basés sur l'API Hugging Face Transformers, il vous suffit de modifier une ligne de code pour accélérer le modèle. En théorie, il peut prendre en charge l'exécution de n'importe quelModèle Transformers, ce qui est utile pour ceux qui connaissent Transformers. Les développeurs d'API sont très sympathiques.
En plus de l'API Transformers, de nombreuses personnes utilisent également LangChain pour développer de grandes applications de modèle de langage.
À cette fin, BigDL-LLM fournit également une intégration LangChain facile à utiliser[3], permettant aux développeurs d'utiliser facilement BigDL-LLM pour développer de nouvelles applications ou migrer des applications existantes basées sur l'API Transformers ou l'API LangChain.
De plus, pour les grands modèles de langage PyTorch généraux (modèles qui n'utilisent pas l'API Transformer ou LangChain), vous pouvez également utiliser l'accélération en un clic de l'API BigDL-LLM optimise_model pour améliorer les performances. Pour plus de détails, veuillez vous référer au README GitHub[4] et à la documentation officielle[5].
BigDL-LLM fournit également un grand nombre d'échantillons d'accélération LLM open source couramment utilisés (par exemple, des échantillons utilisant l'API Transformers[6] et des échantillons utilisant l'API LangChain[7], ainsi que des didacticiels (y compris la prise en charge des notebooks Jupyter) [8], pratique pour les développeurs qui souhaitent démarrer et l'essayer rapidement
Installation et utilisation : processus d'installation simple et interface API facile à utiliser
Il est très pratique d'installer BigDL-LLM, exécutez simplement ce qui suit commande :
pip install --pre --upgrade bigdl-llm[all]
△Si le code n'est pas entièrement affiché, veuillez glisser vers la gauche ou la droite
Il est également très simple d'utiliser BigDL-LLM pour accélérer de grands modèles (ici nous utilisons uniquement l'API de style Transformers à titre d'exemple)
Utilisez l'API de style BigDL-LLM Transformer. Pour accélérer le modèle, il vous suffit de modifier la partie de chargement du modèle. Le processus d'utilisation ultérieur est complètement le même que celui des Transformers natifs. L'utilisation de l'API BigDL-LLM est presque la même que celle de l'API Transformers - l'utilisateur n'a qu'à modifier l'importation et à la définir dans le paramètre from_pretrained
load_in_4bit=True BigDL-LLM effectuera un low-4 bits. quantification de précision pendant le processus de chargement du modèle et utilisation de diverses technologies d'accélération logicielle et matérielle pour l'optimisation lors du processus d'inférence ultérieur
#Load Hugging Face Transformers model with INT4 optimizationsfrom bigdl.llm. transformers import AutoModelForCausalLMmodel = AutoModelForCausalLM.from_pretrained('/path/to/model/', load_in_4bit=True)△ Si le code n'est pas entièrement affiché, veuillez glisser vers la gauche ou la droite 下文将以 LLM 常见应用场景“语音助手”为例,展示采用 BigDL-LLM 快速实现 LLM 应用的案例。通常情况下,语音助手应用的工作流程分为以下两个部分: 以下是本文使用 BigDL-LLM 和 LangChain[11] 来搭建语音助手应用的过程: 在语音识别阶段:第一步,加载预处理器 processor 和语音识别模型 recog_model。本示例中使用的识别模型 Whisper 是一个 Transformers 模型。 只需使用 BigDL-LLM 中的 AutoModelForSpeechSeq2Seq 并设置参数 load_in_4bit=True,就能够以 INT4 精度加载并加速这一模型,从而显著缩短模型推理用时。 △若代码显示不全,请左右滑动 第二步,进行语音识别。首先使用处理器从输入语音中提取输入特征,然后使用识别模型预测 token,并再次使用处理器将 token 解码为自然语言文本。 △若代码显示不全,请左右滑动 在文本生成阶段,首先使用 BigDL-LLM 的 TransformersLLM API 创建一个 LangChain 语言模型(TransformersLLM 是在 BigDL-LLM 中定义的语言链 LLM 集成)。 可以使用这个 API 来加载 Hugging Face Transformers 的任何模型 △若代码显示不全,请左右滑动 然后,创建一个正常的对话链 LLMChain,并将已经创建的 llm 设置为输入参数。 △若代码显示不全,请左右滑动 以下代码将使用一个链条来记录所有对话历史,并将其适当地格式化为大型语言模型的输入。这样,我们可以生成合适的回复。只需将识别模型生成的文本作为 "human_input" 输入即可。代码如下: △若代码显示不全,请左右滑动 最后,将语音识别和文本生成步骤放入循环中,即可在多轮对话中与该“语音助手”交谈。您可访问底部 [12] 链接,查看完整的示例代码,并使用自己的电脑进行尝试。快用 BigDL-LLM 来快速搭建自己的语音助手吧! 黄晟盛是英特尔公司的资深架构师,黄凯是英特尔公司的AI框架工程师,戴金权是英特尔院士、大数据技术全球CTO和BigDL项目的创始人,他们都从事着与大数据和AI相关的工作示例:快速实现一个基于大语言模型的语音助手应用
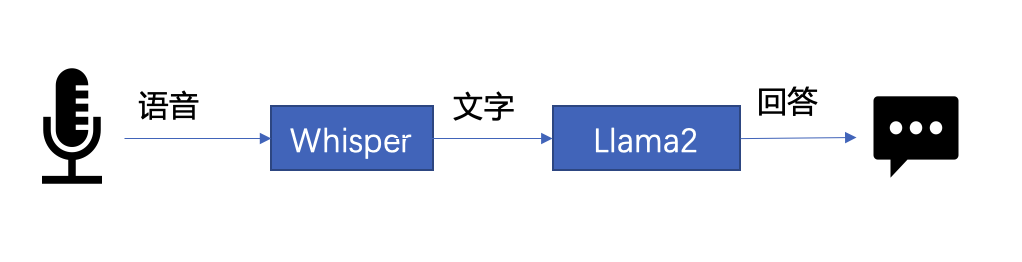
△图 1. 语音助手工作流程示意
#processor = WhisperProcessor .from_pretrained(recog_model_path)recog_model = AutoModelForSpeechSeq2Seq .from_pretrained(recog_model_path, load_in_4bit=True)
input_features = processor(frame_data,sampling_rate=audio.sample_rate,return_tensor=“pt”).input_featurespredicted_ids = recogn_model.generate(input_features, forced_decoder_ids=forced_decoder_ids)text = processor.batch_decode(predicted_ids, skip_special_tokens=True)[0]
llm = TransformersLLM . from_model_id(model_id=llm_model_path,model_kwargs={"temperature": 0, "max_length": args.max_length, "trust_remote_code": True},)# The following code is complete the same as the use-casevoiceassistant_chain = LLMChain(llm=llm, prompt=prompt,verbose=True,memory=ConversationBufferWindowMemory(k=2),)
response_text = voiceassistant_chain .predict(human_input=text, stop=”\n\n”)
作者简介
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Ce site a rapporté le 27 juin que Jianying est un logiciel de montage vidéo développé par FaceMeng Technology, une filiale de ByteDance. Il s'appuie sur la plateforme Douyin et produit essentiellement du contenu vidéo court pour les utilisateurs de la plateforme. Il est compatible avec iOS, Android et. Windows, MacOS et autres systèmes d'exploitation. Jianying a officiellement annoncé la mise à niveau de son système d'adhésion et a lancé un nouveau SVIP, qui comprend une variété de technologies noires d'IA, telles que la traduction intelligente, la mise en évidence intelligente, l'emballage intelligent, la synthèse humaine numérique, etc. En termes de prix, les frais mensuels pour le clipping SVIP sont de 79 yuans, les frais annuels sont de 599 yuans (attention sur ce site : équivalent à 49,9 yuans par mois), l'abonnement mensuel continu est de 59 yuans par mois et l'abonnement annuel continu est de 59 yuans par mois. est de 499 yuans par an (équivalent à 41,6 yuans par mois) . En outre, le responsable de Cut a également déclaré que afin d'améliorer l'expérience utilisateur, ceux qui se sont abonnés au VIP d'origine
 Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Améliorez la productivité, l’efficacité et la précision des développeurs en intégrant une génération et une mémoire sémantique améliorées par la récupération dans les assistants de codage IA. Traduit de EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, auteur JanakiramMSV. Bien que les assistants de programmation d'IA de base soient naturellement utiles, ils ne parviennent souvent pas à fournir les suggestions de code les plus pertinentes et les plus correctes, car ils s'appuient sur une compréhension générale du langage logiciel et des modèles d'écriture de logiciels les plus courants. Le code généré par ces assistants de codage est adapté à la résolution des problèmes qu’ils sont chargés de résoudre, mais n’est souvent pas conforme aux normes, conventions et styles de codage des équipes individuelles. Cela aboutit souvent à des suggestions qui doivent être modifiées ou affinées pour que le code soit accepté dans l'application.
 Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Pour en savoir plus sur l'AIGC, veuillez visiter : 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou est différent de la banque de questions traditionnelle que l'on peut voir partout sur Internet. nécessite de sortir des sentiers battus. Les grands modèles linguistiques (LLM) sont de plus en plus importants dans les domaines de la science des données, de l'intelligence artificielle générative (GenAI) et de l'intelligence artificielle. Ces algorithmes complexes améliorent les compétences humaines et stimulent l’efficacité et l’innovation dans de nombreux secteurs, devenant ainsi la clé permettant aux entreprises de rester compétitives. LLM a un large éventail d'applications. Il peut être utilisé dans des domaines tels que le traitement du langage naturel, la génération de texte, la reconnaissance vocale et les systèmes de recommandation. En apprenant de grandes quantités de données, LLM est capable de générer du texte
 Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Les grands modèles linguistiques (LLM) sont formés sur d'énormes bases de données textuelles, où ils acquièrent de grandes quantités de connaissances du monde réel. Ces connaissances sont intégrées à leurs paramètres et peuvent ensuite être utilisées en cas de besoin. La connaissance de ces modèles est « réifiée » en fin de formation. À la fin de la pré-formation, le modèle arrête effectivement d’apprendre. Alignez ou affinez le modèle pour apprendre à exploiter ces connaissances et répondre plus naturellement aux questions des utilisateurs. Mais parfois, la connaissance du modèle ne suffit pas, et bien que le modèle puisse accéder à du contenu externe via RAG, il est considéré comme bénéfique de l'adapter à de nouveaux domaines grâce à un réglage fin. Ce réglage fin est effectué à l'aide de la contribution d'annotateurs humains ou d'autres créations LLM, où le modèle rencontre des connaissances supplémentaires du monde réel et les intègre.
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
L'apprentissage automatique est une branche importante de l'intelligence artificielle qui donne aux ordinateurs la possibilité d'apprendre à partir de données et d'améliorer leurs capacités sans être explicitement programmés. L'apprentissage automatique a un large éventail d'applications dans divers domaines, de la reconnaissance d'images et du traitement du langage naturel aux systèmes de recommandation et à la détection des fraudes, et il change notre façon de vivre. Il existe de nombreuses méthodes et théories différentes dans le domaine de l'apprentissage automatique, parmi lesquelles les cinq méthodes les plus influentes sont appelées les « Cinq écoles d'apprentissage automatique ». Les cinq grandes écoles sont l’école symbolique, l’école connexionniste, l’école évolutionniste, l’école bayésienne et l’école analogique. 1. Le symbolisme, également connu sous le nom de symbolisme, met l'accent sur l'utilisation de symboles pour le raisonnement logique et l'expression des connaissances. Cette école de pensée estime que l'apprentissage est un processus de déduction inversée, à travers les connaissances existantes.
 Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Editeur | KX Dans le domaine de la recherche et du développement de médicaments, il est crucial de prédire avec précision et efficacité l'affinité de liaison des protéines et des ligands pour le criblage et l'optimisation des médicaments. Cependant, les études actuelles ne prennent pas en compte le rôle important des informations sur la surface moléculaire dans les interactions protéine-ligand. Sur cette base, des chercheurs de l'Université de Xiamen ont proposé un nouveau cadre d'extraction de caractéristiques multimodales (MFE), qui combine pour la première fois des informations sur la surface des protéines, la structure et la séquence 3D, et utilise un mécanisme d'attention croisée pour comparer différentes modalités. alignement. Les résultats expérimentaux démontrent que cette méthode atteint des performances de pointe dans la prédiction des affinités de liaison protéine-ligand. De plus, les études d’ablation démontrent l’efficacité et la nécessité des informations sur la surface des protéines et de l’alignement des caractéristiques multimodales dans ce cadre. Les recherches connexes commencent par "S
 Les startups d'IA ont collectivement transféré leurs emplois vers OpenAI, et l'équipe de sécurité s'est regroupée après le départ d'Ilya !
Jun 08, 2024 pm 01:00 PM
Les startups d'IA ont collectivement transféré leurs emplois vers OpenAI, et l'équipe de sécurité s'est regroupée après le départ d'Ilya !
Jun 08, 2024 pm 01:00 PM
" sept péchés capitaux" » Dissiper les rumeurs : selon des informations divulguées et des documents obtenus par Vox, la haute direction d'OpenAI, y compris Altman, était bien au courant de ces dispositions de récupération de capitaux propres et les a approuvées. De plus, OpenAI est confronté à un problème grave et urgent : la sécurité de l’IA. Les récents départs de cinq employés liés à la sécurité, dont deux de ses employés les plus en vue, et la dissolution de l'équipe « Super Alignment » ont une nouvelle fois mis les enjeux de sécurité d'OpenAI sur le devant de la scène. Le magazine Fortune a rapporté qu'OpenA
