
 Périphériques technologiques
IA
Implémentation d'OpenAI CLIP sur des ensembles de données personnalisés
Périphériques technologiques
IA
Implémentation d'OpenAI CLIP sur des ensembles de données personnalisés
Implémentation d'OpenAI CLIP sur des ensembles de données personnalisés

En janvier 2021, OpenAI a annoncé deux nouveaux modèles : DALL-E et CLIP. Les deux modèles sont des modèles multimodaux qui relient le texte et les images d’une manière ou d’une autre. Le nom complet de CLIP est Contrastive Language-Image Pre-training (Contrastive Language-Image Pre-training), qui est une méthode de pré-formation basée sur des paires texte-image contrastées. Pourquoi introduire CLIP ? Parce que la diffusion stable actuellement populaire n’est pas un modèle unique, mais se compose de plusieurs modèles. L'un des composants clés est l'encodeur de texte, qui est utilisé pour encoder la saisie de texte de l'utilisateur, et cet encodeur de texte est l'encodeur de texte dans le modèle CLIP
Lorsque le modèle CLIP est entraîné, vous pouvez lui donner une phrase d'entrée. , et extrayez les images les plus pertinentes qui vont avec. CLIP apprend la relation entre une phrase complète et l'image qu'elle décrit. C'est-à-dire qu'il est formé sur des phrases complètes, plutôt que sur des catégories discrètes comme « voiture », « chien », etc. Ceci est crucial pour l'application. Lorsqu'il est formé sur des phrases complètes, le modèle peut en apprendre davantage et reconnaître des modèles entre les photos et le texte. Ils ont également démontré que le modèle fonctionne comme un classificateur lorsqu’il est formé sur un ensemble de données important composé de photos et de phrases correspondantes. Lorsque CLIP a été publié, ses performances de classification sur l'ensemble de données ImageNet ont dépassé celles de ResNets-50 après un réglage fin sans aucun réglage fin (zéro-shot), ce qui signifie qu'il est très utile.
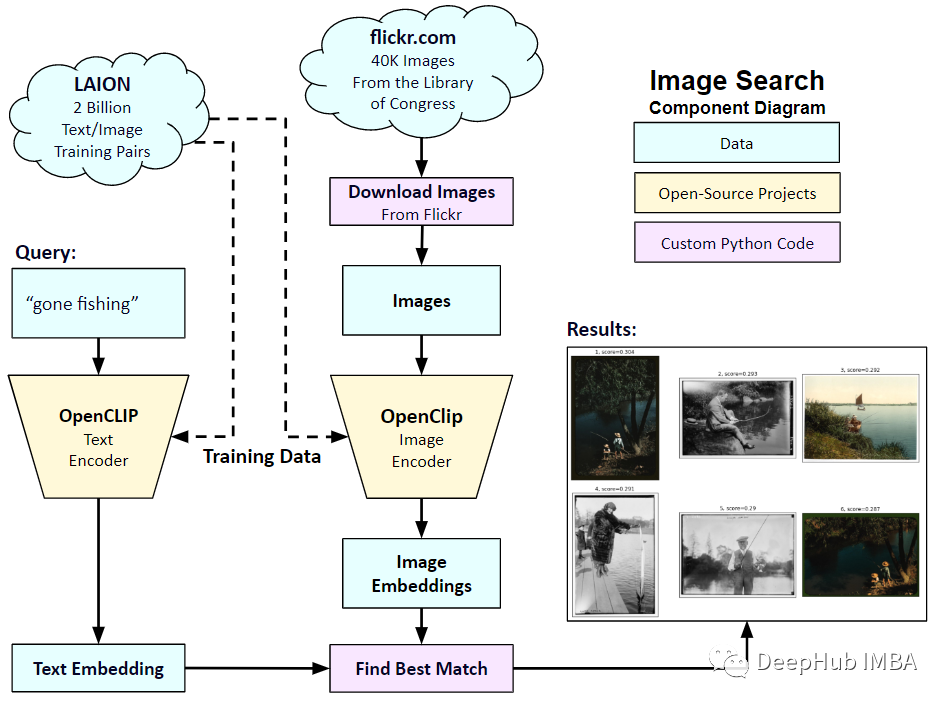
Donc, dans cet article, nous utiliserons PyTorch pour implémenter le modèle CLIP à partir de zéro afin que nous puissions avoir une meilleure compréhension de CLIP
Vous devez utiliser 2 bibliothèques ici : timm et transformers, Let's importez d'abord le code
import os import cv2 import gc import numpy as np import pandas as pd import itertools from tqdm.autonotebook import tqdm import albumentations as A import matplotlib.pyplot as plt import torch from torch import nn import torch.nn.functional as F import timm from transformers import DistilBertModel, DistilBertConfig, DistilBertTokenizer
L'étape suivante consiste à prétraiter les données et la configuration générale. config est un fichier python ordinaire dans lequel nous mettons tous les hyperparamètres. Si vous utilisez Jupyter Notebook, il s'agit d'une classe définie au début de Notebook.
class CFG:debug = Falseimage_path = "../input/flickr-image-dataset/flickr30k_images/flickr30k_images"captions_path = "."batch_size = 32num_workers = 4head_lr = 1e-3image_encoder_lr = 1e-4text_encoder_lr = 1e-5weight_decay = 1e-3patience = 1factor = 0.8epochs = 2device = torch.device("cuda" if torch.cuda.is_available() else "cpu") model_name = 'resnet50'image_embedding = 2048text_encoder_model = "distilbert-base-uncased"text_embedding = 768text_tokenizer = "distilbert-base-uncased"max_length = 200 pretrained = True # for both image encoder and text encodertrainable = True # for both image encoder and text encodertemperature = 1.0 # image sizesize = 224 # for projection head; used for both image and text encodersnum_projection_layers = 1projection_dim = 256 dropout = 0.1Il existe également des classes d'assistance pour nos indicateurs personnalisés
class AvgMeter:def __init__(self, name="Metric"):self.name = nameself.reset() def reset(self):self.avg, self.sum, self.count = [0] * 3 def update(self, val, count=1):self.count += countself.sum += val * countself.avg = self.sum / self.count def __repr__(self):text = f"{self.name}: {self.avg:.4f}"return text def get_lr(optimizer):for param_group in optimizer.param_groups:return param_group["lr"]Notre objectif est de décrire des images et des phrases. L'ensemble de données doit donc renvoyer à la fois des phrases et des images. Vous devez donc utiliser le tagueur DistilBERT pour baliser la phrase (titre), puis fournir l'identifiant de balise (input_ids) et le masque d'attention à DistilBERT. DistilBERT est plus petit que le modèle BERT, mais les résultats des modèles sont similaires, nous choisissons donc de l'utiliser.
L'étape suivante consiste à tokeniser à l'aide du tokenizer HuggingFace. L'objet tokenizer obtenu dans __init__ sera chargé lors de l'exécution du modèle. Le titre est complété et tronqué à une longueur maximale prédéterminée. Avant de charger l'image correspondante, nous chargerons une légende codée dans __getitem__, qui est un dictionnaire avec les clés input_ids et attention_mask, en la transformant et en l'augmentant (le cas échéant). Transformez-le ensuite en tenseur et stockez-le dans un dictionnaire avec "image" comme clé. Enfin, nous saisissons le texte original du titre dans le dictionnaire avec le mot-clé « titre ».
class CLIPDataset(torch.utils.data.Dataset):def __init__(self, image_filenames, captions, tokenizer, transforms):"""image_filenames and cpations must have the same length; so, if there aremultiple captions for each image, the image_filenames must have repetitivefile names """ self.image_filenames = image_filenamesself.captions = list(captions)self.encoded_captions = tokenizer(list(captions), padding=True, truncatinotallow=True, max_length=CFG.max_length)self.transforms = transforms def __getitem__(self, idx):item = {key: torch.tensor(values[idx])for key, values in self.encoded_captions.items()} image = cv2.imread(f"{CFG.image_path}/{self.image_filenames[idx]}")image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)image = self.transforms(image=image)['image']item['image'] = torch.tensor(image).permute(2, 0, 1).float()item['caption'] = self.captions[idx] return item def __len__(self):return len(self.captions) def get_transforms(mode="train"):if mode == "train":return A.Compose([A.Resize(CFG.size, CFG.size, always_apply=True),A.Normalize(max_pixel_value=255.0, always_apply=True),])else:return A.Compose([A.Resize(CFG.size, CFG.size, always_apply=True),A.Normalize(max_pixel_value=255.0, always_apply=True),])Encodeur d'image et de texte : nous utiliserons ResNet50 comme encodeur d'image.
class ImageEncoder(nn.Module):"""Encode images to a fixed size vector""" def __init__(self, model_name=CFG.model_name, pretrained=CFG.pretrained, trainable=CFG.trainable):super().__init__()self.model = timm.create_model(model_name, pretrained, num_classes=0, global_pool="avg")for p in self.model.parameters():p.requires_grad = trainable def forward(self, x):return self.model(x)
Utilisez DistilBERT comme encodeur de texte. Utilisez la représentation finale des jetons CLS pour obtenir la représentation complète de la phrase.
class TextEncoder(nn.Module):def __init__(self, model_name=CFG.text_encoder_model, pretrained=CFG.pretrained, trainable=CFG.trainable):super().__init__()if pretrained:self.model = DistilBertModel.from_pretrained(model_name)else:self.model = DistilBertModel(cnotallow=DistilBertConfig()) for p in self.model.parameters():p.requires_grad = trainable # we are using the CLS token hidden representation as the sentence's embeddingself.target_token_idx = 0 def forward(self, input_ids, attention_mask):output = self.model(input_ids=input_ids, attention_mask=attention_mask)last_hidden_state = output.last_hidden_statereturn last_hidden_state[:, self.target_token_idx, :]
Le code ci-dessus a codé l'image et le texte dans des vecteurs de taille fixe (image 2048, texte 768), nous avons besoin que l'image et le texte aient des dimensions similaires pour pouvoir les comparer, nous mettons donc les dimensions 2048 et 768 vecteurs dimensionnels Projetés à 256 dimensions (projection_dim), on ne peut les comparer que si les dimensions sont les mêmes.
class ProjectionHead(nn.Module):def __init__(self,embedding_dim,projection_dim=CFG.projection_dim,dropout=CFG.dropout):super().__init__()self.projection = nn.Linear(embedding_dim, projection_dim)self.gelu = nn.GELU()self.fc = nn.Linear(projection_dim, projection_dim)self.dropout = nn.Dropout(dropout)self.layer_norm = nn.LayerNorm(projection_dim) def forward(self, x):projected = self.projection(x)x = self.gelu(projected)x = self.fc(x)x = self.dropout(x)x = x + projectedx = self.layer_norm(x)return x
Donc notre modèle CLIP final ressemble à ceci :
class CLIPModel(nn.Module):def __init__(self,temperature=CFG.temperature,image_embedding=CFG.image_embedding,text_embedding=CFG.text_embedding,):super().__init__()self.image_encoder = ImageEncoder()self.text_encoder = TextEncoder()self.image_projection = ProjectionHead(embedding_dim=image_embedding)self.text_projection = ProjectionHead(embedding_dim=text_embedding)self.temperature = temperature def forward(self, batch):# Getting Image and Text Featuresimage_features = self.image_encoder(batch["image"])text_features = self.text_encoder(input_ids=batch["input_ids"], attention_mask=batch["attention_mask"])# Getting Image and Text Embeddings (with same dimension)image_embeddings = self.image_projection(image_features)text_embeddings = self.text_projection(text_features) # Calculating the Losslogits = (text_embeddings @ image_embeddings.T) / self.temperatureimages_similarity = image_embeddings @ image_embeddings.Ttexts_similarity = text_embeddings @ text_embeddings.Ttargets = F.softmax((images_similarity + texts_similarity) / 2 * self.temperature, dim=-1)texts_loss = cross_entropy(logits, targets, reductinotallow='none')images_loss = cross_entropy(logits.T, targets.T, reductinotallow='none')loss = (images_loss + texts_loss) / 2.0 # shape: (batch_size)return loss.mean() #这里还加了一个交叉熵函数 def cross_entropy(preds, targets, reductinotallow='none'):log_softmax = nn.LogSoftmax(dim=-1)loss = (-targets * log_softmax(preds)).sum(1)if reduction == "none":return losselif reduction == "mean":return loss.mean()
Il faut expliquer ici que CLIP utilise l'entropie croisée symétrique comme fonction de perte, ce qui peut réduire l'impact du bruit et améliorer la robustesse du modèle. . Pour plus de simplicité, nous utilisons simplement l'entropie croisée.
Nous pouvons tester :
# A simple Example batch_size = 4 dim = 256 embeddings = torch.randn(batch_size, dim) out = embeddings @ embeddings.T print(F.softmax(out, dim=-1))
La prochaine étape est la formation. Certaines fonctions peuvent nous aider à charger le chargeur de données de formation et de vérification
def make_train_valid_dfs():dataframe = pd.read_csv(f"{CFG.captions_path}/captions.csv")max_id = dataframe["id"].max() + 1 if not CFG.debug else 100image_ids = np.arange(0, max_id)np.random.seed(42)valid_ids = np.random.choice(image_ids, size=int(0.2 * len(image_ids)), replace=False)train_ids = [id_ for id_ in image_ids if id_ not in valid_ids]train_dataframe = dataframe[dataframe["id"].isin(train_ids)].reset_index(drop=True)valid_dataframe = dataframe[dataframe["id"].isin(valid_ids)].reset_index(drop=True)return train_dataframe, valid_dataframe def build_loaders(dataframe, tokenizer, mode):transforms = get_transforms(mode=mode)dataset = CLIPDataset(dataframe["image"].values,dataframe["caption"].values,tokenizer=tokenizer,transforms=transforms,)dataloader = torch.utils.data.DataLoader(dataset,batch_size=CFG.batch_size,num_workers=CFG.num_workers,shuffle=True if mode == "train" else False,)return dataloaderEnsuite, c'est la formation et l'évaluation
def train_epoch(model, train_loader, optimizer, lr_scheduler, step):loss_meter = AvgMeter()tqdm_object = tqdm(train_loader, total=len(train_loader))for batch in tqdm_object:batch = {k: v.to(CFG.device) for k, v in batch.items() if k != "caption"}loss = model(batch)optimizer.zero_grad()loss.backward()optimizer.step()if step == "batch":lr_scheduler.step() count = batch["image"].size(0)loss_meter.update(loss.item(), count) tqdm_object.set_postfix(train_loss=loss_meter.avg, lr=get_lr(optimizer))return loss_meter def valid_epoch(model, valid_loader):loss_meter = AvgMeter() tqdm_object = tqdm(valid_loader, total=len(valid_loader))for batch in tqdm_object:batch = {k: v.to(CFG.device) for k, v in batch.items() if k != "caption"}loss = model(batch) count = batch["image"].size(0)loss_meter.update(loss.item(), count) tqdm_object.set_postfix(valid_loss=loss_meter.avg)return loss_meterEnfin intégré. C'est tout
def main():train_df, valid_df = make_train_valid_dfs()tokenizer = DistilBertTokenizer.from_pretrained(CFG.text_tokenizer)train_loader = build_loaders(train_df, tokenizer, mode="train")valid_loader = build_loaders(valid_df, tokenizer, mode="valid") model = CLIPModel().to(CFG.device)params = [{"params": model.image_encoder.parameters(), "lr": CFG.image_encoder_lr},{"params": model.text_encoder.parameters(), "lr": CFG.text_encoder_lr},{"params": itertools.chain(model.image_projection.parameters(), model.text_projection.parameters()), "lr": CFG.head_lr, "weight_decay": CFG.weight_decay}]optimizer = torch.optim.AdamW(params, weight_decay=0.)lr_scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode="min", patience=CFG.patience, factor=CFG.factor)step = "epoch" best_loss = float('inf')for epoch in range(CFG.epochs):print(f"Epoch: {epoch + 1}")model.train()train_loss = train_epoch(model, train_loader, optimizer, lr_scheduler, step)model.eval()with torch.no_grad():valid_loss = valid_epoch(model, valid_loader) if valid_loss.avg <p><span>App : obtenez des intégrations d'images et trouvez des correspondances. </span></p><p><span>Comment l'appliquer en pratique après avoir terminé la formation ? Nous devons écrire une fonction qui charge le modèle entraîné, lui fournit des images de l'ensemble de validation et renvoie la forme (valid_set_size, 256) et les image_embeddings du modèle lui-même. La méthode d'appel de </span></p><pre class="brush:php;toolbar:false">def get_image_embeddings(valid_df, model_path):tokenizer = DistilBertTokenizer.from_pretrained(CFG.text_tokenizer)valid_loader = build_loaders(valid_df, tokenizer, mode="valid") model = CLIPModel().to(CFG.device)model.load_state_dict(torch.load(model_path, map_locatinotallow=CFG.device))model.eval() valid_image_embeddings = []with torch.no_grad():for batch in tqdm(valid_loader):image_features = model.image_encoder(batch["image"].to(CFG.device))image_embeddings = model.image_projection(image_features)valid_image_embeddings.append(image_embeddings)return model, torch.cat(valid_image_embeddings) _, valid_df = make_train_valid_dfs() model, image_embeddings = get_image_embeddings(valid_df, "best.pt") def find_matches(model, image_embeddings, query, image_filenames, n=9):tokenizer = DistilBertTokenizer.from_pretrained(CFG.text_tokenizer)encoded_query = tokenizer([query])batch = {key: torch.tensor(values).to(CFG.device)for key, values in encoded_query.items()}with torch.no_grad():text_features = model.text_encoder(input_ids=batch["input_ids"], attention_mask=batch["attention_mask"])text_embeddings = model.text_projection(text_features) image_embeddings_n = F.normalize(image_embeddings, p=2, dim=-1)text_embeddings_n = F.normalize(text_embeddings, p=2, dim=-1)dot_similarity = text_embeddings_n @ image_embeddings_n.T values, indices = torch.topk(dot_similarity.squeeze(0), n * 5)matches = [image_filenames[idx] for idx in indices[::5]] _, axes = plt.subplots(3, 3, figsize=(10, 10))for match, ax in zip(matches, axes.flatten()):image = cv2.imread(f"{CFG.image_path}/{match}")image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)ax.imshow(image)ax.axis("off") plt.show()est la suivante :
find_matches(model, image_embeddings,query="one dog sitting on the grass",image_filenames=valid_df['image'].values,n=9)
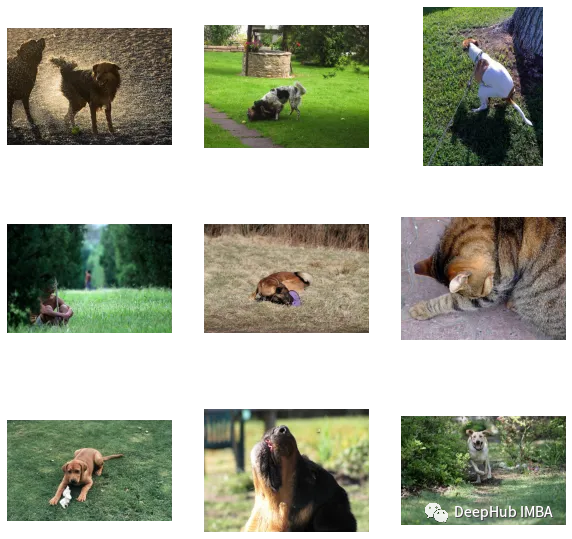
On voit que l'effet de notre personnalisation est bon (mais il y a un chat sur la photo, haha). En d'autres termes, la méthode CLIP est également réalisable pour être personnalisée sur de petits ensembles de données
Voici le code et l'ensemble de données de cet article :
https://www.kaggle.com/code/jyotidabas/simple -openai-clip-implémentation
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Un nouveau paradigme de programmation, quand Spring Boot rencontre OpenAI
Feb 01, 2024 pm 09:18 PM
Un nouveau paradigme de programmation, quand Spring Boot rencontre OpenAI
Feb 01, 2024 pm 09:18 PM
En 2023, la technologie de l’IA est devenue un sujet brûlant et a un impact énorme sur diverses industries, notamment dans le domaine de la programmation. Les gens sont de plus en plus conscients de l’importance de la technologie de l’IA, et la communauté Spring ne fait pas exception. Avec l’évolution continue de la technologie GenAI (Intelligence Artificielle Générale), il est devenu crucial et urgent de simplifier la création d’applications dotées de fonctions d’IA. Dans ce contexte, « SpringAI » a émergé, visant à simplifier le processus de développement d'applications fonctionnelles d'IA, en le rendant simple et intuitif et en évitant une complexité inutile. Grâce à « SpringAI », les développeurs peuvent plus facilement créer des applications dotées de fonctions d'IA, ce qui les rend plus faciles à utiliser et à exploiter.
 Choisir le modèle d'intégration qui correspond le mieux à vos données : un test comparatif des intégrations multilingues OpenAI et open source
Feb 26, 2024 pm 06:10 PM
Choisir le modèle d'intégration qui correspond le mieux à vos données : un test comparatif des intégrations multilingues OpenAI et open source
Feb 26, 2024 pm 06:10 PM
OpenAI a récemment annoncé le lancement de son modèle d'intégration de dernière génération, embeddingv3, qui, selon eux, est le modèle d'intégration le plus performant avec des performances multilingues plus élevées. Ce lot de modèles est divisé en deux types : les plus petits text-embeddings-3-small et les plus puissants et plus grands text-embeddings-3-large. Peu d'informations sont divulguées sur la façon dont ces modèles sont conçus et formés, et les modèles ne sont accessibles que via des API payantes. Il existe donc de nombreux modèles d'intégration open source. Mais comment ces modèles open source se comparent-ils au modèle open source open source ? Cet article comparera empiriquement les performances de ces nouveaux modèles avec des modèles open source. Nous prévoyons de créer une donnée
 Travail posthume de l'équipe OpenAI Super Alignment : deux grands modèles jouent à un jeu et le résultat devient plus compréhensible
Jul 19, 2024 am 01:29 AM
Travail posthume de l'équipe OpenAI Super Alignment : deux grands modèles jouent à un jeu et le résultat devient plus compréhensible
Jul 19, 2024 am 01:29 AM
Si la réponse donnée par le modèle d’IA est incompréhensible du tout, oseriez-vous l’utiliser ? À mesure que les systèmes d’apprentissage automatique sont utilisés dans des domaines de plus en plus importants, il devient de plus en plus important de démontrer pourquoi nous pouvons faire confiance à leurs résultats, et quand ne pas leur faire confiance. Une façon possible de gagner confiance dans le résultat d'un système complexe est d'exiger que le système produise une interprétation de son résultat qui soit lisible par un humain ou un autre système de confiance, c'est-à-dire entièrement compréhensible au point que toute erreur possible puisse être trouvé. Par exemple, pour renforcer la confiance dans le système judiciaire, nous exigeons que les tribunaux fournissent des avis écrits clairs et lisibles qui expliquent et soutiennent leurs décisions. Pour les grands modèles de langage, nous pouvons également adopter une approche similaire. Cependant, lorsque vous adoptez cette approche, assurez-vous que le modèle de langage génère
 L'éditeur Zed basé sur Rust est open source, avec prise en charge intégrée d'OpenAI et GitHub Copilot
Feb 01, 2024 pm 02:51 PM
L'éditeur Zed basé sur Rust est open source, avec prise en charge intégrée d'OpenAI et GitHub Copilot
Feb 01, 2024 pm 02:51 PM
Auteur丨Compilé par TimAnderson丨Produit par Noah|51CTO Technology Stack (WeChat ID : blog51cto) Le projet d'éditeur Zed est encore en phase de pré-version et a été open source sous licences AGPL, GPL et Apache. L'éditeur offre des performances élevées et plusieurs options assistées par l'IA, mais n'est actuellement disponible que sur la plate-forme Mac. Nathan Sobo a expliqué dans un article que dans la base de code du projet Zed sur GitHub, la partie éditeur est sous licence GPL, les composants côté serveur sont sous licence AGPL et la partie GPUI (GPU Accelerated User) l'interface) adopte la Licence Apache2.0. GPUI est un produit développé par l'équipe Zed
 N'attendez pas OpenAI, attendez qu'Open-Sora soit entièrement open source
Mar 18, 2024 pm 08:40 PM
N'attendez pas OpenAI, attendez qu'Open-Sora soit entièrement open source
Mar 18, 2024 pm 08:40 PM
Il n'y a pas si longtemps, OpenAISora est rapidement devenu populaire grâce à ses étonnants effets de génération vidéo. Il s'est démarqué parmi la foule de modèles vidéo littéraires et est devenu le centre d'attention mondiale. Suite au lancement du processus de reproduction d'inférence de formation Sora avec une réduction des coûts de 46 % il y a 2 semaines, l'équipe Colossal-AI a entièrement open source le premier modèle de génération vidéo d'architecture de type Sora au monde "Open-Sora1.0", couvrant l'ensemble processus de formation, y compris le traitement des données, tous les détails de la formation et les poids des modèles, et joignez-vous aux passionnés mondiaux de l'IA pour promouvoir une nouvelle ère de création vidéo. Pour un aperçu, jetons un œil à une vidéo d'une ville animée générée par le modèle « Open-Sora1.0 » publié par l'équipe Colossal-AI. Ouvrir-Sora1.0
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 Microsoft et OpenAI prévoient d'investir 100 millions de dollars dans des robots humanoïdes ! Les internautes appellent Musk
Feb 01, 2024 am 11:18 AM
Microsoft et OpenAI prévoient d'investir 100 millions de dollars dans des robots humanoïdes ! Les internautes appellent Musk
Feb 01, 2024 am 11:18 AM
Il a été révélé que Microsoft et OpenAI investissaient de grosses sommes d’argent dans une start-up de robots humanoïdes au début de l’année. Parmi eux, Microsoft prévoit d'investir 95 millions de dollars et OpenAI investira 5 millions de dollars. Selon Bloomberg, la société devrait lever un total de 500 millions de dollars au cours de ce cycle, et sa valorisation pré-monétaire pourrait atteindre 1,9 milliard de dollars. Qu'est-ce qui les attire ? Jetons d’abord un coup d’œil aux réalisations de cette entreprise en matière de robotique. Ce robot est tout argenté et noir, et son apparence ressemble à l'image d'un robot dans un blockbuster de science-fiction hollywoodien : maintenant, il met une capsule de café dans la machine à café : si elle n'est pas placée correctement, elle s'ajustera sans aucun problème. télécommande humaine : Cependant, après un certain temps, une tasse de café peut être emportée et dégustée : Avez-vous des membres de votre famille qui l'ont reconnu ? Oui, ce robot a été créé il y a quelque temps.
 Les performances d'exécution locale du service Embedding dépassent celles d'OpenAI Text-Embedding-Ada-002, ce qui est très pratique !
Apr 15, 2024 am 09:01 AM
Les performances d'exécution locale du service Embedding dépassent celles d'OpenAI Text-Embedding-Ada-002, ce qui est très pratique !
Apr 15, 2024 am 09:01 AM
Ollama est un outil super pratique qui vous permet d'exécuter facilement des modèles open source tels que Llama2, Mistral et Gemma localement. Dans cet article, je vais vous présenter comment utiliser Ollama pour vectoriser du texte. Si vous n'avez pas installé Ollama localement, vous pouvez lire cet article. Dans cet article, nous utiliserons le modèle nomic-embed-text[2]. Il s'agit d'un encodeur de texte qui surpasse OpenAI text-embedding-ada-002 et text-embedding-3-small sur les tâches à contexte court et à contexte long. Démarrez le service nomic-embed-text lorsque vous avez installé avec succès o
