
 Périphériques technologiques
IA
Le raisonnement H100 s'est envolé 8 fois ! NVIDIA a officiellement annoncé TensorRT-LLM open source, prenant en charge plus de 10 modèles
Périphériques technologiques
IA
Le raisonnement H100 s'est envolé 8 fois ! NVIDIA a officiellement annoncé TensorRT-LLM open source, prenant en charge plus de 10 modèles
Le raisonnement H100 s'est envolé 8 fois ! NVIDIA a officiellement annoncé TensorRT-LLM open source, prenant en charge plus de 10 modèles

Les « pauvres GPU » sont sur le point de faire leurs adieux à leur situation difficile !
Tout à l'heure, NVIDIA a publié un logiciel open source appelé TensorRT-LLM, qui peut accélérer le processus d'inférence de grands modèles de langage exécutés sur H100

Alors, combien de fois peut-il être amélioré ?
Après l'ajout de TensorRT-LLM et de sa série de fonctions d'optimisation (y compris le traitement par lots en vol), le débit total du modèle a augmenté de 8 fois.
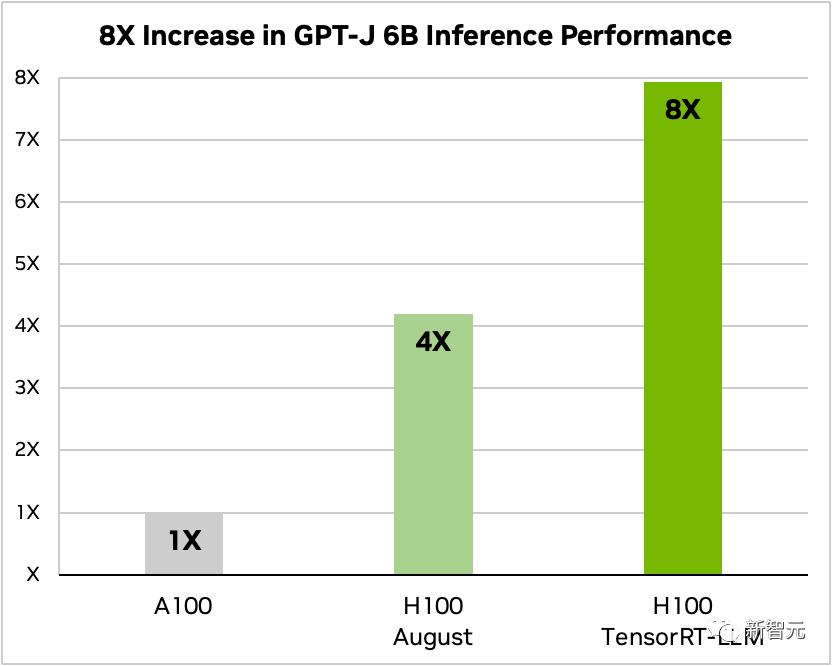
Comparaison des GPT-J-6B A100 et H100 avec et sans TensorRT-LLM
De plus, en prenant Llama 2 comme exemple, TensorRT-LLM peut améliorer les performances d'inférence par rapport à l'utilisation indépendante de A100 Amélioration de 4,6 fois
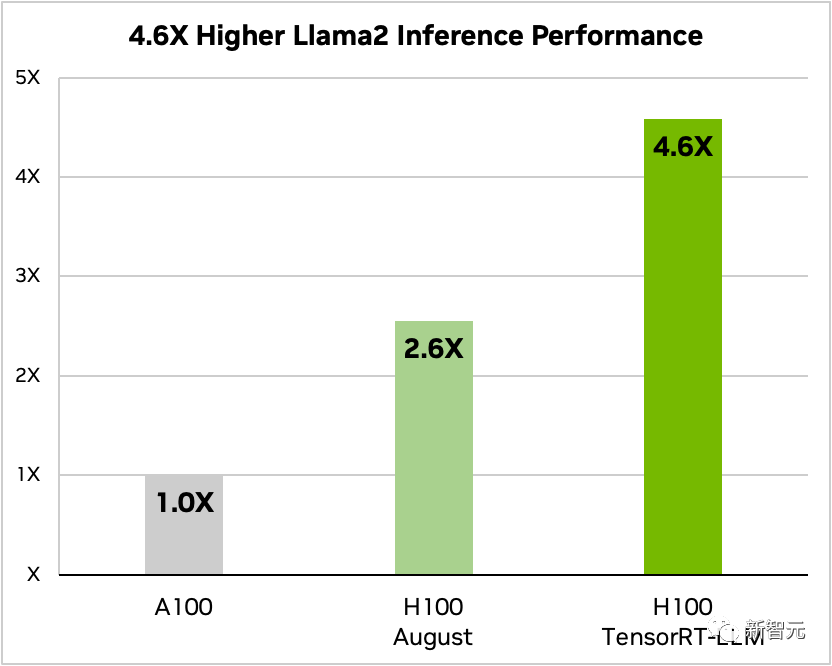
Comparaison de Llama 2 70B, A100 et H100 avec et sans TensorRT-LLM
Les internautes ont dit que le super H100, combiné avec TensorRT-LLM, est sans aucun doute Cela changera complètement le courant situation d'inférence de grand modèle de langage !

TensorRT-LLM : artefact d'accélération d'inférence de grand modèle
Actuellement, en raison de l'énorme échelle de paramètres des grands modèles, la difficulté et le coût du « déploiement et de l'inférence » ont toujours été élevés.
TensorRT-LLM développé par NVIDIA vise à améliorer considérablement le débit de LLM et à réduire les coûts grâce au GPU

Plus précisément, TensorRT-LLM optimise le compilateur d'apprentissage profond de TensorRT et le noyau FasterTransformer, le pré- et post-traitement , et la communication multi-GPU/multi-nœuds sont encapsulés dans une simple API Python open source
NVIDIA a encore amélioré FasterTransformer pour en faire une solution de production.
On peut voir que TensorRT-LLM fournit une interface de programmation d'applications Python facile à utiliser, open source et modulaire.
Les codeurs qui n'ont pas besoin de connaissances approfondies en C++ ou CUDA peuvent déployer, exécuter et déboguer divers modèles de langage à grande échelle, et obtenir d'excellentes performances et une personnalisation rapide

Selon le blog officiel de NVIDIA , TensorRT-LLM adopte quatre méthodes pour améliorer les performances d'inférence LLM sur les GPU Nvidia
Tout d'abord, TensorRT-LLM est introduit pour les plus de 10 grands modèles actuels, permettant aux développeurs de l'exécuter immédiatement.
Deuxièmement, TensorRT-LLM, en tant que bibliothèque logicielle open source, permet à LLM d'effectuer une inférence sur plusieurs GPU et plusieurs serveurs GPU simultanément.
Ces serveurs sont connectés respectivement via les interconnexions NVLink et InfiniBand de NVIDIA.
Le troisième point concerne le "traitement par lots in-machine", qui est une nouvelle technologie de planification qui permet à des tâches de différents modèles d'entrer et de sortir du GPU indépendamment des autres tâches
Enfin, TensorRT-LLM a été optimisé, vous pouvez utiliser le moteur de transformateur H100 pour réduire l'utilisation de la mémoire et la latence lors de l'inférence de modèle.
Examinons en détail comment TensorRT-LLM améliore les performances des modèles
Prend en charge un riche écosystème LLM
TensorRT-LLM fournit un excellent support pour l'écosystème de modèles open source
Ce qui doit être réécrit Oui : Les modèles de langage les plus grands et les plus avancés, tels que Llama 2-70B de Meta, nécessitent que plusieurs GPU travaillent ensemble pour fournir des réponses en temps réel
Auparavant, pour obtenir les meilleures performances d'inférence LLM, les développeurs devaient réécrire manuellement le Modélisez l'IA et décomposez-le en plusieurs morceaux, puis coordonnez l'exécution entre les GPU

TensorRT-LLM utilise la technologie tenseur parallèle pour distribuer la matrice de poids à chaque appareil, simplifiant ainsi le processus et permettant une inférence efficace à grande échelle
Chaque modèle peut être exécuté sur plusieurs appareils connectés via NVLink Fonctionne en parallèle sur plusieurs GPU et plusieurs serveurs sans intervention du développeur ni modification du modèle.
Avec le lancement de nouveaux modèles et architectures de modèles, les développeurs peuvent utiliser le dernier noyau open source NVIDIA AI (Kernal) dans TensorRT-LLM pour optimiser les modèles
Ce qui doit être réécrit est : Noyau pris en charge Fusion inclut la dernière implémentation de FlashAttention, ainsi qu'une attention multi-têtes masquée pour le contexte et les étapes de génération de l'exécution du modèle GPT, etc.
De plus, TensorRT-LLM inclut également de nombreux grands modèles de langage actuellement populaires. version optimisée et prête à l'emploi.
Ces modèles incluent Meta Llama 2, OpenAI GPT-2 et GPT-3, Falcon, Mosaic MPT, BLOOM et plus de dix autres. Tous ces modèles peuvent être appelés à l'aide de l'API Python TensorRT-LLM facile à utiliser
Ces fonctions peuvent aider les développeurs à créer des modèles de langage volumineux personnalisés plus rapidement et avec plus de précision pour répondre aux différents besoins de diverses industries.
Traitement par lots en vol
De nos jours, les grands modèles de langage sont extrêmement polyvalents.
Un modèle peut être utilisé simultanément pour plusieurs tâches apparemment disparates : des simples réponses aux questions-réponses dans un chatbot, au résumé de documents ou à la génération de longs blocs de code, les charges de travail sont très dynamiques et les tailles de sortie doivent être respectées. différents ordres de grandeur.
La diversité des tâches peut rendre difficile le regroupement efficace des requêtes et leur exécution parallèle efficace, ce qui peut entraîner l'exécution de certaines requêtes plus tôt que d'autres.

Pour gérer ces charges dynamiques, TensorRT-LLM inclut une technologie de planification optimisée appelée « In-flight batching ».
Le principe de base des grands modèles de langage est que l'ensemble du processus de génération de texte peut être réalisé via plusieurs itérations du modèle
Avec le traitement par lots en vol, le runtime TensorRT-LLM est immédiatement libéré du lot lorsque il s'agit d'une séquence terminée au lieu d'attendre que l'ensemble du lot soit terminé avant de passer à l'ensemble de requêtes suivant.
Lors de l'exécution d'une nouvelle demande, d'autres demandes du lot précédent qui n'ont pas été complétées sont toujours en cours de traitement.
Utilisation améliorée du GPU grâce au traitement par lots sur la machine et à des optimisations supplémentaires au niveau du noyau, ce qui entraîne au moins le double du débit des tests de requêtes réels pour LLM sur H100
Utilisation du moteur H100 Transformer du FP 8
TensorRT- LLM fournit également une fonctionnalité appelée H100 Transformer Engine, qui peut réduire efficacement la consommation de mémoire et la latence lors de l'inférence de grands modèles.
Étant donné que LLM contient des milliards de poids de modèle et de fonctions d'activation, il est généralement entraîné et représenté avec des valeurs FP16 ou BF16, chacune occupant 16 bits de mémoire.
Cependant, au moment de l'inférence, la plupart des modèles peuvent être représentés efficacement avec une précision moindre à l'aide de techniques de quantification, telles que des entiers de 8 bits ou même de 4 bits (INT8 ou INT4).
La quantification est le processus de réduction du poids du modèle et de la précision d'activation sans sacrifier la précision. L’utilisation d’une précision inférieure signifie que chaque paramètre est plus petit et que le modèle occupe moins d’espace dans la mémoire GPU.

De cette façon, vous pouvez utiliser le même matériel pour déduire des modèles plus grands, tout en réduisant la consommation de temps sur les opérations de mémoire pendant le processus d'exécution
Grâce à la technologie H100 Transformer Engine, combinée à TensorRT-LLM Le H100 Le GPU permet aux utilisateurs de convertir facilement les poids des modèles au nouveau format FP8 et de compiler automatiquement les modèles pour tirer parti des cœurs FP8 optimisés.
Et ce processus ne nécessite aucun codage ! Le format de données FP8 introduit par H100 permet aux développeurs de quantifier leurs modèles et de réduire considérablement la consommation de mémoire sans réduire la précision du modèle.
Par rapport à d'autres formats de données tels que INT8 ou INT4, la quantification FP8 conserve une plus grande précision tout en atteignant les performances les plus rapides et est la plus pratique à mettre en œuvre. Par rapport à d'autres formats de données tels que INT8 ou INT4, la quantification FP8 conserve une plus grande précision tout en atteignant les performances les plus rapides et est la plus pratique à mettre en œuvre
Comment obtenir TensorRT-LLM
Bien que TensorRT-LLM ne soit pas encore officiel, mais les utilisateurs peuvent désormais en faire l'expérience à l'avance
Le lien de l'application est le suivant :
https://developer.nvidia.com/tensorrt-llm-early-access/join
Nvidia l'a également dit Will TensorRT-LLM a été rapidement intégré au framework NVIDIA NeMo.
Ce framework fait partie de AI Enterprise récemment lancé par NVIDIA, offrant aux entreprises clientes une plate-forme logicielle d'IA de niveau entreprise sécurisée, stable et hautement gérable
Les développeurs et les chercheurs peuvent utiliser le framework NeMo sur NVIDIA NGC ou un projet sur GitHub pour accéder à TensorRT-LLM
Cependant, il convient de noter que les utilisateurs doivent s'inscrire au programme pour développeurs NVIDIA pour postuler à la version à accès anticipé.
Discussion animée parmi les internautes
Les utilisateurs de Reddit ont eu une discussion animée sur la sortie de TensorRT-LLM
Il est difficile d'imaginer à quel point l'effet sera amélioré après l'optimisation du matériel spécifiquement pour LLM.

Mais certains internautes pensent que le but de cette chose est d'aider Lao Huang à vendre plus de H100.
Certains internautes ont des opinions différentes à ce sujet. Ils pensent que Tensor RT est également utile pour les utilisateurs qui déploient un apprentissage profond localement. Tant que vous disposez d'un GPU RTX, vous pourrez également bénéficier de produits similaires à l'avenir

D'un point de vue plus macro, peut-être pour LLM, il y aura une série de mesures d'optimisation spécifiquement au niveau matériel, et peut-être même que du matériel spécialement conçu pour LLM est apparu pour améliorer ses performances. Cette situation s'est produite dans de nombreuses applications populaires, et LLM ne fait pas exception
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 Le modèle de dialogue NVIDIA ChatQA a évolué vers la version 2.0, avec la longueur du contexte mentionnée à 128 Ko
Jul 26, 2024 am 08:40 AM
Le modèle de dialogue NVIDIA ChatQA a évolué vers la version 2.0, avec la longueur du contexte mentionnée à 128 Ko
Jul 26, 2024 am 08:40 AM
La communauté ouverte LLM est une époque où une centaine de fleurs fleurissent et s'affrontent. Vous pouvez voir Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 et bien d'autres. excellents interprètes. Cependant, par rapport aux grands modèles propriétaires représentés par le GPT-4-Turbo, les modèles ouverts présentent encore des lacunes importantes dans de nombreux domaines. En plus des modèles généraux, certains modèles ouverts spécialisés dans des domaines clés ont été développés, tels que DeepSeek-Coder-V2 pour la programmation et les mathématiques, et InternVL pour les tâches de langage visuel.
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
 « AI Factory » favorisera la refonte de l'ensemble de la pile logicielle, et NVIDIA fournit des conteneurs Llama3 NIM que les utilisateurs peuvent déployer
Jun 08, 2024 pm 07:25 PM
« AI Factory » favorisera la refonte de l'ensemble de la pile logicielle, et NVIDIA fournit des conteneurs Llama3 NIM que les utilisateurs peuvent déployer
Jun 08, 2024 pm 07:25 PM
Selon les informations de ce site le 2 juin, lors du discours d'ouverture du Huang Renxun 2024 Taipei Computex, Huang Renxun a présenté que l'intelligence artificielle générative favoriserait la refonte de l'ensemble de la pile logicielle et a démontré ses microservices cloud natifs NIM (Nvidia Inference Microservices). . Nvidia estime que « l'usine IA » déclenchera une nouvelle révolution industrielle : en prenant comme exemple l'industrie du logiciel lancée par Microsoft, Huang Renxun estime que l'intelligence artificielle générative favorisera sa refonte complète. Pour faciliter le déploiement de services d'IA par les entreprises de toutes tailles, NVIDIA a lancé les microservices cloud natifs NIM (Nvidia Inference Microservices) en mars de cette année. NIM+ est une suite de microservices cloud natifs optimisés pour réduire les délais de commercialisation
 Une seule carte exécute Llama 70B plus rapidement que deux cartes, Microsoft vient de mettre le FP6 dans l'Open source A100 |
Apr 29, 2024 pm 04:55 PM
Une seule carte exécute Llama 70B plus rapidement que deux cartes, Microsoft vient de mettre le FP6 dans l'Open source A100 |
Apr 29, 2024 pm 04:55 PM
Le FP8 et la précision de quantification inférieure en virgule flottante ne sont plus le « brevet » du H100 ! Lao Huang voulait que tout le monde utilise INT8/INT4, et l'équipe Microsoft DeepSpeed a commencé à exécuter FP6 sur A100 sans le soutien officiel de NVIDIA. Les résultats des tests montrent que la quantification FP6 de la nouvelle méthode TC-FPx sur A100 est proche ou parfois plus rapide que celle de INT4, et a une précision supérieure à celle de cette dernière. En plus de cela, il existe également une prise en charge de bout en bout des grands modèles, qui ont été open source et intégrés dans des cadres d'inférence d'apprentissage profond tels que DeepSpeed. Ce résultat a également un effet immédiat sur l'accélération des grands modèles : dans ce cadre, en utilisant une seule carte pour exécuter Llama, le débit est 2,65 fois supérieur à celui des cartes doubles. un
 Aucune donnée OpenAI requise, rejoignez la liste des grands modèles de code ! UIUC publie StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Aucune donnée OpenAI requise, rejoignez la liste des grands modèles de code ! UIUC publie StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
À la pointe de la technologie logicielle, le groupe de l'UIUC Zhang Lingming, en collaboration avec des chercheurs de l'organisation BigCode, a récemment annoncé le modèle de grand code StarCoder2-15B-Instruct. Cette réalisation innovante a permis une percée significative dans les tâches de génération de code, dépassant avec succès CodeLlama-70B-Instruct et atteignant le sommet de la liste des performances de génération de code. Le caractère unique de StarCoder2-15B-Instruct réside dans sa stratégie d'auto-alignement pur. L'ensemble du processus de formation est ouvert, transparent et complètement autonome et contrôlable. Le modèle génère des milliers d'instructions via StarCoder2-15B en réponse au réglage fin du modèle de base StarCoder-15B sans recourir à des annotations manuelles coûteuses.
 Surpassant largement le DPO : l'équipe de Chen Danqi a proposé une optimisation simple des préférences SimPO et a également affiné le modèle open source 8B le plus puissant.
Jun 01, 2024 pm 04:41 PM
Surpassant largement le DPO : l'équipe de Chen Danqi a proposé une optimisation simple des préférences SimPO et a également affiné le modèle open source 8B le plus puissant.
Jun 01, 2024 pm 04:41 PM
Afin d'aligner les grands modèles de langage (LLM) sur les valeurs et les intentions humaines, il est essentiel d'apprendre les commentaires humains pour garantir qu'ils sont utiles, honnêtes et inoffensifs. En termes d'alignement du LLM, une méthode efficace est l'apprentissage par renforcement basé sur le retour humain (RLHF). Bien que les résultats de la méthode RLHF soient excellents, certains défis d’optimisation sont impliqués. Cela implique de former un modèle de récompense, puis d'optimiser un modèle politique pour maximiser cette récompense. Récemment, certains chercheurs ont exploré des algorithmes hors ligne plus simples, dont l’optimisation directe des préférences (DPO). DPO apprend le modèle politique directement sur la base des données de préférence en paramétrant la fonction de récompense dans RLHF, éliminant ainsi le besoin d'un modèle de récompense explicite. Cette méthode est simple et stable
