

Utilisé pour la pré-formation auto-supervisée SOTA !


Idée de thèse :
l'encodage automatique masqué est devenu un paradigme de pré-formation réussi pour les modèles Transformer de texte, d'images et, plus récemment, de nuages de points. Les ensembles de données brutes sur les voitures conviennent à la pré-formation auto-supervisée car ils sont généralement moins coûteux à collecter que l'annotation pour des tâches telles que la détection d'objets 3D (OD). Cependant, le développement d’auto-encodeurs masqués pour les nuages de points s’est uniquement concentré sur les données synthétiques et intérieures. Par conséquent, les méthodes existantes ont adapté leurs représentations et modèles en nuages de points petits et denses avec une densité de points uniforme. Dans ce travail, nous étudions l'autoencodage masqué sur des nuages de points dans des contextes automobiles, qui sont clairsemés et dont la densité peut varier considérablement entre différents objets d'une même scène. À cette fin, cet article propose Voxel-MAE, un schéma simple de pré-entraînement à l'auto-codage masqué conçu pour la représentation des voxels. Cet article pré-entraîne un squelette de détecteur d'objets 3D basé sur Transformer pour reconstruire les voxels masqués et distinguer les voxels vides des voxels non vides. Notre méthode améliore les performances 3D OD de 1,75 mAP et 1,05 NDS sur l'ensemble de données complexe nuScenes. De plus, nous montrons qu'en utilisant Voxel-MAE pour la pré-formation, nous n'avons besoin que de 40 % de données annotées pour surpasser les données équivalentes avec initialisation aléatoire.
Principales contributions :
Cet article propose Voxel-MAE (une méthode de déploiement de pré-entraînement auto-supervisé de style MAE sur des nuages de points voxélisés), et l'exécute sur le grand ensemble de données de nuages de points automobiles nuScenes. . La méthode présentée dans cet article est le premier programme de pré-formation auto-supervisé utilisant le réseau fédérateur de nuage de points automobile Transformer.
Cet article adapte notre méthode de représentation des voxels et utilise un ensemble unique de tâches de reconstruction pour capturer les caractéristiques des nuages de points voxélisés.
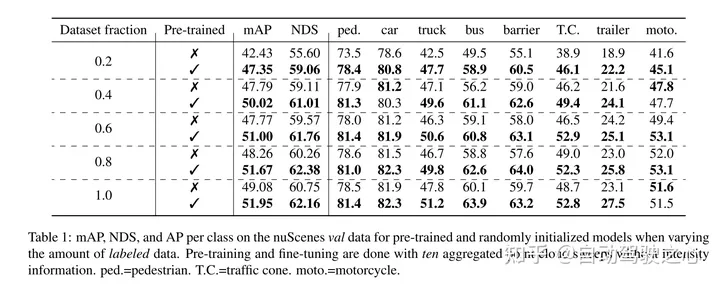
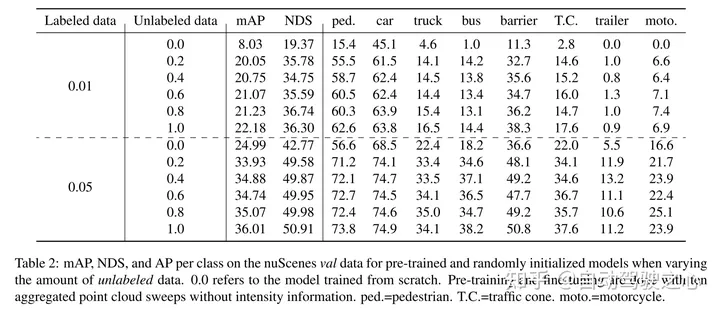
Cet article prouve que notre méthode est efficace en matière de données et réduit le besoin de données annotées. Avec une pré-formation, cet article surpasse les données entièrement supervisées en utilisant seulement 40 % des données annotées.
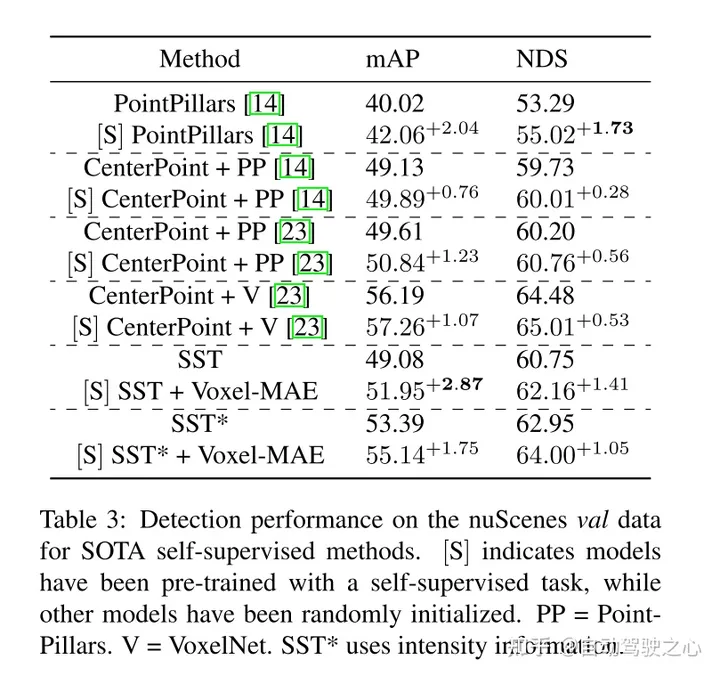
De plus, cet article révèle que Voxel-MAE améliore les performances des détecteurs basés sur transformateur de 1,75 point de pourcentage dans mAP et de 1,05 point de pourcentage dans NDS, améliorant ainsi ses performances par rapport aux méthodes auto-supervisées existantes.
Conception de réseau :
Le but de ce travail est d'étendre la pré-formation de style MAE aux nuages de points voxélisés. L'idée principale est toujours d'utiliser un encodeur pour créer une représentation latente riche à partir d'observations partielles de l'entrée, puis d'utiliser un décodeur pour reconstruire l'entrée d'origine, comme le montre la figure 2. Après la pré-formation, l'encodeur est utilisé comme épine dorsale du détecteur d'objets 3D. Cependant, en raison des différences fondamentales entre les images et les nuages de points, certaines modifications sont nécessaires pour une formation efficace de Voxel-MAE.
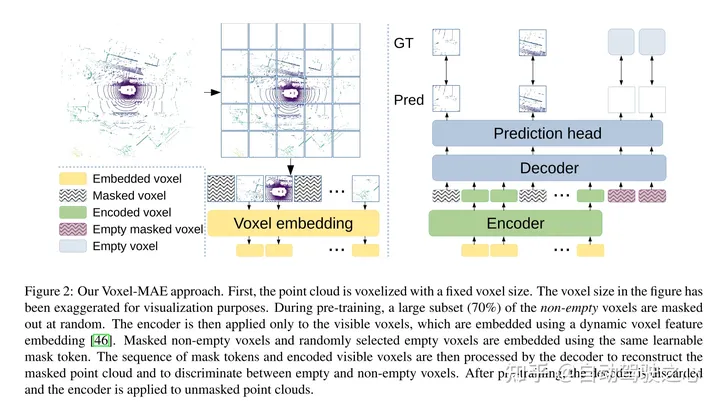
Figure 2 : Méthode Voxel-MAE de cet article. Tout d’abord, le nuage de points est voxélisé avec une taille de voxel fixe. Les tailles de voxels dans les figures ont été exagérées à des fins de visualisation. Avant l'entraînement, une grande partie (70 %) des voxels non vides sont masqués de manière aléatoire. L'encodeur est ensuite appliqué uniquement aux voxels visibles, intégrant ces voxels à l'aide de l'intégration de fonctionnalités de voxels dynamiques [46]. Les voxels non vides masqués et les voxels vides sélectionnés au hasard sont intégrés à l'aide des mêmes jetons de masque apprenables. Le décodeur traite ensuite la séquence de jetons de masque et la séquence codée de voxels visibles pour reconstruire le nuage de points masqué et distinguer les voxels vides des voxels non vides. Après le pré-entraînement, le décodeur est abandonné et l'encodeur est appliqué au nuage de points non masqué.

Figure 1 : MAE (à gauche) divise l'image en patchs de taille fixe qui ne se chevauchent pas. Les méthodes de modélisation de points masqués existantes (au milieu) créent un nombre fixe de patchs de nuages de points en utilisant l'échantillonnage des points les plus éloignés et les k voisins les plus proches. Notre méthode (à droite) utilise des voxels non superposés et un nombre dynamique de points.
Résultats expérimentaux :
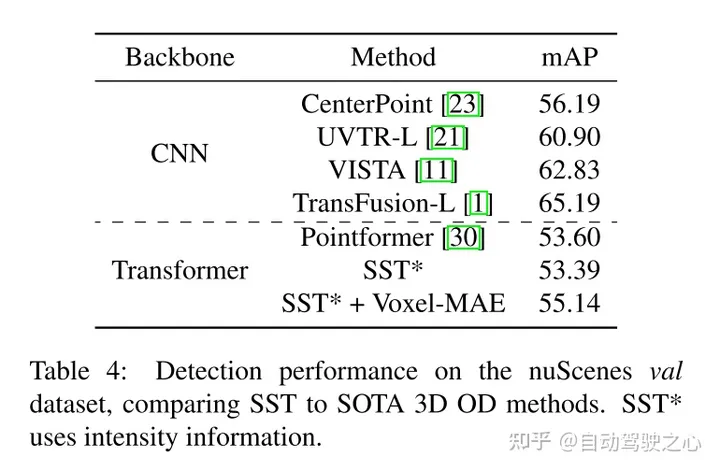
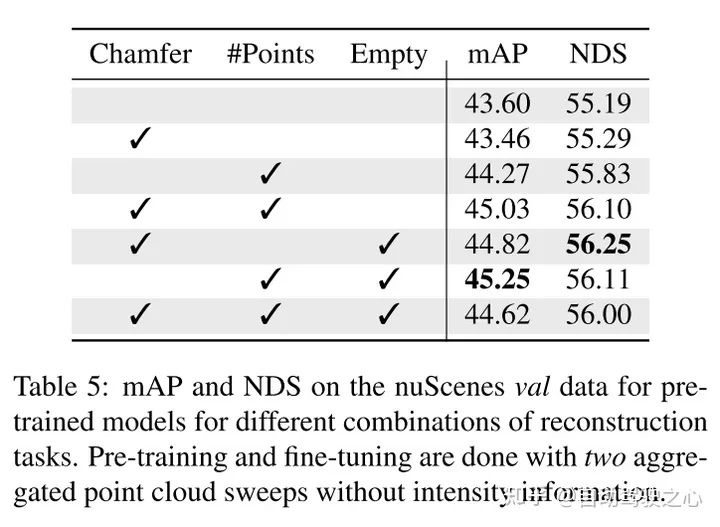
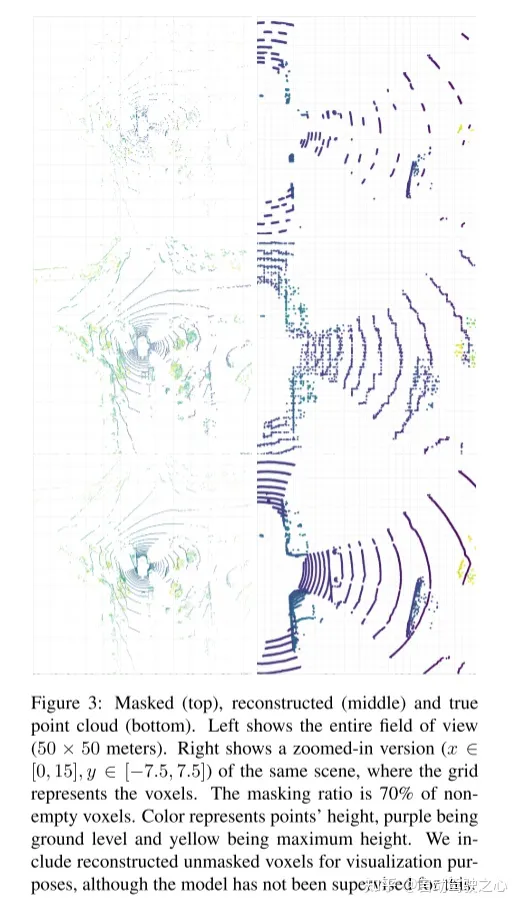
引用:
Hess G, Jaxing J, Svensson E, et al. Auto-encodeur masqué pour la pré-formation auto-supervisée sur les nuages de points lidar[C]//Actes de la conférence d'hiver IEEE/CVF sur les applications de la vision par ordinateur. 2023 : 350-359.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le papier Stable Diffusion 3 est enfin publié, et les détails architecturaux sont révélés. Cela aidera-t-il à reproduire Sora ?
Mar 06, 2024 pm 05:34 PM
Le papier Stable Diffusion 3 est enfin publié, et les détails architecturaux sont révélés. Cela aidera-t-il à reproduire Sora ?
Mar 06, 2024 pm 05:34 PM
L'article de StableDiffusion3 est enfin là ! Ce modèle est sorti il y a deux semaines et utilise la même architecture DiT (DiffusionTransformer) que Sora. Il a fait beaucoup de bruit dès sa sortie. Par rapport à la version précédente, la qualité des images générées par StableDiffusion3 a été considérablement améliorée. Il prend désormais en charge les invites multithèmes, et l'effet d'écriture de texte a également été amélioré et les caractères tronqués n'apparaissent plus. StabilityAI a souligné que StableDiffusion3 est une série de modèles avec des tailles de paramètres allant de 800M à 8B. Cette plage de paramètres signifie que le modèle peut être exécuté directement sur de nombreux appareils portables, réduisant ainsi considérablement l'utilisation de l'IA.
 Avez-vous vraiment maîtrisé la conversion des systèmes de coordonnées ? Des enjeux multi-capteurs indispensables à la conduite autonome
Oct 12, 2023 am 11:21 AM
Avez-vous vraiment maîtrisé la conversion des systèmes de coordonnées ? Des enjeux multi-capteurs indispensables à la conduite autonome
Oct 12, 2023 am 11:21 AM
Le premier article pilote et clé présente principalement plusieurs systèmes de coordonnées couramment utilisés dans la technologie de conduite autonome, et comment compléter la corrélation et la conversion entre eux, et enfin construire un modèle d'environnement unifié. L'objectif ici est de comprendre la conversion du véhicule en corps rigide de caméra (paramètres externes), la conversion de caméra en image (paramètres internes) et la conversion d'image en unité de pixel. La conversion de 3D en 2D aura une distorsion, une traduction, etc. Points clés : Le système de coordonnées du véhicule et le système de coordonnées du corps de la caméra doivent être réécrits : le système de coordonnées planes et le système de coordonnées des pixels Difficulté : la distorsion de l'image doit être prise en compte. La dé-distorsion et l'ajout de distorsion sont compensés sur le plan de l'image. 2. Introduction Il existe quatre systèmes de vision au total : système de coordonnées du plan de pixels (u, v), système de coordonnées d'image (x, y), système de coordonnées de caméra () et système de coordonnées mondiales (). Il existe une relation entre chaque système de coordonnées,
 Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
La prédiction de trajectoire joue un rôle important dans la conduite autonome. La prédiction de trajectoire de conduite autonome fait référence à la prédiction de la trajectoire de conduite future du véhicule en analysant diverses données pendant le processus de conduite du véhicule. En tant que module central de la conduite autonome, la qualité de la prédiction de trajectoire est cruciale pour le contrôle de la planification en aval. La tâche de prédiction de trajectoire dispose d'une riche pile technologique et nécessite une connaissance de la perception dynamique/statique de la conduite autonome, des cartes de haute précision, des lignes de voie, des compétences en architecture de réseau neuronal (CNN&GNN&Transformer), etc. Il est très difficile de démarrer ! De nombreux fans espèrent se lancer dans la prédiction de trajectoire le plus tôt possible et éviter les pièges. Aujourd'hui, je vais faire le point sur quelques problèmes courants et des méthodes d'apprentissage introductives pour la prédiction de trajectoire ! Connaissances introductives 1. Existe-t-il un ordre d'entrée pour les épreuves de prévisualisation ? R : Regardez d’abord l’enquête, p
 DualBEV : dépassant largement BEVFormer et BEVDet4D, ouvrez le livre !
Mar 21, 2024 pm 05:21 PM
DualBEV : dépassant largement BEVFormer et BEVDet4D, ouvrez le livre !
Mar 21, 2024 pm 05:21 PM
Cet article explore le problème de la détection précise d'objets sous différents angles de vue (tels que la perspective et la vue à vol d'oiseau) dans la conduite autonome, en particulier comment transformer efficacement les caractéristiques de l'espace en perspective (PV) en vue à vol d'oiseau (BEV). implémenté via le module Visual Transformation (VT). Les méthodes existantes sont globalement divisées en deux stratégies : la conversion 2D en 3D et la conversion 3D en 2D. Les méthodes 2D vers 3D améliorent les caractéristiques 2D denses en prédisant les probabilités de profondeur, mais l'incertitude inhérente aux prévisions de profondeur, en particulier dans les régions éloignées, peut introduire des inexactitudes. Alors que les méthodes 3D vers 2D utilisent généralement des requêtes 3D pour échantillonner des fonctionnalités 2D et apprendre les poids d'attention de la correspondance entre les fonctionnalités 3D et 2D via un transformateur, ce qui augmente le temps de calcul et de déploiement.
 Le premier modèle mondial de génération de vidéos de scènes de conduite autonomes multi-vues DrivingDiffusion : nouvelles idées pour les données et la simulation BEV
Oct 23, 2023 am 11:13 AM
Le premier modèle mondial de génération de vidéos de scènes de conduite autonomes multi-vues DrivingDiffusion : nouvelles idées pour les données et la simulation BEV
Oct 23, 2023 am 11:13 AM
Quelques réflexions personnelles de l'auteur Dans le domaine de la conduite autonome, avec le développement de sous-tâches/solutions de bout en bout basées sur BEV, les données d'entraînement multi-vues de haute qualité et la construction de scènes de simulation correspondantes sont devenues de plus en plus importantes. En réponse aux problèmes des tâches actuelles, la « haute qualité » peut être divisée en trois aspects : des scénarios à longue traîne dans différentes dimensions : comme les véhicules à courte portée dans les données sur les obstacles et les angles de cap précis lors du découpage des voitures, et les données sur les lignes de voie. . Scènes telles que des courbes avec des courbures différentes ou des rampes/fusions/fusions difficiles à capturer. Celles-ci reposent souvent sur de grandes quantités de données collectées et sur des stratégies complexes d’exploration de données, qui sont coûteuses. Valeur réelle 3D - image hautement cohérente : l'acquisition actuelle des données BEV est souvent affectée par des erreurs d'installation/calibrage du capteur, des cartes de haute précision et l'algorithme de reconstruction lui-même. cela m'a amené à
 Comprenez facilement les images 4K HD ! Ce grand modèle multimodal analyse automatiquement le contenu des affiches Web, ce qui le rend très pratique pour les travailleurs.
Apr 23, 2024 am 08:04 AM
Comprenez facilement les images 4K HD ! Ce grand modèle multimodal analyse automatiquement le contenu des affiches Web, ce qui le rend très pratique pour les travailleurs.
Apr 23, 2024 am 08:04 AM
Un modèle volumineux capable d'analyser automatiquement le contenu des PDF, des pages Web, des affiches et des graphiques Excel n'est pas très pratique pour les travailleurs. Le modèle InternLM-XComposer2-4KHD (en abrégé IXC2-4KHD) proposé par Shanghai AILab, l'Université chinoise de Hong Kong et d'autres instituts de recherche en fait une réalité. Par rapport à d'autres grands modèles multimodaux qui ont une limite de résolution ne dépassant pas 1 500 x 1 500, ce travail augmente l'image d'entrée maximale des grands modèles multimodaux à une résolution supérieure à 4K (3 840 x 1 600) et prend en charge n'importe quel rapport d'aspect et 336 pixels en 4K. Changements de résolution dynamiques. Trois jours après sa sortie, le modèle était en tête de la liste de popularité des modèles de réponses visuelles aux questions HuggingFace. Facile à manier
 GSLAM | Une architecture générale et un benchmark
Oct 20, 2023 am 11:37 AM
GSLAM | Une architecture générale et un benchmark
Oct 20, 2023 am 11:37 AM
J'ai soudainement découvert un article vieux de 19 ans GSLAM : A General SLAM Framework and Benchmark open source code : https://github.com/zdzhaoyong/GSLAM Accédez directement au texte intégral et ressentez la qualité de ce travail ~ 1 Technologie SLAM abstraite a remporté de nombreux succès récemment et a attiré de nombreuses entreprises de haute technologie. Cependant, la question de savoir comment s'interfacer avec les algorithmes existants ou émergents pour effectuer efficacement des analyses comparatives en termes de vitesse, de robustesse et de portabilité reste une question. Dans cet article, une nouvelle plateforme SLAM appelée GSLAM est proposée, qui fournit non seulement des capacités d'évaluation, mais fournit également aux chercheurs un moyen utile de développer rapidement leurs propres systèmes SLAM.
 'Minecraft' se transforme en une ville IA et les habitants des PNJ jouent comme de vraies personnes
Jan 02, 2024 pm 06:25 PM
'Minecraft' se transforme en une ville IA et les habitants des PNJ jouent comme de vraies personnes
Jan 02, 2024 pm 06:25 PM
Veuillez noter que cet homme carré fronça les sourcils, pensant à l'identité des « invités non invités » devant lui. Il s’est avéré qu’elle se trouvait dans une situation dangereuse, et une fois qu’elle s’en est rendu compte, elle a rapidement commencé une recherche mentale pour trouver une stratégie pour résoudre le problème. Finalement, elle a décidé de fuir les lieux, de demander de l'aide le plus rapidement possible et d'agir immédiatement. En même temps, la personne de l'autre côté pensait la même chose qu'elle... Il y avait une telle scène dans "Minecraft" où tous les personnages étaient contrôlés par l'intelligence artificielle. Chacun d’eux a un cadre identitaire unique. Par exemple, la jeune fille mentionnée précédemment est une coursière de 17 ans mais intelligente et courageuse. Ils ont la capacité de se souvenir, de penser et de vivre comme des humains dans cette petite ville de Minecraft. Ce qui les anime est une toute nouvelle,
