
 Périphériques technologiques
IA
Explorez les techniques de formation pour les segments de test en monde ouvert à l'aide de méthodes d'auto-formation avec des extensions de prototypes dynamiques
Périphériques technologiques
IA
Explorez les techniques de formation pour les segments de test en monde ouvert à l'aide de méthodes d'auto-formation avec des extensions de prototypes dynamiques
Explorez les techniques de formation pour les segments de test en monde ouvert à l'aide de méthodes d'auto-formation avec des extensions de prototypes dynamiques

L'amélioration de la capacité de généralisation du modèle est une base importante pour promouvoir la mise en œuvre de méthodes de perception basées sur la vision. La formation/adaptation au moment du test généralise le modèle à des domaines cibles inconnus en ajustant les poids des paramètres du modèle dans la section de test Segment de distribution des données. . Les méthodes TTT/TTA existantes se concentrent généralement sur l'amélioration des performances de formation des segments de test sous les données du domaine cible dans un monde en boucle fermée.
Cependant, dans de nombreux scénarios d'application, le domaine cible est facilement contaminé par de fortes données hors domaine (Strong OOD), telles que des données sans rapport avec des catégories sémantiques. Ce scénario est également connu sous le nom de Open World Test Segment Training (OWTTT). Dans ce cas, les TTT/TTA existants forcent généralement la classification des données hors domaine fortes en catégories connues, interférant ainsi finalement avec la capacité à résoudre les données hors domaine faibles (Weak OOD) telles que les images qui sont interférées avec by noise
Récemment, l'Université de technologie de Chine du Sud et l'équipe A*STAR ont proposé pour la première fois la mise en place d'une formation de segment de test en monde ouvert et ont lancé la méthode de formation correspondante

- Papier : https ://arxiv.org/abs/2308.09942
- Code : https://github.com/Yushu-Li/OWTTT
Cet article propose d'abord une solide méthode de filtrage d'échantillons de données hors domaine avec seuil adaptatif pour améliorer la méthode d'auto-formation TTT dans le monde ouvert de la robustesse. Le procédé propose en outre une méthode pour caractériser des échantillons forts hors domaine sur la base de prototypes étendus dynamiquement afin d'améliorer l'effet de séparation de données hors domaine faible/fort. Enfin, l'auto-formation est limitée par l'alignement de la distribution
La méthode de cette étude a obtenu les meilleures performances sur 5 benchmarks OWTTT différents et a ouvert une nouvelle direction pour des méthodes TTT plus robustes pour des recherches ultérieures sur TTT. Cette recherche a été acceptée comme document de présentation orale à l'ICCV 2023
Introduction
La formation sur les segments de test (TTT) peut accéder aux données du domaine cible uniquement dans la phase d'inférence et effectuer une inférence à la volée sur des distributions décalées. données de test. Le succès du TTT a été démontré sur un certain nombre de données de domaine cible artificiellement sélectionnées et corrompues. Cependant, les limites des capacités des méthodes TTT existantes n’ont pas été entièrement explorées.
Pour promouvoir les applications TTT dans des scénarios ouverts, la recherche s'est déplacée vers l'étude des scénarios dans lesquels les méthodes TTT peuvent échouer. De nombreux efforts ont été déployés pour développer des méthodes TTT stables et robustes dans des environnements de monde ouvert plus réalistes. Dans ce travail, nous explorons un scénario de monde ouvert courant mais négligé, dans lequel le domaine cible peut contenir des distributions de données de test tirées d'environnements significativement différents, tels que des catégories sémantiques différentes de celles du domaine source, ou simplement du bruit aléatoire.
Nous appelons les données de test ci-dessus des données fortes hors distribution (strong OOD). Ce que l'on appelle dans ce travail des données OOD faibles sont des données de test avec des changements de distribution, tels que des dommages synthétiques courants. Par conséquent, le manque de travaux existants sur cet environnement réaliste nous motive à explorer l’amélioration de la robustesse de l’Open World Test Segment Training (OWTTT), où les données de test sont contaminées par de forts échantillons OOD.
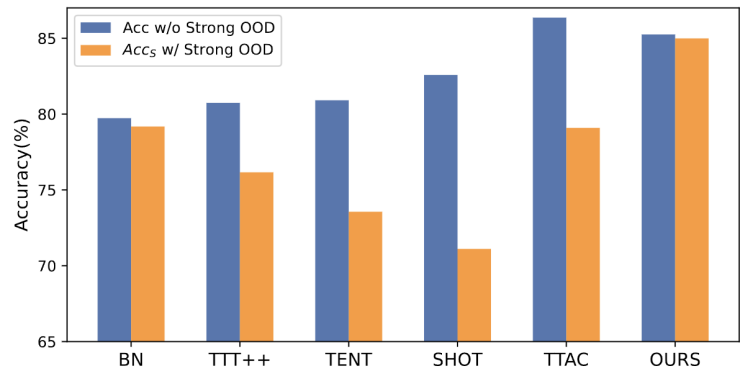
Figure 1 : Résultats de l'évaluation de la méthode TTT existante sous le paramètre OWTTT
Comme le montre la figure 1, nous avons d'abord évalué la méthode TTT existante sous le paramètre OWTTT et avons constaté que les deux méthodes TTT via l'auto -l'alignement de la formation et de la distribution est affecté par de forts échantillons OOD. Ces résultats démontrent qu’une formation sécurisée pendant les tests dans le monde ouvert ne peut pas être obtenue en appliquant les techniques TTT existantes. Nous attribuons leur échec aux deux raisons suivantes.
- Le TTT basé sur l'auto-formation a du mal à gérer des échantillons OOD forts car il doit attribuer des échantillons de test à des catégories connues. Bien que certains échantillons peu fiables puissent être filtrés en appliquant le seuil utilisé dans l’apprentissage semi-supervisé, il n’y a toujours aucune garantie que tous les échantillons OOD forts seront filtrés.
- Les méthodes basées sur l'alignement de la distribution seront affectées lorsque des échantillons OOD forts sont calculés pour estimer la distribution du domaine cible. L'alignement de la distribution globale [1] et l'alignement de la distribution des classes [2] peuvent être affectés et conduire à un alignement inexact de la distribution des fonctionnalités.
Afin de résoudre les raisons potentielles de l'échec des méthodes TTT existantes, nous proposons une méthode qui combine deux technologies pour améliorer la robustesse du TTT en monde ouvert dans un cadre d'auto-formation
Tout d'abord, nous construisons la base de référence de TTT sur la variante auto-entraînée, c'est-à-dire le clustering dans le domaine cible avec le prototype du domaine source comme centre du cluster. Pour atténuer l'impact de l'auto-formation sur les OOD forts avec des pseudo-étiquettes incorrectes, nous concevons une méthode sans hyperparamètres pour rejeter les échantillons OOD forts.
Pour séparer davantage les caractéristiques des échantillons OOD faibles et des échantillons OOD forts, nous permettons au pool de prototypes de s'étendre en sélectionnant des échantillons OOD forts isolés. Par conséquent, l’auto-formation permettra aux échantillons OOD forts de former des groupes serrés autour du prototype OOD fort nouvellement développé. Cela facilitera l’alignement de la distribution entre les domaines source et cible. Nous proposons en outre de régulariser l'auto-formation grâce à un alignement de la distribution mondiale afin de réduire le risque de biais de confirmation.
Enfin, pour synthétiser des scénarios TTT en monde ouvert, nous adoptons les ensembles de données CIFAR10-C, CIFAR100-C, ImageNet-C, VisDA-C, ImageNet-R, Tiny-ImageNet, MNIST et SVHN, et utilisons un Les données l'ensemble est un OOD faible et les autres sont un OOD fort pour établir un ensemble de données de référence. Nous appelons cette référence l'Open World Test Segment Training Benchmark et espérons que cela encouragera davantage de travaux futurs à se concentrer sur la robustesse de la formation des segments de test dans des scénarios plus réalistes.
Méthode
L'article divise la méthode proposée en quatre parties pour présenter
1) Aperçu du paramétrage du segment de test tâche de formation dans le monde ouvert.
2) Décrit comment implémenter TTT via Réécrire le contenu comme : analyse de cluster et comment étendre le prototype pour une formation en temps de test en monde ouvert.
3) Présente comment utiliser les données du domaine cible pour l'expansion dynamique du prototype.
4) Présentation de Distribution Alignment combiné à un contenu réécrit : analyse de cluster pour obtenir une puissante formation en temps de test en monde ouvert.
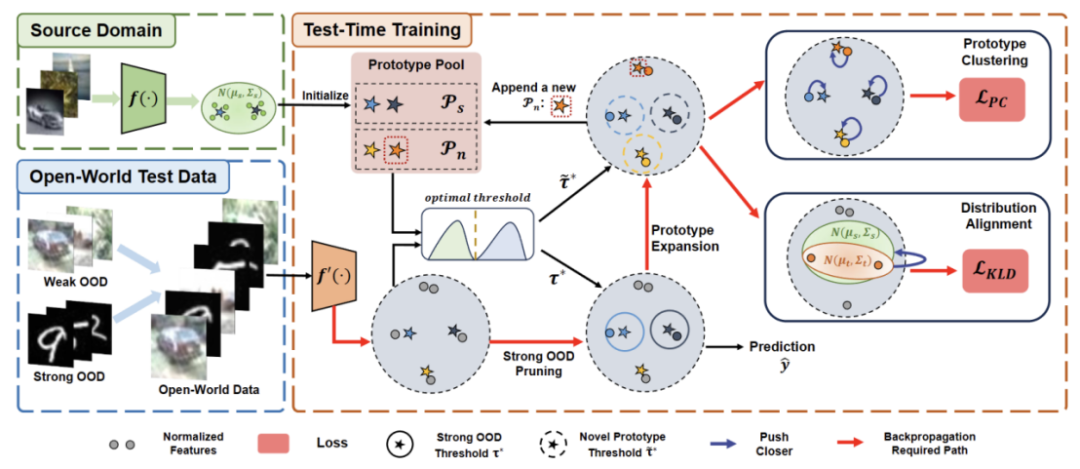
Figure 2 : Présentation de la méthode
Paramètre de la tâche
Le but de TTT est d'adapter le modèle pré-entraîné du domaine source au domaine cible, où le domaine cible peut présenter des différences par rapport à la migration de distribution du domaine source. Dans le TTT standard en monde fermé, les espaces d'étiquettes des domaines source et cible sont les mêmes. Cependant, dans le TTT en monde ouvert, l'espace d'étiquettes du domaine cible contient l'espace cible du domaine source, ce qui signifie que le domaine cible a de nouvelles catégories sémantiques inédites
Afin d'éviter toute confusion entre les définitions de TTT, nous adoptons TTAC [2 Le protocole d'entraînement au temps de test séquentiel (sTTT) proposé dans ] est évalué. Dans le cadre du protocole sTTT, les échantillons de test sont testés séquentiellement et les mises à jour du modèle sont effectuées après avoir observé de petits lots d'échantillons de test. La prédiction pour tout échantillon de test arrivant à l'horodatage t n'est affectée par aucun échantillon de test arrivant à t+k (dont k est supérieur à 0).
Contenu réécrit comme : Analyse de cluster
Inspiré par les travaux utilisant le clustering dans les tâches d'adaptation de domaine [3,4], nous traitons la formation de segments de test comme la découverte de structures de cluster dans les données du domaine cible. En identifiant des prototypes représentatifs en tant que centres de cluster, les structures de cluster sont identifiées dans le domaine cible et les échantillons de test sont encouragés à s'intégrer à proximité de l'un des prototypes. Le contenu réécrit est le suivant : L'objectif de l'analyse groupée est défini comme minimisant la perte de log-vraisemblance négative de la similarité cosinus entre l'échantillon et le centre de la grappe, comme le montre la formule suivante.
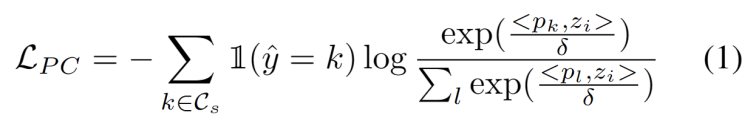
Nous développons une méthode sans hyperparamètres pour filtrer les échantillons OOD forts afin d'éviter l'impact négatif de l'ajustement des poids des modèles. Plus précisément, nous définissons un score OOD fort pour chaque échantillon de test comme la plus grande similarité avec le prototype du domaine source, comme le montre l'équation suivante.
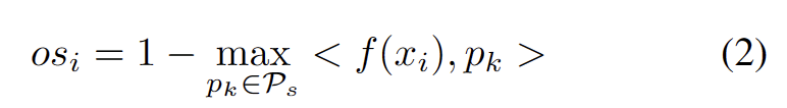
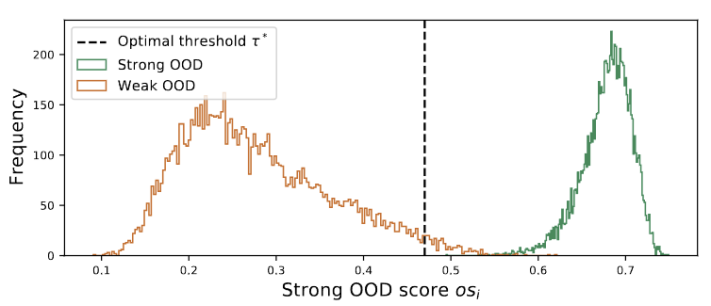
Les valeurs aberrantes de la figure 3 montrent une distribution bimodale
Nous observons que les valeurs aberrantes suivent une distribution bimodale, comme le montre la figure 3. Par conséquent, au lieu de spécifier un seuil fixe, nous définissons le seuil optimal comme la meilleure valeur séparant les deux distributions. Plus précisément, le problème peut être formulé en divisant les valeurs aberrantes en deux groupes, et le seuil optimal minimisera la variance au sein du groupe. L'optimisation de l'équation suivante peut être réalisée efficacement en recherchant de manière exhaustive tous les seuils possibles de 0 à 1 par pas de 0,01.
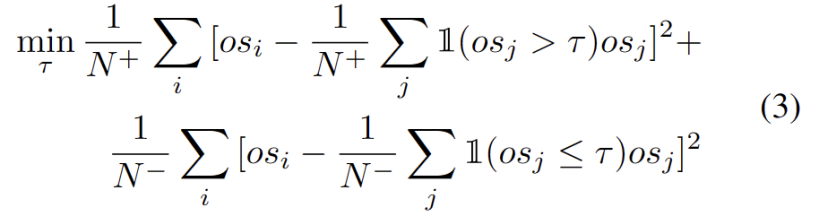
Extension de prototype dynamique
L'expansion du pool de prototypes OOD forts nécessite de prendre en compte à la fois le domaine source et le prototype OOD fort pour évaluer les échantillons de test. Pour estimer dynamiquement le nombre de clusters à partir des données, des études antérieures ont étudié des problèmes similaires. L'algorithme déterministe de clustering dur DP-means [5] a été développé en mesurant la distance des points de données aux centres de cluster connus, et un nouveau cluster est initialisé lorsque la distance est supérieure à un seuil. DP-means s'avère équivalent à l'optimisation de l'objectif K-means mais avec une pénalité supplémentaire sur le nombre de clusters, fournissant une solution réalisable pour l'expansion dynamique des prototypes.
Pour atténuer la difficulté d'estimer des hyperparamètres supplémentaires, nous définissons d'abord un échantillon de test avec un score OOD fort étendu comme la distance la plus proche du prototype de domaine source existant et du prototype OOD fort, comme suit. Par conséquent, tester des échantillons au-dessus de ce seuil permettra de construire un nouveau prototype. Pour éviter d'ajouter des échantillons de test à proximité, nous répétons progressivement ce processus d'expansion du prototype.
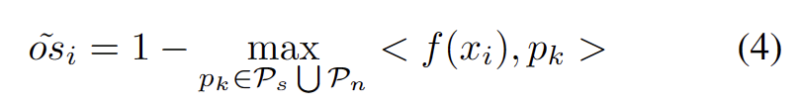
Avec d'autres prototypes OOD forts identifiés, nous avons défini la réécriture de l'échantillon de test comme : perte d'analyse de cluster, en tenant compte de deux facteurs. Premièrement, les échantillons de test classés dans des classes connues doivent être intégrés plus près des prototypes et plus éloignés des autres prototypes, ce qui définit la tâche de classification en classe K. Deuxièmement, les échantillons de test classés comme prototypes OOD forts doivent être éloignés de tout prototype du domaine source, ce qui définit la tâche de classification de classe K+1. En gardant ces objectifs à l’esprit, nous réécrirons le contenu comme suit : La perte de l’analyse groupée est définie comme l’équation suivante.
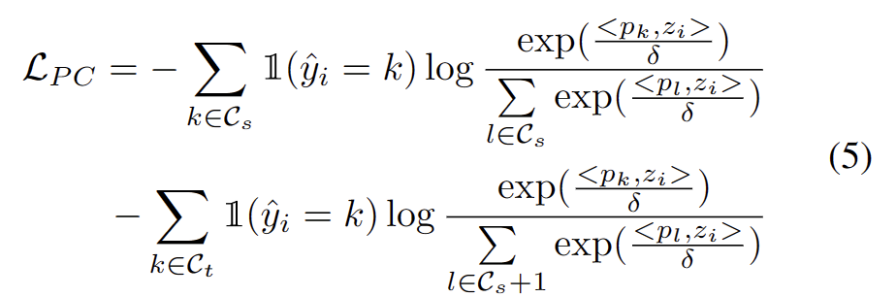
Les contraintes d'alignement distribué signifient que dans une conception ou une mise en page, les éléments doivent être disposés et alignés d'une manière spécifique. Cette contrainte peut être appliquée à une variété de scénarios différents, notamment la conception Web, la conception graphique et l'aménagement de l'espace. En utilisant des contraintes d'alignement distribuées, la relation entre les éléments peut être rendue plus claire et plus unifiée, améliorant ainsi l'esthétique et la lisibilité de la conception globale.
Il est bien connu que l'auto-apprentissage est sensible aux pseudo-étiquettes erronées. La situation est aggravée lorsque le domaine cible est constitué d'échantillons OOD. Pour réduire le risque d'échec, nous utilisons en outre l'alignement de distribution [1] comme régularisation pour l'auto-formation, comme suit.
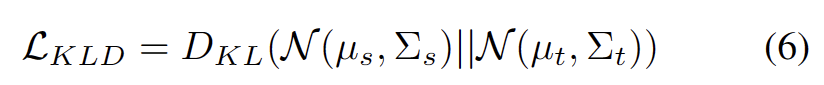
Expériences
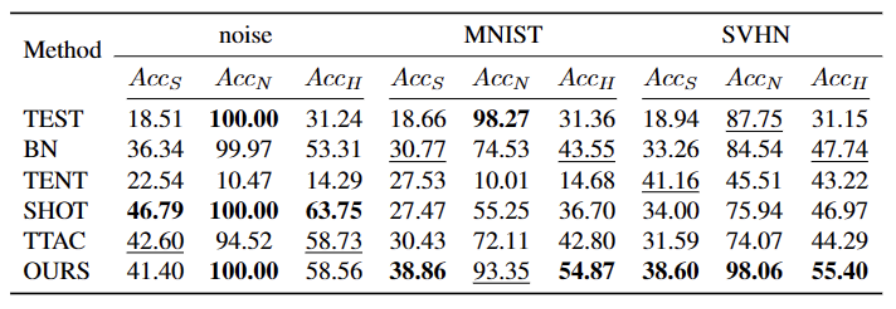
Nous avons testé sur 5 ensembles de données de référence OWTTT différents, y compris des ensembles de données synthétiques corrompus et des ensembles de données de style variable. L'expérience utilise principalement trois indicateurs d'évaluation : une faible précision de classification OOD ACCS, une forte précision de classification OOD ACCN et la moyenne harmonique des deux ACCH

Ce qui doit être réécrit est : L'ensemble de données Cifar10-C est différent La performance de la méthode est présentée dans le tableau ci-dessous

Le contenu qui doit être réécrit est : Les performances des différentes méthodes dans l'ensemble de données Cifar100-C sont présentées dans le tableau ci-dessous :
Le contenu qui doit être réécrit est le suivant : Sur l'ensemble de données ImageNet-C, les performances des différentes méthodes sont présentées dans le tableau ci-dessous
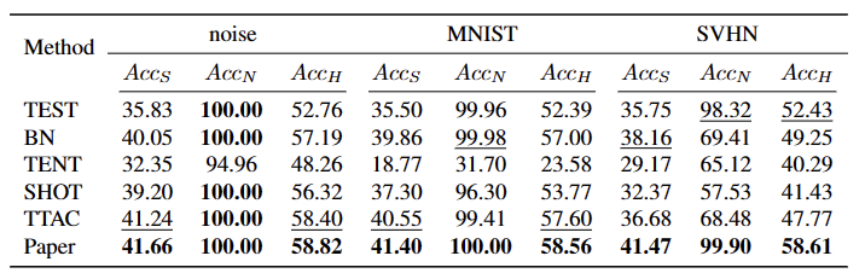
Tableau 4 Performances des différentes méthodes sur l'ensemble de données ImageNet-R
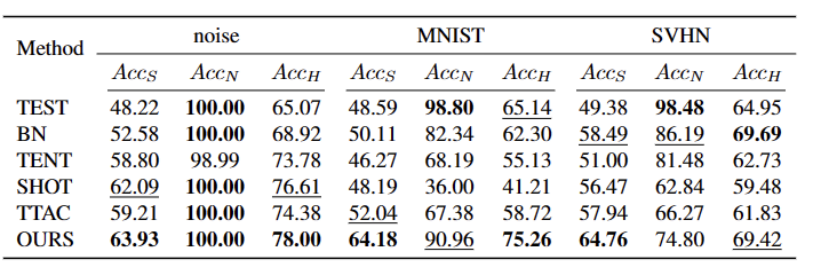
Tableau 5 Performances des différentes méthodes sur l'ensemble de données VisDA-C
Notre méthode est cohérente sur presque toutes les données sets Par rapport aux meilleures méthodes actuelles, il existe des améliorations significatives, comme le montre le tableau ci-dessus. Il peut identifier efficacement les échantillons OOD forts et réduire l'impact sur la classification des échantillons OOD faibles. Par conséquent, dans le scénario du monde ouvert, notre méthode peut obtenir un TTT plus robuste
Résumé
Cet article propose d'abord les problèmes et les paramètres de la formation de segments de test en monde ouvert (OWTTT), en soulignant l'existant. Nous rencontrons des difficultés lors du traitement de données du domaine cible contenant des échantillons OOD forts qui présentent des décalages sémantiques par rapport aux échantillons du domaine source. Une méthode d'auto-apprentissage basée sur l'expansion dynamique de prototypes est proposée pour résoudre les problèmes ci-dessus. Nous espérons que ce travail pourra fournir de nouvelles orientations pour les recherches ultérieures sur le TTT afin d'explorer des méthodes TTT plus robustes
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
0. À quoi sert cet article ? Nous proposons DepthFM : un modèle d'estimation de profondeur monoculaire génératif de pointe, polyvalent et rapide. En plus des tâches traditionnelles d'estimation de la profondeur, DepthFM démontre également des capacités de pointe dans les tâches en aval telles que l'inpainting en profondeur. DepthFM est efficace et peut synthétiser des cartes de profondeur en quelques étapes d'inférence. Lisons ce travail ensemble ~ 1. Titre des informations sur l'article : DepthFM : FastMonocularDepthEstimationwithFlowMatching Auteur : MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
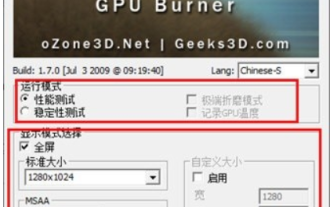 Que pensez-vous de furmark ? - Comment furmark est-il considéré comme qualifié ?
Mar 19, 2024 am 09:25 AM
Que pensez-vous de furmark ? - Comment furmark est-il considéré comme qualifié ?
Mar 19, 2024 am 09:25 AM
Que pensez-vous de furmark ? 1. Définissez le « Mode d'exécution » et le « Mode d'affichage » dans l'interface principale, ajustez également le « Mode de test » et cliquez sur le bouton « Démarrer ». 2. Après avoir attendu un moment, vous verrez les résultats du test, y compris divers paramètres de la carte graphique. Comment Furmark est-il qualifié ? 1. Utilisez une machine à pâtisserie Furmark et vérifiez les résultats pendant environ une demi-heure. Elle oscille essentiellement autour de 85 degrés, avec une valeur maximale de 87 degrés et une température ambiante de 19 degrés. Grand châssis, 5 ports de ventilateur de châssis, deux à l'avant, deux en haut et un à l'arrière, mais un seul ventilateur est installé. Tous les accessoires ne sont pas overclockés. 2. Dans des circonstances normales, la température normale de la carte graphique doit être comprise entre « 30 et 85 ℃ ». 3. Même en été, lorsque la température ambiante est trop élevée, la température normale est de « 50 à 85 ℃.
 La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
Je pleure à mort. Le monde construit à la folie de grands modèles. Les données sur Internet ne suffisent pas du tout. Le modèle de formation ressemble à « The Hunger Games », et les chercheurs en IA du monde entier se demandent comment nourrir ces personnes avides de données. Ce problème est particulièrement important dans les tâches multimodales. À une époque où rien ne pouvait être fait, une équipe de start-up du département de l'Université Renmin de Chine a utilisé son propre nouveau modèle pour devenir la première en Chine à faire de « l'auto-alimentation des données générées par le modèle » une réalité. De plus, il s’agit d’une approche à deux volets, du côté compréhension et du côté génération, les deux côtés peuvent générer de nouvelles données multimodales de haute qualité et fournir un retour de données au modèle lui-même. Qu'est-ce qu'un modèle ? Awaker 1.0, un grand modèle multimodal qui vient d'apparaître sur le Forum Zhongguancun. Qui est l'équipe ? Moteur Sophon. Fondé par Gao Yizhao, doctorant à la Hillhouse School of Artificial Intelligence de l’Université Renmin.
 La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
Quoi? Zootopie est-elle concrétisée par l’IA domestique ? Avec la vidéo est exposé un nouveau modèle de génération vidéo domestique à grande échelle appelé « Keling ». Sora utilise une voie technique similaire et combine un certain nombre d'innovations technologiques auto-développées pour produire des vidéos qui comportent non seulement des mouvements larges et raisonnables, mais qui simulent également les caractéristiques du monde physique et possèdent de fortes capacités de combinaison conceptuelle et d'imagination. Selon les données, Keling prend en charge la génération de vidéos ultra-longues allant jusqu'à 2 minutes à 30 ips, avec des résolutions allant jusqu'à 1080p, et prend en charge plusieurs formats d'image. Un autre point important est que Keling n'est pas une démo ou une démonstration de résultats vidéo publiée par le laboratoire, mais une application au niveau produit lancée par Kuaishou, un acteur leader dans le domaine de la vidéo courte. De plus, l'objectif principal est d'être pragmatique, de ne pas faire de chèques en blanc et de se mettre en ligne dès sa sortie. Le grand modèle de Ke Ling est déjà sorti à Kuaiying.
 L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
Récemment, le milieu militaire a été submergé par la nouvelle : les avions de combat militaires américains peuvent désormais mener des combats aériens entièrement automatiques grâce à l'IA. Oui, tout récemment, l’avion de combat IA de l’armée américaine a été rendu public pour la première fois, dévoilant ainsi son mystère. Le nom complet de ce chasseur est Variable Stability Simulator Test Aircraft (VISTA). Il a été personnellement piloté par le secrétaire de l'US Air Force pour simuler une bataille aérienne en tête-à-tête. Le 2 mai, le secrétaire de l'US Air Force, Frank Kendall, a décollé à bord d'un X-62AVISTA à la base aérienne d'Edwards. Notez que pendant le vol d'une heure, toutes les actions de vol ont été effectuées de manière autonome par l'IA ! Kendall a déclaré : "Au cours des dernières décennies, nous avons réfléchi au potentiel illimité du combat air-air autonome, mais cela a toujours semblé hors de portée." Mais maintenant,
 Pour seulement 250$, le directeur technique de Hugging Face vous apprend étape par étape comment peaufiner Llama 3
May 06, 2024 pm 03:52 PM
Pour seulement 250$, le directeur technique de Hugging Face vous apprend étape par étape comment peaufiner Llama 3
May 06, 2024 pm 03:52 PM
Les grands modèles de langage open source familiers tels que Llama3 lancé par Meta, les modèles Mistral et Mixtral lancés par MistralAI et Jamba lancé par AI21 Lab sont devenus des concurrents d'OpenAI. Dans la plupart des cas, les utilisateurs doivent affiner ces modèles open source en fonction de leurs propres données pour libérer pleinement le potentiel du modèle. Il n'est pas difficile d'affiner un grand modèle de langage (comme Mistral) par rapport à un petit en utilisant Q-Learning sur un seul GPU, mais le réglage efficace d'un grand modèle comme Llama370b ou Mixtral est resté un défi jusqu'à présent. . C'est pourquoi Philipp Sch, directeur technique de HuggingFace
 Surpassant largement le DPO : l'équipe de Chen Danqi a proposé une optimisation simple des préférences SimPO et a également affiné le modèle open source 8B le plus puissant.
Jun 01, 2024 pm 04:41 PM
Surpassant largement le DPO : l'équipe de Chen Danqi a proposé une optimisation simple des préférences SimPO et a également affiné le modèle open source 8B le plus puissant.
Jun 01, 2024 pm 04:41 PM
Afin d'aligner les grands modèles de langage (LLM) sur les valeurs et les intentions humaines, il est essentiel d'apprendre les commentaires humains pour garantir qu'ils sont utiles, honnêtes et inoffensifs. En termes d'alignement du LLM, une méthode efficace est l'apprentissage par renforcement basé sur le retour humain (RLHF). Bien que les résultats de la méthode RLHF soient excellents, certains défis d’optimisation sont impliqués. Cela implique de former un modèle de récompense, puis d'optimiser un modèle politique pour maximiser cette récompense. Récemment, certains chercheurs ont exploré des algorithmes hors ligne plus simples, dont l’optimisation directe des préférences (DPO). DPO apprend le modèle politique directement sur la base des données de préférence en paramétrant la fonction de récompense dans RLHF, éliminant ainsi le besoin d'un modèle de récompense explicite. Cette méthode est simple et stable
