
 Périphériques technologiques
IA
Andrew Ng aime ça ! Des chercheurs de Harvard et du MIT ont utilisé les échecs pour prouver que les grands modèles de langage « comprennent » effectivement le monde.
Périphériques technologiques
IA
Andrew Ng aime ça ! Des chercheurs de Harvard et du MIT ont utilisé les échecs pour prouver que les grands modèles de langage « comprennent » effectivement le monde.
Andrew Ng aime ça ! Des chercheurs de Harvard et du MIT ont utilisé les échecs pour prouver que les grands modèles de langage « comprennent » effectivement le monde.

En 2021, Emily M. Bender, linguiste à l'Université de Washington, a publié un article affirmant que les grands modèles de langage ne sont rien de plus que des « perroquets stochastiques ». Ils ne comprennent pas le monde réel et ne comptent donc que les occurrences d'un certain mot. génère aléatoirement des mots plausibles comme un perroquet.
En raison du caractère ininterprétable des réseaux de neurones, la communauté universitaire ne sait pas non plus si le modèle de langage est un perroquet aléatoire, et les opinions des différentes parties varient considérablement.
En raison du manque de tests largement reconnus, la question de savoir si un modèle peut « comprendre le monde » est devenue une question philosophique plutôt qu'une question scientifique.
Récemment, des chercheurs de l'Université Harvard et du MIT ont publié conjointement une nouvelle étude Othello-GPT, qui a vérifié l'efficacité des représentations internes dans un simple jeu de société. Ils pensent que la représentation interne du modèle de langage est effectivement établie. un modèle mondial, pas seulement une simple mémoire ou des statistiques, mais la source de sa capacité reste encore floue.

Lien papier : https://arxiv.org/pdf/2210.13382.pdf
Le processus expérimental est très simple, sans aucune connaissance préalable des règles d'Othello, les chercheurs ont découvert que le modèle peut prédire. mouvements légaux et capturer l'état du plateau avec une très grande précision.
Andrew Ng a exprimé une grande reconnaissance pour cette recherche dans la rubrique "Lettre". Il estime que sur la base de cette recherche, il y a des raisons de croire que les modèles de langage à grande échelle ont construit un modèle mondial suffisamment complexe, et dans une certaine mesure. dans la mesure où ils comprennent le monde.
Lien du blog : https://www.deeplearning.ai/the-batch/does-ai-understand-the-world/
Cependant, Andrew Ng a également déclaré que même si la philosophie est importante, Ce débat va probablement s’éterniser, alors passons à la programmation !
Modèle mondial de l'échiquier
Si vous imaginez l'échiquier comme un simple « monde » et demandez au modèle de prendre des décisions continues pendant le jeu, vous pouvez d'abord tester si le modèle séquentiel peut apprendre la représentation du monde.

Les chercheurs ont choisi un simple jeu d'Othello, Othello, comme plate-forme expérimentale. La règle est de placer quatre pièces d'échecs au centre de l'échiquier 8*8, deux pour le noir et deux pour les deux côtés ; à tour de rôle pour effectuer des mouvements. Dans la direction droite ou diagonale, toutes les pièces ennemies (sans compter les espaces) entre les deux pièces de son propre côté deviendront toutes ses propres pièces (appelées pièces de capture). Chaque mouvement doit avoir des pièces de capture dans le mouvement. À la fin, le plateau sera entièrement occupé, celui qui a le plus de fils gagne.
Par rapport aux échecs, les règles d'Othello sont beaucoup plus simples ; en même temps, l'espace de recherche des jeux d'échecs est suffisamment grand pour que le modèle ne puisse pas terminer la génération de séquences via la mémoire, il est donc très approprié pour tester la représentation du monde. capacité d’apprentissage du modèle.
Modèle de langage Othello
Les chercheurs ont d'abord formé un modèle de langage variant GPT (Othello-GPT), en saisissant le script du jeu (une série d'opérations de mouvement d'échecs effectuées par le joueur) dans le modèle, mais le modèle ne contenait aucune information. concernant Connaissance préalable du jeu et des règles associées.
Le modèle n'est pas explicitement formé pour poursuivre l'amélioration de la stratégie, gagner des jeux, etc., mais a une précision relativement élevée lors de la génération d'opérations de mouvement légales d'Othello.
Ensemble de données
Les chercheurs ont utilisé deux ensembles de données d'entraînement :
Championship (Championship) s'est davantage concentré sur la qualité des données, principalement adoptées par des joueurs humains professionnels dans deux tournois Othello, une étape de réflexion plus stratégique , mais seuls 7 605 et 132 921 échantillons de jeu ont été collectés respectivement. Après la fusion des deux ensembles de données, ils ont été divisés au hasard en un ensemble d'entraînement (20 millions d'échantillons) et un ensemble de vérification (3,796 millions d'échantillons) selon un rapport de 8 : 2). .
Synthetic accorde plus d'attention à l'échelle des données et consiste en des opérations de mouvement aléatoires et légales. La distribution des données est différente de l'ensemble de données du championnat, mais est uniformément échantillonnée à partir de l'arbre de jeu d'Othello, avec 20 millions d'échantillons utilisés. formation et 3,796 millions d’échantillons pour validation.
La description de chaque jeu se compose d'une chaîne de jetons et la taille du vocabulaire est de 60 (8*8-4)
Modèle et formation
L'architecture du modèle est à 8 couches Modèle GPT avec 8 têtes, la dimension cachée est 512
Les poids du modèle sont initialisés de manière complètement aléatoire, y compris la couche d'intégration de mots, bien qu'il existe une relation géométrique dans la liste de mots représentant la position de l'échiquier (comme C4). inférieur à B4), ce biais inductif n’est pas clairement exprimé, mais laissé au modèle pour apprentissage.
Prédire les mouvements légaux
Le principal indicateur d'évaluation du modèle est de savoir si les opérations de mouvement prédites par le modèle sont conformes aux règles d'Othello.
Othello-GPT entraîné sur le jeu de données synthétique a un taux d'erreur de 0,01% et sur le jeu de données championnat un taux d'erreur de 5,17%, contre un taux d'erreur de 93,29% pour l'Othello-GPT non entraîné, c'est-à-dire , ces deux ensembles de données permettent au modèle d'apprendre dans une certaine mesure les règles du jeu.
Une explication possible est que le modèle se souvient de toutes les opérations de mouvement du jeu Othello.
Pour tester cette conjecture, les chercheurs ont synthétisé un nouvel ensemble de données : au début de chaque jeu, Othello a quatre positions d'ouverture possibles (C5, D6, E3 et F4), et toutes les positions d'ouverture C5. Après avoir supprimé les mouvements, il a été utilisé comme ensemble d'entraînement, puis les données d'ouverture C5 ont été utilisées comme test, c'est-à-dire que près d'un quart de l'arbre du jeu a été supprimé. Il a été constaté que le taux d'erreur du modèle n'était toujours que de 0,02 %
. Donc, les hautes performances d'Othello-GPT ne sont pas dues à la mémoire, car les données de test sont complètement invisibles pendant le processus de formation, alors qu'est-ce qui fait exactement que le modèle prédit avec succès ?
Exploration des représentations internes
Les sondes sont un outil couramment utilisé pour détecter les représentations internes des réseaux de neurones. Chaque sonde est un classificateur ou un régresseur dont l'entrée est constituée des activations internes du réseau et est entraînée pour prédire les caractéristiques d'intérêt.
Dans cette tâche, afin de détecter si l'activation interne d'Othello-GPT contient la représentation de l'état actuel de l'échiquier, après avoir saisi la séquence de mouvement, le vecteur d'activation interne est utilisé pour prédire la prochaine étape du mouvement.
Lors de l'utilisation de sondes linéaires, la représentation interne Othello-GPT entraînée n'est que légèrement plus précise qu'une estimation aléatoire.

Lors de l'utilisation de sondes non linéaires (MLP à deux couches), le taux d'erreur diminue considérablement, prouvant que l'état de la carte n'est pas stocké de manière simple lors de l'activation du réseau.
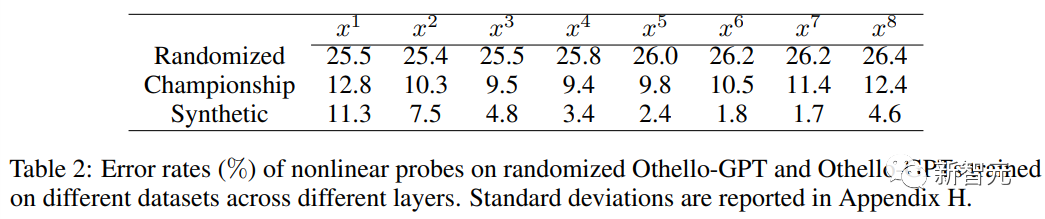
Expérience d'intervention
Pour déterminer la relation causale entre les prédictions du modèle et les représentations du monde émergentes, c'est-à-dire si l'état du tableau affecte effectivement les résultats de prédiction du réseau, les chercheurs ont mené une série d'expériences d'intervention et ont mesuré les résultats obtenus. impact.
Étant donné un ensemble d'activations d'Othello-GPT, utilisez des sondes pour prédire l'état de la carte, enregistrez les prédictions de mouvements associées, puis modifiez les activations pour laisser les sondes prédire l'état de la carte mis à jour.
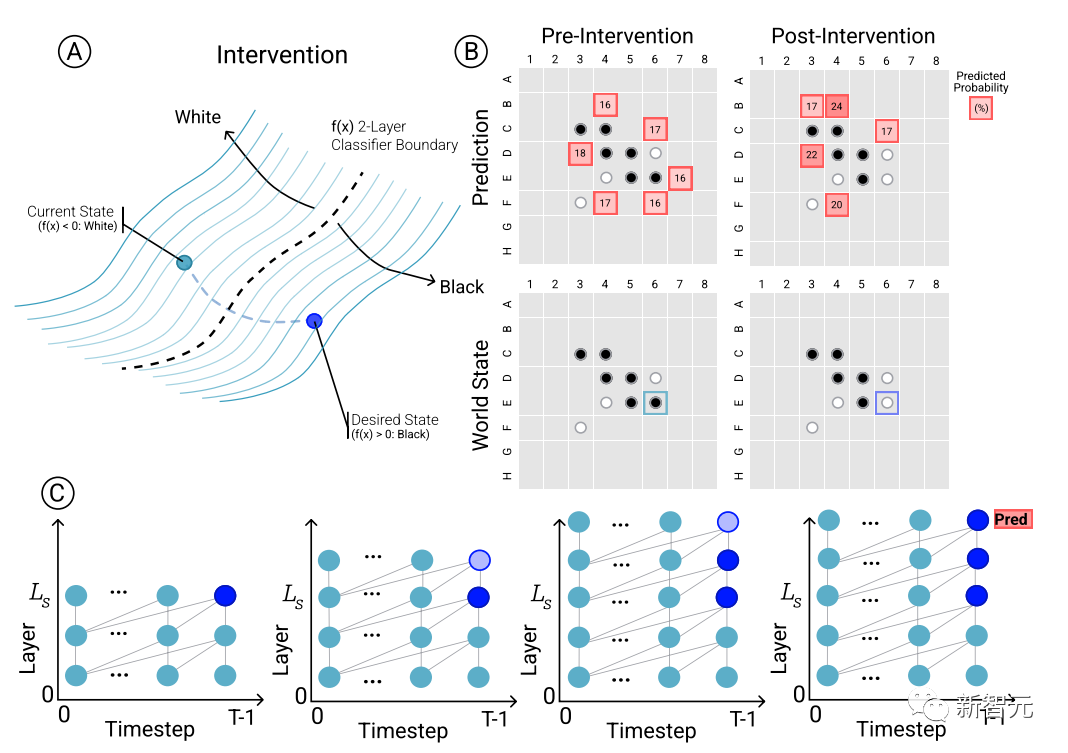
L'opération d'intervention comprend le changement de la pièce d'échecs dans une certaine position du blanc au noir, etc. Une petite modification conduira aux résultats du modèle et constatera que la représentation interne peut compléter de manière fiable la prédiction, c'est-à-dire il existe un écart entre la représentation interne et la prédiction du modèle.
Visualisation
En plus des expériences d'intervention pour vérifier la validité de la représentation interne, les chercheurs ont également visualisé les résultats de la prédiction. Par exemple, pour chaque pièce d'échecs sur l'échiquier, on peut demander au modèle si la technologie d'intervention est utilisée. est utilisé pour changer la pièce d'échecs. La façon dont les résultats prédits changeront correspond à la signification des résultats prédits.
Ensuite, les cartes sont colorées et visualisées en fonction de la saillance prédite par top1 de l'état actuel de l'échiquier. Étant donné que la carte dessinée est saisie en fonction de l'espace latent du réseau, elle peut également être appelée carte de saillance latente.

On peut constater que des modèles clairs sont présentés dans les cartes de saillance latente des principales prédictions des Othello-GPT formés sur des ensembles de données synthétiques et de championnat.
La version synthétique d'Othello-GPT montre une valeur de signification plus élevée dans les positions d'opérations légales, tandis que la valeur de signification des opérations illégales est nettement inférieure. Même les joueurs d'échecs avec un peu d'expérience peuvent voir l'intention du modèle ; La carte de saillance de la version tournoi est plus complexe. Bien que la valeur de saillance de la position d'opération légale soit relativement élevée, d'autres positions montrent également une saillance plus élevée. Cela peut être dû au fait que les maîtres d'Othello prennent davantage en compte la situation globale.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment ajouter une nouvelle colonne dans SQL
Apr 09, 2025 pm 02:09 PM
Comment ajouter une nouvelle colonne dans SQL
Apr 09, 2025 pm 02:09 PM
Ajoutez de nouvelles colonnes à une table existante dans SQL en utilisant l'instruction ALTER TABLE. Les étapes spécifiques comprennent: la détermination des informations du nom de la table et de la colonne, rédaction des instructions de la table ALTER et exécution des instructions. Par exemple, ajoutez une colonne de messagerie à la table des clients (VARCHAR (50)): Alter Table Clients Ajouter un e-mail VARCHAR (50);
 Quelle est la syntaxe pour ajouter des colonnes dans SQL
Apr 09, 2025 pm 02:51 PM
Quelle est la syntaxe pour ajouter des colonnes dans SQL
Apr 09, 2025 pm 02:51 PM
La syntaxe pour ajouter des colonnes dans SQL est alter table table_name Ajouter Column_name data_type [pas null] [default default_value]; Lorsque Table_Name est le nom de la table, Column_name est le nouveau nom de colonne, DATA_TYPE est le type de données, et non Null Spécifie si les valeurs NULL sont autorisées, et default default_value spécifie la valeur par défaut.
 Tableau Clear SQL: Conseils d'optimisation des performances
Apr 09, 2025 pm 02:54 PM
Tableau Clear SQL: Conseils d'optimisation des performances
Apr 09, 2025 pm 02:54 PM
Conseils pour améliorer les performances de compensation de la table SQL: utilisez une table tronquée au lieu de supprimer, libre d'espace et réinitialiser la colonne d'identité. Désactivez les contraintes de clés étrangères pour éviter la suppression en cascade. Utilisez les opérations d'encapsulation des transactions pour assurer la cohérence des données. Supprimer les mégadonnées et limiter le nombre de lignes via Limit. Reconstruisez l'indice après la compensation pour améliorer l'efficacité de la requête.
 Comment définir des valeurs par défaut lors de l'ajout de colonnes dans SQL
Apr 09, 2025 pm 02:45 PM
Comment définir des valeurs par défaut lors de l'ajout de colonnes dans SQL
Apr 09, 2025 pm 02:45 PM
Définissez la valeur par défaut des colonnes nouvellement ajoutées, utilisez l'instruction ALTER TABLE: Spécifiez des colonnes Ajouter et définissez la valeur par défaut: alter table table_name Ajouter Column_name data_type default_value; Utilisez la clause CONSTRAINT pour spécifier la valeur par défaut: ALTER TABLE TABLE_NAME ADD COLUMN COLUMN_NAME DATA_TYPE CONSTRAINT DEFAULT_CONSTRAINT DEFAULT_VALUE;
 Utilisez la déclaration de suppression pour effacer les tables SQL
Apr 09, 2025 pm 03:00 PM
Utilisez la déclaration de suppression pour effacer les tables SQL
Apr 09, 2025 pm 03:00 PM
Oui, l'instruction Delete peut être utilisée pour effacer une table SQL, les étapes sont les suivantes: Utilisez l'instruction Delete: Delete de Table_Name; Remplacez Table_Name par le nom de la table à effacer.
 Comment gérer la fragmentation de la mémoire redis?
Apr 10, 2025 pm 02:24 PM
Comment gérer la fragmentation de la mémoire redis?
Apr 10, 2025 pm 02:24 PM
La fragmentation de la mémoire redis fait référence à l'existence de petites zones libres dans la mémoire allouée qui ne peut pas être réaffectée. Les stratégies d'adaptation comprennent: Redémarrer Redis: effacer complètement la mémoire, mais le service d'interruption. Optimiser les structures de données: utilisez une structure plus adaptée à Redis pour réduire le nombre d'allocations et de versions de mémoire. Ajustez les paramètres de configuration: utilisez la stratégie pour éliminer les paires de valeurs clés les moins récemment utilisées. Utilisez le mécanisme de persistance: sauvegardez régulièrement les données et redémarrez Redis pour nettoyer les fragments. Surveillez l'utilisation de la mémoire: découvrez les problèmes en temps opportun et prenez des mesures.
 phpmyadmin crée un tableau de données
Apr 10, 2025 pm 11:00 PM
phpmyadmin crée un tableau de données
Apr 10, 2025 pm 11:00 PM
Pour créer un tableau de données à l'aide de PhpMyAdmin, les étapes suivantes sont essentielles: connectez-vous à la base de données et cliquez sur le nouvel onglet. Nommez le tableau et sélectionnez le moteur de stockage (InnODB recommandé). Ajouter les détails de la colonne en cliquant sur le bouton Ajouter une colonne, y compris le nom de la colonne, le type de données, s'il faut autoriser les valeurs nuls et d'autres propriétés. Sélectionnez une ou plusieurs colonnes comme clés principales. Cliquez sur le bouton Enregistrer pour créer des tables et des colonnes.
 Comment créer une base de données Oracle Comment créer une base de données Oracle
Apr 11, 2025 pm 02:33 PM
Comment créer une base de données Oracle Comment créer une base de données Oracle
Apr 11, 2025 pm 02:33 PM
La création d'une base de données Oracle n'est pas facile, vous devez comprendre le mécanisme sous-jacent. 1. Vous devez comprendre les concepts de la base de données et des SGBD Oracle; 2. Master les concepts de base tels que SID, CDB (base de données de conteneurs), PDB (base de données enfichable); 3. Utilisez SQL * Plus pour créer CDB, puis créer PDB, vous devez spécifier des paramètres tels que la taille, le nombre de fichiers de données et les chemins; 4. Les applications avancées doivent ajuster le jeu de caractères, la mémoire et d'autres paramètres et effectuer un réglage des performances; 5. Faites attention à l'espace disque, aux autorisations et aux paramètres des paramètres, et surveillez et optimisez en continu les performances de la base de données. Ce n'est qu'en le maîtrisant habilement une pratique continue que vous pouvez vraiment comprendre la création et la gestion des bases de données Oracle.
