
 Périphériques technologiques
IA
Nouvel élan pour les mises à niveau de l'IA ; anxiété liée aux applications des grands modèles, comment Baidu le résout ; Wang Xiaochuan publie un grand modèle open source 丨AI New Retail Morning News ;
Périphériques technologiques
IA
Nouvel élan pour les mises à niveau de l'IA ; anxiété liée aux applications des grands modèles, comment Baidu le résout ; Wang Xiaochuan publie un grand modèle open source 丨AI New Retail Morning News ;
Nouvel élan pour les mises à niveau de l'IA ; anxiété liée aux applications des grands modèles, comment Baidu le résout ; Wang Xiaochuan publie un grand modèle open source 丨AI New Retail Morning News ;


Observation marketing de l'IA
《Le stockage, nouveau moteur de l'évolution de l'IA》
À l'ère des grands modèles, le stockage nécessite non seulement de grandes quantités et une haute qualité, mais nécessite également de fortes performances, une bonne stabilité et des économies d'énergie. Fournir des mesures de support de stockage pour l'IA : en prenant en charge tous les types de protocoles de stockage, nous pouvons réaliser l'adaptation et la fusion intelligentes de données multi-protocoles dans plusieurs scénarios ; en réalisant un accès direct aux données par des puces intelligentes, nous pouvons améliorer le chargement et le traitement des données ; définit pendant le processus de formation. (Source : compte officiel WeChat "Yuanchuan Technology Review")
"L'ambition IA d'Apple : conflits internes, contre-attaques et défis"
Après le lancement d'iOS 10 par Apple en 2016, Apple a lancé une nouvelle contre-attaque de l'IA, qui se reflète principalement sous deux aspects : l'intégration verticale et la combinaison de logiciels et de matériel. Apple a investi dans plusieurs domaines de l'IA, tels que la reconnaissance vocale, la reconnaissance faciale, etc., et a intégré des fonctions d'IA dans ses produits et services. Mesures : Il est nécessaire de trouver un équilibre entre la protection de la vie privée des utilisateurs et l'amélioration de la puissance de calcul, tout en répondant aux attaques des géants de la technologie tels que Google et Microsoft contre les grands modèles d'IA. (Source : compte public WeChat "Chuangye Bang")
《RLHF ne nécessite plus d'annotation humaine, Google propose une génération de feedback basée sur l'IA : l'effet est comparable à l'annotation humaine》
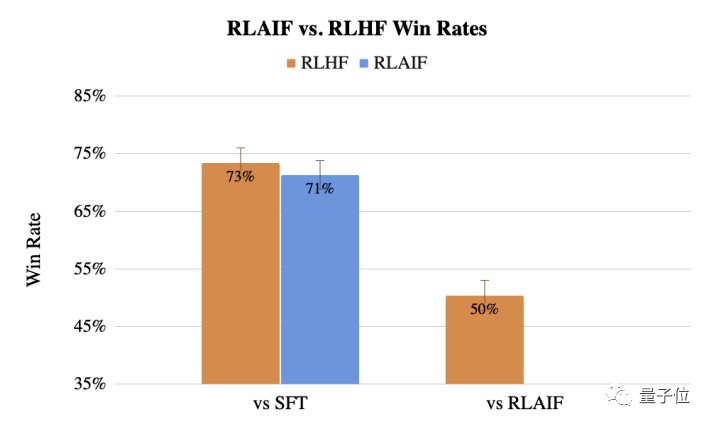
RLAIF est une méthode de génération de feedback basée sur l'IA qui peut remplacer le feedback humain dans RLHF, de sorte que la formation de grands modèles ne soit plus soumise aux limitations humaines. RLAIF utilise LLM pour générer des données de rétroaction, puis utilise une version modifiée de l'algorithme A2C pour effectuer un apprentissage par renforcement et entraîner le modèle cible. Les performances de RLAIF sur les tâches de résumé de texte sont comparables à celles de RLHF, et même meilleures dans certains détails. (Source : compte officiel WeChat "Xi Xiaoyao Technology Talk")
Observation sur application grand modèle
《Comment Baidu résout-il l'anxiété d'application des grands modèles ? 》
La grande industrie du mannequinat est confrontée au manque de couche d'application et à la perte d'intérêt des utilisateurs, et doit passer du « taquin » à l'innovation qui peut véritablement changer la vie et le travail. Initiatives Baidu : le concours d'entrepreneuriat « Wenxin Cup » a été organisé pour fournir aux équipes participantes l'interface API Wenxin Big Model, les ressources informatiques Baidu Intelligent Cloud et un soutien à l'investissement ; le Wenxin Big Model a été utilisé pour reconstruire Baidu Search et d'autres séries avec plus de 100 millions ; les utilisateurs. (Source : compte officiel WeChat "Alphabet List")
《Dialogue Shen Dou : Il existe de nombreux grands modèles sur le marché aujourd'hui, mais la plupart d'entre eux disparaîtront rapidement》La grande industrie du mannequin doit se tourner vers des innovations qui peuvent changer la vie et le travail, et Baidu à travers Wen Plateforme Xinyiyan et Qianfan, répondant aux besoins du côté C et du côté B. Avantages de Baidu dans la recherche et le développement de la technologie des grands modèles : Wenxin Large Model 3.5 présente une amélioration de 50 % de l'effet de modèle, une multiplication par 2 de la vitesse d'entraînement et une multiplication par 17 de la vitesse d'inférence, réduisant considérablement les coûts d'inférence et permettant à Baidu d'héberger un un plus grand nombre d'utilisateurs. (Source : compte public WeChat « Geek Park »)
《Baichuan Intelligent a publié Baichuan2, Wang Xiaochuan : L'ère des entreprises chinoises utilisant LLaMA2 est révolue|Jiazi Discovery》
Caractéristiques : prend en charge des dizaines de langues telles que le chinois, l'anglais, l'espagnol et le français ; sélectionne et filtre des données industrielles verticales de haute qualité basées sur des milliards de données Internet ; crée un système de regroupement de contenu à très grande échelle pour compléter des centaines de données ; des milliards de données horaires de nettoyage et de filtrage ; système de notation de la qualité du contenu multi-granularité. Perspectives : un modèle de paramètres de 100 milliards d'analyse comparative GPT-3.5 sera publié au quatrième trimestre de cette année, et une super application devrait être publiée au premier trimestre de l'année prochaine. (Source : compte public WeChat "Jiazi Discovery") [Fin]
La photo provient d'Internet et a été supprimée pour cause de violation
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Dix outils d'annotation de texte gratuits open source recommandés
Mar 26, 2024 pm 08:20 PM
Dix outils d'annotation de texte gratuits open source recommandés
Mar 26, 2024 pm 08:20 PM
L'annotation de texte est le travail d'étiquettes ou de balises correspondant à un contenu spécifique dans le texte. Son objectif principal est d’apporter des informations complémentaires au texte pour une analyse et un traitement plus approfondis, notamment dans le domaine de l’intelligence artificielle. L'annotation de texte est cruciale pour les tâches d'apprentissage automatique supervisées dans les applications d'intelligence artificielle. Il est utilisé pour entraîner des modèles d'IA afin de mieux comprendre les informations textuelles en langage naturel et d'améliorer les performances de tâches telles que la classification de texte, l'analyse des sentiments et la traduction linguistique. Grâce à l'annotation de texte, nous pouvons apprendre aux modèles d'IA à reconnaître les entités dans le texte, à comprendre le contexte et à faire des prédictions précises lorsque de nouvelles données similaires apparaissent. Cet article recommande principalement de meilleurs outils d'annotation de texte open source. 1.LabelStudiohttps://github.com/Hu
 15 outils d'annotation d'images gratuits open source recommandés
Mar 28, 2024 pm 01:21 PM
15 outils d'annotation d'images gratuits open source recommandés
Mar 28, 2024 pm 01:21 PM
L'annotation d'images est le processus consistant à associer des étiquettes ou des informations descriptives à des images pour donner une signification et une explication plus profondes au contenu de l'image. Ce processus est essentiel à l’apprentissage automatique, qui permet d’entraîner les modèles de vision à identifier plus précisément les éléments individuels des images. En ajoutant des annotations aux images, l'ordinateur peut comprendre la sémantique et le contexte derrière les images, améliorant ainsi la capacité de comprendre et d'analyser le contenu de l'image. L'annotation d'images a un large éventail d'applications, couvrant de nombreux domaines, tels que la vision par ordinateur, le traitement du langage naturel et les modèles de vision graphique. Elle a un large éventail d'applications, telles que l'assistance aux véhicules pour identifier les obstacles sur la route, en aidant à la détection. et le diagnostic des maladies grâce à la reconnaissance d'images médicales. Cet article recommande principalement de meilleurs outils d'annotation d'images open source et gratuits. 1.Makesens
 L'application de grands modèles Tencent Yuanbao est en ligne ! Hunyuan est mis à niveau pour créer un assistant IA complet pouvant être transporté n'importe où
Jun 09, 2024 pm 10:38 PM
L'application de grands modèles Tencent Yuanbao est en ligne ! Hunyuan est mis à niveau pour créer un assistant IA complet pouvant être transporté n'importe où
Jun 09, 2024 pm 10:38 PM
Le 30 mai, Tencent a annoncé une mise à niveau complète de son modèle Hunyuan. L'application « Tencent Yuanbao » basée sur le modèle Hunyuan a été officiellement lancée et peut être téléchargée sur les magasins d'applications Apple et Android. Par rapport à la version de l'applet Hunyuan lors de la phase de test précédente, Tencent Yuanbao fournit des fonctionnalités de base telles que la recherche IA, le résumé IA et l'écriture IA pour les scénarios d'efficacité du travail ; pour les scénarios de la vie quotidienne, le gameplay de Yuanbao est également plus riche et fournit de multiples fonctionnalités d'application IA. , et de nouvelles méthodes de jeu telles que la création d'agents personnels sont ajoutées. « Tencent ne s'efforcera pas d'être le premier à créer un grand modèle. » Liu Yuhong, vice-président de Tencent Cloud et responsable du grand modèle Tencent Hunyuan, a déclaré : « Au cours de l'année écoulée, nous avons continué à promouvoir les capacités de Tencent. Grand modèle Tencent Hunyuan. Dans la technologie polonaise riche et massive dans des scénarios commerciaux tout en obtenant un aperçu des besoins réels des utilisateurs.
 Lancement du grand modèle Bytedance Beanbao, le service d'IA complet Volcano Engine aide les entreprises à se transformer intelligemment
Jun 05, 2024 pm 07:59 PM
Lancement du grand modèle Bytedance Beanbao, le service d'IA complet Volcano Engine aide les entreprises à se transformer intelligemment
Jun 05, 2024 pm 07:59 PM
Tan Dai, président de Volcano Engine, a déclaré que les entreprises qui souhaitent bien mettre en œuvre de grands modèles sont confrontées à trois défis clés : l'effet de modèle, le coût d'inférence et la difficulté de mise en œuvre : elles doivent disposer d'un bon support de base de grands modèles pour résoudre des problèmes complexes, et elles doivent également avoir une inférence à faible coût. Les services permettent d'utiliser largement de grands modèles, et davantage d'outils, de plates-formes et d'applications sont nécessaires pour aider les entreprises à mettre en œuvre des scénarios. ——Tan Dai, président de Huoshan Engine 01. Le grand modèle de pouf fait ses débuts et est largement utilisé. Le polissage de l'effet de modèle est le défi le plus critique pour la mise en œuvre de l'IA. Tan Dai a souligné que ce n'est que grâce à une utilisation intensive qu'un bon modèle peut être poli. Actuellement, le modèle Doubao traite 120 milliards de jetons de texte et génère 30 millions d'images chaque jour. Afin d'aider les entreprises à mettre en œuvre des scénarios de modèles à grande échelle, le modèle à grande échelle beanbao développé indépendamment par ByteDance sera lancé à travers le volcan.
 Recommandé : Excellent projet de détection et de reconnaissance des visages open source JS
Apr 03, 2024 am 11:55 AM
Recommandé : Excellent projet de détection et de reconnaissance des visages open source JS
Apr 03, 2024 am 11:55 AM
La technologie de détection et de reconnaissance des visages est déjà une technologie relativement mature et largement utilisée. Actuellement, le langage d'application Internet le plus utilisé est JS. La mise en œuvre de la détection et de la reconnaissance faciale sur le front-end Web présente des avantages et des inconvénients par rapport à la reconnaissance faciale back-end. Les avantages incluent la réduction de l'interaction réseau et de la reconnaissance en temps réel, ce qui réduit considérablement le temps d'attente des utilisateurs et améliore l'expérience utilisateur. Les inconvénients sont les suivants : il est limité par la taille du modèle et la précision est également limitée ; Comment utiliser js pour implémenter la détection de visage sur le web ? Afin de mettre en œuvre la reconnaissance faciale sur le Web, vous devez être familier avec les langages et technologies de programmation associés, tels que JavaScript, HTML, CSS, WebRTC, etc. Dans le même temps, vous devez également maîtriser les technologies pertinentes de vision par ordinateur et d’intelligence artificielle. Il convient de noter qu'en raison de la conception du côté Web
 Le document multimodal Alibaba 7B comprenant le grand modèle remporte le nouveau SOTA
Apr 02, 2024 am 11:31 AM
Le document multimodal Alibaba 7B comprenant le grand modèle remporte le nouveau SOTA
Apr 02, 2024 am 11:31 AM
Nouveau SOTA pour des capacités de compréhension de documents multimodaux ! L'équipe Alibaba mPLUG a publié le dernier travail open source mPLUG-DocOwl1.5, qui propose une série de solutions pour relever les quatre défis majeurs que sont la reconnaissance de texte d'image haute résolution, la compréhension générale de la structure des documents, le suivi des instructions et l'introduction de connaissances externes. Sans plus tarder, examinons d’abord les effets. Reconnaissance et conversion en un clic de graphiques aux structures complexes au format Markdown : Des graphiques de différents styles sont disponibles : Une reconnaissance et un positionnement de texte plus détaillés peuvent également être facilement traités : Des explications détaillées sur la compréhension du document peuvent également être données : Vous savez, « Compréhension du document " est actuellement un scénario important pour la mise en œuvre de grands modèles linguistiques. Il existe de nombreux produits sur le marché pour aider à la lecture de documents. Certains d'entre eux utilisent principalement des systèmes OCR pour la reconnaissance de texte et coopèrent avec LLM pour le traitement de texte.
 Référence GPT-4 ! Le grand modèle Jiutian de China Mobile a passé le double enregistrement
Apr 04, 2024 am 09:31 AM
Référence GPT-4 ! Le grand modèle Jiutian de China Mobile a passé le double enregistrement
Apr 04, 2024 am 09:31 AM
Selon des informations du 4 avril, l'Administration du cyberespace de Chine a récemment publié une liste de grands modèles enregistrés, et le « Grand modèle d'interaction du langage naturel Jiutian » de China Mobile y a été inclus, indiquant que le grand modèle Jiutian AI de China Mobile peut officiellement fournir des informations artificielles génératives. services de renseignement vers le monde extérieur. China Mobile a déclaré qu'il s'agit du premier modèle à grande échelle développé par une entreprise centrale à avoir réussi à la fois le double enregistrement national « Enregistrement du service d'intelligence artificielle générative » et le double enregistrement « Enregistrement de l'algorithme de service de synthèse profonde domestique ». Selon les rapports, le grand modèle d'interaction en langage naturel de Jiutian présente les caractéristiques de capacités, de sécurité et de crédibilité améliorées de l'industrie, et prend en charge la localisation complète. Il a formé plusieurs versions de paramètres telles que 9 milliards, 13,9 milliards, 57 milliards et 100 milliards. et peut être déployé de manière flexible dans le Cloud, la périphérie et la fin sont des situations différentes
 Pratique avancée du graphe de connaissances industrielles
Jun 13, 2024 am 11:59 AM
Pratique avancée du graphe de connaissances industrielles
Jun 13, 2024 am 11:59 AM
1. Introduction au contexte Tout d’abord, présentons l’historique du développement de la technologie Yunwen. Yunwen Technology Company... 2023 est la période où les grands modèles prédominent. De nombreuses entreprises pensent que l'importance des graphiques a été considérablement réduite après les grands modèles et que les systèmes d'information prédéfinis étudiés précédemment ne sont plus importants. Cependant, avec la promotion du RAG et la prévalence de la gouvernance des données, nous avons constaté qu'une gouvernance des données plus efficace et des données de haute qualité sont des conditions préalables importantes pour améliorer l'efficacité des grands modèles privatisés. Par conséquent, de plus en plus d'entreprises commencent à y prêter attention. au contenu lié à la construction des connaissances. Cela favorise également la construction et le traitement des connaissances à un niveau supérieur, où de nombreuses techniques et méthodes peuvent être explorées. On voit que l'émergence d'une nouvelle technologie ne détruit pas toutes les anciennes technologies, mais peut également intégrer des technologies nouvelles et anciennes.
