
 Périphériques technologiques
IA
Vos amis regardent aussi ! L'algorithme Google STUDY prend en charge le système de recommandation de listes de livres pour que les étudiants tombent amoureux de la lecture
Périphériques technologiques
IA
Vos amis regardent aussi ! L'algorithme Google STUDY prend en charge le système de recommandation de listes de livres pour que les étudiants tombent amoureux de la lecture
Vos amis regardent aussi ! L'algorithme Google STUDY prend en charge le système de recommandation de listes de livres pour que les étudiants tombent amoureux de la lecture

Ouvrir un livre est bénéfique, c'est ce que nous avons toujours compris. La lecture peut aider les gens à améliorer leurs compétences linguistiques et à acquérir de nouvelles compétences....
La lecture peut également améliorer l'humeur et la santé mentale. Les personnes qui lisent régulièrement ont une meilleure culture générale et une compréhension plus profonde des autres cultures.
De plus, des études ont prouvé que le plaisir de lire est lié à la réussite scolaire.
Mais à l'ère de l'explosion de l'information, il existe d'abondantes ressources de lecture en ligne et hors ligne. Que lire devient un défi difficile.
En particulier, le contenu de lecture doit correspondre à différentes tranches d'âge et être engageant.
Et le système de recommandation est la solution à ce défi. Il présente aux lecteurs du matériel de lecture pertinent et les aide à rester intéressés.
Le cœur du système de recommandation est l'apprentissage automatique (ML), qui est largement utilisé dans la création de différents types de systèmes de recommandation : des vidéos aux livres en passant par les plateformes de commerce électronique.
Le modèle ML formé peut faire des recommandations à chaque utilisateur individuellement en fonction des préférences de l'utilisateur, de l'engagement de l'utilisateur et des éléments recommandés, améliorant ainsi l'expérience utilisateur.
La dernière recherche de Google propose un système de recommandation de contenu de livres audio qui prend en compte la nature sociale de la lecture (comme les environnements éducatifs) : l'algorithme STUDY.
Étant donné que ce que lisent actuellement les pairs d’une personne peut avoir un impact significatif sur ce qu’elle souhaite lire, Google s’est associé à Learning Ally.
Learning Ally est une organisation éducative à but non lucratif dotée d'une vaste bibliothèque numérique de livres audio sélectionnés pour les étudiants, parfaite pour créer des modèles de recommandation sociale.
Cela permet au modèle de bénéficier d'informations en temps réel sur les groupes sociaux localisés des étudiants (tels que les salles de classe).
STUDY algorithm
STUDY algorithm adopte une méthode de modélisation du problème de contenu recommandé en tant que problème de prédiction du taux de clics.
où la probabilité d'interaction de l'utilisateur simulé avec chaque élément spécifique dépend de :
1) Caractéristiques de l'utilisateur et de l'élément
2) La séquence de l'historique des interactions avec les éléments de l'utilisateur.
Des travaux antérieurs ont montré que le modèle Transformer est bien adapté à la modélisation de ce problème.
En traitant chaque utilisateur individuellement, la simulation d'une interaction devient un problème de modélisation de séquence autorégressive.
L'algorithme STUDY est le produit final de la modélisation des données à travers ce cadre conceptuel, puis de l'extension de ce cadre.
Le problème de prédiction du taux de clics peut modéliser les dépendances entre les préférences d'articles passées et futures des utilisateurs individuels, et apprendre des modèles de similarité entre les utilisateurs au moment de la formation.
Mais un problème est que la méthode de prédiction du taux de clics ne peut pas modéliser les dépendances entre les différents utilisateurs.
À cette fin, Google a développé le modèle STUDY, qui peut résoudre les lacunes de la modélisation de séquences autorégressives qui ne peuvent pas modéliser la nature sociale de la lecture.
STUDY peut relier les séquences de livres lus par plusieurs élèves d'une classe en une seule séquence, collectant ainsi les données de plusieurs élèves dans un seul modèle.
Cependant, cette représentation des données doit être étudiée attentivement lors de sa modélisation avec un Transformer.
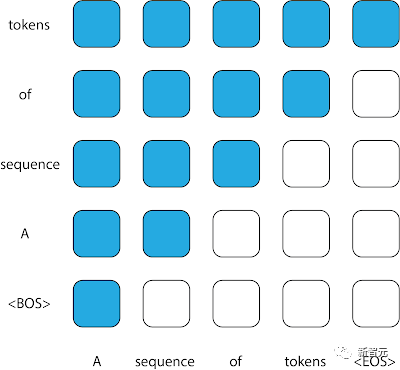
Dans Transformer, le masque d'attention est la matrice qui contrôle quelles entrées peuvent être utilisées pour prédire quelles sorties.
Le modèle d'utilisation de tous les jetons précédents de la séquence pour informer la prédiction des résultats de sortie dans une matrice d'attention triangulaire supérieure, que l'on trouve généralement dans les décodeurs causals.
Cependant, étant donné que la séquence entrée dans le modèle STUDY n'est pas dans l'ordre chronologique, bien que chacune de ses sous-séquences composantes soit dans l'ordre chronologique, le décodeur causal traditionnel n'est plus adapté à cette séquence.
En essayant de prédire chaque jeton, le modèle ne permet pas de se tourner vers chaque jeton qui apparaît avant lui dans la séquence ; certains de ces jetons peuvent avoir des horodatages ultérieurs et contenir des informations qui ne sont pas disponibles au moment du déploiement ; .
 photos
photos
Masques d'attention couramment utilisés dans les décodeurs causals. Chaque colonne représente une sortie et chaque colonne représente une sortie. Une entrée de matrice avec une valeur de 1 (indiquée en bleu) à une position spécifique indique que le modèle peut observer l'entrée de cette ligne lors de la prédiction de la sortie de la colonne correspondante, tandis qu'une valeur de 0 (indiquée en blanc) indique le contraire. . Le modèle
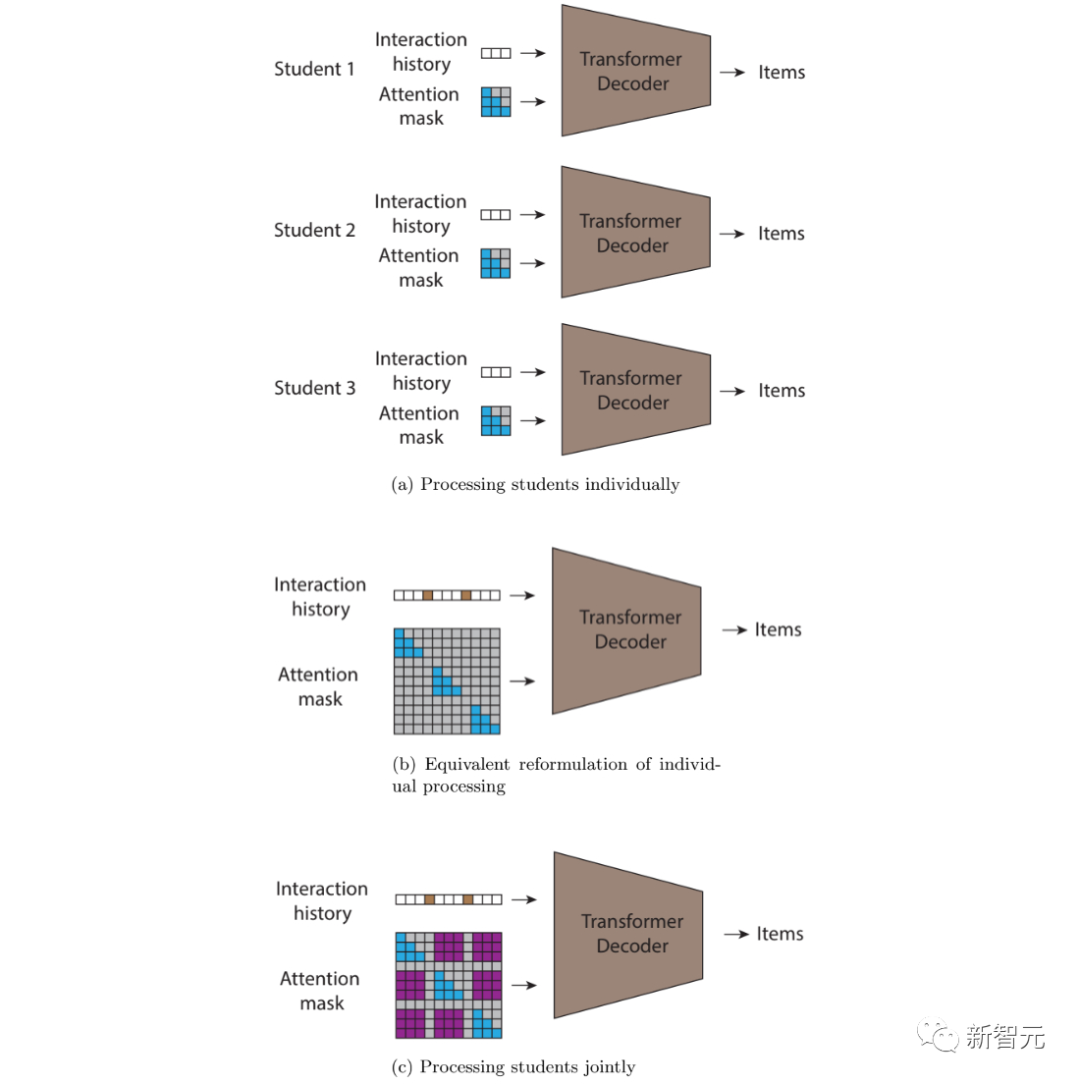
STUDY est basé sur un transformateur causal qui remplace le masque d'attention matriciel triangulaire par un masque d'attention flexible basé sur un horodatage, permettant l'attention sur différentes sous-séquences.
Par rapport aux convertisseurs ordinaires, le modèle STUDY maintient une matrice d'attention triangulaire causale dans une séquence et a des valeurs flexibles dans différentes séquences qui dépendent de l'horodatage.
Ainsi, la prédiction pour tout point de sortie de la séquence fera référence à tous les points d'entrée qui se sont produits dans le passé par rapport au moment actuel, qu'ils se soient produits avant ou après le point d'entrée actuel dans la séquence.
Cette contrainte causale est importante car si cette contrainte n'est pas appliquée pendant la formation, le modèle peut apprendre à utiliser les informations futures pour faire des prédictions, ce qui n'est pas possible dans les déploiements réels.
 Photos
Photos
(a) Un transformateur autorégressif séquentiel avec attention causale, qui peut gérer chaque utilisateur individuellement (b) Une passe avant conjointe équivalente, qui calcule la même chose que (a) Idem (c) ; En introduisant de nouvelles valeurs non nulles dans le masque d'attention (affiché en violet), les informations peuvent circuler entre les utilisateurs. Pour ce faire, nous avons autorisé que les prédictions soient conditionnelles à toutes les interactions avec des horodatages antérieurs, que les interactions proviennent ou non du même utilisateur
Expérience
Google a utilisé l'ensemble de données Learning Ally pour entraîner le modèle STUDY, en utilisant. plusieurs références Faites une comparaison.
L'équipe a utilisé un décodeur CTR autorégressif (appelé « individuel »), une ligne de base du k-voisin le plus proche (KNN) et une base de référence sociale comparable - le Social Attention Memory Network (SAMN).
Ils ont utilisé les données de la première année universitaire pour la formation et les données de la deuxième année universitaire pour la validation et les tests.
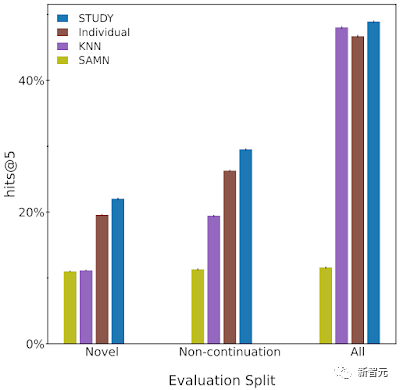
L'équipe évalue ces modèles en mesurant le pourcentage de temps pendant lequel le prochain élément avec lequel l'utilisateur interagit réellement figure parmi les n principales suggestions du modèle.
En plus d'évaluer le modèle sur l'ensemble de l'ensemble de tests, l'équipe rapporte également les scores du modèle sur deux sous-ensembles de l'ensemble de tests qui sont plus difficiles que l'ensemble de données.
On peut observer que les étudiants interagissent généralement plusieurs fois avec les livres audio, il est donc trivial de simplement recommander le dernier livre qu'un utilisateur a lu.
Par conséquent, les chercheurs appellent le premier sous-ensemble de test « non-continuation ». Dans ce sous-ensemble, nous examinons uniquement les performances de recommandation de chaque modèle lorsque les étudiants interagissent avec des livres différents de l'interaction précédente.
De plus, l'équipe a également observé que les étudiants réviseront les livres qu'ils ont lus dans le passé, de sorte que les livres recommandés pour chaque élève sont limités aux livres qu'ils ont lus dans le passé, ce qui peut être fait lors du test. set Obtenez d'excellentes performances.
Bien qu'il puisse être utile de recommander aux étudiants leurs livres préférés du passé, une grande partie de la valeur des systèmes de recommandation vient de la recommandation de contenus nouveaux et inconnus aux utilisateurs.
Pour mesurer cela, l'équipe a évalué le modèle sur un sous-ensemble de l'ensemble de tests où les étudiants ont interagi avec la bibliographie pour la première fois. Nous nommons ce sous-ensemble d’évaluation « nouveau sous-ensemble ».
On constate que "STUDY" est meilleur que les autres modèles dans presque toutes les évaluations.
 Images
Images
L'importance d'un regroupement approprié
Le cœur de l'algorithme STUDY est de regrouper les utilisateurs et d'effectuer une inférence conjointe sur plusieurs utilisateurs du même groupe en une seule passe avant du modèle.
Les chercheurs ont examiné l'importance du regroupement pratique sur les performances du modèle à travers une étude d'ablation.
Dans le modèle proposé, les chercheurs ont regroupé tous les élèves d'une même année et d'une même école.
Nous avons ensuite expérimenté des regroupements définis par tous les élèves d'une même année et d'un même district, ainsi que le regroupement de tous les élèves en un seul groupe et l'utilisation d'un sous-ensemble aléatoire à chaque passage avant.
Les chercheurs ont également comparé ces modèles avec des modèles « personnels » à titre de référence.
Des études ont montré que l'utilisation de groupes plus localisés est plus efficace, c'est-à-dire que les regroupements d'écoles et de niveaux sont meilleurs que les regroupements de districts scolaires et de niveaux.
Cela conforte l'hypothèse selon laquelle le modèle de recherche réussit parce que des activités telles que la lecture sont sociales : les choix de lecture des gens sont susceptibles d'être corrélés avec les choix de lecture de leur entourage.
Les deux modes surpassent les deux autres modes (mode groupe unique et mode individuel) sans utiliser les niveaux scolaires pour regrouper les élèves.
Cela montre que les données d'utilisateurs ayant des niveaux de lecture et des intérêts similaires sont bénéfiques pour améliorer les performances du modèle.
Enfin, cette étude Google s'est limitée à la modélisation d'un groupe d'utilisateurs supposant que les relations sociales sont homogènes.
Référence :
https://www.php.cn/link/0b32f1a9efe5edf3dd2f38b0c0052bfe
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment supprimer les informations sur l'auteur et la dernière modification dans Microsoft Word
Apr 15, 2023 am 11:43 AM
Comment supprimer les informations sur l'auteur et la dernière modification dans Microsoft Word
Apr 15, 2023 am 11:43 AM
Les documents Microsoft Word contiennent certaines métadonnées lors de leur enregistrement. Ces détails sont utilisés pour l'identification du document, comme la date de création, l'auteur, la date de modification, etc. Il contient également d'autres informations telles que le nombre de caractères, le nombre de mots, le nombre de paragraphes, etc. Si vous souhaitez supprimer l'auteur ou les dernières informations modifiées ou toute autre information afin que d'autres personnes ne connaissent pas les valeurs, il existe un moyen. Dans cet article, voyons comment supprimer les informations sur l'auteur et la dernière modification d'un document. Supprimer les informations sur l'auteur et la dernière modification du document Microsoft Word Étape 1 – Accédez à
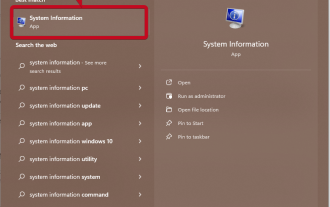 Comment obtenir le GPU sous Windows 11 et vérifier les détails de la carte graphique
Nov 07, 2023 am 11:21 AM
Comment obtenir le GPU sous Windows 11 et vérifier les détails de la carte graphique
Nov 07, 2023 am 11:21 AM
Utilisation des informations système Cliquez sur Démarrer et entrez les informations système. Cliquez simplement sur le programme comme indiqué dans l'image ci-dessous. Vous trouverez ici la plupart des informations sur le système, notamment les informations sur la carte graphique. Dans le programme Informations système, développez Composants, puis cliquez sur Afficher. Laissez le programme rassembler toutes les informations nécessaires et une fois prêt, vous pourrez trouver le nom spécifique de la carte graphique et d'autres informations sur votre système. Même si vous possédez plusieurs cartes graphiques, vous pouvez trouver ici la plupart des contenus liés aux cartes graphiques dédiées et intégrées connectées à votre ordinateur. Utilisation du Gestionnaire de périphériques Windows 11 Tout comme la plupart des autres versions de Windows, vous pouvez également trouver la carte graphique sur votre ordinateur à partir du Gestionnaire de périphériques. Cliquez sur Démarrer puis
 Comment partager les coordonnées avec NameDrop : guide pratique pour iOS 17
Sep 16, 2023 pm 06:09 PM
Comment partager les coordonnées avec NameDrop : guide pratique pour iOS 17
Sep 16, 2023 pm 06:09 PM
Dans iOS 17, il existe une nouvelle fonctionnalité AirDrop qui vous permet d'échanger des informations de contact avec quelqu'un en touchant deux iPhones. Cela s'appelle NameDrop, et voici comment cela fonctionne. Plutôt que de saisir le numéro d'une nouvelle personne pour l'appeler ou lui envoyer un SMS, NameDrop vous permet simplement de placer votre iPhone près de son iPhone pour échanger ses coordonnées afin qu'elle ait votre numéro. Rassembler les deux appareils fera automatiquement apparaître l’interface de partage de contacts. En cliquant sur la fenêtre contextuelle, vous afficherez les informations de contact d'une personne et son affiche de contact (vous pouvez personnaliser et modifier vos propres photos, également une nouvelle fonctionnalité d'iOS17). Cet écran comprend également des options pour « Recevoir uniquement » ou partager vos propres informations de contact en réponse.
 L'algorithme NeRF à vue unique S^3-NeRF utilise des informations multi-éclairage pour restaurer la géométrie de la scène et les informations sur les matériaux.
Apr 13, 2023 am 10:58 AM
L'algorithme NeRF à vue unique S^3-NeRF utilise des informations multi-éclairage pour restaurer la géométrie de la scène et les informations sur les matériaux.
Apr 13, 2023 am 10:58 AM
Les travaux actuels de reconstruction d'images 3D utilisent généralement une méthode de reconstruction stéréo multi-vues (Multi-view Stereo) qui capture la scène cible à partir de plusieurs points de vue (multi-vues) dans des conditions d'éclairage naturel constantes. Cependant, ces méthodes supposent généralement des surfaces lambertiennes et ont des difficultés à récupérer les détails haute fréquence. Une autre approche de la reconstruction de scène consiste à utiliser des images capturées à partir d'un point de vue fixe mais avec des points lumineux différents. Les méthodes photométriques stéréo, par exemple, prennent cette configuration et utilisent ses informations d'ombrage pour reconstruire les détails de surface d'objets non lambertiens. Cependant, les méthodes existantes à vue unique utilisent généralement une carte normale ou une carte de profondeur pour représenter le visible.
 Le forum du sommet sur l'éducation sur les applications de réalité virtuelle Yuanverse s'est tenu à Zhengzhou
Nov 30, 2023 pm 08:33 PM
Le forum du sommet sur l'éducation sur les applications de réalité virtuelle Yuanverse s'est tenu à Zhengzhou
Nov 30, 2023 pm 08:33 PM
Un forum du sommet sur l'éducation sur les applications de réalité virtuelle Metaverse s'est tenu à Zhengzhou, la danse « Lumière flottante » de Dong Yushan, professeur au Henan Art Vocational College, a montré une danse légère et douce. Dans le même temps, des personnes virtuelles ont également dansé de manière synchrone dans l'espace Yuanverse. Leurs postures de danse douces et gracieuses ont émerveillé de nombreux invités. Le 24 novembre, le Forum du Sommet sur l'éducation des applications de réalité virtuelle Yuanverse s'est tenu à Zhengzhou, en se concentrant sur les événements. Des représentants d'instituts de recherche scientifique, d'universités, d'associations industrielles et d'entreprises renommées se sont réunis pour discuter des tendances de développement du Yuanverse. "Le Metaverse a été un sujet fréquemment évoqué ces dernières années et il a apporté des possibilités illimitées à l'industrie de l'animation." Wang Xudong, vice-président de l'Association de l'industrie de l'animation du Henan, a déclaré dans son discours qu'au cours des dernières années, la Chine a
 Comment fonctionne NameDrop sur iPhone (et comment le désactiver)
Nov 30, 2023 am 11:53 AM
Comment fonctionne NameDrop sur iPhone (et comment le désactiver)
Nov 30, 2023 am 11:53 AM
Dans iOS17, il existe une nouvelle fonctionnalité AirDrop qui vous permet d'échanger des informations de contact avec quelqu'un en touchant deux iPhones en même temps. Cela s'appelle NameDrop, et voici comment cela fonctionne réellement. NameDrop élimine le besoin de saisir le numéro d'une nouvelle personne pour l'appeler ou lui envoyer un SMS afin qu'elle ait votre numéro, vous pouvez simplement tenir votre iPhone près de son iPhone pour échanger des informations de contact. Rassembler les deux appareils fera automatiquement apparaître l’interface de partage de contacts. En cliquant sur la fenêtre contextuelle, vous afficherez les informations de contact d'une personne et son affiche de contact (une photo de votre choix que vous pouvez personnaliser et modifier, également nouvelle sur iOS 17). Cet écran inclut également « Recevoir uniquement » ou partagez vos propres informations de contact en réponse.
 Quelle est la raison du retard dans la réception des messages sur WeChat ?
Sep 19, 2023 pm 03:02 PM
Quelle est la raison du retard dans la réception des messages sur WeChat ?
Sep 19, 2023 pm 03:02 PM
La raison du retard dans la réception des informations par WeChat peut être due à des problèmes de réseau, à la charge du serveur, à des problèmes de version, à des problèmes de périphérique, à des problèmes d'envoi de messages ou à d'autres facteurs. Introduction détaillée : 1. Problèmes de réseau. Le retard dans la réception des informations sur WeChat peut être lié à la connexion réseau. Si la connexion réseau est instable ou si le signal est faible, cela peut entraîner des retards dans la transmission des informations. connecté à un réseau stable et la force du signal réseau est bonne. 2. Lorsque la charge du serveur WeChat est élevée, cela peut entraîner des retards dans la transmission des informations, en particulier pendant les périodes de pointe ou lorsqu'un grand nombre d'utilisateurs utilisent WeChat. en même temps, etc.
 Application de la méthode de correction de cause à effet dans le scénario de recommandation Ant Marketing
Jan 13, 2024 pm 12:15 PM
Application de la méthode de correction de cause à effet dans le scénario de recommandation Ant Marketing
Jan 13, 2024 pm 12:15 PM
1. Contexte de la correction de cause à effet 1. Un écart se produit dans le système de recommandation. Des données sont collectées pour entraîner le modèle de recommandation à recommander les éléments appropriés aux utilisateurs. Lorsque les utilisateurs interagissent avec les éléments recommandés, les données collectées sont utilisées pour entraîner davantage le modèle, formant ainsi une boucle fermée. Cependant, il peut y avoir divers facteurs d'influence dans cette boucle fermée, entraînant des erreurs. La principale raison de l'erreur est que la plupart des données utilisées pour entraîner le modèle sont des données d'observation plutôt que des données d'entraînement idéales, qui sont affectées par des facteurs tels que la stratégie d'exposition et la sélection des utilisateurs. L’essence de ce biais réside dans la différence entre les attentes des estimations empiriques du risque et les attentes des véritables estimations du risque idéal. 2. Biais courants Il existe trois principaux types de biais courants dans les systèmes de marketing de recommandation : Biais sélectif : il est dû à la racine de l'utilisateur.
