
 Périphériques technologiques
IA
Baichuan Intelligent a sorti le grand modèle Baichuan2 : il est largement en avance sur Llama2, et les tranches d'entraînement sont également open source
Périphériques technologiques
IA
Baichuan Intelligent a sorti le grand modèle Baichuan2 : il est largement en avance sur Llama2, et les tranches d'entraînement sont également open source
Baichuan Intelligent a sorti le grand modèle Baichuan2 : il est largement en avance sur Llama2, et les tranches d'entraînement sont également open source

Lorsque l'industrie a été surprise que Baichuan Intelligent ait lancé un grand modèle en 28 jours en moyenne, l'entreprise ne s'est pas arrêtée.
Lors d'une conférence de presse dans l'après-midi du 6 septembre, Baichuan Intelligence a annoncé l'open source officiel du grand modèle Baichuan-2 affiné.
 Zhang Bo, académicien de l'Académie chinoise des sciences et doyen honoraire de l'Institut d'intelligence artificielle de l'Université Tsinghua, était présent à la conférence de presse.
Zhang Bo, académicien de l'Académie chinoise des sciences et doyen honoraire de l'Institut d'intelligence artificielle de l'Université Tsinghua, était présent à la conférence de presse.
Il s'agit d'une autre nouveauté de Baichuan depuis la sortie du grand modèle Baichuan-53B en août. Les modèles open source incluent Baichuan2-7B, Baichuan2-13B, Baichuan2-13B-Chat et leurs versions quantifiées 4 bits, et ils sont tous gratuits et disponibles dans le commerce.
En plus de la divulgation complète du modèle, Baichuan Intelligence a également cette fois ouvert Check Point pour la formation du modèle et a publié le rapport technique Baichuan 2, détaillant les détails de la formation du nouveau modèle. Wang Xiaochuan, fondateur et PDG de Baichuan Intelligence, a exprimé l'espoir que cette décision puisse aider les grands établissements universitaires modèles, les développeurs et les utilisateurs d'entreprises à acquérir une compréhension approfondie du processus de formation des grands modèles et à mieux promouvoir le développement technologique des grands modèles. recherche universitaire et communautés.
Lien original grand modèle Baichuan 2 : https://github.com/baichuan-inc/Baichuan2
Rapport technique : https://cdn.baichuan-ai.com/paper/Baichuan2-technical-report.pdf
Les modèles open source d'aujourd'hui sont de taille « plus petite » par rapport aux grands modèles. Parmi eux, Baichuan2-7B-Base et Baichuan2-13B-Base sont tous deux formés sur la base de 2 600 milliards de données multilingues de haute qualité, conservant la génération précédente de modèles open source. Sur la base de nombreuses fonctionnalités telles que de bonnes capacités de génération et de création, des capacités de dialogue multi-tours fluides et un faible seuil de déploiement, les deux modèles ont considérablement amélioré leurs capacités en mathématiques, codage, sécurité, raisonnement logique et compréhension sémantique.
"Pour faire simple, le modèle à 7 milliards de paramètres de Baichuan7B est déjà à égalité avec le modèle à 13 milliards de paramètres de LLaMA2 sur le benchmark anglais. On peut donc utiliser le petit pour faire le grand, le petit modèle est équivalent au capacité du grand modèle, et dans le même corps Le modèle quantitatif peut atteindre des performances plus élevées, dépassant largement les performances de LLaMA2", a déclaré Wang Xiaochuan.
Par rapport au modèle 13B de la génération précédente, Baichuan2-13B-Base a amélioré ses capacités mathématiques de 49 %, ses capacités de codage de 46 %, ses capacités de sécurité de 37 %, ses capacités de raisonnement logique de 25 % et ses capacités de compréhension sémantique de 15 % .
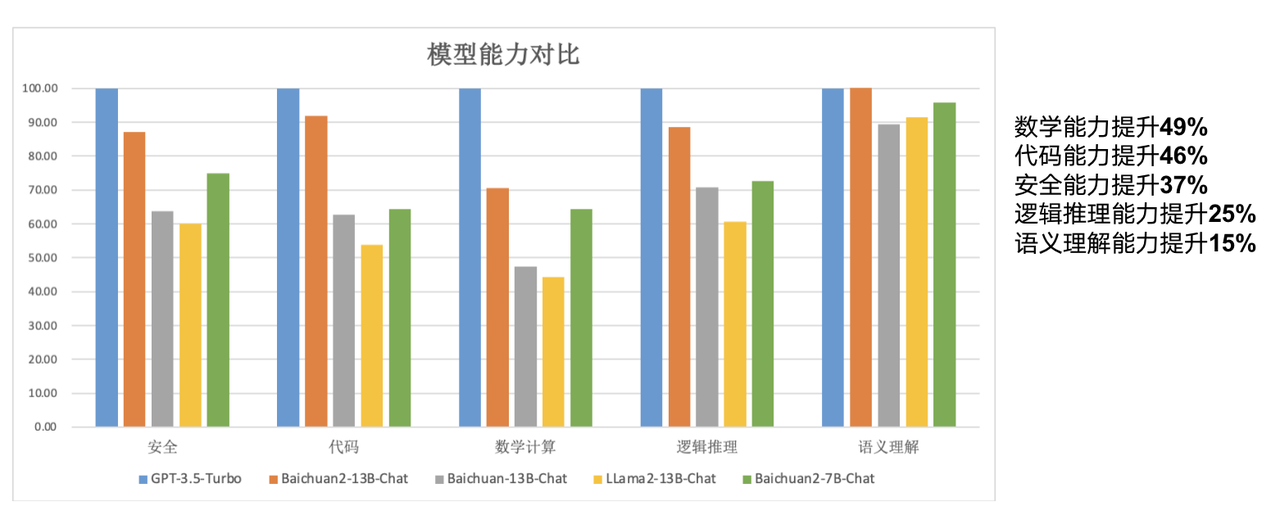
Selon les rapports, les chercheurs de Baichuan Intelligence ont procédé à de nombreuses optimisations, depuis l'acquisition de données jusqu'à la mise au point du nouveau modèle.
"Nous nous sommes appuyés sur plus d'expérience lors de recherches précédentes, avons effectué une évaluation de la qualité du contenu multi-granularité sur une grande quantité de données de formation de modèles, utilisé 260 millions de T de niveau de corpus pour former des modèles 7B et 13B et ajouté un support multilingue." Wang Xiaochuan a dit. "Nous pouvons atteindre une performance de formation de 180TFLOPS dans le cluster Qianka A800, et le taux d'utilisation de la machine dépasse 50 %. De plus, nous avons également réalisé de nombreux travaux d'alignement de sécurité
Les deux modèles open source cette fois sont largement." utilisé dans les principaux Les performances sur la liste d'évaluation sont excellentes. Dans plusieurs benchmarks d'évaluation faisant autorité tels que MMLU, CMMLU et GSM8K, il est largement en tête de LLaMA2. Par rapport à d'autres modèles avec le même nombre de paramètres, ses performances sont également très. impressionnant, et ses performances sont nettement meilleures que celles du produit concurrent LLaMA2 avec un modèle de même taille.
Ce qui mérite d'être mentionné, c'est que selon plusieurs critères d'évaluation en anglais faisant autorité tels que MMLU, Baichuan2-7B est à égalité avec LLaMA2 avec 13 milliards de paramètres sur les tâches anglaises traditionnelles avec 7 milliards de paramètres.
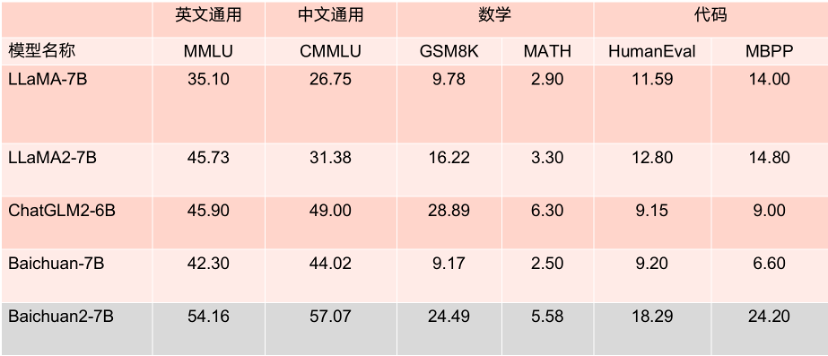
Résultats de référence du modèle de paramètres 7B.
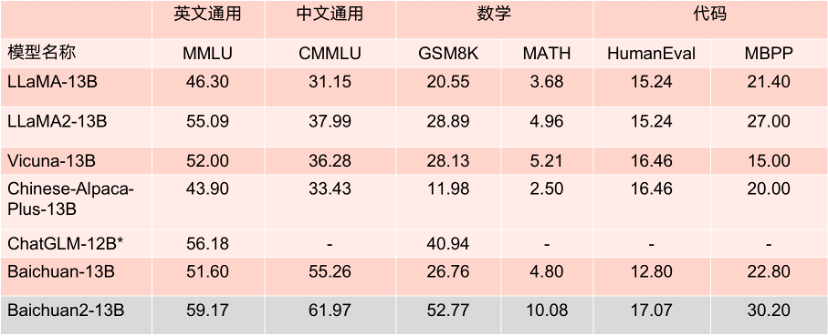
Résultats de référence du modèle de paramètres 13B.
Baichuan2-7B et Baichuan2-13B sont non seulement entièrement ouverts à la recherche universitaire, mais les développeurs peuvent également les utiliser gratuitement à des fins commerciales après avoir postulé par e-mail pour obtenir une licence commerciale officielle.
"En plus de la publication de modèles, nous espérons également fournir davantage de soutien au domaine universitaire", a déclaré Wang Xiaochuan. « En plus du rapport technique, nous avons également ouvert le modèle de paramètres de poids dans le processus de formation du grand modèle Baichuan2. Cela peut aider tout le monde à comprendre la pré-formation, ou à effectuer des réglages et des améliorations. C'est également la première fois en Chine. qu'une entreprise a ouvert un tel modèle.》
La formation de grands modèles comprend plusieurs étapes telles que l'acquisition de données massives de haute qualité, la formation stable de clusters de formation à grande échelle et le réglage de l'algorithme du modèle. Chaque lien nécessite l'investissement d'une grande quantité de talents, de puissance de calcul et d'autres ressources. Le coût élevé de la formation complète d'un modèle à partir de zéro a empêché la communauté universitaire de mener des recherches approfondies sur la formation de grands modèles.
Baichuan Intelligence a ouvert Check Ponit pour l'ensemble du processus de formation des modèles de 220B à 2640B. Ceci est d'une grande valeur pour les instituts de recherche scientifique qui souhaitent étudier le processus de formation des grands modèles, la formation continue des modèles et l'alignement des valeurs du modèle, etc., et peut promouvoir les progrès de la recherche scientifique sur les grands modèles nationaux.
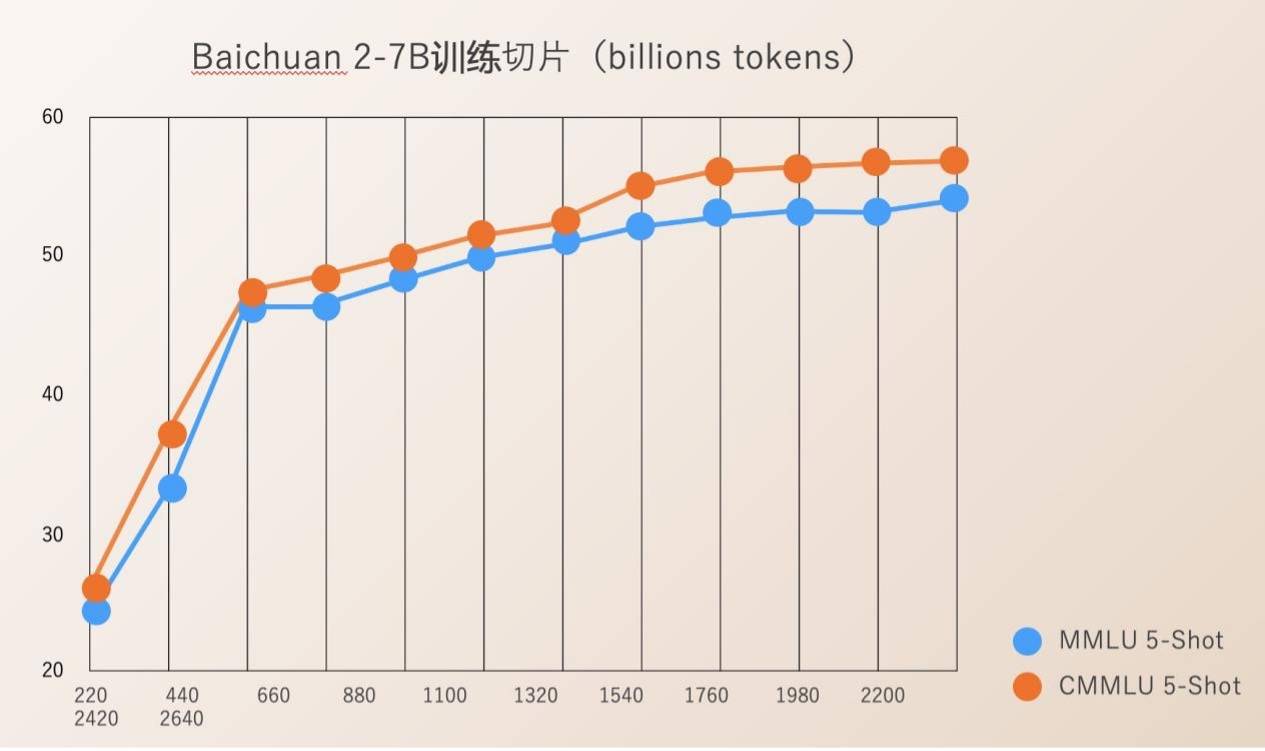
Auparavant, la plupart des modèles open source ne divulguaient que leurs propres poids de modèle et mentionnaient rarement les détails de formation. Les développeurs ne pouvaient effectuer que des ajustements limités, ce qui rendait difficile la conduite de recherches approfondies.
Le rapport technique Baichuan 2 publié par Baichuan Intelligence détaille l'ensemble du processus de formation Baichuan 2, y compris le traitement des données, l'optimisation de la structure du modèle, la loi d'échelle, les indicateurs de processus, etc.
Depuis sa création, Baichuan Intelligence considère la promotion de la prospérité du grand modèle écologique chinois grâce à l'open source comme une direction de développement importante de l'entreprise. Moins de quatre mois après sa création, la société a publié deux grands modèles chinois commerciaux gratuits et open source, Baichuan-7B et Baichuan-13B, ainsi qu'un grand modèle Baichuan-53B à recherche améliorée. évalué dans de nombreuses revues faisant autorité, il figure en bonne place sur la liste et a été téléchargé plus de 5 millions de fois.
La semaine dernière, le lancement du premier lot de photographies de service public à grande échelle a été une nouvelle importante dans le domaine technologique. Parmi les grandes entreprises modèles fondées cette année, Baichuan Intelligent est la seule à être enregistrée au titre des « Mesures provisoires pour la gestion des services d'intelligence artificielle générative » et à pouvoir officiellement fournir des services au public.
Avec des capacités de R&D et d'innovation de base sur les grands modèles de pointe, les deux grands modèles Baichuan 2 open source cette fois-ci ont reçu des réponses positives de la part des entreprises en amont et en aval, notamment Tencent Cloud, Alibaba Cloud, Volcano Ark, Huawei, MediaTek et bien d'autres. entreprises bien connues Tous ont participé à cette conférence et ont conclu une coopération avec Baichuan Intelligence. Selon les rapports, le nombre de téléchargements des grands modèles de Baichuan Intelligence sur Hugging Face a atteint 3,37 millions au cours du mois dernier.
Selon le plan précédent de Baichuan Intelligence, ils publieront cette année un grand modèle avec 100 milliards de paramètres et lanceront une « super application » au premier trimestre de l'année prochaine.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 L'auteur de ControlNet a encore un succès ! L'ensemble du processus de génération d'une peinture à partir d'une image, gagnant 1,4k étoiles en deux jours
Jul 17, 2024 am 01:56 AM
L'auteur de ControlNet a encore un succès ! L'ensemble du processus de génération d'une peinture à partir d'une image, gagnant 1,4k étoiles en deux jours
Jul 17, 2024 am 01:56 AM
Il s'agit également d'une vidéo Tusheng, mais PaintsUndo a emprunté une voie différente. L'auteur de ControlNet, LvminZhang, a recommencé à vivre ! Cette fois, je vise le domaine de la peinture. Le nouveau projet PaintsUndo a reçu 1,4kstar (toujours en hausse folle) peu de temps après son lancement. Adresse du projet : https://github.com/lllyasviel/Paints-UNDO Grâce à ce projet, l'utilisateur saisit une image statique et PaintsUndo peut automatiquement vous aider à générer une vidéo de l'ensemble du processus de peinture, du brouillon de ligne au suivi du produit fini. . Pendant le processus de dessin, les changements de lignes sont étonnants. Le résultat vidéo final est très similaire à l’image originale : jetons un coup d’œil à un dessin complet.
 En tête de liste des ingénieurs logiciels d'IA open source, la solution sans agent de l'UIUC résout facilement les problèmes de programmation réels du banc SWE.
Jul 17, 2024 pm 10:02 PM
En tête de liste des ingénieurs logiciels d'IA open source, la solution sans agent de l'UIUC résout facilement les problèmes de programmation réels du banc SWE.
Jul 17, 2024 pm 10:02 PM
La colonne AIxiv est une colonne où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com Les auteurs de cet article font tous partie de l'équipe de l'enseignant Zhang Lingming de l'Université de l'Illinois à Urbana-Champaign (UIUC), notamment : Steven Code repair ; doctorant en quatrième année, chercheur
 Travail posthume de l'équipe OpenAI Super Alignment : deux grands modèles jouent à un jeu et le résultat devient plus compréhensible
Jul 19, 2024 am 01:29 AM
Travail posthume de l'équipe OpenAI Super Alignment : deux grands modèles jouent à un jeu et le résultat devient plus compréhensible
Jul 19, 2024 am 01:29 AM
Si la réponse donnée par le modèle d’IA est incompréhensible du tout, oseriez-vous l’utiliser ? À mesure que les systèmes d’apprentissage automatique sont utilisés dans des domaines de plus en plus importants, il devient de plus en plus important de démontrer pourquoi nous pouvons faire confiance à leurs résultats, et quand ne pas leur faire confiance. Une façon possible de gagner confiance dans le résultat d'un système complexe est d'exiger que le système produise une interprétation de son résultat qui soit lisible par un humain ou un autre système de confiance, c'est-à-dire entièrement compréhensible au point que toute erreur possible puisse être trouvé. Par exemple, pour renforcer la confiance dans le système judiciaire, nous exigeons que les tribunaux fournissent des avis écrits clairs et lisibles qui expliquent et soutiennent leurs décisions. Pour les grands modèles de langage, nous pouvons également adopter une approche similaire. Cependant, lorsque vous adoptez cette approche, assurez-vous que le modèle de langage génère
 Les articles arXiv peuvent être publiés sous forme de 'barrage', la plateforme de discussion alphaXiv de Stanford est en ligne, LeCun l'aime
Aug 01, 2024 pm 05:18 PM
Les articles arXiv peuvent être publiés sous forme de 'barrage', la plateforme de discussion alphaXiv de Stanford est en ligne, LeCun l'aime
Aug 01, 2024 pm 05:18 PM
acclamations! Qu’est-ce que ça fait lorsqu’une discussion sur papier se résume à des mots ? Récemment, des étudiants de l'Université de Stanford ont créé alphaXiv, un forum de discussion ouvert pour les articles arXiv qui permet de publier des questions et des commentaires directement sur n'importe quel article arXiv. Lien du site Web : https://alphaxiv.org/ En fait, il n'est pas nécessaire de visiter spécifiquement ce site Web. Il suffit de remplacer arXiv dans n'importe quelle URL par alphaXiv pour ouvrir directement l'article correspondant sur le forum alphaXiv : vous pouvez localiser avec précision les paragraphes dans. l'article, Phrase : dans la zone de discussion sur la droite, les utilisateurs peuvent poser des questions à l'auteur sur les idées et les détails de l'article. Par exemple, ils peuvent également commenter le contenu de l'article, tels que : "Donné à".
 Une avancée significative dans l'hypothèse de Riemann ! Tao Zhexuan recommande fortement les nouveaux articles du MIT et d'Oxford, et le lauréat de la médaille Fields, âgé de 37 ans, a participé
Aug 05, 2024 pm 03:32 PM
Une avancée significative dans l'hypothèse de Riemann ! Tao Zhexuan recommande fortement les nouveaux articles du MIT et d'Oxford, et le lauréat de la médaille Fields, âgé de 37 ans, a participé
Aug 05, 2024 pm 03:32 PM
Récemment, l’hypothèse de Riemann, connue comme l’un des sept problèmes majeurs du millénaire, a réalisé une nouvelle avancée. L'hypothèse de Riemann est un problème mathématique non résolu très important, lié aux propriétés précises de la distribution des nombres premiers (les nombres premiers sont les nombres qui ne sont divisibles que par 1 et par eux-mêmes, et jouent un rôle fondamental dans la théorie des nombres). Dans la littérature mathématique actuelle, il existe plus d'un millier de propositions mathématiques basées sur l'établissement de l'hypothèse de Riemann (ou sa forme généralisée). En d’autres termes, une fois que l’hypothèse de Riemann et sa forme généralisée seront prouvées, ces plus d’un millier de propositions seront établies sous forme de théorèmes, qui auront un impact profond sur le domaine des mathématiques et si l’hypothèse de Riemann s’avère fausse, alors parmi eux ; ces propositions qui en font partie perdront également de leur efficacité. Une nouvelle percée vient du professeur de mathématiques du MIT, Larry Guth, et de l'Université d'Oxford
 La formation Axiom permet au LLM d'apprendre le raisonnement causal : le modèle à 67 millions de paramètres est comparable au niveau de mille milliards de paramètres GPT-4.
Jul 17, 2024 am 10:14 AM
La formation Axiom permet au LLM d'apprendre le raisonnement causal : le modèle à 67 millions de paramètres est comparable au niveau de mille milliards de paramètres GPT-4.
Jul 17, 2024 am 10:14 AM
Montrez la chaîne causale à LLM et il pourra apprendre les axiomes. L'IA aide déjà les mathématiciens et les scientifiques à mener des recherches. Par exemple, le célèbre mathématicien Terence Tao a partagé à plusieurs reprises son expérience de recherche et d'exploration à l'aide d'outils d'IA tels que GPT. Pour que l’IA soit compétitive dans ces domaines, des capacités de raisonnement causal solides et fiables sont essentielles. La recherche présentée dans cet article a révélé qu'un modèle Transformer formé sur la démonstration de l'axiome de transitivité causale sur de petits graphes peut se généraliser à l'axiome de transitivité sur de grands graphes. En d’autres termes, si le Transformateur apprend à effectuer un raisonnement causal simple, il peut être utilisé pour un raisonnement causal plus complexe. Le cadre de formation axiomatique proposé par l'équipe est un nouveau paradigme pour l'apprentissage du raisonnement causal basé sur des données passives, avec uniquement des démonstrations.
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 Le premier MLLM basé sur Mamba est là ! Les poids des modèles, le code de formation, etc. sont tous open source
Jul 17, 2024 am 02:46 AM
Le premier MLLM basé sur Mamba est là ! Les poids des modèles, le code de formation, etc. sont tous open source
Jul 17, 2024 am 02:46 AM
La colonne AIxiv est une colonne où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com. Introduction Ces dernières années, l'application de grands modèles de langage multimodaux (MLLM) dans divers domaines a connu un succès remarquable. Cependant, en tant que modèle de base pour de nombreuses tâches en aval, le MLLM actuel se compose du célèbre réseau Transformer, qui
