
 Périphériques technologiques
IA
UniOcc : Unifier la prédiction d'occupation centrée sur la vision avec un rendu géométrique et sémantique !
Périphériques technologiques
IA
UniOcc : Unifier la prédiction d'occupation centrée sur la vision avec un rendu géométrique et sémantique !
UniOcc : Unifier la prédiction d'occupation centrée sur la vision avec un rendu géométrique et sémantique !

Titre original : UniOcc : Unifying Vision-Centric 3D Occupancy Prediction withometric and Semantic Rendering
Veuillez cliquer sur le lien suivant pour consulter l'article : https://arxiv.org/pdf/2306.09117.pdf

Paper idée :
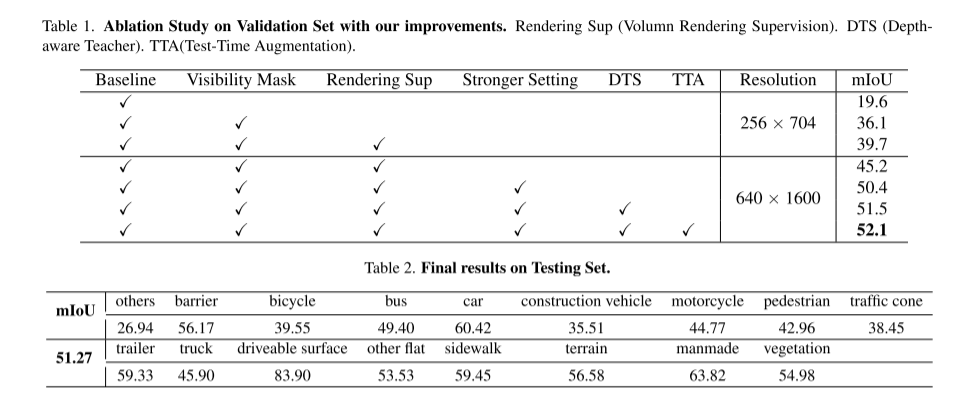
Dans ce rapport technique, nous proposons une solution appelée UniOCC pour les trajectoires de prédiction d'occupation 3D centrées sur la vision dans le cadre du CVPR 2023 nuScenes Open Dataset Challenge. Les méthodes de prédiction d'occupation existantes se concentrent principalement sur l'utilisation d'étiquettes d'occupation 3D pour optimiser les caractéristiques projetées de l'espace volumétrique 3D. Cependant, le processus de génération de ces étiquettes est très complexe et coûteux (reposant sur une annotation sémantique 3D), et est limité par la résolution des voxels et ne peut pas fournir une sémantique spatiale à granularité fine. Pour remédier à cette limitation, nous proposons une nouvelle méthode de prédiction d'occupation unifiée (UniOcc) qui impose explicitement des contraintes géométriques spatiales et complète la supervision sémantique fine avec un rendu de rayons de volume. Notre méthode améliore considérablement les performances du modèle et montre un bon potentiel pour réduire les coûts d'annotation manuelle. Compte tenu de la complexité de l'annotation des occupations 3D, nous proposons en outre le cadre Teacher Student (DTS) sensible à la profondeur pour améliorer la précision des prédictions à l'aide de données non étiquetées. Notre solution a atteint 51,27 % mIoU sur le classement officiel monomodèle, se classant troisième dans ce défi
Conception de réseau :
Dans ce défi, cet article propose UniOcc, qui est une solution générale qui exploite le rendu de volume pour unifier la supervision de représentations 2D et 3D, améliorant les modèles de prédiction d'occupation multi-caméras. Cet article ne conçoit pas une nouvelle architecture de modèle, mais se concentre sur l'amélioration des modèles existants [3, 18, 20] de manière polyvalente et plug-and-play.
Réécrit comme suit : cet article implémente la fonction de génération de cartes sémantiques et de profondeur 2D à l'aide du rendu de volume en mettant à niveau la représentation vers une représentation de style NeRF [1, 15, 21]. Cela permet une supervision fine au niveau des pixels 2D. Par échantillonnage de rayons de voxels tridimensionnels, la sémantique de pixel bidimensionnelle restituée et les informations de profondeur peuvent être obtenues. En intégrant explicitement les relations d'occlusion géométrique et les contraintes de cohérence sémantique, cet article fournit des conseils explicites pour le modèle et garantit le respect de ces contraintes. Il convient de mentionner qu'UniOcc a le potentiel de réduire le recours à des annotations sémantiques 3D coûteuses. En l'absence d'étiquettes d'occupation 3D, les modèles formés à l'aide uniquement de notre supervision de rendu de volume fonctionnent encore mieux que les modèles formés à l'aide de la supervision d'étiquettes 3D. Cela met en évidence le potentiel passionnant de réduire le recours à des annotations sémantiques 3D coûteuses, car les représentations de scènes peuvent être apprises directement à partir d’étiquettes de segmentation 2D abordables. De plus, le coût de l'annotation de segmentation 2D peut être encore réduit en utilisant des technologies avancées telles que SAM [6] et [14,19].
Cet article présente également le cadre Depth Sensing Teacher-Student (DTS), une méthode de formation auto-supervisée. Différent du Mean Teacher classique, DTS améliore la prédiction approfondie du modèle d'enseignant, permettant une formation stable et efficace tout en utilisant des données non étiquetées. De plus, cet article applique quelques techniques simples mais efficaces pour améliorer les performances du modèle. Cela inclut l'utilisation de masques visibles lors de la formation, l'utilisation d'un réseau fédérateur pré-entraîné plus solide, l'augmentation de la résolution des voxels et la mise en œuvre de l'augmentation des données au moment du test (TTA)
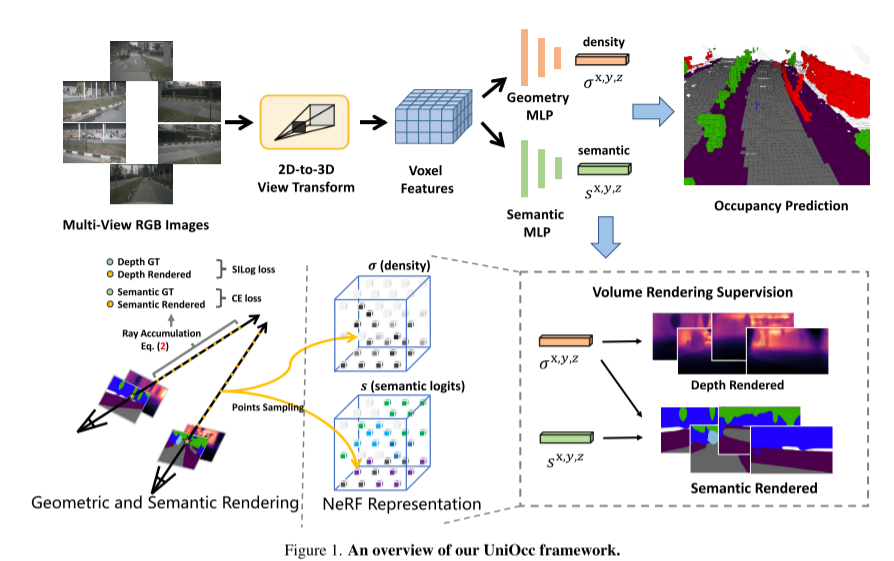 Voici un aperçu du framework UniOcc :
Image 1
Voici un aperçu du framework UniOcc :
Image 1
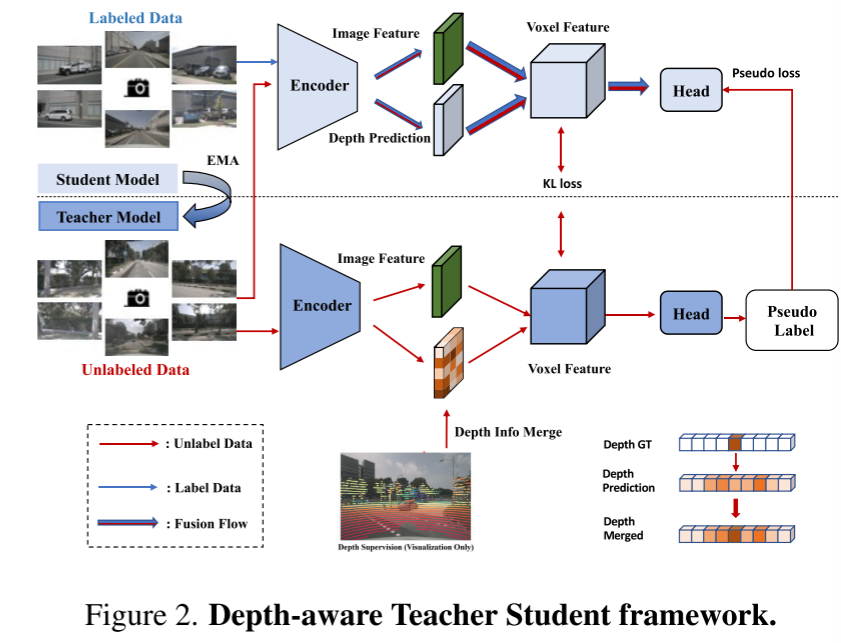 Image 2. Cadre enseignant-élève soucieux de la profondeur.
Image 2. Cadre enseignant-élève soucieux de la profondeur.

Pan, M., Liu, L., Liu, J., Huang, P., Wang, L., Zhang, S. , Xu, S., Lai, Z., Yang, K. (2023). UniOcc : unifier le rendu géométrique et sémantique avec une prédiction d'occupation 3D centrée sur la vision. ArXiv. /abdos/2306.09117
 Lien original : https://mp.weixin.qq.com/s/iLPHMtLzc5z0f4bg_W1vIg
Lien original : https://mp.weixin.qq.com/s/iLPHMtLzc5z0f4bg_W1vIg
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Smart App Control sur Windows 11 : comment l'activer ou le désactiver
Jun 06, 2023 pm 11:10 PM
Smart App Control sur Windows 11 : comment l'activer ou le désactiver
Jun 06, 2023 pm 11:10 PM
Intelligent App Control est un outil très utile dans Windows 11 qui aide à protéger votre PC contre les applications non autorisées qui peuvent endommager vos données, telles que les ransomwares ou les logiciels espions. Cet article explique ce qu'est Smart App Control, comment il fonctionne et comment l'activer ou le désactiver dans Windows 11. Qu’est-ce que Smart App Control dans Windows 11 ? Smart App Control (SAC) est une nouvelle fonctionnalité de sécurité introduite dans la mise à jour Windows 1122H2. Il fonctionne avec Microsoft Defender ou un logiciel antivirus tiers pour bloquer les applications potentiellement inutiles susceptibles de ralentir votre appareil, d'afficher des publicités inattendues ou d'effectuer d'autres actions inattendues. Application intelligente
 Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Écrit précédemment, nous discutons aujourd'hui de la manière dont la technologie d'apprentissage profond peut améliorer les performances du SLAM (localisation et cartographie simultanées) basé sur la vision dans des environnements complexes. En combinant des méthodes d'extraction de caractéristiques approfondies et de correspondance de profondeur, nous introduisons ici un système SLAM visuel hybride polyvalent conçu pour améliorer l'adaptation dans des scénarios difficiles tels que des conditions de faible luminosité, un éclairage dynamique, des zones faiblement texturées et une gigue importante. Notre système prend en charge plusieurs modes, notamment les configurations étendues monoculaire, stéréo, monoculaire-inertielle et stéréo-inertielle. En outre, il analyse également comment combiner le SLAM visuel avec des méthodes d’apprentissage profond pour inspirer d’autres recherches. Grâce à des expériences approfondies sur des ensembles de données publiques et des données auto-échantillonnées, nous démontrons la supériorité du SL-SLAM en termes de précision de positionnement et de robustesse du suivi.
 Les traits du visage volent, ouvrent la bouche, regardent fixement et lèvent les sourcils. L'IA peut les imiter parfaitement, ce qui rend impossible la prévention des escroqueries vidéo.
Dec 14, 2023 pm 11:30 PM
Les traits du visage volent, ouvrent la bouche, regardent fixement et lèvent les sourcils. L'IA peut les imiter parfaitement, ce qui rend impossible la prévention des escroqueries vidéo.
Dec 14, 2023 pm 11:30 PM
Avec une capacité d'imitation de l'IA aussi puissante, il est vraiment impossible de l'empêcher. Le développement de l’IA a-t-il atteint ce niveau aujourd’hui ? Votre pied avant fait voler les traits de votre visage, et sur votre pied arrière, la même expression est reproduite. Regarder fixement, lever les sourcils, faire la moue, aussi exagérée que soit l'expression, tout est parfaitement imité. Augmentez la difficulté, haussez les sourcils, ouvrez plus grand les yeux, et même la forme de la bouche est tordue, et l'avatar du personnage virtuel peut parfaitement reproduire l'expression. Lorsque vous ajustez les paramètres à gauche, l'avatar virtuel à droite modifiera également ses mouvements en conséquence pour donner un gros plan de la bouche et des yeux. On ne peut pas dire que l'imitation soit exactement la même, seule l'expression est exactement la même. idem (extrême droite). La recherche provient d'institutions telles que l'Université technique de Munich, qui propose GaussianAvatars, qui
 Qu'est-ce que le NeRF ? La reconstruction 3D basée sur NeRF est-elle basée sur des voxels ?
Oct 16, 2023 am 11:33 AM
Qu'est-ce que le NeRF ? La reconstruction 3D basée sur NeRF est-elle basée sur des voxels ?
Oct 16, 2023 am 11:33 AM
1 Introduction Les champs de rayonnement neuronal (NeRF) constituent un paradigme relativement nouveau dans le domaine de l'apprentissage profond et de la vision par ordinateur. Cette technologie a été introduite dans l'article ECCV2020 « NeRF : Representing Scenes as Neural Radiation Fields for View Synthesis » (qui a remporté le prix du meilleur article) et est depuis devenue extrêmement populaire, avec près de 800 citations à ce jour [1 ]. Cette approche marque un changement radical dans la manière traditionnelle dont l’apprentissage automatique traite les données 3D. Représentation de la scène du champ de rayonnement neuronal et processus de rendu différenciable : compositer des images en échantillonnant des coordonnées 5D (position et direction de visualisation) le long des rayons de la caméra ; introduire ces positions dans un MLP pour produire des densités de couleur et volumétriques et composer ces valeurs à l'aide de techniques de rendu volumétrique ; ; la fonction de rendu est différentiable, elle peut donc être transmise
 La première reconstruction purement visuelle et statique de la conduite autonome
Jun 02, 2024 pm 03:24 PM
La première reconstruction purement visuelle et statique de la conduite autonome
Jun 02, 2024 pm 03:24 PM
Une solution d'annotation purement visuelle utilise principalement la vision ainsi que certaines données du GPS, de l'IMU et des capteurs de vitesse de roue pour l'annotation dynamique. Bien entendu, pour les scénarios de production de masse, il n’est pas nécessaire qu’il s’agisse d’une vision pure. Certains véhicules produits en série seront équipés de capteurs comme le radar à semi-conducteurs (AT128). Si nous créons une boucle fermée de données dans la perspective d'une production de masse et utilisons tous ces capteurs, nous pouvons résoudre efficacement le problème de l'étiquetage des objets dynamiques. Mais notre plan ne prévoit pas de radar à semi-conducteurs. Par conséquent, nous présenterons cette solution d’étiquetage de production de masse la plus courante. Le cœur d’une solution d’annotation purement visuelle réside dans la reconstruction de pose de haute précision. Nous utilisons le schéma de reconstruction de pose de Structure from Motion (SFM) pour garantir la précision de la reconstruction. Mais passe
 MotionLM : technologie de modélisation de langage pour la prédiction de mouvement multi-agents
Oct 13, 2023 pm 12:09 PM
MotionLM : technologie de modélisation de langage pour la prédiction de mouvement multi-agents
Oct 13, 2023 pm 12:09 PM
Cet article est reproduit avec la permission du compte public Autonomous Driving Heart. Veuillez contacter la source pour la réimpression. Titre original : MotionLM : Multi-Agent Motion Forecasting as Language Modeling Lien vers l'article : https://arxiv.org/pdf/2309.16534.pdf Affiliation de l'auteur : Conférence Waymo : ICCV2023 Idée d'article : Pour la planification de la sécurité des véhicules autonomes, prédisez de manière fiable le comportement futur des agents routiers est cruciale. Cette étude représente les trajectoires continues sous forme de séquences de jetons de mouvement discrets et traite la prédiction de mouvement multi-agents comme une tâche de modélisation du langage. Le modèle que nous proposons, MotionLM, présente les avantages suivants :
 Jetez un œil au passé et au présent de l'Occ et de la conduite autonome ! La première revue résume de manière exhaustive les trois thèmes majeurs de l'amélioration des fonctionnalités/déploiement en production de masse/annotation efficace.
May 08, 2024 am 11:40 AM
Jetez un œil au passé et au présent de l'Occ et de la conduite autonome ! La première revue résume de manière exhaustive les trois thèmes majeurs de l'amélioration des fonctionnalités/déploiement en production de masse/annotation efficace.
May 08, 2024 am 11:40 AM
Écrit ci-dessus et compréhension personnelle de l'auteur Ces dernières années, la conduite autonome a reçu une attention croissante en raison de son potentiel à réduire la charge du conducteur et à améliorer la sécurité de conduite. La prédiction d'occupation tridimensionnelle basée sur la vision est une tâche de perception émergente adaptée à une enquête rentable et complète sur la sécurité de la conduite autonome. Bien que de nombreuses études aient démontré la supériorité des outils de prédiction d’occupation 3D par rapport aux tâches de perception centrée sur les objets, il existe encore des revues dédiées à ce domaine en développement rapide. Cet article présente d'abord le contexte de la prédiction d'occupation 3D basée sur la vision et discute des défis rencontrés dans cette tâche. Ensuite, nous discutons de manière approfondie de l'état actuel et des tendances de développement des méthodes actuelles de prévision d'occupation 3D sous trois aspects : l'amélioration des fonctionnalités, la convivialité du déploiement et l'efficacité de l'étiquetage. enfin
 Savez-vous que les programmeurs seront en déclin dans quelques années ?
Nov 08, 2023 am 11:17 AM
Savez-vous que les programmeurs seront en déclin dans quelques années ?
Nov 08, 2023 am 11:17 AM
Le magazine "ComputerWorld" a écrit un article disant que "la programmation disparaîtra d'ici 1960" parce qu'IBM a développé un nouveau langage FORTRAN, qui permet aux ingénieurs d'écrire les formules mathématiques dont ils ont besoin, puis de les soumettre à l'ordinateur pour que la programmation se termine. Picture Quelques années plus tard, nous avons entendu un nouveau dicton : tout homme d'affaires peut utiliser des termes commerciaux pour décrire ses problèmes et dire à l'ordinateur quoi faire. Grâce à ce langage de programmation appelé COBOL, les entreprises n'ont plus besoin de programmeurs. Plus tard, il est dit qu'IBM a développé un nouveau langage de programmation appelé RPG qui permet aux employés de remplir des formulaires et de générer des rapports, de sorte que la plupart des besoins de programmation de l'entreprise puissent être satisfaits grâce à lui.
