
 Périphériques technologiques
IA
180 milliards de paramètres, le premier grand modèle open source Falcon au monde est officiellement annoncé ! Crush LLaMA 2, les performances sont proches de GPT-4
Périphériques technologiques
IA
180 milliards de paramètres, le premier grand modèle open source Falcon au monde est officiellement annoncé ! Crush LLaMA 2, les performances sont proches de GPT-4
180 milliards de paramètres, le premier grand modèle open source Falcon au monde est officiellement annoncé ! Crush LLaMA 2, les performances sont proches de GPT-4

Du jour au lendemain, le grand modèle open source Falcon 180B le plus puissant au monde a déclenché tout Internet !
Avec 180 milliards de paramètres, Falcon a suivi une formation sur 3,5 billions de jetons et est directement arrivé en tête du classement Hugging Face.
Dans le test de référence, Falcon 180B a battu Llama 2 dans diverses tâches telles que le raisonnement, le codage, les tests de compétences et de connaissances.
Même, Falcon 180B est à égalité avec Google PaLM 2, et ses performances sont proches de GPT-4.
Cependant, Jim Fan, scientifique principal de NVIDIA, a remis cela en question :
- Le code ne représente que 5 % des données d'entraînement du Falcon-180B.
Et le code est de loin la donnée la plus utile pour améliorer les capacités de raisonnement, maîtriser l'utilisation des outils et améliorer les agents d'IA. En fait, GPT-3.5 est affiné sur la base du Codex.
- Aucun encodage de données de référence.
Sans capacités de codage, vous ne pouvez pas prétendre être « meilleur que GPT-3.5 » ou « proche de GPT-4 ». Cela devrait faire partie intégrante de la recette de pré-formation, et non une modification après coup.
- Pour les modèles de langage avec des paramètres supérieurs à 30B, il est temps d'adopter un système expert hybride (MoE). Jusqu'à présent, nous n'avons vu que OSS MoE LLM
Jetons un oeil, quelle est l'origine du Falcon 180B ?

Le grand modèle open source le plus puissant au monde
Auparavant, Falcon avait lancé trois tailles de modèle, à savoir 1,3B, 7,5B et 40B.
Officiellement, le Falcon 180B est une version améliorée du 40B. Il a été lancé par TII, le principal centre de recherche technologique au monde à Abu Dhabi, et est disponible pour une utilisation commerciale gratuite.

Cette fois, les chercheurs ont apporté des innovations techniques sur le modèle de base, comme l'utilisation de Multi-Query Attention pour améliorer l'évolutivité du modèle.
Pour le processus de formation, Falcon 180B est basé sur Amazon SageMaker, la plateforme d'apprentissage automatique cloud d'Amazon, et a complété la formation de 3,5 billions de jetons sur jusqu'à 4096 GPU.
Temps total de calcul du GPU, environ 7 000 000.
La taille des paramètres du Falcon 180B est 2,5 fois celle de Llama 2 (70B), et la quantité de calcul requise pour l'entraînement est 4 fois celle de Llama 2.
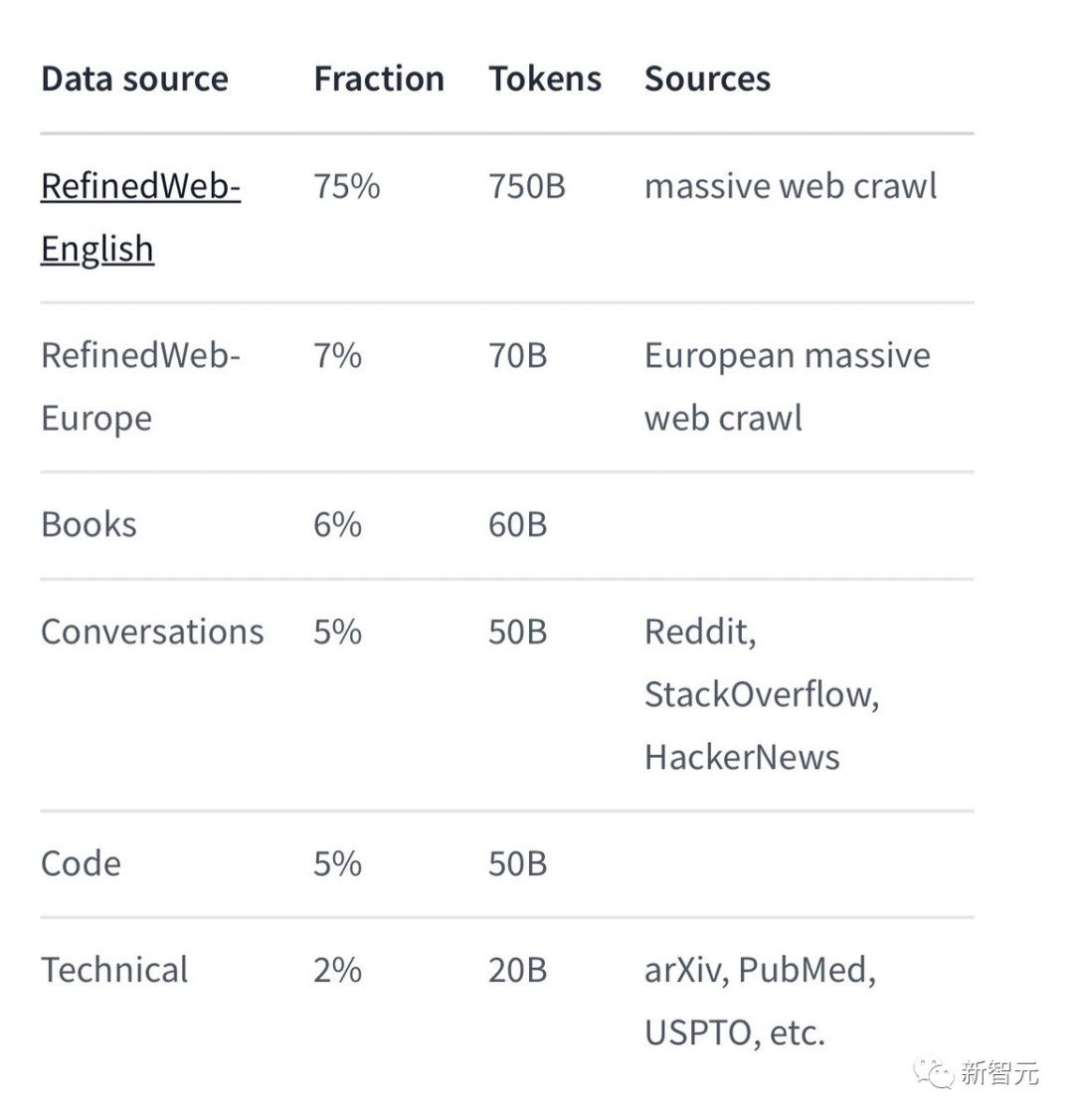
Parmi les données d'entraînement spécifiques, Falcon 180B est principalement l'ensemble de données RefinedWe (représentant environ 85 %).
De plus, il est formé sur un mélange de données organisées telles que des conversations, des documents techniques et une petite partie de code.
Cet ensemble de données de pré-formation est suffisamment grand, même 3,5 billions de jetons n'occupent que moins d'une époque.
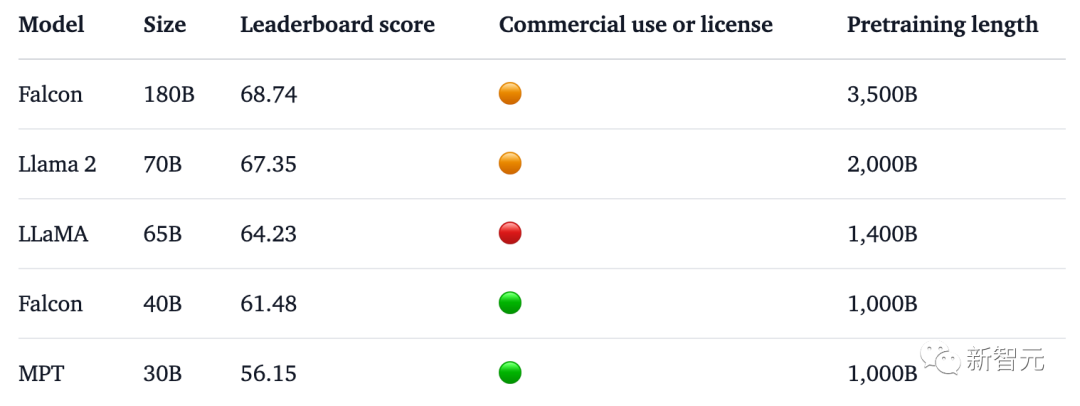
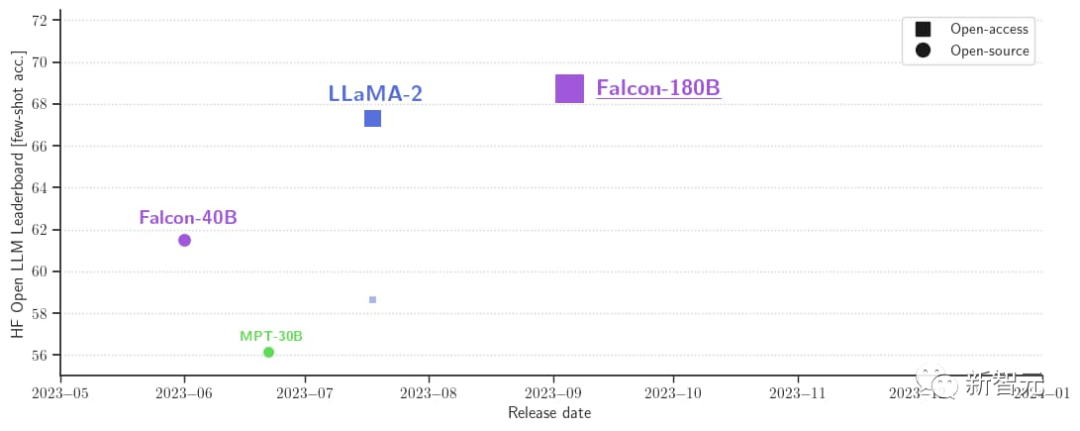
Le responsable affirme que le Falcon 180B est actuellement le "meilleur" grand modèle open source. Les performances spécifiques sont les suivantes :
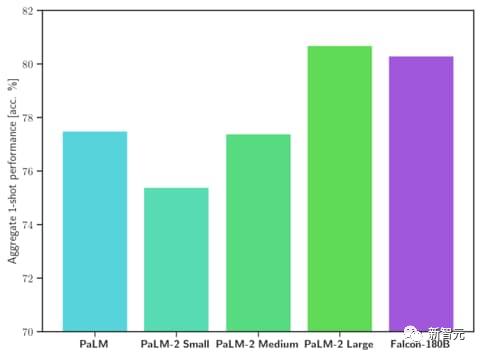
Sur le benchmark MMLU, les performances du Falcon 180B dépassent celles de Llama 2 70B et GPT-. 3.5.
À égalité avec le PaLM 2-Large de Google sur HellaSwag, LAMBADA, WebQuestions, Winogrande, PIQA, ARC, BoolQ, CB, COPA, RTE, WiC, WSC et ReCoRD.
De plus, il s'agit actuellement du grand modèle ouvert avec le score le plus élevé (68,74 points) sur la liste des grands modèles open source Hugging Face, surpassant LlaMA 2 (67,35).
Falcon 180B est maintenant disponible
Dans le même temps, les chercheurs ont également publié le modèle de conversation par chat Falcon-180B-Chat. Le modèle est affiné sur des ensembles de données de conversation et d'instructions couvrant Open-Platypus, UltraChat et Airoboros.

Désormais, tout le monde peut vivre une expérience de démonstration.
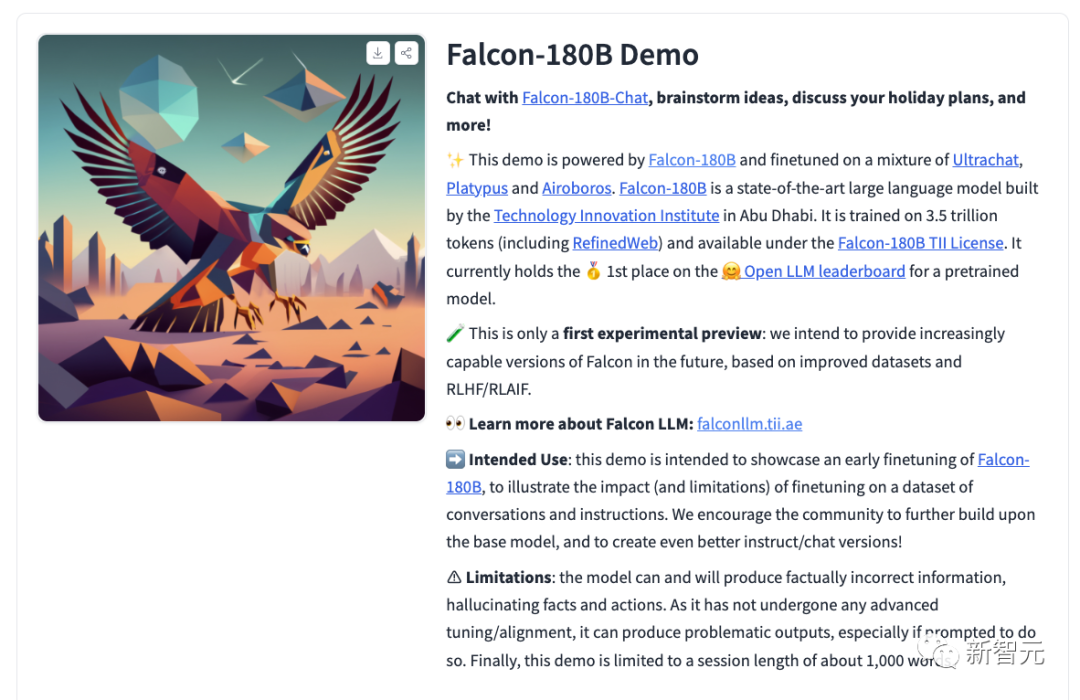
Adresse : https://huggingface.co/tiiuae/falcon-180B-chat
Format d'invite
Le modèle de base n'a pas de format d'invite car ce n'est pas un grand conversationnel Il n’est pas non plus entraîné via des commandes, il ne répond donc pas de manière conversationnelle.
Les modèles pré-entraînés sont une excellente plate-forme pour un réglage précis, mais vous ne devriez peut-être pas les utiliser directement. Son modèle de dialogue a un mode de dialogue simple.
System: Add an optional system prompt hereUser: This is the user inputFalcon: This is what the model generatesUser: This might be a second turn inputFalcon: and so on
Transformers
À partir de Transformers 4.33, Falcon 180B peut être utilisé et téléchargé dans l'écosystème Hugging Face.
Assurez-vous d'être connecté à votre compte Hugging Face et d'avoir installé la dernière version de Transformers :
pip install --upgrade transformershuggingface-cli login
bfloat16
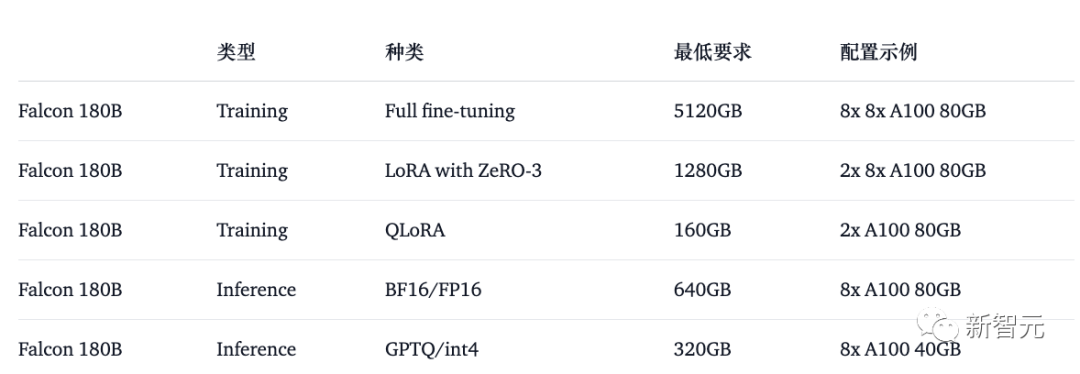
Voici comment utiliser le modèle de base dans bfloat16. Le Falcon 180B est un grand modèle, veuillez donc être conscient de sa configuration matérielle requise.
À cet égard, les exigences matérielles sont les suivantes :
On peut voir que si vous souhaitez affiner complètement le Falcon 180B, vous avez besoin d'au moins 8X8X A100 80G. Si c'est juste pour inférence, vous avez également besoin d'un GPU 8XA100 80G.
from transformers import AutoTokenizer, AutoModelForCausalLMimport transformersimport torchmodel_id = "tiiuae/falcon-180B"tokenizer = AutoTokenizer.from_pretrained(model_id)model = AutoModelForCausalLM.from_pretrained(model_id,torch_dtype=torch.bfloat16,device_map="auto",)prompt = "My name is Pedro, I live in"inputs = tokenizer(prompt, return_tensors="pt").to("cuda")output = model.generate(input_ids=inputs["input_ids"],attention_mask=inputs["attention_mask"],do_sample=True,temperature=0.6,top_p=0.9,max_new_tokens=50,)output = output[0].to("cpu")print(tokenizer.decode(output)peut produire le résultat suivant :
My name is Pedro, I live in Portugal and I am 25 years old. I am a graphic designer, but I am also passionate about photography and video.I love to travel and I am always looking for new adventures. I love to meet new people and explore new places.
en utilisant des bitsandbytes 8 bits et 4 bits
De plus, les versions quantifiées 8 bits et 4 bits du Faucon 180B sont en cours d'évaluation. Il n'y a presque aucune différence entre lui et bfloat16 !
C'est une bonne nouvelle pour l'inférence, car les utilisateurs peuvent utiliser en toute sécurité des versions quantifiées pour réduire les exigences matérielles.
Notez que l'inférence est beaucoup plus rapide dans la version 8 bits que dans la version 4 bits. Pour utiliser la quantification, vous devez installer la bibliothèque "bitsandbytes" et activer les drapeaux correspondants lors du chargement du modèle :
model = AutoModelForCausalLM.from_pretrained(model_id,torch_dtype=torch.bfloat16,**load_in_8bit=True,**device_map="auto",)
Conversation Model
Comme mentionné ci-dessus, une version du modèle affinée pour suivre le dialogue, un modèle de formation très simple est utilisé. Nous devons suivre le même modèle pour exécuter un raisonnement de type chat.
Pour référence, vous pouvez jeter un œil à la fonction [format_prompt] dans la démo du chat :
def format_prompt(message, history, system_prompt):prompt = ""if system_prompt:prompt += f"System: {system_prompt}\n"for user_prompt, bot_response in history:prompt += f"User: {user_prompt}\n"prompt += f"Falcon: {bot_response}\n"prompt += f"User: {message}\nFalcon:"return promptComme vous pouvez le voir ci-dessus, les interactions des utilisateurs et les réponses du modèle sont précédées des délimiteurs User: et Falcon:. Nous les connectons ensemble pour former une invite contenant l’intégralité de l’historique de la conversation. De cette façon, une invite système peut être fournie pour ajuster le style de construction.
Commentaires chauds des internautes
De nombreux internautes discutent de la véritable force du Falcon 180B.
Absolument incroyable. Il bat GPT-3.5 et est comparable au PaLM-2 Large de Google. Cela change la donne !

Un PDG de startup a déclaré que j'avais testé le robot de conversation Falcon-180B et qu'il n'était pas meilleur que le système de discussion Llama2-70B. Le classement HF OpenLLM montre également des résultats mitigés. Ceci est surprenant compte tenu de sa plus grande taille et de son ensemble d’entraînement plus grand.
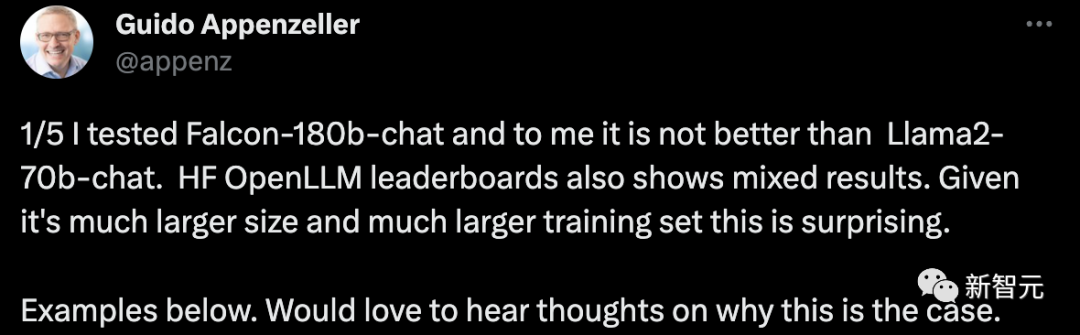
Par exemple :
Donnez quelques objets et laissez Falcon-180B et Llama2-70B y répondre respectivement pour voir quel est l'effet ?
Falcon-180B considère à tort la selle comme un animal. Llama2-70B a répondu de manière concise et a donné la bonne réponse.


Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment créer une base de données Oracle Comment créer une base de données Oracle
Apr 11, 2025 pm 02:36 PM
Comment créer une base de données Oracle Comment créer une base de données Oracle
Apr 11, 2025 pm 02:36 PM
Pour créer une base de données Oracle, la méthode commune consiste à utiliser l'outil graphique DBCA. Les étapes sont les suivantes: 1. Utilisez l'outil DBCA pour définir le nom DBN pour spécifier le nom de la base de données; 2. Définissez Syspassword et SystemPassword sur des mots de passe forts; 3. Définir les caractères et NationalCharacterset à Al32Utf8; 4. Définissez la taille de mémoire et les espaces de table pour s'ajuster en fonction des besoins réels; 5. Spécifiez le chemin du fichier log. Les méthodes avancées sont créées manuellement à l'aide de commandes SQL, mais sont plus complexes et sujets aux erreurs. Faites attention à la force du mot de passe, à la sélection du jeu de caractères, à la taille et à la mémoire de l'espace de table
 Comment créer une base de données Oracle Comment créer une base de données Oracle
Apr 11, 2025 pm 02:33 PM
Comment créer une base de données Oracle Comment créer une base de données Oracle
Apr 11, 2025 pm 02:33 PM
La création d'une base de données Oracle n'est pas facile, vous devez comprendre le mécanisme sous-jacent. 1. Vous devez comprendre les concepts de la base de données et des SGBD Oracle; 2. Master les concepts de base tels que SID, CDB (base de données de conteneurs), PDB (base de données enfichable); 3. Utilisez SQL * Plus pour créer CDB, puis créer PDB, vous devez spécifier des paramètres tels que la taille, le nombre de fichiers de données et les chemins; 4. Les applications avancées doivent ajuster le jeu de caractères, la mémoire et d'autres paramètres et effectuer un réglage des performances; 5. Faites attention à l'espace disque, aux autorisations et aux paramètres des paramètres, et surveillez et optimisez en continu les performances de la base de données. Ce n'est qu'en le maîtrisant habilement une pratique continue que vous pouvez vraiment comprendre la création et la gestion des bases de données Oracle.
 Comment rédiger des instructions de base de données Oracle
Apr 11, 2025 pm 02:42 PM
Comment rédiger des instructions de base de données Oracle
Apr 11, 2025 pm 02:42 PM
Le cœur des instructions Oracle SQL est sélectionné, insérer, mettre à jour et supprimer, ainsi que l'application flexible de diverses clauses. Il est crucial de comprendre le mécanisme d'exécution derrière l'instruction, tel que l'optimisation de l'indice. Les usages avancés comprennent des sous-requêtes, des requêtes de connexion, des fonctions d'analyse et PL / SQL. Les erreurs courantes incluent les erreurs de syntaxe, les problèmes de performances et les problèmes de cohérence des données. Les meilleures pratiques d'optimisation des performances impliquent d'utiliser des index appropriés, d'éviter la sélection *, d'optimiser les clauses et d'utiliser des variables liées. La maîtrise d'Oracle SQL nécessite de la pratique, y compris l'écriture de code, le débogage, la réflexion et la compréhension des mécanismes sous-jacents.
 Comment ajouter, modifier et supprimer le guide de fonctionnement du champ de table de données MySQL
Apr 11, 2025 pm 05:42 PM
Comment ajouter, modifier et supprimer le guide de fonctionnement du champ de table de données MySQL
Apr 11, 2025 pm 05:42 PM
Guide de fonctionnement du champ dans MySQL: Ajouter, modifier et supprimer les champs. Ajouter un champ: alter table table_name Ajouter Column_name data_type [pas null] [Default default_value] [Clé primaire] [Auto_increment] Modifier le champ: alter table table_name modifie Column_name data_type [pas null] [default default_value] [clé primaire]
 Quelles sont les contraintes d'intégrité des tables de base de données Oracle?
Apr 11, 2025 pm 03:42 PM
Quelles sont les contraintes d'intégrité des tables de base de données Oracle?
Apr 11, 2025 pm 03:42 PM
Les contraintes d'intégrité des bases de données Oracle peuvent garantir la précision des données, notamment: Not Null: les valeurs nulles sont interdites; Unique: garantie l'unicité, permettant une seule valeur nulle; Clé primaire: contrainte de clé primaire, renforcer unique et interdire les valeurs nulles; Clé étrangère: maintenir les relations entre les tableaux, les clés étrangères se réfèrent aux clés primaires primaires; Vérifiez: limitez les valeurs de colonne en fonction des conditions.
 Explication détaillée des instances de requête imbriquées dans la base de données MySQL
Apr 11, 2025 pm 05:48 PM
Explication détaillée des instances de requête imbriquées dans la base de données MySQL
Apr 11, 2025 pm 05:48 PM
Les requêtes imbriquées sont un moyen d'inclure une autre requête dans une requête. Ils sont principalement utilisés pour récupérer des données qui remplissent des conditions complexes, associer plusieurs tables et calculer des valeurs de résumé ou des informations statistiques. Les exemples incluent la recherche de salaires supérieurs aux employés, la recherche de commandes pour une catégorie spécifique et le calcul du volume des commandes totales pour chaque produit. Lorsque vous écrivez des requêtes imbriquées, vous devez suivre: écrire des sous-requêtes, écrire leurs résultats sur les requêtes extérieures (référencées avec des alias ou en tant que clauses) et optimiser les performances de la requête (en utilisant des index).
 Que fait Oracle
Apr 11, 2025 pm 06:06 PM
Que fait Oracle
Apr 11, 2025 pm 06:06 PM
Oracle est la plus grande société de logiciels de gestion de base de données au monde (SGBD). Ses principaux produits incluent les fonctions suivantes: Outils de développement du système de gestion de la base de données relationnels (Oracle Database) (Oracle Apex, Oracle Visual Builder) Middleware (Oracle Weblogic Server, Oracle Soa Suite) Cloud Service (Oracle Cloud Infrastructure) Analyse et Oracle Blockchain Pla Intelligence (Oracle Analytic
 Comment configurer le format de journal debian Apache
Apr 12, 2025 pm 11:30 PM
Comment configurer le format de journal debian Apache
Apr 12, 2025 pm 11:30 PM
Cet article décrit comment personnaliser le format de journal d'Apache sur les systèmes Debian. Les étapes suivantes vous guideront à travers le processus de configuration: Étape 1: Accédez au fichier de configuration Apache Le fichier de configuration apache principal du système Debian est généralement situé dans /etc/apache2/apache2.conf ou /etc/apache2/httpd.conf. Ouvrez le fichier de configuration avec les autorisations racinaires à l'aide de la commande suivante: sudonano / etc / apache2 / apache2.conf ou sudonano / etc / apache2 / httpd.conf Étape 2: définir les formats de journal personnalisés à trouver ou
