

Imprimez tous les mots non répétitifs dans deux phrases données


Dans ce tutoriel, nous identifierons et imprimerons tous les mots non répétés dans deux phrases données. Les mots non répétés font référence à des mots qui n'apparaissent qu'une seule fois dans deux phrases, c'est-à-dire qu'ils n'apparaissent pas de manière répétée dans une autre phrase. Cette tâche consiste à analyser une phrase saisie, à identifier des mots individuels et à comparer deux phrases pour trouver des mots qui n'apparaissent qu'une seule fois. Le résultat devrait être une liste de tous ces mots. Cette tâche peut être accomplie via diverses méthodes de programmation, telles que l'utilisation de boucles, de tableaux ou de dictionnaires.
Méthode
Voici deux façons d'imprimer tous les mots non répétitifs dans deux phrases données−
Méthode 1 : Utiliser un dictionnaire
Méthode 2 : Utiliser les collections
Méthode 1 : Utiliser un dictionnaire
À l’aide d’un dictionnaire, comptez le nombre de fois où chaque mot apparaît dans deux phrases. On peut alors consulter le dictionnaire et imprimer tous les mots qui n’apparaissent qu’une seule fois. La fonction Dictionnaire en C++ est généralement utilisée pour afficher tous les mots uniques dans deux phrases spécifiées. La méthode consiste à utiliser une structure de données de dictionnaire ou de table de hachage pour stocker la fréquence de chaque mot dans deux phrases. Nous pouvons ensuite parcourir le dictionnaire et imprimer des termes qui n’apparaissent qu’une seule fois.
Grammaire
Voici la syntaxe sans le code réel pour imprimer tous les mots non dupliqués dans deux phrases données en utilisant les méthodes de dictionnaire en C++ -
Déclarez un dictionnaire pour stocker les fréquences des mots
map<string, int> freqDict;
Entrez deux phrases sous forme de chaînes
string sentence1 = "first sentence"; string sentence2 = "second sentence";
Divisez les phrases en mots et insérez-les dans le dictionnaire
istringstream iss (sentence1 + " " + sentence2);
string word;
while (iss >> word) {
freqDict[word]++;
}
Parcourez le dictionnaire et imprimez des mots uniques
for (const auto& [word, frequency]: freqDict) {
if (frequency == 1) {
cout << word << " ";
}
}
Algorithme
En C++, il s'agit d'une astuce pour utiliser des méthodes de dictionnaire pour imprimer étape par étape tous les éléments uniques dans deux phrases spécifiées -
Étape 1 - Créez deux chaînes s1 et s2 contenant des phrases.
Étape 2 - Déclarez une chaîne de carte vide non ordonnée, int> pour enregistrer la fréquence de chaque mot dans la phrase.
Étape 3 - Utilisez la classe de flux de chaînes de C++ pour analyser les deux phrases afin d'extraire des mots.
Étape 4 - Pour chaque mot extrait, vérifiez s'il apparaît dans le dictionnaire. Si c’est le cas, augmentez sa fréquence de un. Sinon, ajoutez-le au dictionnaire avec la fréquence 1.
Étape 5 - Après avoir traité les deux phrases, parcourez le dictionnaire et affichez tous les termes avec la fréquence 1. Ce sont des mots qui ne sont pas répétés dans les deux phrases.
Étape 6 − La complexité temporelle de cette méthode est O(n),
La traduction chinoise deExemple 1
est :Exemple 1
Ce code utilise une carte non ordonnée pour stocker la fréquence de chaque mot dans la phrase combinée. Il parcourt ensuite la carte, ajoutant chaque mot qui n'apparaît qu'une seule fois à un vecteur de mots non répétitifs. Enfin, il libère des mots non dupliqués. Cet exemple implique que les deux phrases sont codées en dur dans le programme plutôt que saisies par l'utilisateur.
#include <iostream>
#include <string>
#include <unordered_map>
#include <sstream>
#include <vector>
using namespace std;
vector<string> getNonRepeatingWords(string sentence1, string sentence2) {
// Combine the two sentences into a single string
string combined = sentence1 + " " + sentence2;
// Create a map to store the frequency of each word
unordered_map<string, int> wordFreq;
// Use a string stream to extract each word from the combined string
stringstream ss(combined);
string word;
while (ss >> word) {
// Increment the frequency of the word in the map
wordFreq[word]++;
}
// Create a vector to store the non-repeating words
vector<string> nonRepeatingWords;
for (auto& pair : wordFreq) {
if (pair.second == 1) {
nonRepeatingWords.push_back(pair.first);
}
}
return nonRepeatingWords;
}
int main() {
string sentence1 = "The quick brown fox jumps over the lazy dog";
string sentence2 = "A quick brown dog jumps over a lazy fox";
vector<string> nonRepeatingWords = getNonRepeatingWords(sentence1, sentence2);
// Print the non-repeating words
for (auto& word : nonRepeatingWords) {
cout << word << " ";
}
cout << endl;
return 0;
}
Sortie
a A the The
Méthode 2 : Utiliser les collections
Cette stratégie consiste à utiliser des ensembles pour trouver des termes qui n'apparaissent qu'une seule fois dans deux phrases. Nous pouvons créer des ensembles de termes pour chaque phrase, puis identifier l'intersection de ces ensembles. Enfin, nous pouvons parcourir l'intersection et afficher tous les éléments qui n'apparaissent qu'une seule fois.
Une collection est un conteneur associatif qui contient différents éléments dans un ordre trié. Nous pouvons insérer des termes des deux phrases dans la collection et tous les doublons seront automatiquement supprimés.
Grammaire
Bien sûr ! Voici la syntaxe que vous pouvez utiliser en Python pour imprimer tous les mots non répétitifs dans deux phrases données −
Définissez deux phrases sous forme de chaînes
sentence1 = "The fox jumps over dog" sentence2 = "A dog jumps over fox"
Divisez chaque phrase en liste de mots
words1 = sentence1.split() words2 = sentence2.split()
Créez un ensemble à partir de ces deux listes de mots
set1 = set(words1) set2 = set(words2)
Trouvez des mots uniques grâce à l'intersection d'ensembles
Nonrepeating = set1.symmetric_difference(set2)
Imprimez des mots uniques
for word in non-repeating: print(word)
Algorithme
Suivez les instructions ci-dessous pour afficher tous les mots non dupliqués dans deux phrases données à l'aide de fonctions d'agrégation en C++ -
Étape 1 - Créez deux variables de chaîne pour stocker les deux phrases.
Étape 2 - À l'aide de la bibliothèque de flux de chaînes, divisez chaque phrase en mots individuels et stockez-les dans deux tableaux distincts.
Étape 3 - Créez deux ensembles, un pour chaque phrase, pour stocker des mots uniques.
Étape 4 - Parcourez chaque tableau de mots et insérez chaque mot dans le bon ensemble.
Étape 5 - Parcourez chaque ensemble et imprimez les mots non dupliqués.
La traduction chinoise deExemple 2
est :Exemple 2
Dans ce code, nous utilisons la bibliothèque de flux de chaînes pour diviser chaque phrase en mots séparés. Nous utilisons ensuite deux collections, uniqueWords1 et uniqueWords2, pour stocker les mots uniques dans chaque phrase. Enfin, nous parcourons chaque ensemble et imprimons les mots non dupliqués.
#include <iostream>
#include <string>
#include <sstream>
#include <set>
using namespace std;
int main() {
string sentence1 = "This is the first sentence.";
string sentence2 = "This is the second sentence.";
string word;
stringstream ss1(sentence1);
stringstream ss2(sentence2);
set<string> uniqueWords1;
set<string> uniqueWords2;
while (ss1 >> word) {
uniqueWords1.insert(word);
}
while (ss2 >> word) {
uniqueWords2.insert(word);
}
cout << "Non-repeating words in sentence 1:" << endl;
for (const auto& w : uniqueWords1) {
if (uniqueWords2.find(w) == uniqueWords2.end()) {
cout << w << " ";
}
}
cout << endl;
cout << "Non-repeating words in sentence 2:" << endl;
for (const auto& w : uniqueWords2) {
if (uniqueWords1.find(w) == uniqueWords1.end()) {
cout << w << " ";
}
}
cout << endl;
return 0;
}
输出
Non-repeating words in sentence 1: first Non-repeating words in sentence 2: second
结论
总之,从两个提供的句子中打印所有非重复单词的任务是通过使用各种编程方法来实现的,例如将句子分解为单个单词,利用字典来量化每个单词的频率,以及过滤掉非重复单词。生成的非重复单词集合可以报告给控制台或保存在列表或数组中以供进一步使用。这项工作对于基本的编程文本操作和数据结构操作很有帮助。Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment répondre aux commentaires Tiktok avec une intelligence émotionnelle élevée ? Quelles sont les phrases pour répondre aux commentaires TikTok ?
Mar 23, 2024 pm 07:50 PM
Comment répondre aux commentaires Tiktok avec une intelligence émotionnelle élevée ? Quelles sont les phrases pour répondre aux commentaires TikTok ?
Mar 23, 2024 pm 07:50 PM
Dans la société moderne, de nombreuses personnes sont heureuses de montrer leur vie et d'exprimer leurs émotions personnelles sur la plateforme Douyin, et les discussions dans la zone de commentaires déclenchent souvent des discussions animées. La manière de répondre aux commentaires de Douyin avec un QE élevé est devenue le centre de l'attention de nombreuses personnes. 1. Comment répondre aux commentaires de Douyin avec une intelligence émotionnelle élevée ? Être poli et respectueux sont des principes de base de la communication sur Internet. Même si vous n’êtes pas d’accord, répondez poliment. En exprimant votre gratitude et en étant prêt à communiquer, vous pouvez établir une bonne atmosphère de communication. Faire preuve de compréhension et d’empathie est crucial, surtout lorsque les évaluateurs rencontrent des difficultés ou des frustrations. Une façon d'exprimer de l'empathie et de la compréhension est : « Je comprends les difficultés que vous rencontrez, j'espère que vous pourrez trouver un moyen de résoudre vos problèmes et je ferai de mon mieux pour vous aider à les surmonter.
 Comment utiliser Microsoft Reader Coach avec Immersive Reader
Mar 09, 2024 am 09:34 AM
Comment utiliser Microsoft Reader Coach avec Immersive Reader
Mar 09, 2024 am 09:34 AM
Dans cet article, nous allons vous montrer comment utiliser Microsoft Reading Coach dans Immersive Reader sur un PC Windows. Les fonctionnalités de guidage en lecture aident les étudiants ou les individus à pratiquer la lecture et à développer leurs compétences en lecture. Vous commencez par lire un passage ou un document dans une application prise en charge, et sur cette base, votre rapport de lecture est généré par l'outil Reading Coach. Le rapport de lecture indique votre précision de lecture, le temps qu'il vous a fallu pour lire, le nombre de mots corrects par minute et les mots que vous avez trouvés les plus difficiles lors de la lecture. Vous pourrez également pratiquer les mots, ce qui vous aidera à développer vos compétences en lecture en général. Actuellement, seuls Office ou Microsoft365 (y compris OneNote pour le Web et Word pour We)
 Comment puis-je recommencer à mémoriser des mots lorsque je les mémorise à l'encre ? Partagez la méthode de mémorisation et de remémorisation des mots dans Mo Mo !
Mar 15, 2024 pm 03:28 PM
Comment puis-je recommencer à mémoriser des mots lorsque je les mémorise à l'encre ? Partagez la méthode de mémorisation et de remémorisation des mots dans Mo Mo !
Mar 15, 2024 pm 03:28 PM
Êtes-vous curieux de savoir comment recommencer à mémoriser des mots lorsque Mo Mo les mémorise ? Mo Mo Bei Vocabulary est un logiciel d'apprentissage de mots anglais très facile à utiliser. Les utilisateurs peuvent choisir une bibliothèque de vocabulaire anglais pour apprendre l'anglais en fonction de leur niveau d'anglais et de leurs intentions d'apprentissage. Ils peuvent également utiliser des exemples, des mnémoniques et d'autres méthodes pour mieux comprendre et. mémoriser des mots. Certains amis ont fini de mémoriser du vocabulaire et souhaitent recommencer à mémoriser le même livre de vocabulaire, mais ne savent pas comment faire ? Aujourd'hui, l'éditeur a fait le tri pour vous tous les méthodes de mémorisation et de remémorisation des mots ! Venez le télécharger si cela vous aide ! 1. Comment puis-je recommencer à mémoriser des mots ? Partagez la méthode de mémorisation et de remémorisation des mots dans Mo Mo ! 1. Ouvrez l'application Mo Mo Bei Vocabulary, consultez la fonction d'enregistrement sur la page de révision et sélectionnez la date du jour. 2. Cliquez pour entrer et vous verrez l'option pour afficher les détails. 3. Après avoir accédé à la page, sélectionnez
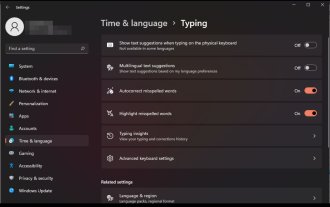 Comment activer ou désactiver la correction automatique des mots mal orthographiés sur Windows 11
Sep 19, 2023 pm 10:53 PM
Comment activer ou désactiver la correction automatique des mots mal orthographiés sur Windows 11
Sep 19, 2023 pm 10:53 PM
La correction automatique est une fonctionnalité très utile qui peut vous faire gagner beaucoup de temps dans votre vie quotidienne. Bien qu'il ne soit pas parfait, la plupart du temps, vous pouvez compter sur lui pour corriger vos fautes d'orthographe et vos fautes d'écriture. Cependant, parfois, cela ne fonctionne pas correctement. Vous constaterez qu'il ne reconnaît pas certains mots, ce qui rend difficile un travail efficace. D’autres fois, vous souhaitez simplement le désactiver et revenir aux anciennes méthodes. Mais y a-t-il des avantages à utiliser la correction automatique ? Gagnez du temps en corrigeant les fautes d’orthographe. Vous aide à apprendre de nouveaux mots en affichant l'orthographe correcte. Cela vous aide à éviter des erreurs embarrassantes dans les e-mails et autres documents. Vous pourrez taper plus rapidement et faire moins d’erreurs. Comment activer ou désactiver la vérification orthographique sur Windows 11 ? 1. Appuyez sur la touche à l'aide de l'application Paramètres
 Où sont les mots qui ont été coupés dans Hundred Words Chop ? Tutoriel de recherche de mots qui peut être utilisé pour éliminer des centaines de mots !
Mar 15, 2024 pm 03:52 PM
Où sont les mots qui ont été coupés dans Hundred Words Chop ? Tutoriel de recherche de mots qui peut être utilisé pour éliminer des centaines de mots !
Mar 15, 2024 pm 03:52 PM
1. Où sont les mots qui ont été supprimés de la Coupe des Cent Mots ? Tutoriel de recherche de mots qui peut être utilisé pour éliminer des centaines de mots ! 1. Accédez à la page d'accueil et cliquez sur la liste de mots. 2. Après avoir accédé à la page, sélectionnez l'option de mot haché. 3. Après être entré dans l'interface, vous pouvez voir les mots qui ont été coupés par l'utilisateur. 4. Si vous souhaitez restaurer le mot haché, cliquez sur l'option Modifier. 5. Recherchez le mot qui doit être restauré et cliquez sur l'icône de coupe à droite pour restaurer le mot. 6. Revenez à l'interface des mots appris et vous pourrez voir les mots que vous venez de récupérer.
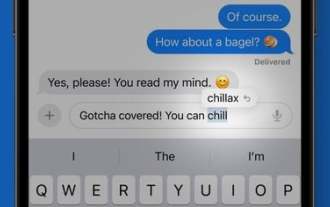 Comment profiter de la correction automatique prédictive dans iOS 17
Sep 17, 2023 pm 03:37 PM
Comment profiter de la correction automatique prédictive dans iOS 17
Sep 17, 2023 pm 03:37 PM
Grâce à une technologie d'apprentissage automatique améliorée, Apple dans iOS 17 a rendu la correction automatique plus utile lors de la saisie de texte sur iPhone. Apple affirme utiliser un « modèle de langage morpher » pour mieux personnaliser la correction automatique pour les utilisateurs individuels, en apprenant vos préférences personnelles et vos choix de mots pour les rendre plus utiles lors de la saisie. Après avoir utilisé iOS 17 pendant quelques semaines, vous devriez remarquer que les suggestions de correction automatique sont plus efficaces pour prédire ce que vous voulez dire et afficher les mots sur lesquels vous pouvez cliquer pour la saisie semi-automatique. La correction automatique est moins agressive que la correction automatique lorsque vous utilisez des acronymes, des mots raccourcis, de l'argot et des expressions familières, mais elle est toujours capable de corriger les fautes d'orthographe accidentelles. Correction de la correction automatique Lorsque la correction automatique modifie un mot, une ligne bleue apparaîtra sous le mot corrigé. Tu peux
 Calculer la longueur des mots dans une chaîne en utilisant Python
Sep 13, 2023 am 11:29 AM
Calculer la longueur des mots dans une chaîne en utilisant Python
Sep 13, 2023 am 11:29 AM
Trouver la longueur de mots individuels dans une chaîne d'entrée donnée à l'aide de Python est un problème qui doit être résolu. Nous souhaitons compter le nombre de caractères de chaque mot dans une saisie de texte et afficher les résultats dans un style structuré tel qu'une liste. La tâche nécessite de diviser la chaîne d'entrée et de séparer chaque mot. Calculez ensuite la longueur de chaque mot en fonction du nombre de caractères qu'il contient. L'objectif fondamental est de créer une fonction ou une procédure capable de recevoir efficacement des entrées, de déterminer la longueur des mots et de produire des résultats en temps opportun. Il est essentiel de résoudre ce problème dans diverses applications, notamment le traitement de texte, le traitement du langage naturel et l'analyse de données, où les statistiques sur la longueur des mots peuvent fournir des informations pertinentes et permettre une analyse supplémentaire. Méthodes utilisées Utiliser les boucles et la fonction split() Utiliser la fonction map() avec len et split() Utiliser
 iOS 17 promet des améliorations significatives de la fonction de correction automatique de l'iPhone
Jun 06, 2023 am 08:20 AM
iOS 17 promet des améliorations significatives de la fonction de correction automatique de l'iPhone
Jun 06, 2023 am 08:20 AM
Apple a présenté aujourd'hui iOS 17 pour iPhone, et l'une des nouvelles fonctionnalités clés apportées par la mise à jour est la correction automatique améliorée. Apple affirme qu'iOS 17 inclut un modèle de langage de prédiction de mots de pointe qui améliorera considérablement la correction automatique de l'iPhone. Chaque fois que vous tapez, l’apprentissage automatique sur l’appareil corrige intelligemment les erreurs avec une précision plus grande que jamais. De plus, vous recevrez désormais des suggestions de texte prédictives en ligne au fur et à mesure que vous tapez, vous permettant d'ajouter des mots ou de compléter des phrases en appuyant sur la barre d'espace. La correction automatique a une conception mise à jour sur iOS 17 qui met brièvement l'accent sur les mots en cours de correction automatique. Cliquer sur un mot souligné affiche le mot original que vous avez tapé, ce qui facilite l'annulation rapide des modifications. Au fil du temps, le système apprendra également votre saisie
