
 Périphériques technologiques
IA
Apache IoTDB : une base de données innovante qui résout les problèmes de stockage, de requêtes et d'utilisation dans les scénarios IoT industriels
Périphériques technologiques
IA
Apache IoTDB : une base de données innovante qui résout les problèmes de stockage, de requêtes et d'utilisation dans les scénarios IoT industriels
Apache IoTDB : une base de données innovante qui résout les problèmes de stockage, de requêtes et d'utilisation dans les scénarios IoT industriels

À l'heure où nous entrons dans l'ère de l'Industrie 4.0 et de l'introduction de la numérisation et de l'automatisation, l'environnement de production devient plus efficace. Dans le même temps, les gens commencent à prêter attention à la valeur potentielle des données massives apportées par les appareils intelligents, mais comment stocker efficacement les données générées par les appareils intelligents et comment mieux analyser les données massives est devenu un problème. Les modèles de bases de données et les méthodes de stockage traditionnels ne peuvent plus répondre à ces besoins. Par conséquent, la base de données de séries chronologiques a émergé au fur et à mesure que les temps l'exigent, dans le but d'obtenir un stockage et une interrogation efficaces des données, et d'aider à mieux explorer la valeur potentielle des données
Face à cette situation, l'Université Tsinghua a lancé le développement d'IoTDB en 2015. Le 23 septembre 2020, Apache IoTDB a obtenu son diplôme et est devenu un projet Apache de premier niveau. Il s'agit actuellement du seul projet de haut niveau de la Fondation Apache initié par des universités chinoises et également du seul projet open source dans le domaine de la gestion des données de l'Internet des objets. sous la Fondation Apache. En octobre 2021, l'équipe principale d'Apache IoTDB a fondé Tianmou Technology et continue d'exploiter IoTDB pour aider les utilisateurs industrielsà résoudre les problèmes de « stockage, vérification et utilisation » des données.
Concernant la technologie de base développée par Apache IoTDB, plusieurs participants ont collaboré pour publier un article de synthèse, qui a élaboré la conception d'IoTDB en détail et complètement. L'article prend comme exemple une entreprise industrielle qui doit gérer des dizaines de milliers de pelles hydrauliques et décrit les exigences : « Les données sont d'abord regroupées dans l'appareil, puis envoyées au serveur via le réseau mobile 5G. Dans le serveur, le les données sont écrites dans la base de données de séries chronologiques. Enfin, les data scientists peuvent charger les données de la base de données dans la plate-forme Big Data pour des analyses et des prédictions complexes, c'est-à-dire des tâches OLAP. https://dl.acm.org/doi/abs/10.1145/3589775
 Adresse du projet : https://github.com/apache/iotdb
Adresse du projet : https://github.com/apache/iotdb
- L'objectif de l'article comprend les éléments suivants parties : 1. Conception du modèle de données :
Organisation des séries temporelles au niveau logique et stockage en mode physique
2. Format de fichier TsFile : Stockage en colonnes auto-développé ; format de fichier, En même temps, il répond à l'efficacité de l'écriture, des requêtes, etc.
3. Moteur IoTDB : Comprend principalement un moteur de stockage, un moteur de requête, etc.; La solution distribuée fait référence à la décomposition d'une tâche ou d'un problème. Méthode permettant de diviser plusieurs sous-tâches en plusieurs sous-tâches et d'attribuer ces sous-tâches à plusieurs ordinateurs ou nœuds pour le traitement. Cette solution améliore la fiabilité, l’évolutivité et les performances du système. En répartissant les tâches sur plusieurs ordinateurs, la charge sur un seul ordinateur peut être réduite et les capacités de traitement simultanées du système peuvent être améliorées. Dans le même temps, les solutions distribuées peuvent également améliorer la tolérance aux pannes du système grâce à une sauvegarde et un basculement redondants. Même en cas de panne d'un nœud, le système peut continuer à fonctionner. Dans l'environnement actuel du Big Data et du cloud computing, les solutions distribuées sont devenues un modèle architectural courant et sont largement utilisées dans divers domaines, tels que les bases de données distribuées, les systèmes de stockage distribués et les plates-formes informatiques distribuées, etc.
Pour ce qui suit contenu, nous donnerons une interprétation plus détaillée de ces parties clés
Interprétation détailléeConception du modèle de données nécessaire
comme indiqué ci-dessous Comme indiqué, nous adoptons une structure arborescente pour répondre à des exigences élevées. opérations d'écriture d'intensité et peut gérer efficacement le problème courant d'arrivée de données retardée dans les scénarios IoT
Dans la structure arborescente, chaque nœud feuille représente un capteur, et chaque nœud feuille représente un capteur. Chaque capteur a un appareil correspondant. Comme le montrent les deux niveaux inférieurs de la figure, il en va de même pour les niveaux supérieurs
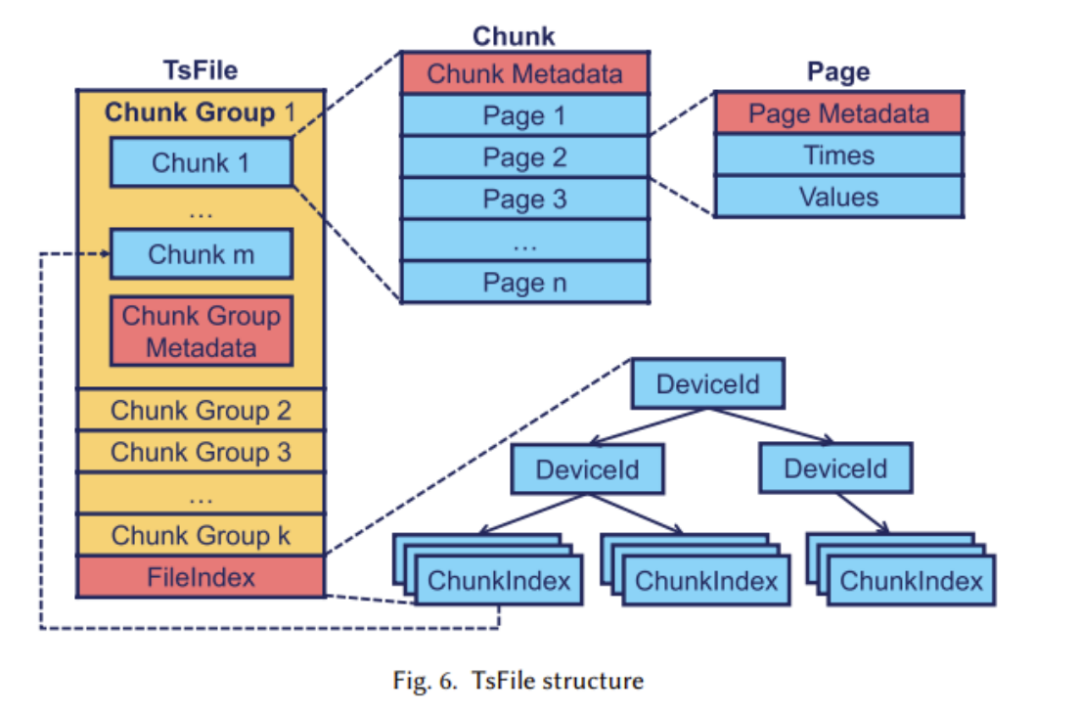
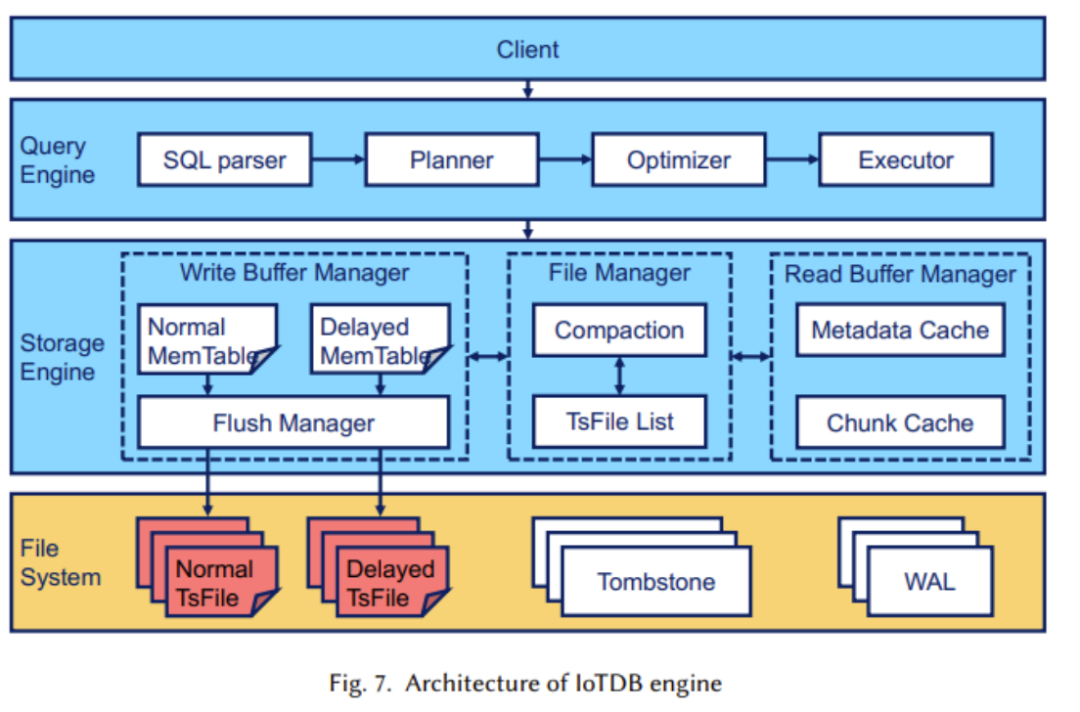
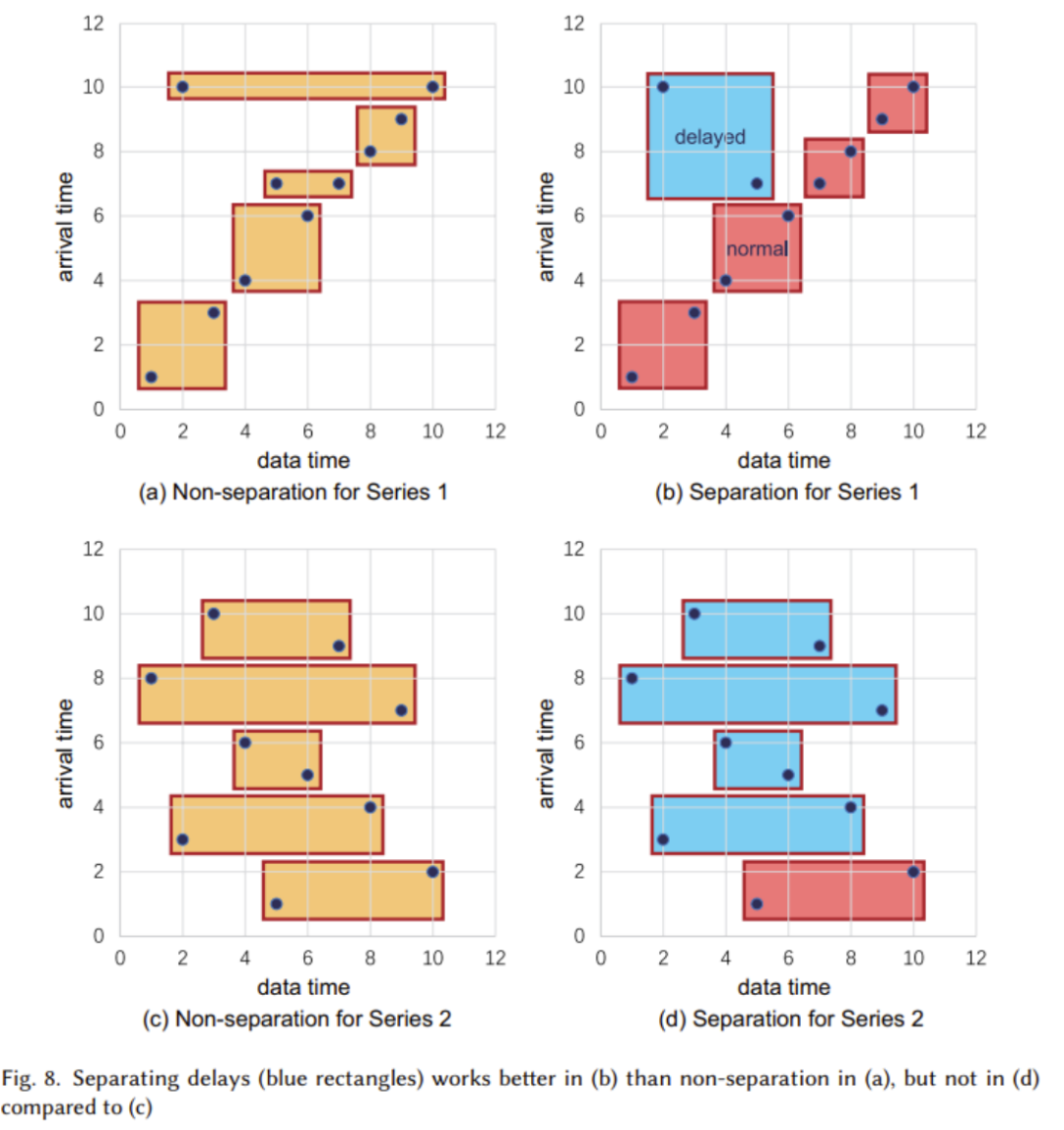
(2) La structure logique a été expliquée dans l'article précédent, nous allons maintenant examiner la mise en œuvre de la structure physique. , qui comprend principalement les séries chronologiques ( Séries temporelles) et la famille de séquences (Famille Séries). La figure ci-dessous montre que chaque série temporelle se compose de deux attributs : l'heure et la valeur. La série temporelle est localisée sur le chemin complet allant du nœud racine au nœud feuille. L'image ci-dessus montre le concept de cluster de séquences. Un cluster de séquences peut contenir plusieurs appareils, et leurs données seront stockées ensemble dans TsFile (une structure de fichiers, qui sera expliquée plus tard)Le contenu qui doit être réécrit est : 2. Conception du format de fichier TsFile TsFile est un format de fichier de stockage en colonnes auto-développé par Apache IoTDB. Sa structure est illustrée dans la figure ci-dessous : Lors de la conception de TsFile, l'équipe de recherche s'est principalement concentrée sur la résolution des problèmes : Les principales solutions apportées sont : Dans cette partie, les chercheurs se concentrent principalement sur l'arrivée retardée, le traitement efficace des requêtes et les requêtes SQL similaires dans le scénario de l'Internet des objets. conception. La structure du moteur IoTDB est présentée dans la figure ci-dessous : Sur la figure, on peut voir que la partie moteur de stockage est principalement utilisée pour gérer l'écriture, la lecture et la gestion de TsFile. Dans cette partie, la technologie de séparation différée automatique est adoptée (comme le montre la figure ci-dessous) Dans la plupart des cas, lorsque les plages de temps dans TsFile ne se chevauchent pas, il est recommandé d'utiliser la séparation différée des données. Cependant, dans les cas où la plupart des données ne sont pas ordonnées, la séparation paresseuse des données n'est pas recommandée. Après la réécriture : un autre composant important est le moteur de requête, qui est responsable de la conversion des requêtes SQL en requêtes pouvant être exécutées par l'opérateur de base de données. . Dans le même temps, afin de s'adapter aux scénarios de l'IoT industriel, Apache IoTDB a également conçu de riches fonctions de requête de données de séries chronologiques Le contenu qui doit être réécrit est : 4. Solution décentralisée
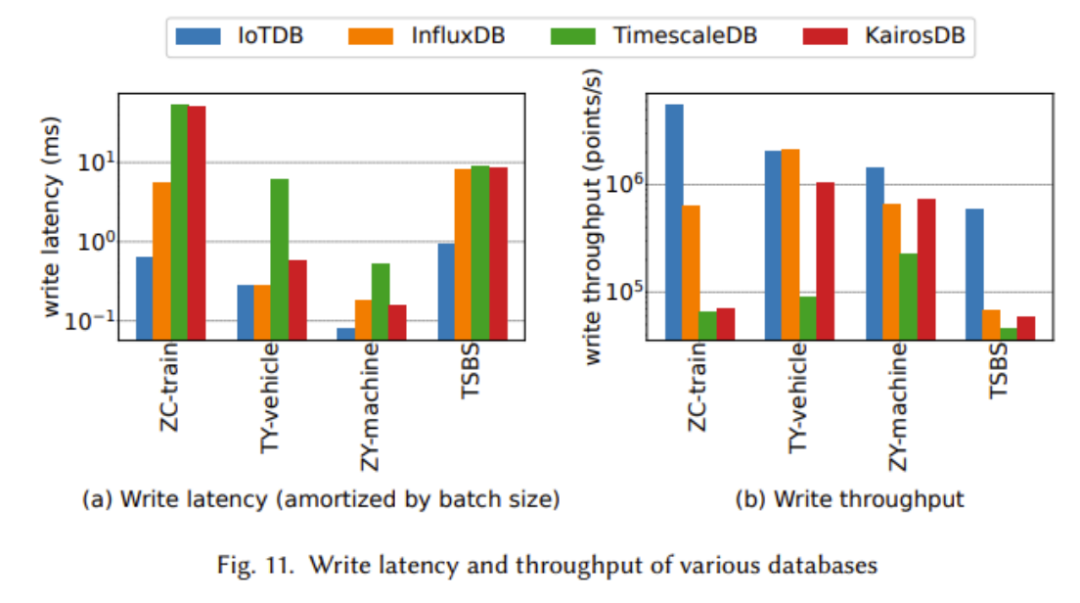
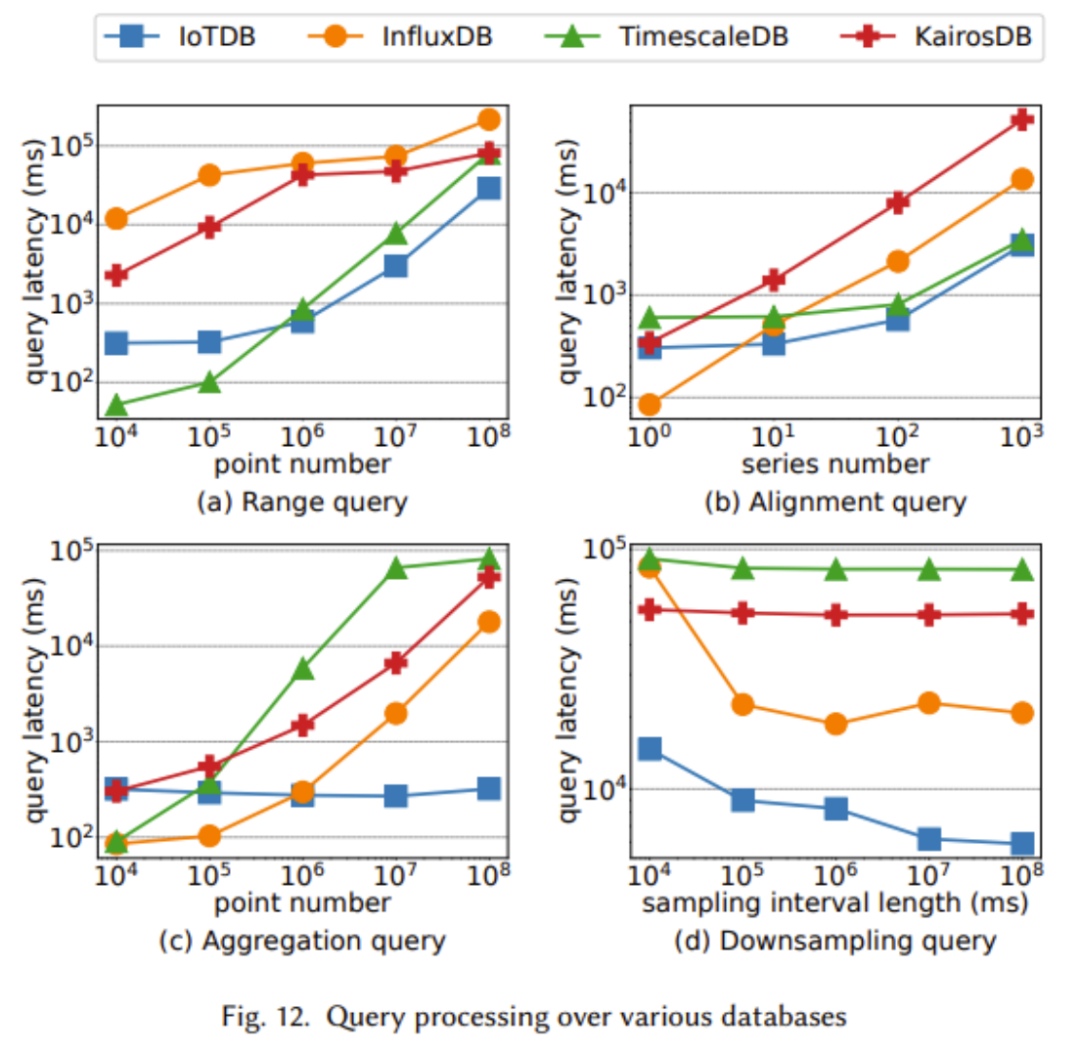
TsFile peut être trouvé dans Distribué sur HDFS et exploité par Spark. En outre, il fournit également des solutions natives pour une meilleure gestion de la distribution des données et du traitement des requêtes, notamment la réplication de partition, la réplication NB-Raft et la cohérence de lecture dynamiqueRésultats de comparaison Dans l'article, nous comparons TsFile et IoTDB, deux formats de fichiers et bases de données de synchronisation de pointe largement utilisés dans l'industrie. A travers la figure suivante, nous montrons les avantages d'Apache IoTDB sous de nombreux aspects Les deux chiffres ci-dessus montrent les avantages de TsFile en termes de débit d'écriture, de coût de temps de lecture et de performances de synchronisation. Cela est principalement dû à la conception de la structure compatible IoT de TsFile, qui évite de stocker des informations redondantes telles que l'identifiant de l'appareil. Bien qu'il n'y ait aucun avantage évident dans l'utilisation du disque de TsFile, cela est dû au fait qu'un index plus granulaire est construit, ce qui entraîne une plus grande utilisation d'espace. Cependant, ce sacrifice peut conduire à des améliorations extraordinaires du temps de requête, car nous pouvons constater un net avantage en termes de coût du temps de lecture Comme le montre clairement le graphique ci-dessus, IoTDB surpasse dans presque tous les tests Présentant de meilleures performances, y compris un débit d'écriture plus élevé et une latence d'écriture plus faible Dans les expériences ci-dessus, nous avons observé que lorsque la taille des données de requête est plus grande, IoTDB présente de meilleures performances. Les avantages d'IoTDB sont particulièrement évidents, en particulier dans l'agrégation de données à grande échelle. requêtes en temps réel et analyse Big Data pour les applications IoT. Le système comprend un nouveau format de fichier de série chronologique appelé TsFile, qui utilise le stockage en colonnes pour stocker les heures et les valeurs afin d'éviter les valeurs nulles et d'obtenir une compression efficace. Basé sur TsFile, le moteur IoTDB utilise une stratégie de type arborescence LSM pour gérer les écritures de haute intensité et peut gérer le problème courant d'arrivée de données retardée dans les scénarios IoT. De riches fonctions de requête évolutives et des informations statistiques précalculées dans TsFile permettent à IoTDB de gérer efficacement les tâches OLTP et OLAP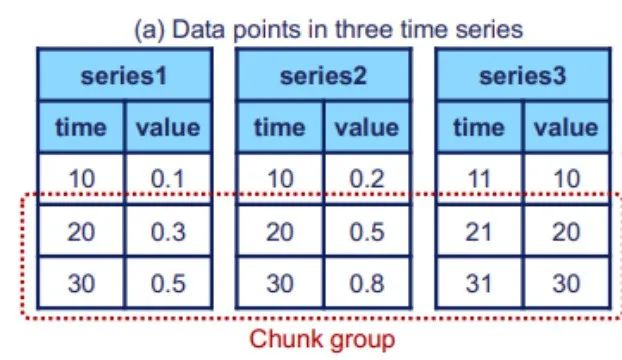
IoTDB est devenue une nouvelle base de données capable de mieux faire face aux scénarios IoT industriels, basée sur la technologie ci-dessus.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment définir le niveau de journal Debian Apache
Apr 13, 2025 am 08:33 AM
Comment définir le niveau de journal Debian Apache
Apr 13, 2025 am 08:33 AM
Cet article décrit comment ajuster le niveau de journalisation du serveur Apacheweb dans le système Debian. En modifiant le fichier de configuration, vous pouvez contrôler le niveau verbeux des informations de journal enregistrées par Apache. Méthode 1: Modifiez le fichier de configuration principal pour localiser le fichier de configuration: le fichier de configuration d'Apache2.x est généralement situé dans le répertoire / etc / apache2 /. Le nom de fichier peut être apache2.conf ou httpd.conf, selon votre méthode d'installation. Modifier le fichier de configuration: Ouvrez le fichier de configuration avec les autorisations racine à l'aide d'un éditeur de texte (comme Nano): Sutonano / etc / apache2 / apache2.conf
 Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Dans Debian Systems, les appels du système ReadDir sont utilisés pour lire le contenu des répertoires. Si ses performances ne sont pas bonnes, essayez la stratégie d'optimisation suivante: simplifiez le nombre de fichiers d'annuaire: divisez les grands répertoires en plusieurs petits répertoires autant que possible, en réduisant le nombre d'éléments traités par appel ReadDir. Activer la mise en cache de contenu du répertoire: construire un mécanisme de cache, mettre à jour le cache régulièrement ou lorsque le contenu du répertoire change et réduire les appels fréquents à Readdir. Les caches de mémoire (telles que Memcached ou Redis) ou les caches locales (telles que les fichiers ou les bases de données) peuvent être prises en compte. Adoptez une structure de données efficace: si vous implémentez vous-même la traversée du répertoire, sélectionnez des structures de données plus efficaces (telles que les tables de hachage au lieu de la recherche linéaire) pour stocker et accéder aux informations du répertoire
 Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Dans Debian Systems, la fonction ReadDir est utilisée pour lire le contenu du répertoire, mais l'ordre dans lequel il revient n'est pas prédéfini. Pour trier les fichiers dans un répertoire, vous devez d'abord lire tous les fichiers, puis les trier à l'aide de la fonction QSORT. Le code suivant montre comment trier les fichiers de répertoire à l'aide de ReadDir et QSort dans Debian System: # include # include # include # include # include // Fonction de comparaison personnalisée, utilisée pour qsortintCompare (constvoid * a, constvoid * b) {returnstrcmp (* (
 Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
La configuration du pare-feu d'un serveur de courrier Debian est une étape importante pour assurer la sécurité du serveur. Voici plusieurs méthodes de configuration de pare-feu couramment utilisées, y compris l'utilisation d'iptables et de pare-feu. Utilisez les iptables pour configurer le pare-feu pour installer iptables (sinon déjà installé): Sudoapt-getUpDaSuDoapt-getinstalliptableView Règles actuelles iptables: Sudoiptable-L Configuration
 Méthode d'installation du certificat de Debian Mail Server SSL
Apr 13, 2025 am 11:39 AM
Méthode d'installation du certificat de Debian Mail Server SSL
Apr 13, 2025 am 11:39 AM
Les étapes pour installer un certificat SSL sur le serveur de messagerie Debian sont les suivantes: 1. Installez d'abord la boîte à outils OpenSSL, assurez-vous que la boîte à outils OpenSSL est déjà installée sur votre système. Si ce n'est pas installé, vous pouvez utiliser la commande suivante pour installer: Sudoapt-getUpDaSuDoapt-getInstallOpenSSL2. Générer la clé privée et la demande de certificat Suivant, utilisez OpenSSL pour générer une clé privée RSA 2048 bits et une demande de certificat (RSE): OpenSS
 Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
La fonction ReadDir dans le système Debian est un appel système utilisé pour lire le contenu des répertoires et est souvent utilisé dans la programmation C. Cet article expliquera comment intégrer ReadDir avec d'autres outils pour améliorer sa fonctionnalité. Méthode 1: combinant d'abord le programme de langue C et le pipeline, écrivez un programme C pour appeler la fonction readdir et sortir le résultat: # include # include # include # includeIntmain (intargc, char * argv []) {dir * dir; structDirent * entrée; if (argc! = 2) {
 Comment Debian OpenSSL empêche les attaques de l'homme au milieu
Apr 13, 2025 am 10:30 AM
Comment Debian OpenSSL empêche les attaques de l'homme au milieu
Apr 13, 2025 am 10:30 AM
Dans Debian Systems, OpenSSL est une bibliothèque importante pour le chiffrement, le décryptage et la gestion des certificats. Pour empêcher une attaque d'homme dans le milieu (MITM), les mesures suivantes peuvent être prises: utilisez HTTPS: assurez-vous que toutes les demandes de réseau utilisent le protocole HTTPS au lieu de HTTP. HTTPS utilise TLS (Protocole de sécurité de la couche de transport) pour chiffrer les données de communication pour garantir que les données ne sont pas volées ou falsifiées pendant la transmission. Vérifiez le certificat de serveur: vérifiez manuellement le certificat de serveur sur le client pour vous assurer qu'il est digne de confiance. Le serveur peut être vérifié manuellement via la méthode du délégué d'URLSession
 Comment faire Debian Hadoop Log Management
Apr 13, 2025 am 10:45 AM
Comment faire Debian Hadoop Log Management
Apr 13, 2025 am 10:45 AM
Gérer les journaux Hadoop sur Debian, vous pouvez suivre les étapes et les meilleures pratiques suivantes: l'agrégation de journal Activer l'agrégation de journaux: définir yarn.log-aggregation-inable à true dans le fichier yarn-site.xml pour activer l'agrégation de journaux. Configurer la stratégie de rétention du journal: Définissez Yarn.log-agregation.retain-secondes pour définir le temps de rétention du journal, tel que 172800 secondes (2 jours). Spécifiez le chemin de stockage des journaux: via yarn.n
