
在常见的图像编辑操作中,图像合成是指将一张图片的前景物体与另一张背景图片结合,生成一张合成图的过程。合成后的图像在视觉效果上类似于将前景物体从一张图片传送到另一张背景图片上,如下图所示

图像合成在艺术创作、海报设计、电子商务、虚拟现实、数据增广等领域被广泛使用
通过简单的剪切粘贴得到的合成图可能会存在很多问题。在之前的研究工作中,图像合成衍生出不同的子任务,分别解决不同的子问题。举例来说,图像混合旨在解决前景和背景之间不自然的边界。图像和谐化旨在调整前景的光照使其与背景和谐。视角调整旨在调整前景的姿态,使其与背景匹配。物体放置旨在为前景物体预测合适的位置、大小、透视角度。阴影生成旨在为前景物体在背景上生成合理的阴影
根据下图所示,之前的研究工作以串行或并行的方式执行上述子任务,以获得逼真自然的合成图像。在串行框架中,我们可以根据实际需求有选择性地执行部分子任务
在并行框架下,目前流行的方法是使用扩散模型。它接受一张带有前景边界框的背景图片和一张前景物体图片作为输入,直接生成最终的合成图像。这样可以使得前景物体与背景图片无缝融合,光照和阴影效果合理,姿态与背景相适应
这个并行框架相当于同时执行多个子任务,无法有选择性地执行部分子任务,不具有可控性,可能会对前景物体的姿态或者颜色带来不必要或者不合理的改变
需要重写的是:

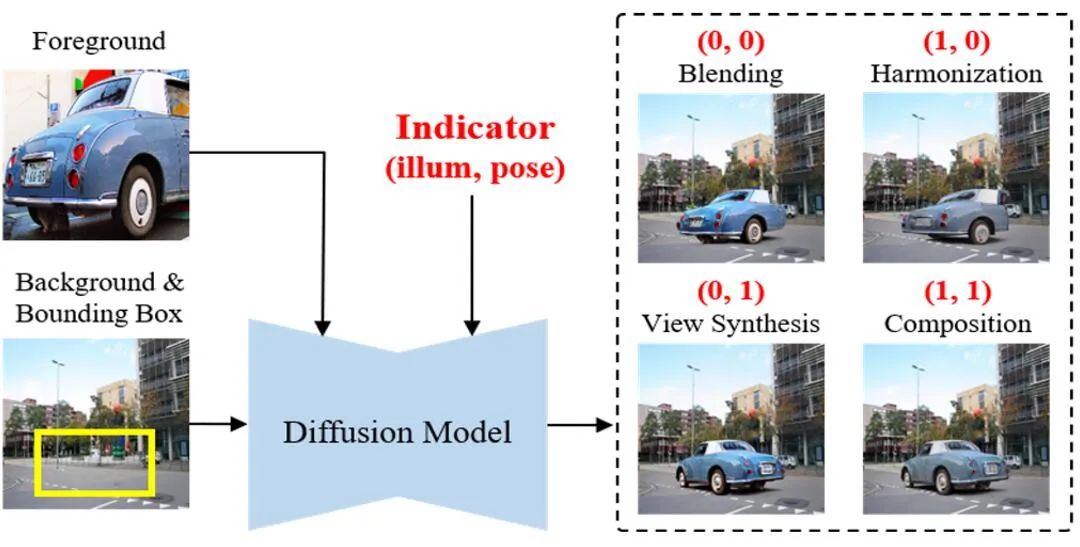
为了增强并行框架的可控性并有选择性地执行部分子任务,我们提出了可控图像合成模型 Controllable Image Composition (ControlCom)。如下图所示,我们使用一个指示向量作为扩散模型的条件信息,以控制合成图中前景物体的属性。指示向量是一个二维的二值向量,其中每个维度分别控制是否调整前景物体的光照属性和姿态属性,其中1表示调整,0表示保留
具体来说,(0,0)表示既不改变前景光照,也不改变前景姿态,只是将物体无缝融入背景图片,相当于图像混合(image blending)。(1,0)表示只改变前景光照使其与背景和谐,保留前景姿态,相当于图像和谐化(image harmonization)。(0,1)表示只改变前景姿态使其与背景匹配,保留前景光照,相当于视角调整(view synthesis)。(1,1)表示同时改变前景的光照和姿态,相当于现在的不可控并行图像合成
我们将四种任务纳入同一个框架,通过指示向量实现了四合一物体传送门的功能,可以将物体传送到场景中的指定位置。这项工作是由上海交通大学和蚂蚁集团合作完成的,代码和模型即将开源

请点击以下链接查看论文:https://arxiv.org/abs/2308.10040
代码模型链接:https://github.com/bcmi/ControlCom-Image-Composition
在下面的图中,我们展示了可控图像合成的功能
左边一列,前景物体的姿态原本就和背景图片适配,用户可能希望保留前景物体的姿态。之前的方法 PbE [1]、ObjectStitch [2] 会对前景物体的姿态做出不必要且不可控的改变。我们方法的 (1,0) 版本能够保留前景物体的姿态,将前景物体无缝融入背景图片且光照和谐
右侧的一列中,前景物体的光照本应与背景光照相同。以往的方法可能会导致前景物体的颜色发生意外的变化,例如车辆和服装的颜色。我们的方法(版本0.1)能够保留前景物体的颜色,并同时调整其姿态,使其自然地融入背景图片中

接下来,我们展示更多我们方法四个版本 (0,0),(1,0),(0,1),(1,1) 的结果。可以看出在使用不同指示向量的情况下,我们的方法能够有选择性地调整前景物体的部分属性,有效控制合成图的效果,满足用户不同的需求。

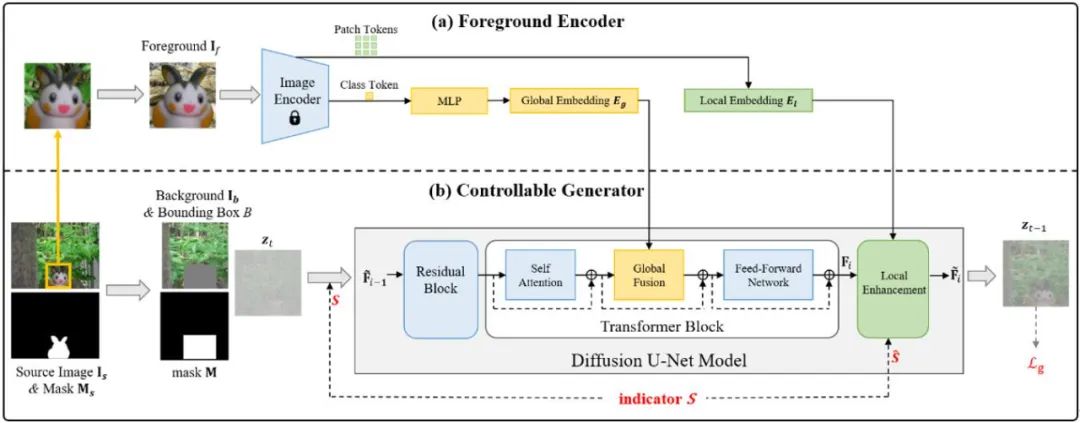
我们需要重新写的内容是:能够实现四种功能的模型结构是什么样的呢?我们的方法采用了以下模型结构,模型的输入包括带有前景边界框的背景图片和前景物体图片,将前景物体的特征和指示向量结合到扩散模型中
我们重新提取了前景物体的全局特征和局部特征,并先融合全局特征,再融合局部特征。在局部融合的过程中,我们使用了对齐的前景特征图进行特征调制,以实现更好的细节保留。同时,在全局融合和局部融合中都使用了指示向量,以更充分地控制前景物体的属性
我们使用预训练的稳定扩散算法,基于OpenImage的190万张图片来训练模型。为了同时训练四个子任务,我们设计了一套数据处理和增强的流程。有关数据和训练的详细信息,请参阅论文
我们在COCOEE数据集和自己构建的数据集上进行了测试。由于之前的方法只能实现不可控的图像合成,所以我们与(1,1)版本和之前的方法进行了比较。比较结果如下图所示,PCTNet是一种图像和谐化方法,能够保留物体的细节,但不能调整前景的姿态,也不能补全前景物体。其他方法能够生成相同种类的物体,但在细节保留方面效果较差,例如衣服的款式、杯子的纹理、鸟的羽毛颜色等等
我们的方法相比之下能够更好地保留前景物体的细节,补全不完整的前景物体,并且调整前景物体的光照、姿势以及与背景的适配

这项工作是对可控图像合成的首次尝试,任务非常困难,仍然存在许多不足之处,模型的表现不够稳定和鲁棒。此外,除了光照和姿态之外,前景物体的属性还可以进一步细化,如何实现更细粒度的可控图像合成是一个更具挑战性的任务
为了保持原意不变,需要重写的内容是:参考文献
杨,古,张,张,陈,孙,陈,文(2023年)。以示例为基础的图像编辑与扩散模型。在CVPR中
[2] 宋永忠,张智,林志龙,科恩,S. D.,普莱斯,B. L.,张静,金素英,阿里亚加,D. G. 2023。ObjectStitch:生成式物体合成。在CVPR中
以上就是「场景控制传送门:四合一物体传送,上交&蚂蚁出品」的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告![ThinkPHP5快速开发企业站点[全程实录]](https://img.php.cn/upload/course/000/000/068/6253d918a3ce7278.png)


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号




 840
840























