
 Périphériques technologiques
IA
Jia Qianghuai : Construction et application d'un graphe de connaissances à grande échelle sur les fourmis
Périphériques technologiques
IA
Jia Qianghuai : Construction et application d'un graphe de connaissances à grande échelle sur les fourmis
Jia Qianghuai : Construction et application d'un graphe de connaissances à grande échelle sur les fourmis


1. Présentation du graphe de connaissances
Présentez d'abord quelques concepts de base du graphe de connaissances.
1. Qu'est-ce qu'un graphe de connaissances ?
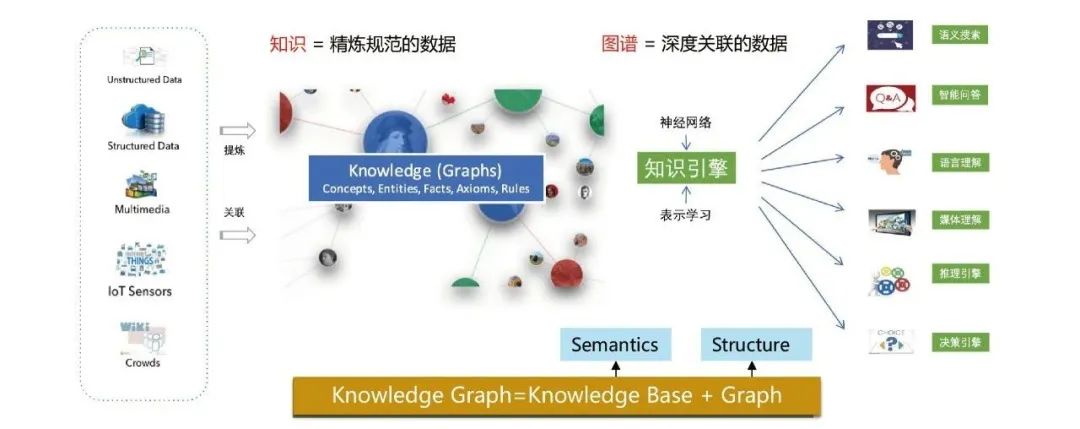
Le graphe de connaissances vise à utiliser des structures graphiques pour modéliser, identifier et déduire des relations complexes entre les choses et précipiter la connaissance du domaine. a Il est largement utilisé dans les moteurs de recherche, la réponse intelligente aux questions, la compréhension sémantique du langage, l'analyse des décisions Big Data et bien d'autres domaines.
Le graphe de connaissances modélise à la fois la relation sémantique et la relation structurelle entre les données. Combiné à la technologie d'apprentissage en profondeur, les deux relations peuvent être mieux intégrées et représentées.
2. Pourquoi devrions-nous construire un graphe de connaissances ?
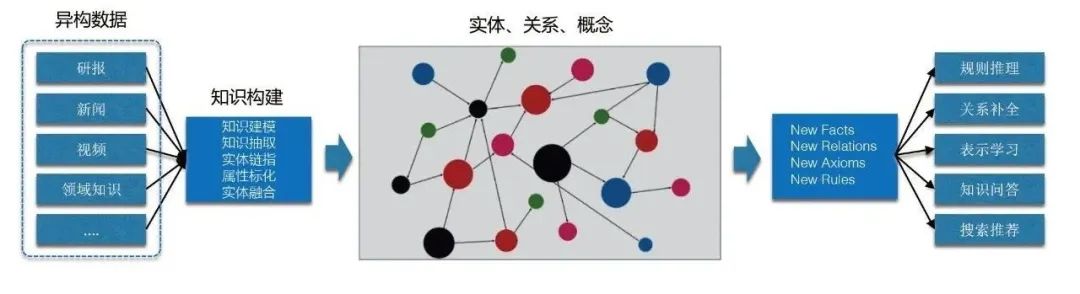
Nous souhaitons construire un graphe de connaissances principalement à partir des deux points suivants : d'une part, les caractéristiques de l'arrière-plan de la source de données des fourmis elles-mêmes, d'autre part. d’autre part, ce que le knowledge graph peut apporter.
[1] Les sources de données elles-mêmes sont diverses et hétérogènes, manquant d'un système unifié de compréhension des connaissances.
[2] Les graphes de connaissances peuvent apporter de multiples avantages, notamment :
- Standardisation sémantique : utilisez la technologie de construction de graphes pour améliorer le niveau de standardisation et de normalisation des entités, des relations, des concepts, etc.
- Accumulation de connaissances de domaine : réalisez une représentation et une interconnexion des connaissances basées sur la sémantique et la structure graphique, accumulant ainsi de riches connaissances de domaine.
- Réutilisation des connaissances : créez un graphique de connaissances Ant de haute qualité, réduisez les coûts de l'entreprise et améliorez l'efficacité grâce à l'intégration, à la liaison et à d'autres services.
- Découverte du raisonnement des connaissances : découvrez des connaissances plus longues basées sur la technologie de raisonnement graphique, servant des scénarios tels que le contrôle des risques, le crédit, les réclamations, les opérations marchandes, les recommandations marketing, etc.
3. Aperçu de la façon de créer des graphes de connaissances
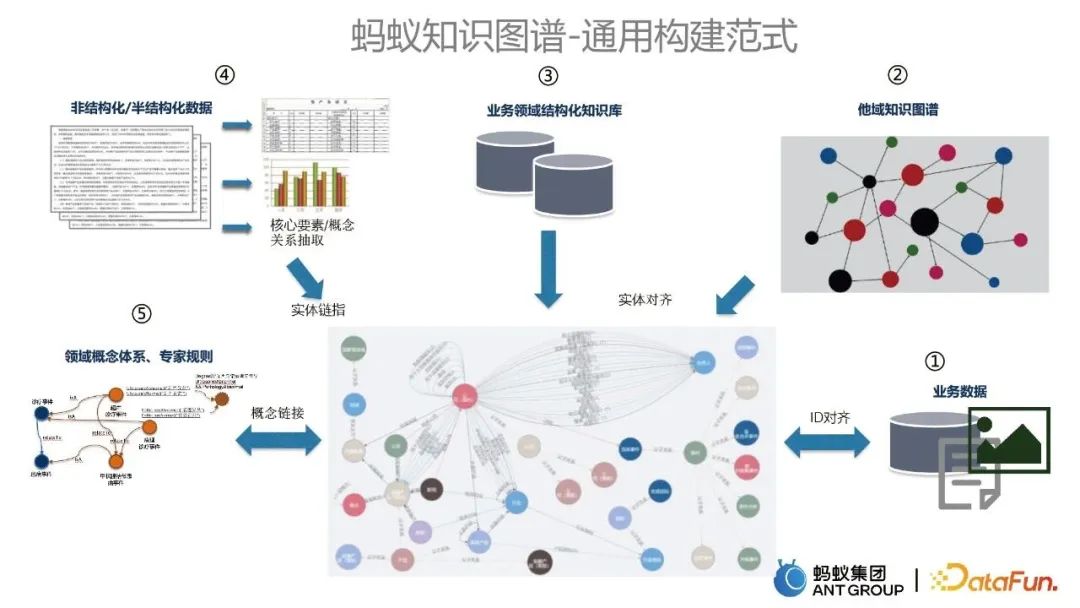
Dans le processus de création de divers graphes de connaissances commerciales, nous avons précipité un ensemble de paradigmes de construction généraux pour les graphes de connaissances des fourmis, qui sont principalement divisés en Cinq parties suivantes :
- Partez des données commerciales en tant que source de données importante pour le démarrage à froid des graphiques.
- Le graphe de connaissances des autres domaines est intégré au graphe existant, ce qui est réalisé grâce à la technologie d'alignement des entités.
- L'intégration de la base de connaissances structurée dans le domaine métier et du graphe de connaissances existant est également réalisée grâce à la technologie d'alignement des entités.
- Les données non structurées et semi-structurées, telles que le texte, seront utilisées pour extraire des informations et mettre à jour la carte existante grâce à la technologie de lien d'entité.
- L'intégration de systèmes de concepts de domaine et de règles expertes relie les concepts et règles associés aux graphes de connaissances existants.
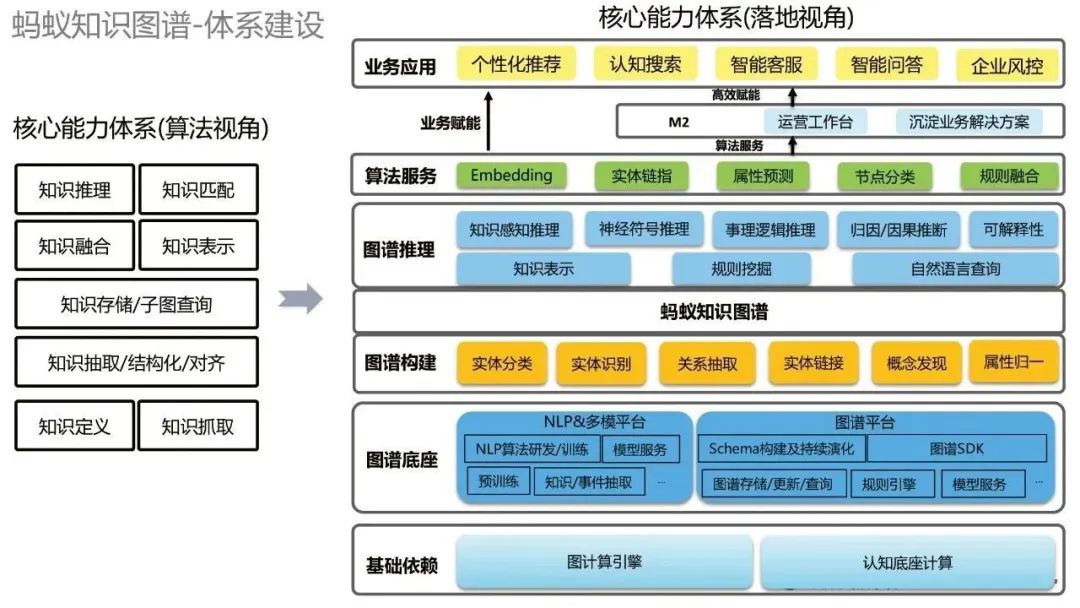
Après avoir un paradigme de construction commun, il est nécessaire de réaliser une construction systématique. Examinez la construction systématique du Ant Knowledge Graph sous deux angles. Premièrement, d’un point de vue algorithmique, il existe diverses capacités algorithmiques, telles que le raisonnement par connaissances, l’appariement des connaissances, etc. Du point de vue de la mise en œuvre, de bas en haut, les dépendances de base les plus basses incluent le moteur de calcul graphique et le calcul de base cognitive au-dessus se trouvent la base de graphiques, y compris la plate-forme PNL et multimodale et la plate-forme graphique au-dessus se trouvent diverses technologies de construction de graphiques ; Sur cette base, nous pouvons construire le graphe de connaissances des fourmis ; sur la base du graphe de connaissances, nous pouvons faire un raisonnement graphique plus haut, nous fournissons certaines capacités générales d'algorithme ;
2. Construction de graphes
Ensuite, nous partagerons certaines des capacités de base d'Ant Group dans la création de graphes de connaissances, notamment la construction de graphes, la fusion de graphes et la cognition de graphes.
1. Construction de cartes
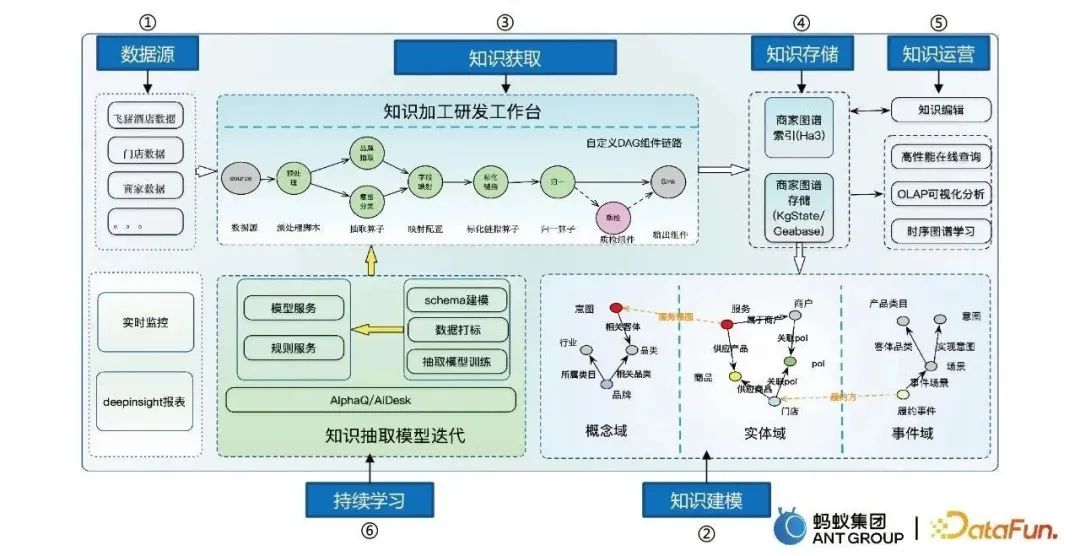
Le processus de construction de cartes comprend principalement six étapes :
- Sources de données pour obtenir des données multivariées.
- La modélisation des connaissances convertit des données massives en données structurées, en modélisant trois domaines : les concepts, les entités et les événements.
- Acquisition de connaissances et construction d'une plateforme de R&D en traitement des connaissances.
- Stockage de connaissances, y compris le stockage Ha3 et le stockage de graphiques, etc.
- Opérations de connaissances, y compris l'édition de connaissances, la requête en ligne, l'extraction, etc.
- Apprentissage continu, permettant au modèle d'apprendre automatiquement et de manière itérative.
Trois expériences et compétences dans le processus de construction
Classification des entités intégrant des connaissances expertes
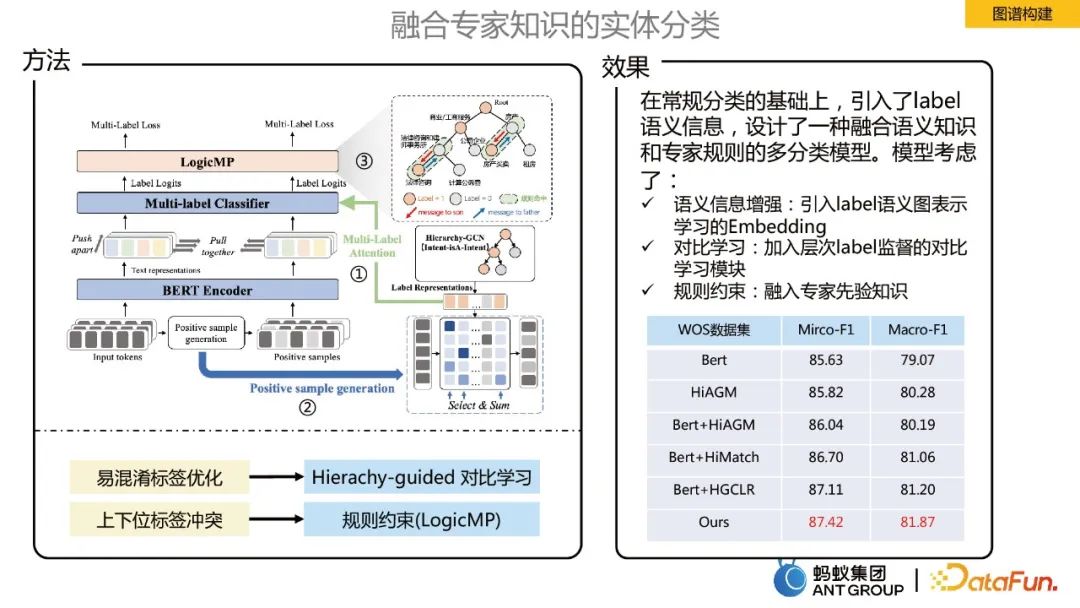
Dans la construction d'un graphe de connaissances, il est nécessaire de classer les entités d'entrée, ce qui constitue un problème à grande échelle chez la fourmi Scénario Tâche de classification des étiquettes. Afin d'intégrer les connaissances d'experts pour la classification des entités, les trois points d'optimisation principaux suivants sont réalisés :
- Amélioration de l'information sémantique : introduction de l'intégration de l'apprentissage de la représentation graphique sémantique des étiquettes.
- Apprentissage du contraste : ajoutez une supervision d'étiquettes hiérarchiques à des fins de comparaison.
- Contraintes de règles logiques : incorporer des connaissances préalables d'experts.
Reconnaissance d'entités injectée dans le vocabulaire du domaine
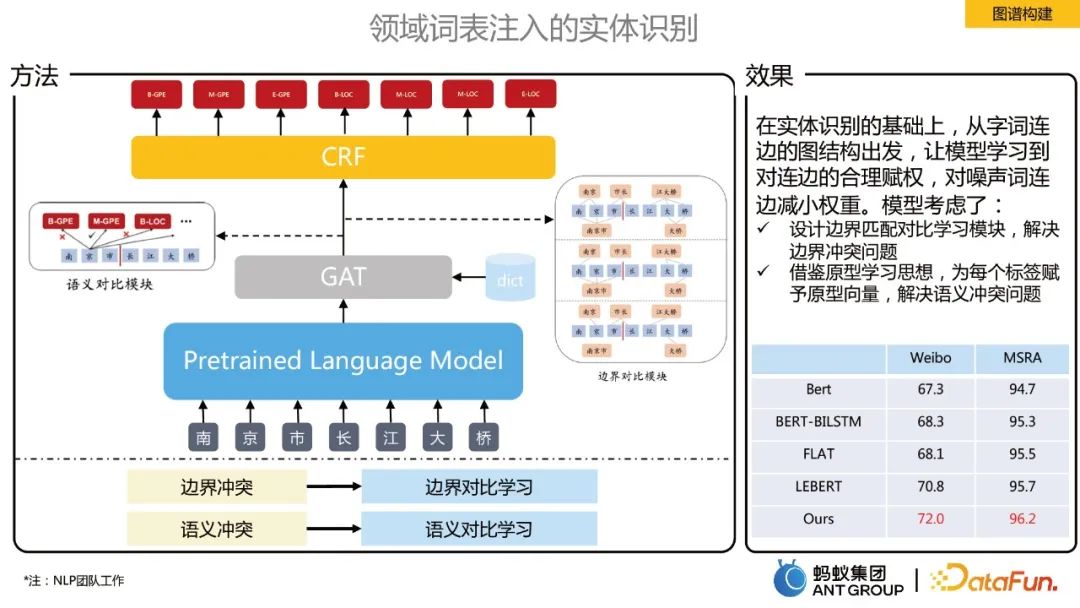
Sur la base de la reconnaissance d'entités, à partir de la structure graphique des bords de mots, le modèle apprend une pondération raisonnable des bords et des connexions de mots bruyantes. Réduisez le poids du bord. . Deux modules, apprentissage contrastif aux frontières et apprentissage contrastif sémantique, sont proposés :
- apprentissage contrastif aux frontières pour résoudre des problèmes de conflits de frontières. Une fois le vocabulaire injecté, un graphique entièrement connecté est construit et GAT est utilisé pour apprendre la représentation de chaque jeton. La partie correcte de la classification des limites construit un exemple de graphique positif et la partie incorrecte construit un exemple de graphique négatif par comparaison. , le modèle apprend chaque jeton informations de limite d'un jeton.
- L'apprentissage contrastif sémantique est utilisé pour résoudre des problèmes de conflits sémantiques. S'appuyant sur l'idée d'apprentissage de prototypes, la représentation sémantique de l'étiquette est ajoutée pour renforcer l'association entre chaque jeton et la sémantique de l'étiquette.
Extraction de relations sur petits échantillons contrainte par des règles logiques
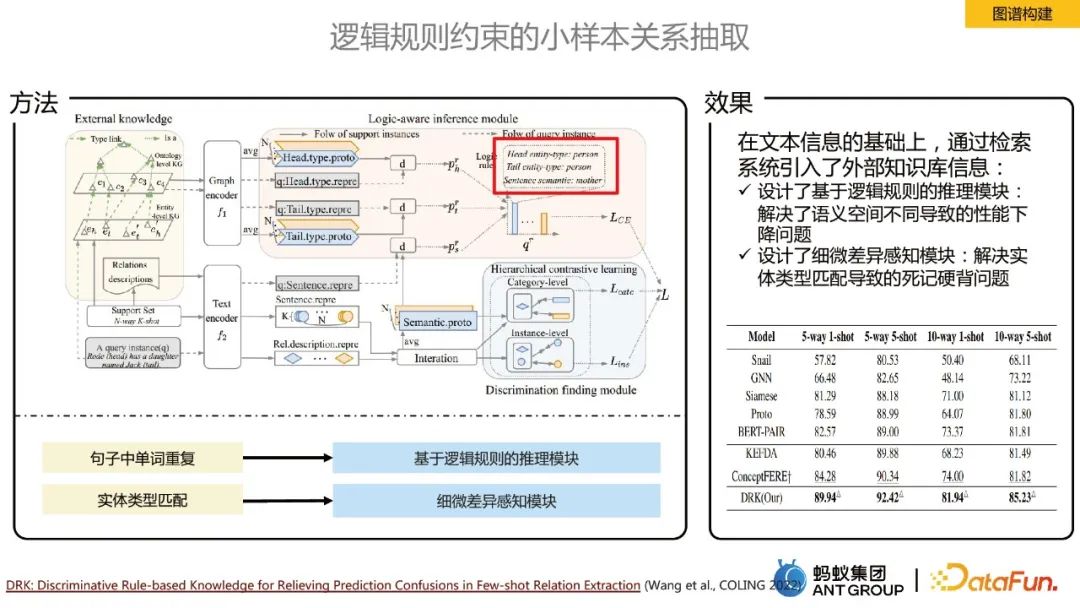
Dans les problèmes de domaine, nous avons très peu d'échantillons étiquetés et serons confrontés à des scénarios avec peu de tirs ou zéro tir. Dans ce cas, nous effectuons une extraction de relations. L'idée principale est d'introduire une base de connaissances externe. Afin de résoudre le problème de dégradation des performances causé par différents espaces sémantiques, un module de raisonnement basé sur des règles logiques est conçu afin de résoudre le problème d'apprentissage par cœur causé par la correspondance de types d'entités ; Un module de perception des différences subtiles est conçu.
2. Fusion de graphiques
La fusion de graphiques fait référence à la fusion d'informations entre des graphiques dans différents domaines commerciaux.
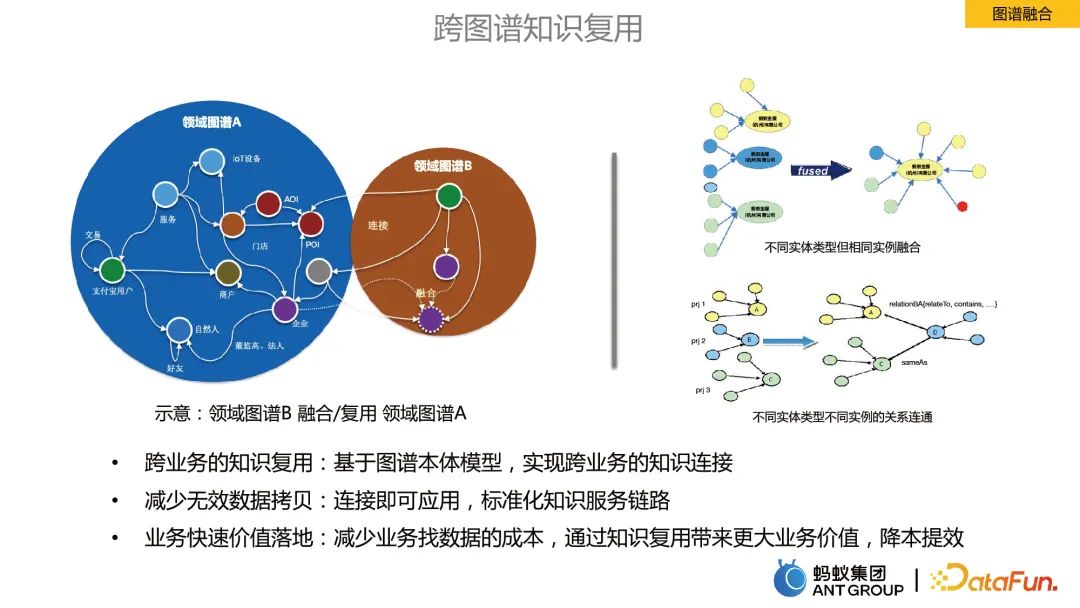
Avantages de la fusion de graphes :
- Réutilisation des connaissances inter-métiers : sur la base du modèle d'ontologie graphique, une connexion des connaissances inter-métiers est réalisée.
- Réduire les copies de données invalides : connectez-vous et postulez, liens de services de connaissances standardisés.
- Mise en œuvre rapide de la valeur commerciale : réduisez le coût de recherche de données pour l'entreprise, apportez une plus grande valeur commerciale grâce à la réutilisation des connaissances, réduisez les coûts et améliorez l'efficacité.
Alignement d'entités dans la fusion de graphes
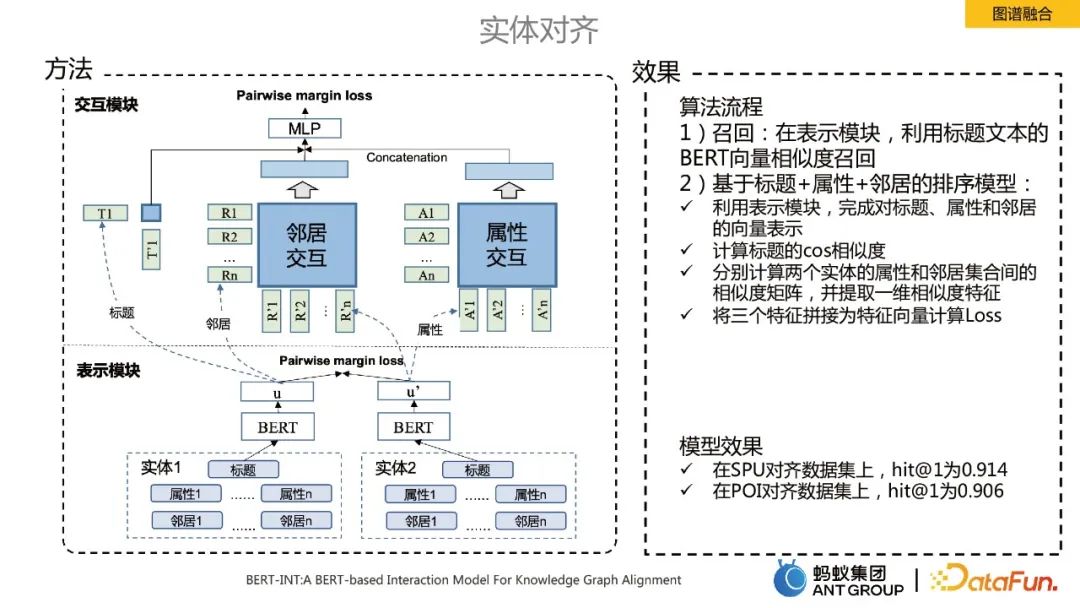
Un point technique essentiel dans le processus de fusion de graphes de connaissances est l'alignement des entités. Ici, nous utilisons l'algorithme SOTA BERT-INT, qui comprend principalement deux modules, l'un est le module de présentation et l'autre est le module d'interaction.
Le processus de mise en œuvre de l'algorithme comprend principalement le rappel et le tri :
Rappel : Dans le module de représentation, le rappel de similarité vectorielle BERT du texte du titre est utilisé.
Modèle de classement basé sur titre + attribut + voisin : ü Utilisez le module de représentation pour compléter la représentation vectorielle du titre, de l'attribut et du voisin :
- Calculez la similarité cos du titre.
- Calculez la matrice de similarité entre les attributs et les ensembles voisins de deux entités respectivement, et extrayez les caractéristiques de similarité unidimensionnelles.
- Splice trois caractéristiques dans un vecteur de caractéristiques pour calculer la perte.
3. Cognition graphique
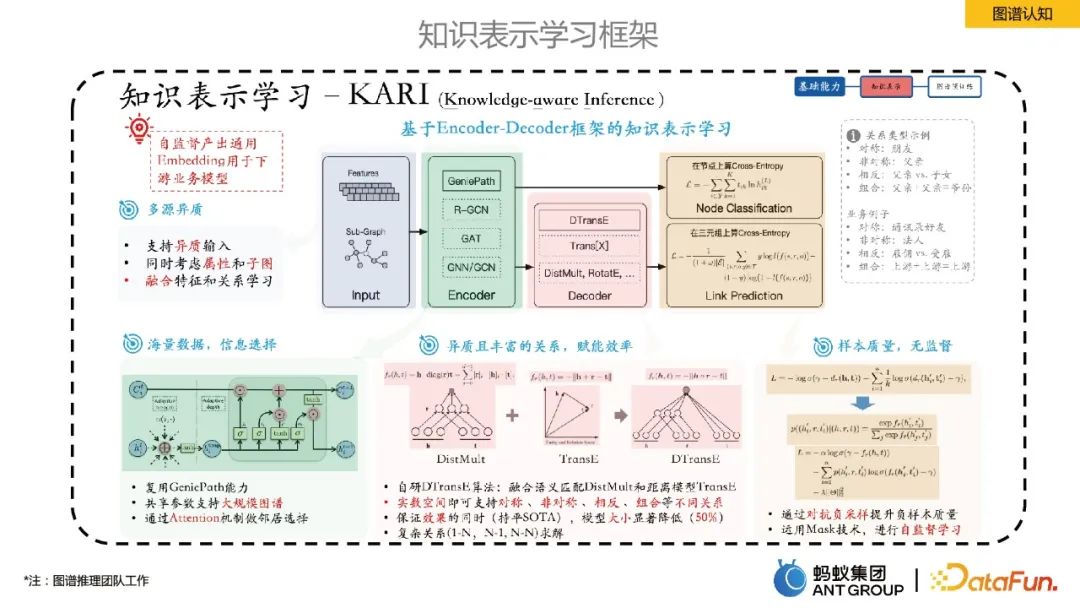
Cette partie présente principalement le cadre d'apprentissage de la représentation interne des connaissances d'Ant.
Ant a proposé un apprentissage de représentation des connaissances basé sur le framework Encoder-Decoder. Parmi eux, Encoder est une méthode d'apprentissage neuronal graphique, et Decoder est un apprentissage de représentation de connaissances, tel que la prédiction de lien. Ce cadre d'apprentissage de représentation peut auto-superviser la production d'intégrations universelles d'entités/relations, ce qui présente plusieurs avantages : 1) la taille de l'intégration est beaucoup plus petite que l'espace des fonctionnalités d'origine, réduisant les coûts de stockage 2) les vecteurs de faible dimension sont plus denses, atténuant ainsi efficacement ; le problème de la rareté des données. 3) L'apprentissage dans le même espace vectoriel rend la fusion de données hétérogènes provenant de plusieurs sources plus naturelle. 4) L'intégration a une certaine universalité et est pratique pour une utilisation commerciale en aval.
3. Application de graphe de connaissances
Ensuite, je partagerai quelques cas d'application typiques du graphe de connaissances dans Ant Group.
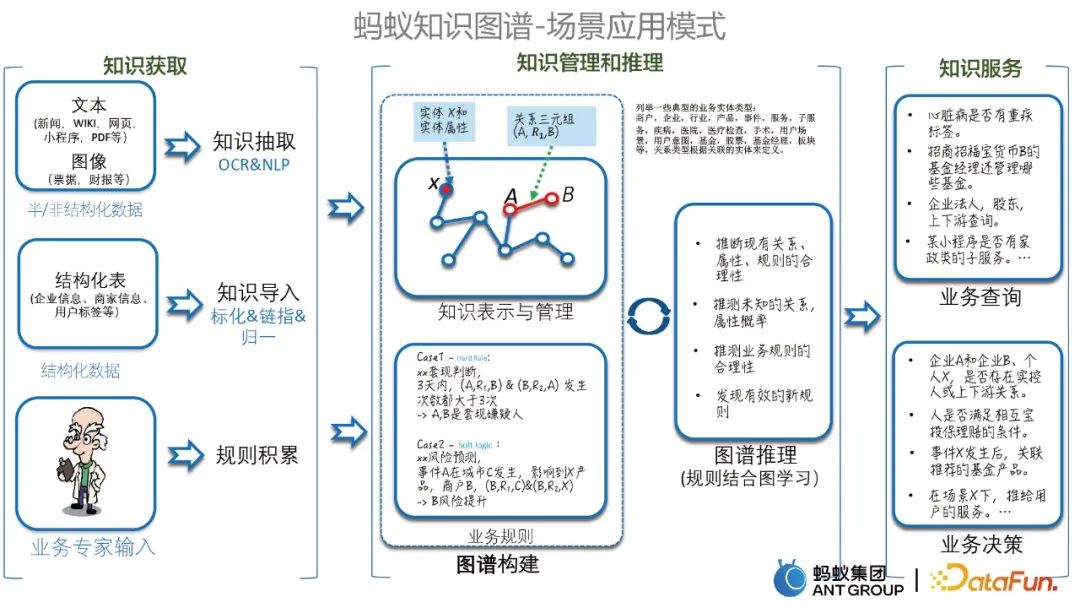
1. Modes d'application de scénarios du graphe
Avant d'introduire des cas spécifiques, introduisons d'abord plusieurs modes d'application de scénarios de l'Ant Knowledge Graph, qui incluent principalement l'acquisition de connaissances, la gestion et le raisonnement des connaissances, ainsi que les services de connaissances. Comme indiqué ci-dessous.
2. Quelques cas typiques
Cas 1 : Rappel de correspondance structuré basé sur un graphe de connaissances
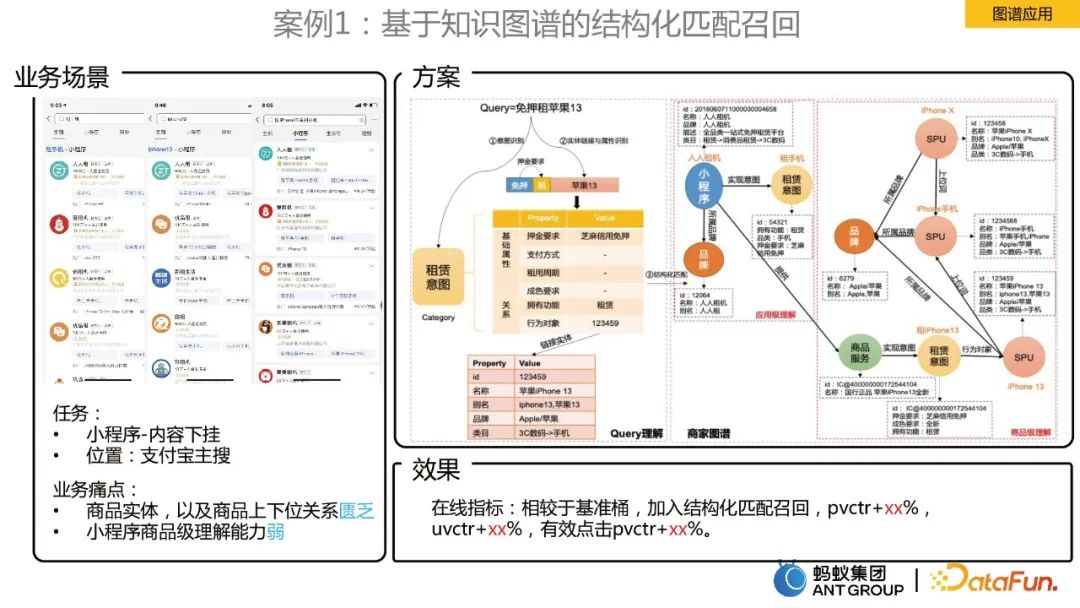
Le scénario commercial est le contenu du mini programme dans la recherche principale d'Alipay et l'affaire à résoudre. Les points faibles sont :
- Le manque d'entités de produits et la relation entre les niveaux supérieur et inférieur des produits.
- Faible capacité à comprendre le niveau des produits des petits programmes.
La solution est de construire un graphe de connaissances marchand. En combinaison avec la relation produit de la carte marchande, une compréhension structurée du niveau produit de la requête utilisateur est obtenue.
Cas 2 : Application de la prédiction en temps réel de l'intention de l'utilisateur dans le système de recommandation
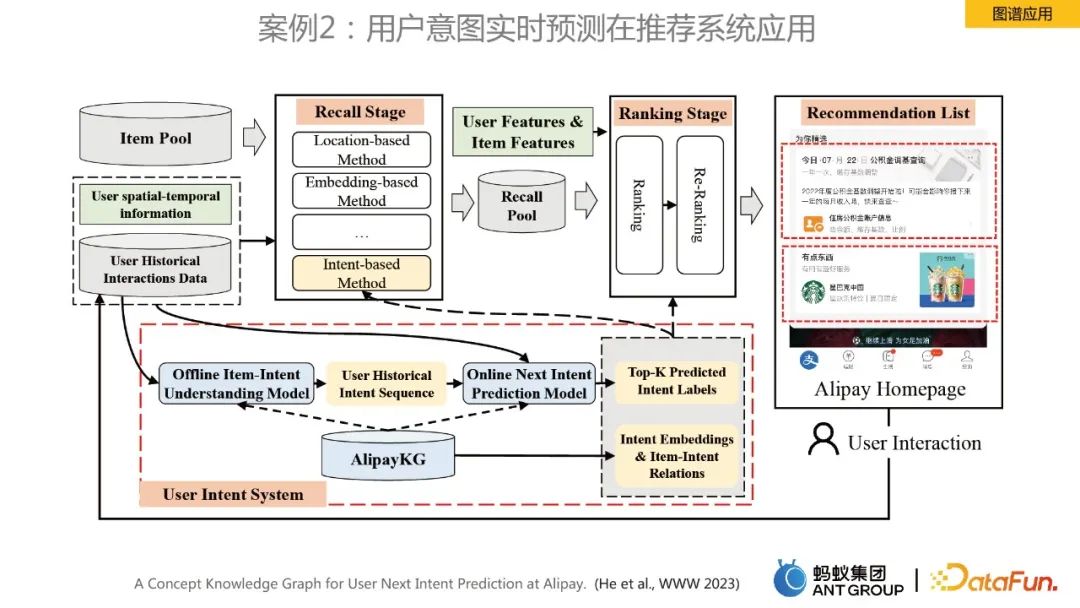
Ce cas concerne la prédiction en temps réel de l'intention de l'utilisateur pour la recommandation de la page d'accueil, et AlipayKG est construit. figure ci-dessus. Des travaux connexes ont également été publiés lors de la conférence majeure www 2023. Vous pouvez vous référer à l'article pour une meilleure compréhension.
Cas 3 : Recommandation de coupon marketing intégrant la représentation des connaissances
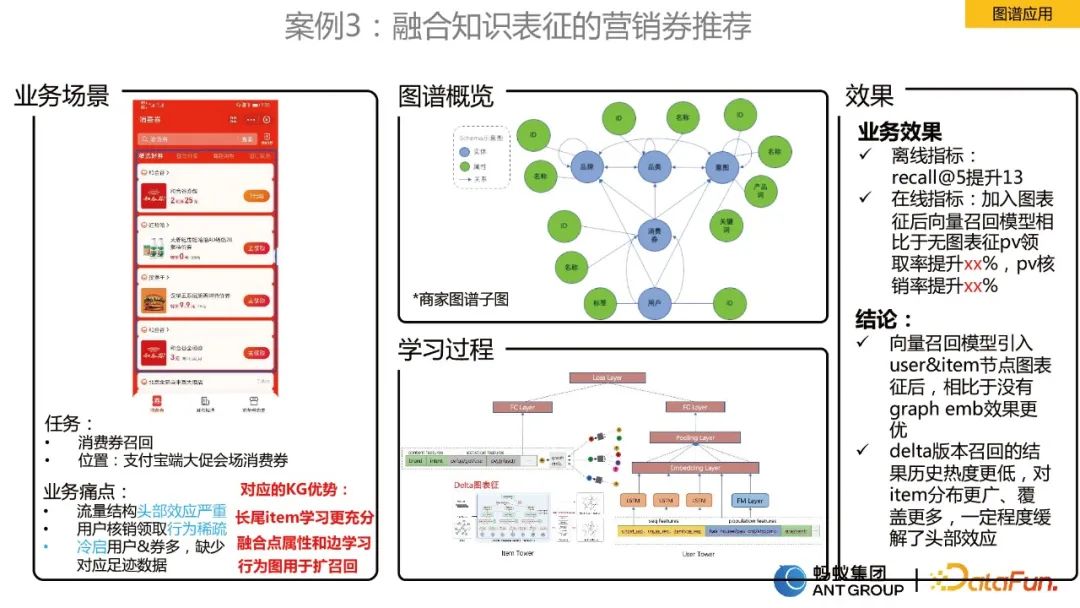
Ce scénario est un scénario de recommandation de coupon consommateur. Les problèmes rencontrés par l'entreprise sont :
.- Effet de tête sérieux.
- Le comportement de vérification et de collecte des utilisateurs est rare.
- Il existe de nombreux utilisateurs et coupons de démarrage à froid, mais les données d'empreinte correspondantes font défaut.
Afin de résoudre les problèmes ci-dessus, nous avons conçu un algorithme de rappel vectoriel profond qui fusionne la représentation graphique dynamique. Parce que nous avons constaté que le comportement des coupons de consommation des utilisateurs est cyclique, une arête unique statique ne peut pas modéliser ce comportement cyclique. À cette fin, nous avons d'abord construit un graphe dynamique, puis avons utilisé l'algorithme de graphe dynamique auto-développé par l'équipe pour apprendre la représentation d'intégration. Après avoir obtenu la représentation, nous l'avons placée dans le modèle à tour jumelle pour le rappel vectoriel.
Cas 4 : Raisonnement de règles d'experts en réclamations intelligentes basé sur des événements de diagnostic et de traitement
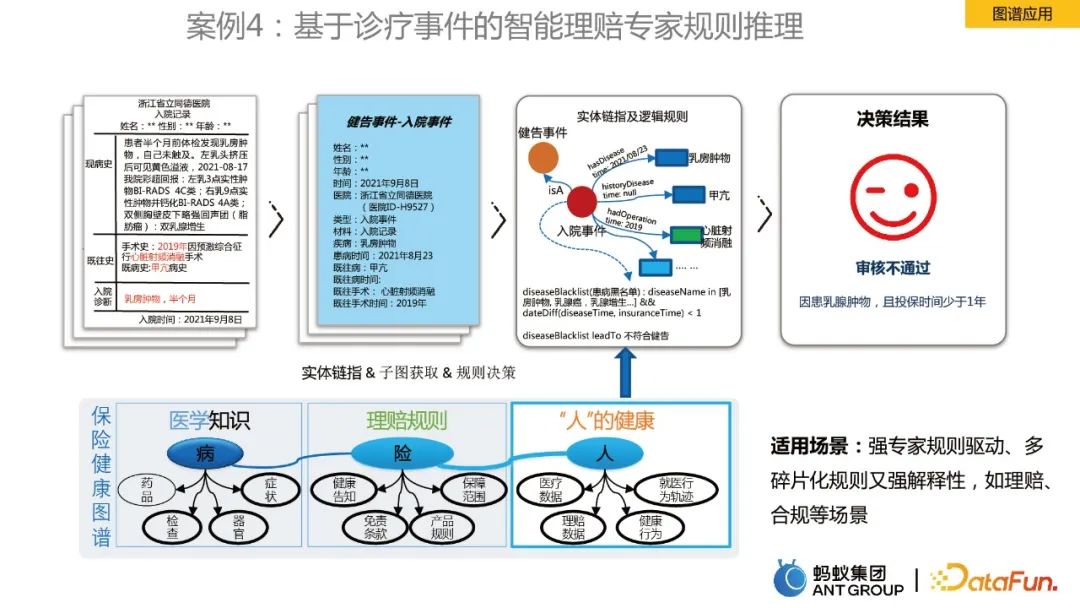
Le dernier cas concerne le raisonnement de règles graphiques. En prenant comme exemple la carte de santé de l'assurance maladie, elle comprend des connaissances médicales, des règles de réclamation et des informations sur la santé des « personnes », qui sont liées à des entités et associées à des règles logiques comme base de prise de décision. Grâce à la carte, l'efficacité du règlement des réclamations d'experts a été améliorée.
4. Graphiques et grands modèles
Enfin, discutons brièvement des opportunités des graphes de connaissances dans le contexte du développement rapide actuel des grands modèles.
1. La relation entre les graphes de connaissances et les grands modèles
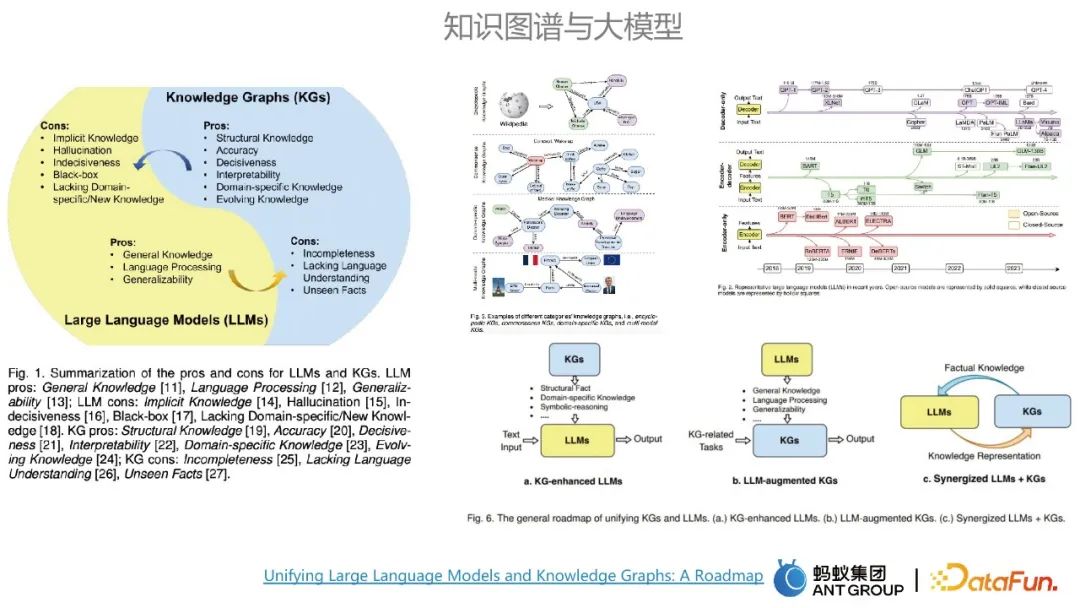
Les graphes de connaissances et les grands modèles ont chacun leurs propres avantages et inconvénients. Les principaux avantages des grands modèles sont la modélisation des connaissances générales et l'universalité, tandis que les inconvénients des grands modèles. les modèles sont parfaits. Cela peut être compensé par les avantages du knowledge graph. Les avantages de la carte incluent une grande précision et une forte interprétabilité. Les grands modèles et les graphiques de connaissances peuvent s'influencer mutuellement.
Il existe généralement trois voies pour l'intégration de graphiques et de grands modèles : la première consiste à utiliser des graphiques de connaissances pour améliorer les grands modèles ; la seconde consiste à utiliser de grands modèles pour améliorer les graphiques de connaissances ; et les graphes de connaissances. , avantages complémentaires, le grand modèle peut être considéré comme une base de connaissances paramétrée, et le graphe de connaissances peut être considéré comme une base de connaissances affichée.
2. Cas d'application des grands modèles et des graphes de connaissances
Les grands modèles sont utilisés dans la construction de graphes de connaissances
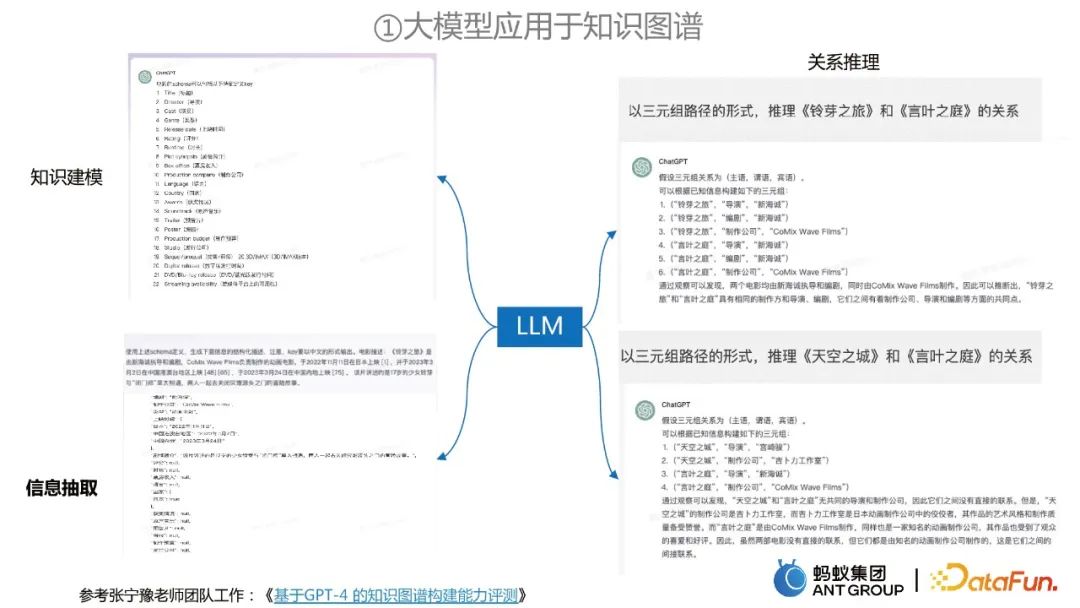
Dans le processus de construction de graphes de connaissances, les grands modèles peuvent être utilisés pour l'extraction d'informations, la modélisation des connaissances et Raisonnement relationnel.
Comment utiliser de grands modèles pour appliquer l'extraction d'informations à partir de graphes de connaissances

Ce travail de la DAMO Academy décompose le problème d'extraction d'informations en deux étapes :
- Dans la première étape, nous voulons recherchez les entités, les relations ou les types d'événements existants dans le texte pour réduire l'espace de recherche et la complexité informatique.
- Dans la deuxième étape, nous extrayons en outre les informations pertinentes en fonction des types précédemment extraits et de la liste correspondante donnée.
Application des graphiques de connaissances aux grands modèles
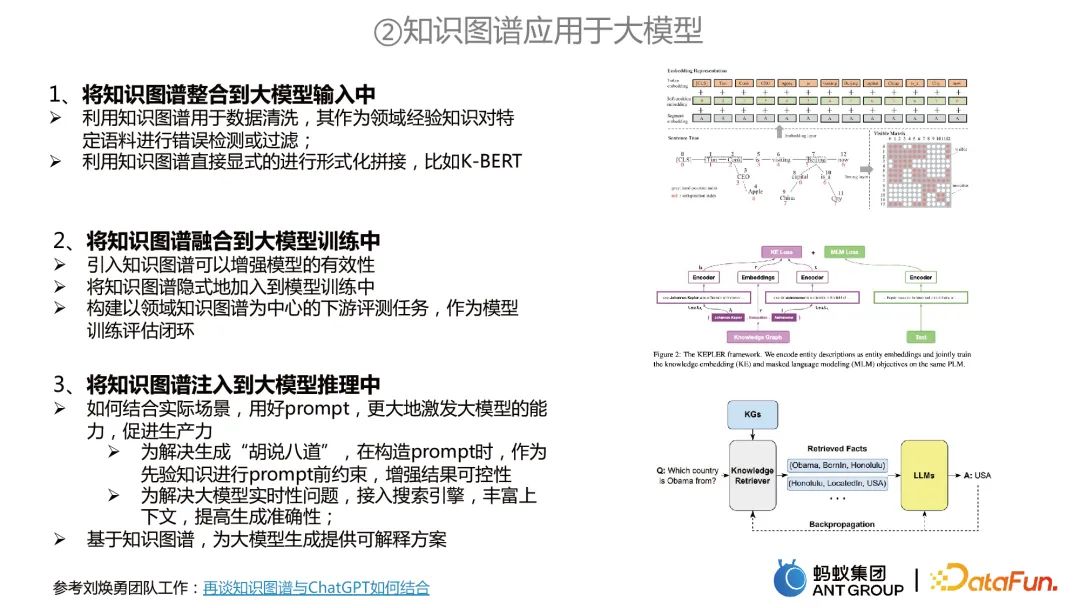
L'application des graphiques de connaissances aux grands modèles comprend principalement trois aspects :
L'intégration des graphiques de connaissances dans les entrées de grands modèles. Le graphe de connaissances peut être utilisé pour le nettoyage des données, ou le graphe de connaissances peut être utilisé pour effectuer directement un épissage formel.
Intégrez un graphique de connaissances dans la formation de grands modèles. Par exemple, deux tâches sont entraînées en même temps.Le graphe de connaissances peut être utilisé pour les tâches de représentation des connaissances, et le grand modèle peut être utilisé pour la pré-formation du MLM, et les deux sont modélisés conjointement.
Injectez un graphique de connaissances dans le raisonnement sur un grand modèle. Premièrement, deux problèmes liés aux grands modèles peuvent être résolus.Le premier est d'utiliser le graphe de connaissances comme contraintes a priori pour éviter le « non-sens » des grands modèles ; D’un autre côté, sur la base de graphes de connaissances, des solutions interprétables peuvent être fournies pour la génération de modèles à grande échelle.
Le système de questions-réponses amélioré par les connaissances
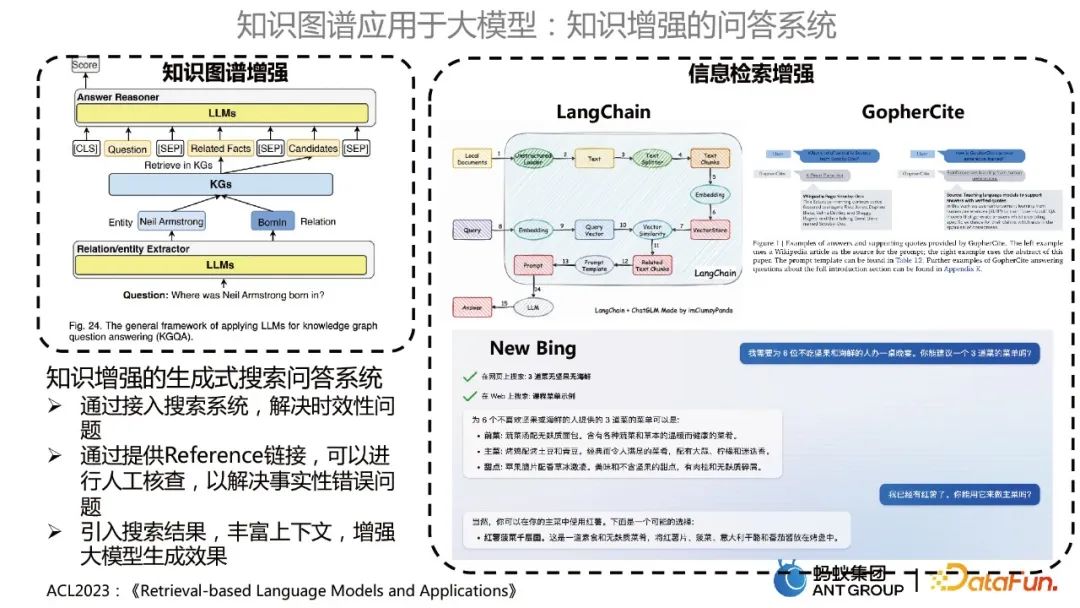
comprend principalement deux catégories. L'une est le système de questions-réponses amélioré par un graphe de connaissances, qui utilise un grand modèle pour optimiser le modèle KBQA, l'autre est l'amélioration de la recherche d'informations, similaire à LangChain, GopherCite ; , et New Bing. Utilisez de grands modèles pour formuler des questions et des réponses dans la base de connaissances.
Le système de questions et réponses de recherche générative amélioré par les connaissances présente les avantages suivants :
- Résolvez le problème de rapidité en accédant au système de recherche.
- En fournissant un lien de référence, une vérification manuelle peut être effectuée pour résoudre des erreurs factuelles.
- Introduisez les résultats de recherche, enrichissez le contexte et améliorez les effets de génération de grands modèles.
3. Résumé et perspectives

Comment les graphes de connaissances et les grands modèles peuvent mieux interagir et travailler ensemble, y compris les trois directions suivantes :
- Promouvoir les graphes de connaissances et les grands modèles en PNL, en -applications approfondies dans des domaines tels que les systèmes de questions-réponses.
- Utilisation de graphes de connaissances pour la détection des hallucinations et la désintoxication des grands modèles.
- Développement de modèles de grands domaines combinés à des graphes de connaissances.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Méthodes et étapes d'utilisation de BERT pour l'analyse des sentiments en Python
Jan 22, 2024 pm 04:24 PM
Méthodes et étapes d'utilisation de BERT pour l'analyse des sentiments en Python
Jan 22, 2024 pm 04:24 PM
BERT est un modèle de langage d'apprentissage profond pré-entraîné proposé par Google en 2018. Le nom complet est BidirectionnelEncoderRepresentationsfromTransformers, qui est basé sur l'architecture Transformer et présente les caractéristiques d'un codage bidirectionnel. Par rapport aux modèles de codage unidirectionnels traditionnels, BERT peut prendre en compte les informations contextuelles en même temps lors du traitement du texte, de sorte qu'il fonctionne bien dans les tâches de traitement du langage naturel. Sa bidirectionnalité permet à BERT de mieux comprendre les relations sémantiques dans les phrases, améliorant ainsi la capacité expressive du modèle. Grâce à des méthodes de pré-formation et de réglage fin, BERT peut être utilisé pour diverses tâches de traitement du langage naturel, telles que l'analyse des sentiments, la dénomination
 Analyse des fonctions d'activation de l'IA couramment utilisées : pratique d'apprentissage en profondeur de Sigmoid, Tanh, ReLU et Softmax
Dec 28, 2023 pm 11:35 PM
Analyse des fonctions d'activation de l'IA couramment utilisées : pratique d'apprentissage en profondeur de Sigmoid, Tanh, ReLU et Softmax
Dec 28, 2023 pm 11:35 PM
Les fonctions d'activation jouent un rôle crucial dans l'apprentissage profond. Elles peuvent introduire des caractéristiques non linéaires dans les réseaux neuronaux, permettant ainsi au réseau de mieux apprendre et simuler des relations entrées-sorties complexes. La sélection et l'utilisation correctes des fonctions d'activation ont un impact important sur les performances et les résultats de formation des réseaux de neurones. Cet article présentera quatre fonctions d'activation couramment utilisées : Sigmoid, Tanh, ReLU et Softmax, à partir de l'introduction, des scénarios d'utilisation, des avantages, Les inconvénients et les solutions d'optimisation sont abordés pour vous fournir une compréhension complète des fonctions d'activation. 1. Fonction sigmoïde Introduction à la formule de la fonction SIgmoïde : La fonction sigmoïde est une fonction non linéaire couramment utilisée qui peut mapper n'importe quel nombre réel entre 0 et 1. Il est généralement utilisé pour unifier le
 Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Écrit précédemment, nous discutons aujourd'hui de la manière dont la technologie d'apprentissage profond peut améliorer les performances du SLAM (localisation et cartographie simultanées) basé sur la vision dans des environnements complexes. En combinant des méthodes d'extraction de caractéristiques approfondies et de correspondance de profondeur, nous introduisons ici un système SLAM visuel hybride polyvalent conçu pour améliorer l'adaptation dans des scénarios difficiles tels que des conditions de faible luminosité, un éclairage dynamique, des zones faiblement texturées et une gigue importante. Notre système prend en charge plusieurs modes, notamment les configurations étendues monoculaire, stéréo, monoculaire-inertielle et stéréo-inertielle. En outre, il analyse également comment combiner le SLAM visuel avec des méthodes d’apprentissage profond pour inspirer d’autres recherches. Grâce à des expériences approfondies sur des ensembles de données publiques et des données auto-échantillonnées, nous démontrons la supériorité du SL-SLAM en termes de précision de positionnement et de robustesse du suivi.
 Intégration d'espace latent : explication et démonstration
Jan 22, 2024 pm 05:30 PM
Intégration d'espace latent : explication et démonstration
Jan 22, 2024 pm 05:30 PM
L'intégration d'espace latent (LatentSpaceEmbedding) est le processus de mappage de données de grande dimension vers un espace de faible dimension. Dans le domaine de l'apprentissage automatique et de l'apprentissage profond, l'intégration d'espace latent est généralement un modèle de réseau neuronal qui mappe les données d'entrée de grande dimension dans un ensemble de représentations vectorielles de basse dimension. Cet ensemble de vecteurs est souvent appelé « vecteurs latents » ou « latents ». encodages". Le but de l’intégration de l’espace latent est de capturer les caractéristiques importantes des données et de les représenter sous une forme plus concise et compréhensible. Grâce à l'intégration de l'espace latent, nous pouvons effectuer des opérations telles que la visualisation, la classification et le regroupement de données dans un espace de faible dimension pour mieux comprendre et utiliser les données. L'intégration d'espace latent a de nombreuses applications dans de nombreux domaines, tels que la génération d'images, l'extraction de caractéristiques, la réduction de dimensionnalité, etc. L'intégration de l'espace latent est le principal
 Comprendre en un seul article : les liens et les différences entre l'IA, le machine learning et le deep learning
Mar 02, 2024 am 11:19 AM
Comprendre en un seul article : les liens et les différences entre l'IA, le machine learning et le deep learning
Mar 02, 2024 am 11:19 AM
Dans la vague actuelle de changements technologiques rapides, l'intelligence artificielle (IA), l'apprentissage automatique (ML) et l'apprentissage profond (DL) sont comme des étoiles brillantes, à la tête de la nouvelle vague des technologies de l'information. Ces trois mots apparaissent fréquemment dans diverses discussions de pointe et applications pratiques, mais pour de nombreux explorateurs novices dans ce domaine, leurs significations spécifiques et leurs connexions internes peuvent encore être entourées de mystère. Alors regardons d'abord cette photo. On constate qu’il existe une corrélation étroite et une relation progressive entre l’apprentissage profond, l’apprentissage automatique et l’intelligence artificielle. Le deep learning est un domaine spécifique du machine learning, et le machine learning
 Super fort! Top 10 des algorithmes de deep learning !
Mar 15, 2024 pm 03:46 PM
Super fort! Top 10 des algorithmes de deep learning !
Mar 15, 2024 pm 03:46 PM
Près de 20 ans se sont écoulés depuis que le concept d'apprentissage profond a été proposé en 2006. L'apprentissage profond, en tant que révolution dans le domaine de l'intelligence artificielle, a donné naissance à de nombreux algorithmes influents. Alors, selon vous, quels sont les 10 meilleurs algorithmes pour l’apprentissage profond ? Voici les meilleurs algorithmes d’apprentissage profond, à mon avis. Ils occupent tous une position importante en termes d’innovation, de valeur d’application et d’influence. 1. Contexte du réseau neuronal profond (DNN) : Le réseau neuronal profond (DNN), également appelé perceptron multicouche, est l'algorithme d'apprentissage profond le plus courant lorsqu'il a été inventé pour la première fois, jusqu'à récemment en raison du goulot d'étranglement de la puissance de calcul. années, puissance de calcul, La percée est venue avec l'explosion des données. DNN est un modèle de réseau neuronal qui contient plusieurs couches cachées. Dans ce modèle, chaque couche transmet l'entrée à la couche suivante et
 Pratique avancée du graphe de connaissances industrielles
Jun 13, 2024 am 11:59 AM
Pratique avancée du graphe de connaissances industrielles
Jun 13, 2024 am 11:59 AM
1. Introduction au contexte Tout d’abord, présentons l’historique du développement de la technologie Yunwen. Yunwen Technology Company... 2023 est la période où les grands modèles prédominent. De nombreuses entreprises pensent que l'importance des graphiques a été considérablement réduite après les grands modèles et que les systèmes d'information prédéfinis étudiés précédemment ne sont plus importants. Cependant, avec la promotion du RAG et la prévalence de la gouvernance des données, nous avons constaté qu'une gouvernance des données plus efficace et des données de haute qualité sont des conditions préalables importantes pour améliorer l'efficacité des grands modèles privatisés. Par conséquent, de plus en plus d'entreprises commencent à y prêter attention. au contenu lié à la construction des connaissances. Cela favorise également la construction et le traitement des connaissances à un niveau supérieur, où de nombreuses techniques et méthodes peuvent être explorées. On voit que l'émergence d'une nouvelle technologie ne détruit pas toutes les anciennes technologies, mais peut également intégrer des technologies nouvelles et anciennes.
 Comment utiliser les modèles hybrides CNN et Transformer pour améliorer les performances
Jan 24, 2024 am 10:33 AM
Comment utiliser les modèles hybrides CNN et Transformer pour améliorer les performances
Jan 24, 2024 am 10:33 AM
Convolutional Neural Network (CNN) et Transformer sont deux modèles d'apprentissage en profondeur différents qui ont montré d'excellentes performances sur différentes tâches. CNN est principalement utilisé pour les tâches de vision par ordinateur telles que la classification d'images, la détection de cibles et la segmentation d'images. Il extrait les caractéristiques locales de l'image via des opérations de convolution et effectue une réduction de dimensionnalité des caractéristiques et une invariance spatiale via des opérations de pooling. En revanche, Transformer est principalement utilisé pour les tâches de traitement du langage naturel (NLP) telles que la traduction automatique, la classification de texte et la reconnaissance vocale. Il utilise un mécanisme d'auto-attention pour modéliser les dépendances dans des séquences, évitant ainsi le calcul séquentiel dans les réseaux neuronaux récurrents traditionnels. Bien que ces deux modèles soient utilisés pour des tâches différentes, ils présentent des similitudes dans la modélisation des séquences.
