
 Périphériques technologiques
Industrie informatique
Détection des anomalies : minimisez les faux positifs grâce au moteur de règles
Périphériques technologiques
Industrie informatique
Détection des anomalies : minimisez les faux positifs grâce au moteur de règles
Détection des anomalies : minimisez les faux positifs grâce au moteur de règles

Les anomalies sont des écarts par rapport aux modèles attendus et peuvent survenir dans divers environnements, qu'il s'agisse de transactions bancaires, d'opérations industrielles, du secteur du marketing ou de la surveillance des soins de santé. Les méthodes de détection traditionnelles produisent souvent des taux élevés de fausses alarmes. Un faux positif se produit lorsqu'un système identifie à tort un événement de routine comme une anomalie, ce qui entraîne des efforts d'enquête inutiles et des retards opérationnels. Cette inefficacité est un problème urgent car elle draine des ressources et détourne l’attention des véritables problèmes qui doivent être résolus. Cet article examine en profondeur une approche spécialisée de la détection des anomalies qui utilise largement les moteurs basés sur des règles. Cette approche améliore la précision de l’identification des violations en croisant plusieurs indicateurs de performance clés (KPI). Non seulement cette approche peut vérifier ou réfuter plus efficacement la présence d’une anomalie, mais elle peut parfois également isoler et identifier la cause profonde du problème.
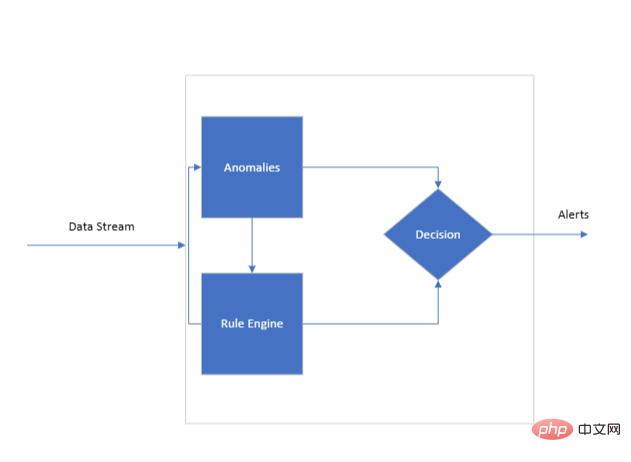
Présentation de l'architecture du système
Flux de données
Il s'agit d'un flux de données continu pour l'examen du moteur. Chaque point du flux peut être associé à un ou plusieurs KPI utilisés par le moteur de règles pour évaluer son ensemble de règles de formation. Un flux continu de données est essentiel pour une surveillance en temps réel, fournissant au moteur les informations nécessaires à son fonctionnement.
Architecture du moteur de règles
Au cœur du système se trouve le moteur de règles, qui doit être formé pour comprendre les nuances des KPI qu'il surveillera. C’est là qu’un ensemble de règles KPI entre en jeu. Ces règles servent de base algorithmique au moteur et sont conçues pour corréler deux ou plusieurs KPI entre eux.
Types de règles KPI :
- Qualité des données : règles qui se concentrent sur la cohérence, l'exactitude et la fiabilité du flux de données.
- Corrélation KPI : règles qui se concentrent sur la corrélation de certains KPI
Processus d'application des règles
Après avoir reçu les données, le moteur recherche immédiatement les écarts ou anomalies dans les KPI entrants. Une anomalie fait ici référence à toute mesure qui se situe en dehors d’une plage acceptable prédéterminée. Le moteur signale ces anomalies pour une enquête plus approfondie, qui peut être divisée en trois opérations principales : accepter, rejeter et affiner. Cela peut impliquer de corréler un KPI avec un autre pour valider ou infirmer une anomalie détectée.
Méthode
Formation de règles
Les étapes de base consistent à créer une série de règles qui relient plusieurs KPI les uns aux autres. Par exemple, une règle peut associer les mesures de qualité d’un produit à la vitesse de production dans une usine. Par exemple :
- Relation directe entre KPI : Une « relation directe » entre deux KPI signifie que lorsqu'un KPI augmente, l'autre KPI augmente également, ou lorsqu'un KPI diminue, l'autre diminue également. Par exemple, dans un commerce de détail, une augmentation des dépenses publicitaires (KPI1) peut être directement liée à une augmentation du chiffre d'affaires (KPI2). Dans ce cas, une augmentation de l’un des aspects a un impact positif sur l’autre. Ces connaissances sont inestimables pour les entreprises car elles facilitent la planification stratégique et l'allocation des ressources.
- Relation inverse entre les KPI : En revanche, une « relation inverse » signifie que lorsqu'un KPI augmente, l'autre KPI diminue et vice versa. Par exemple, dans un environnement manufacturier, le temps nécessaire pour fabriquer un produit (KPI1) peut avoir une relation inverse avec la productivité (KPI2). À mesure que le temps de production est réduit, la productivité peut augmenter. Comprendre la relation inverse est également essentiel pour l'optimisation de l'entreprise, car elle peut nécessiter des mesures d'équilibrage pour optimiser les deux KPI.
- Combinez des KPI pour créer de nouvelles règles : il peut parfois être avantageux de combiner deux ou plusieurs KPI pour créer une nouvelle mesure pouvant fournir des informations précieuses sur les performances de l'entreprise. Par exemple, la combinaison de la valeur à vie du client (KPI1) et du coût d'acquisition client (KPI2) donne un troisième KPI : le rapport valeur/coût du client. Ce nouveau KPI permet de mieux comprendre si le coût d'acquisition d'un nouveau client est proportionnel à la valeur qu'il apporte au fil du temps.
Moteur de règles de formation
Le moteur de règles est entièrement formé pour appliquer efficacement ces règles en temps réel.
Révision en temps réel
Le moteur de règles surveille de manière proactive les données entrantes, en appliquant ses règles entraînées pour identifier les anomalies ou anomalies potentielles.
Prise de décision
En identifiant les anomalies potentielles, le moteur :
- Acceptation des exceptions : phase de confirmation : une fois qu'une exception est signalée, le moteur la comparera avec d'autres KPI associés à l'aide de ses règles KPI pré-entraînées. Le point ici est de déterminer si l’anomalie est réellement un problème ou simplement une valeur aberrante. Cette confirmation est effectuée sur la base de la corrélation entre les KPI primaires et secondaires.
- Rejet des exceptions : phase de faux positifs : toutes les exceptions n'indiquent pas un problème ; certaines peuvent être des valeurs aberrantes statistiques ou des erreurs de données. Dans ce cas, le moteur utilise son entraînement pour rejeter l’anomalie, l’identifiant essentiellement comme un faux positif. Ceci est essentiel pour éliminer la fatigue inutile des alertes et concentrer les ressources sur le véritable problème.
- Réduire la portée de l'anomalie : Phase de raffinement : Parfois, une anomalie peut faire partie d'un problème plus vaste qui affecte plusieurs composants. Ici, le moteur identifie davantage la nature exacte du problème en le limitant à des composants KPI spécifiques. Ce filtrage avancé permet d'identifier rapidement les problèmes et de résoudre les causes profondes.
Avantages
- Réduire les faux positifs : En utilisant un moteur de règles qui croise plusieurs KPI, le système réduit considérablement l'incidence des faux positifs.
- Efficacité en termes de temps et de coûts : les anomalies sont détectées et résolues plus rapidement, réduisant ainsi le temps opérationnel et les coûts associés.
- Précision améliorée : la possibilité de comparer et de contraster plusieurs KPI permet une représentation plus granulaire et précise des événements anormaux.
Conclusion
Cet article décrit une approche de détection des anomalies à l'aide d'un moteur de règles formé sur divers ensembles de règles KPI. Contrairement aux systèmes traditionnels de détection d’anomalies, qui s’appuient souvent uniquement sur des algorithmes statistiques ou des modèles d’apprentissage automatique, cette approche utilise un moteur de règles spécialisé comme pierre angulaire. En approfondissant les relations et les interactions entre les différents KPI, les entreprises peuvent obtenir des informations plus granulaires que des mesures simples et autonomes ne peuvent pas fournir. Cela permet une planification stratégique plus solide, une meilleure gestion des risques et une approche globale plus efficace pour atteindre les objectifs commerciaux. Une fois qu'une anomalie est signalée, le moteur la compare à d'autres KPI associés à l'aide de ses règles KPI pré-entraînées. Le point ici est de déterminer si l’anomalie est réellement un problème ou simplement une valeur aberrante.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment utiliser PHP pour mettre en œuvre la détection des anomalies et l'analyse des fraudes
Jul 30, 2023 am 09:42 AM
Comment utiliser PHP pour mettre en œuvre la détection des anomalies et l'analyse des fraudes
Jul 30, 2023 am 09:42 AM
Comment utiliser PHP pour mettre en œuvre la détection d'anomalies et l'analyse de la fraude Résumé : Avec le développement du commerce électronique, la fraude est devenue un problème incontournable. Cet article explique comment utiliser PHP pour implémenter la détection des anomalies et l'analyse des fraudes. En collectant des données de transaction et des données comportementales des utilisateurs, combinées à des algorithmes d'apprentissage automatique, le comportement des utilisateurs est surveillé et analysé en temps réel dans le système, une fraude potentielle est identifiée et des mesures correspondantes sont prises pour y faire face. Mots clés : PHP, détection d'anomalies, analyse de fraude, machine learning 1. Introduction Avec le développement rapide du commerce électronique, le nombre de transactions que les gens effectuent sur Internet
 Surveillance des performances de sécurité Nginx et détection des anomalies
Jun 10, 2023 pm 04:15 PM
Surveillance des performances de sécurité Nginx et détection des anomalies
Jun 10, 2023 pm 04:15 PM
Nginx est un logiciel serveur HTTP gratuit, open source, performant et léger, largement utilisé sur Internet. Cependant, comme Nginx fait souvent face au réseau public et est responsable de services Web importants, il doit effectuer régulièrement une surveillance des performances de sécurité et une détection des anomalies, et prendre des mesures de sécurité efficaces en temps opportun pour garantir le fonctionnement normal du site Web et la sécurité de données. 1. Surveillance des performances de sécurité de Nginx La surveillance des performances de sécurité de Nginx comprend principalement les aspects suivants : (1) Surveillance des journaux d'accès de Nginx Nginx
 Surveillance des journaux MySQL : comment détecter et analyser rapidement les erreurs et exceptions MySQL
Jun 15, 2023 pm 09:42 PM
Surveillance des journaux MySQL : comment détecter et analyser rapidement les erreurs et exceptions MySQL
Jun 15, 2023 pm 09:42 PM
Avec l'avènement d'Internet et de l'ère du Big Data, la base de données MySQL, en tant que système de gestion de base de données open source couramment utilisé, est adoptée par de plus en plus d'entreprises et d'organisations. Cependant, dans le processus de candidature réel, diverses erreurs et exceptions peuvent survenir dans la base de données MySQL, telles que des pannes du système, des délais d'expiration des requêtes, des blocages, etc. Ces anomalies auront un impact sérieux sur la stabilité du système et l'intégrité des données. Par conséquent, détecter et analyser rapidement les erreurs et anomalies MySQL est une tâche très importante. La surveillance des journaux est une fonction importante de MySQL
 Exemples de détection d'anomalies en Python
Jun 09, 2023 pm 09:33 PM
Exemples de détection d'anomalies en Python
Jun 09, 2023 pm 09:33 PM
Python est un langage de programmation de haut niveau, facile à apprendre et puissant. En raison de sa grande lisibilité, de sa petite quantité de code et de sa maintenance facile, il est largement utilisé dans le calcul scientifique, l'analyse de données, l'intelligence artificielle et d'autres domaines. Cependant, tout langage de programmation rencontrera des erreurs et des exceptions, c'est pourquoi Python fournit également un mécanisme d'exception afin que les développeurs puissent mieux gérer ces situations. Cet article présentera comment utiliser le mécanisme de détection d'anomalies en Python et donnera quelques exemples. 1. Types d'exceptions en Python dans Py
 Meilleures pratiques et sélection d'algorithmes pour la validation de la fiabilité des données et l'évaluation des modèles en Python
Oct 27, 2023 pm 12:01 PM
Meilleures pratiques et sélection d'algorithmes pour la validation de la fiabilité des données et l'évaluation des modèles en Python
Oct 27, 2023 pm 12:01 PM
Comment effectuer les meilleures pratiques et la sélection d'algorithmes pour la vérification de la fiabilité des données et l'évaluation du modèle en Python Introduction : Dans le domaine de l'apprentissage automatique et de l'analyse des données, la vérification de la fiabilité des données et l'évaluation des performances du modèle sont des tâches très importantes. En vérifiant la fiabilité des données, la qualité et l'exactitude des données peuvent être garanties, améliorant ainsi le pouvoir prédictif du modèle. L'évaluation des modèles peut nous aider à sélectionner les meilleurs modèles et à déterminer leurs performances. Cet article présentera les meilleures pratiques et les choix d'algorithmes pour la vérification de la fiabilité des données et l'évaluation des modèles en Python.
 Problème de détection d'anomalies basé sur des séries chronologiques
Oct 09, 2023 pm 04:33 PM
Problème de détection d'anomalies basé sur des séries chronologiques
Oct 09, 2023 pm 04:33 PM
Le problème de la détection d'anomalies basée sur des séries chronologiques nécessite des exemples de code spécifiques. Les données de séries chronologiques sont des données enregistrées dans un certain ordre au fil du temps, telles que les cours des actions, les changements de température, le flux de trafic, etc. Dans les applications pratiques, la détection d’anomalies dans les données de séries chronologiques revêt une grande importance. Une valeur aberrante peut être une valeur extrême incompatible avec des données normales, du bruit, des données erronées ou un événement inattendu dans une situation spécifique. La détection des anomalies peut nous aider à découvrir ces anomalies et à prendre les mesures appropriées. Pour les problèmes de détection d'anomalies de séries chronologiques, couramment utilisés
 Python pour l'analyse de séries chronologiques : prévision et détection d'anomalies
Aug 31, 2023 pm 08:09 PM
Python pour l'analyse de séries chronologiques : prévision et détection d'anomalies
Aug 31, 2023 pm 08:09 PM
Python est devenu le langage de choix des data scientists et des analystes, offrant des bibliothèques et des outils complets d'analyse de données. Python excelle notamment dans l’analyse de séries chronologiques et excelle dans la prévision et la détection d’anomalies. Grâce à sa simplicité, sa polyvalence et sa solide prise en charge des techniques statistiques et d'apprentissage automatique, Python fournit une plate-forme idéale pour extraire des informations précieuses à partir de données dépendantes du temps. Cet article explore les capacités supérieures de Python en matière d'analyse de séries chronologiques, en se concentrant sur la prévision et la détection des anomalies. En approfondissant les aspects pratiques de ces tâches, nous soulignons comment les bibliothèques et les outils de Python permettent une prévision et une identification précises des anomalies dans les données de séries chronologiques. À travers des exemples concrets et des contributions démonstratives
 Comment implémenter un algorithme de détection d'anomalies en C#
Sep 19, 2023 am 08:09 AM
Comment implémenter un algorithme de détection d'anomalies en C#
Sep 19, 2023 am 08:09 AM
Comment implémenter l'algorithme de détection d'anomalies en C# nécessite des exemples de code spécifiques Introduction : Dans la programmation C#, la gestion des exceptions est une partie très importante. Lorsque des erreurs ou des situations inattendues se produisent dans le programme, le mécanisme de gestion des exceptions peut nous aider à gérer ces erreurs avec élégance pour garantir la stabilité et la fiabilité du programme. Cet article présentera en détail comment implémenter des algorithmes de détection d'anomalies en C# et donnera des exemples de code spécifiques. 1. Connaissance de base de la gestion des exceptions Définition et classification des exceptions Les exceptions sont des erreurs ou des situations inattendues rencontrées lors de l'exécution d'un programme, qui perturbent le flux d'exécution normal du programme.
