

Dès la sortie de Code Llama, tout le monde s'attendait à ce que quelqu'un continue la minceur quantitative. Heureusement, cela peut être réalisé localement
Comme prévu, c'est Georgi Gerganov, l'auteur de lama.cpp, qui a agi, mais cette fois il l'a fait. ne suivez pas la routine :
Ne continuez pas Quantifié, le code 34B de Code LLama peut fonctionner sur les ordinateurs Apple même avec une précision FP16, et la vitesse d'inférence dépasse 20 jetons par seconde
 Images
Images
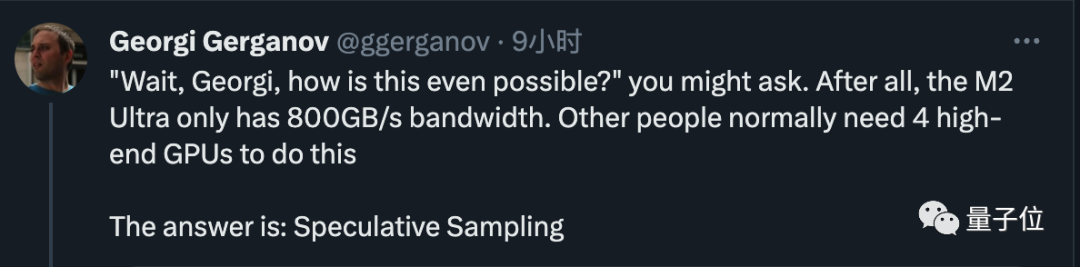
Maintenant, utilisez simplement une bande passante de 800 Go/s M2 Ultra peut effectuer des tâches qui nécessitaient à l'origine 4 GPU haut de gamme, et la vitesse d'écriture du code est également très rapide
Le vieil homme a alors révélé le secret. La réponse est très simple, qui est un échantillonnage/décodage spéculatif
 . Pictures
. Pictures
a attiré l'attention de nombreux géants de l'industrie
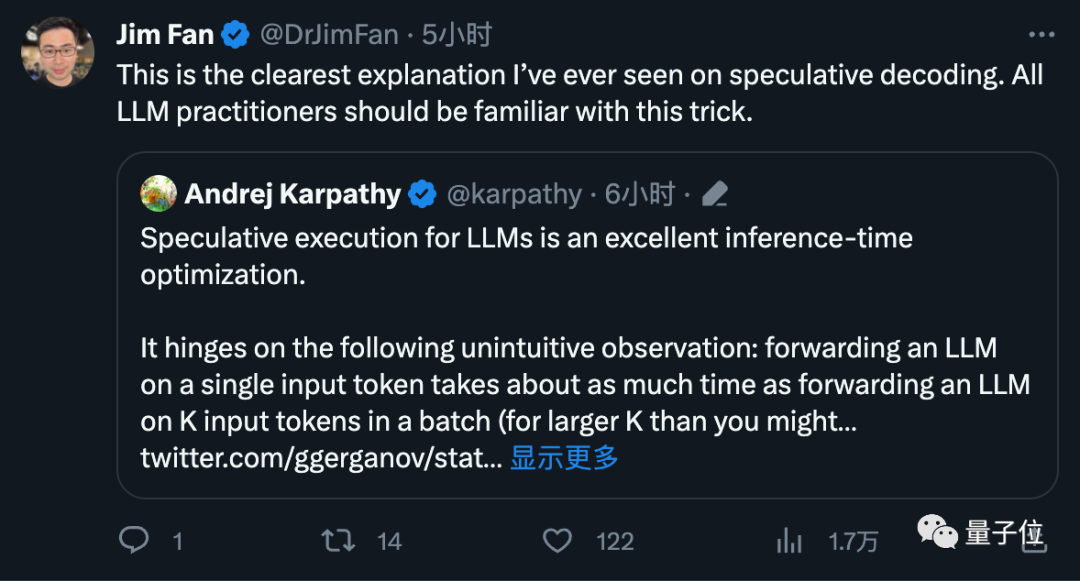
Andrej Karpathy, membre fondateur d'OpenAI, a commenté qu'il s'agit d'une très excellente optimisation du temps d'inférence et a donné des explications plus techniques.
Fan Linxi, un scientifique de Nvidia, estime également qu'il s'agit d'une technique que tous ceux qui travaillent sur de grands modèles devraient connaître
 Pictures
Pictures
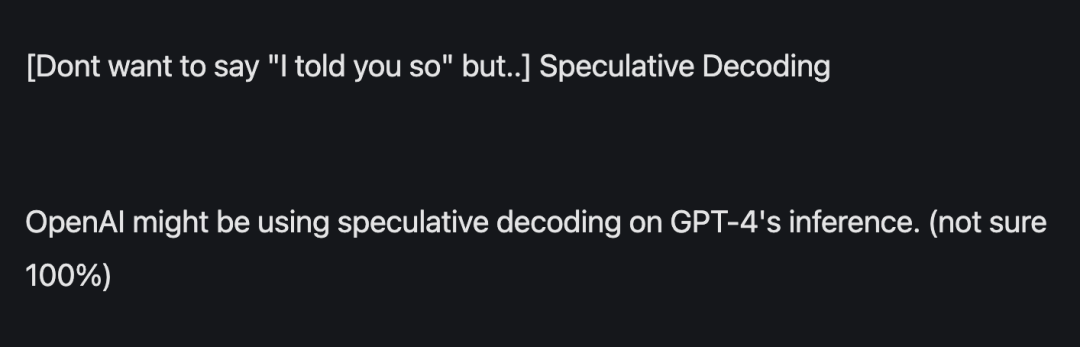
Ceux qui utilisent l'échantillonnage spéculatif Cela ne se limite pas à ceux qui exécutent de grands modèles localement, mais des super géants tels que Google et OpenAI utilisent également cette technologie
Selon des informations précédemment divulguées, GPT-4 utilise cette méthode pour réduire le coût de l'inférence, sinon il ne peut tout simplement pas se permettre de dépenser autant d’argent.
 Photos
Photos
Les dernières nouvelles indiquent que le grand modèle Gemini de nouvelle génération développé conjointement par Google DeepMind est susceptible d'être utilisé.
Bien que la méthode spécifique d'OpenAI soit confidentielle, l'équipe de Google a publié un article connexe, et l'article a été sélectionné pour le rapport oral ICML 2023
 Photos
Photos
La méthode est simple, entraînez d'abord un modèle qui est similaire au grand modèle et moins cher. Pour le petit modèle, laissez le petit modèle générer d'abord K jetons, puis laissez le grand modèle faire le jugement.
Le grand modèle peut utiliser directement les pièces acceptées et modifier les pièces non acceptées par le grand modèle
Dans la recherche originale, le modèle T5-XXL a été utilisé à des fins de démonstration, et tout en gardant les résultats générés inchangés, le
 photo
photo
Andjrey Karpathy compare cette méthode au fait de « laisser le petit modèle rédiger en premier ».
Il a expliqué que la clé de l'efficacité de cette méthode est que lorsqu'un grand modèle est entré dans un jeton et un lot de jetons, le temps nécessaire pour prédire le prochain jeton est presque le même
Chaque jeton dépend du précédent jeton, donc dans des circonstances normales, il est impossible d'échantillonner plusieurs jetons en même temps
Bien que le petit modèle ait une faible capacité, de nombreuses parties lors de la génération réelle d'une phrase sont très simples, et le petit modèle peut également faire le travail. Seulement lorsque vous rencontrez des pièces difficiles, laissez le grand modèle continuer.
L'article original souligne que les modèles matures existants peuvent être directement accélérés sans modifier leur structure ni recyclage.
Un argument mathématique pour le fait que la précision ne sera pas réduite est également donné en annexe de l'article.
 Photos
Photos
Maintenant que nous avons compris le principe, regardons cette fois les réglages spécifiques de Georgi Gerganov.
Il utilise un modèle 7B quantifié sur 4 bits comme modèle « brouillon », qui peut générer environ 80 jetons par seconde.
Lorsqu'il est utilisé seul, le modèle 34B avec une précision FP16 ne peut générer que 10 jetons par seconde
Après avoir utilisé la méthode d'échantillonnage spéculatif, nous avons obtenu un effet d'accélération 2x, ce qui est cohérent avec les données de l'article original
 Image
Image
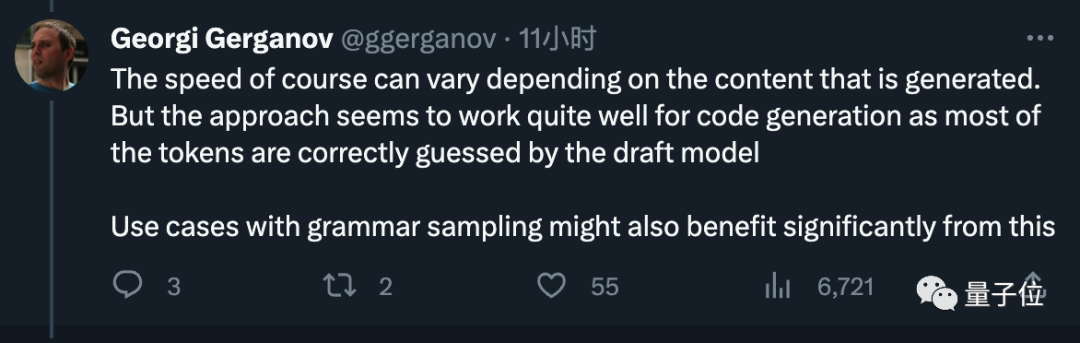
Il a également déclaré que la vitesse peut varier en fonction du contenu généré, mais qu'elle est très efficace dans la génération de code et que le projet de modèle peut deviner correctement la plupart des jetons.
 Photos
Photos
Enfin, il a également suggéré que Meta inclue directement de petits brouillons de modèles lors de la publication de modèles à l'avenir, ce qui a été bien accueilli par tout le monde.
 Photos
Photos
Georgi Gerganov est l'auteur. Il a porté la première génération de LlaMA en C++ en mars de cette année. Son projet open source llama.cpp a reçu près de 40 000 étoiles
 photos
photos
Au début, il ne considérait cela que comme un passe-temps secondaire, mais en raison de la réponse massive, il a annoncé sa création en juin
nouvelle société ggml . ai est dédié à l’exécution de l’IA sur les appareils de pointe. Le produit phare de l'entreprise est le framework d'apprentissage automatique en langage C derrière llama.cpp
 Picture
Picture
Au début de la startup, nous avons obtenu avec succès un financement de pré-amorçage de l'ancien PDG de GitHub, Nat Friedman, et de Daniel Gross, partenaire de Y Combinator. Investissement
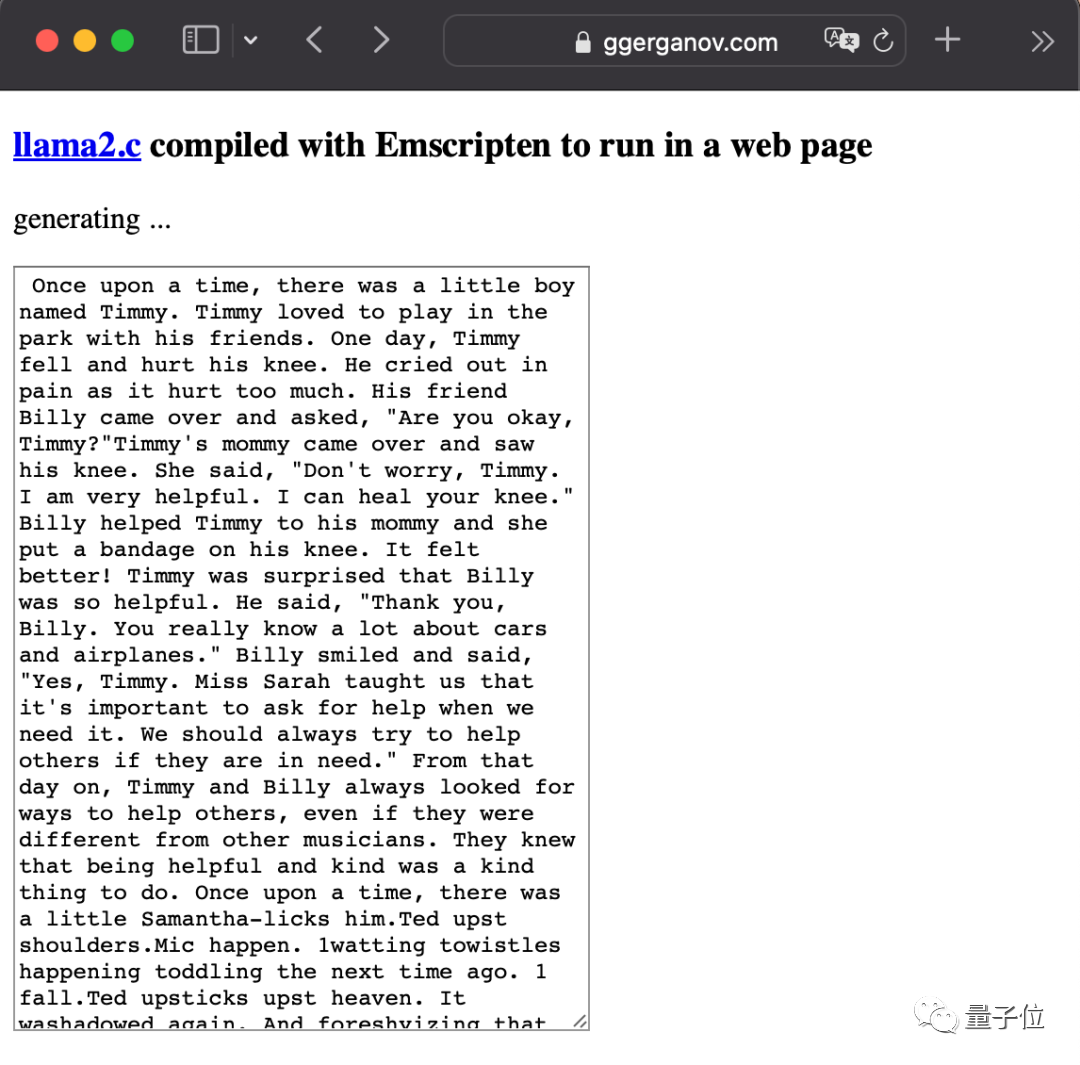
Il a également été très actif après la sortie de LlaMA2. Le plus impitoyable a été de mettre un gros modèle directement dans le navigateur.
 Photos
Photos
Veuillez consulter le document d'échantillonnage spéculatif de Google : https://arxiv.org/abs/2211.17192
Lien de référence : [1] https://x.com/ggerganov/status/1697262700165013689 [2 ]https://x.com/karpathy/status/1697318534555336961
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Que signifie le réseau Apple LTE ?
Que signifie le réseau Apple LTE ?
 Le rôle du mode Ne pas déranger d'Apple
Le rôle du mode Ne pas déranger d'Apple
 Comment résoudre le problème selon lequel Apple ne peut pas télécharger plus de 200 fichiers
Comment résoudre le problème selon lequel Apple ne peut pas télécharger plus de 200 fichiers
 Introduction à l'utilisation du code complet VBS
Introduction à l'utilisation du code complet VBS
 Utilisation de la commande de recherche Linux
Utilisation de la commande de recherche Linux
 Quelle devise est MULTI ?
Quelle devise est MULTI ?
 Comment fermer le port 135 445
Comment fermer le port 135 445
 Comment créer une entrée d'encyclopédie
Comment créer une entrée d'encyclopédie








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



