
 Périphériques technologiques
IA
Un vaste ensemble d'outils de développement de modèles a été créé !
Périphériques technologiques
IA
Un vaste ensemble d'outils de développement de modèles a été créé !
Un vaste ensemble d'outils de développement de modèles a été créé !

Le contenu qui doit être réécrit est le suivant : Auteur Richard MacManus
Planning | Yan Zheng
Web3 n'a pas réussi à renverser le Web2, mais la pile de développement de grands modèles émergente permet aux développeurs de passer de l'ère du « cloud natif » à la nouvelle IA. pile technologique.
Les ingénieurs rapides ne sont peut-être pas en mesure de toucher les nerfs des développeurs pour se précipiter vers de grands modèles, mais les mots du chef de produit ou du leader : un "agent" peut-il être développé, une "chaîne" peut-elle être implémentée et "Quelle base de données vectorielle devrait être utilisé?" sont devenus À l'heure actuelle, les principales sociétés d'applications de grands modèles grand public ont poussé les étudiants en technologie à surmonter les difficultés liées au développement de l'IA.
Quelles sont les couches de la pile technologique émergente ? Où est la partie la plus difficile ? Cet article vous amènera à le découvrir
1. La pile technologique doit être mise à jour. Les développeurs inaugurent l'ère des ingénieurs en IA
Au cours de la dernière année, certains outils ont émergé, tels que LangChain et LlamaIndex, qui ont permis. développeurs d'applications d'IA pour L'écosystème commence à mûrir. Il existe même un terme désormais utilisé pour décrire ceux qui se concentrent sur le développement de l’intelligence artificielle, à savoir « ingénieur IA ». Selon Shawn @swyx Wang, il s'agit de la prochaine étape pour les « ingénieurs rapides ». Il a également créé un diagramme de coordonnées qui démontre visuellement la position des ingénieurs en IA dans l'écosystème plus large de l'intelligence artificielle
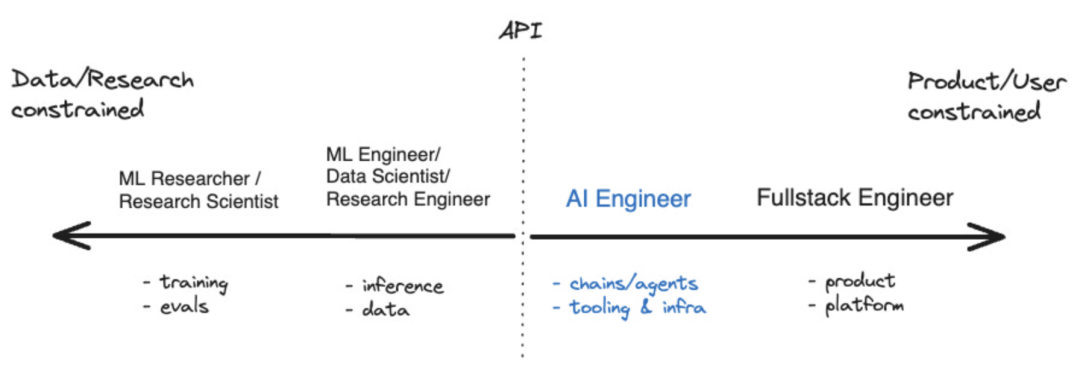 Source : swyx
Source : swyx
Les grands modèles de langage (LLM) sont la technologie de base des ingénieurs en IA. Ce n'est pas un hasard si LangChain et LlamaIndex sont des outils qui étendent et complètent le LLM. Mais quels autres outils sont disponibles pour cette nouvelle génération de développeurs ?
Jusqu'à présent, le meilleur diagramme que j'ai vu de la pile LLM vient de la société de capital-risque Andreessen Horowitz (a16z). Voici son point de vue sur la « pile d'applications LLM » :
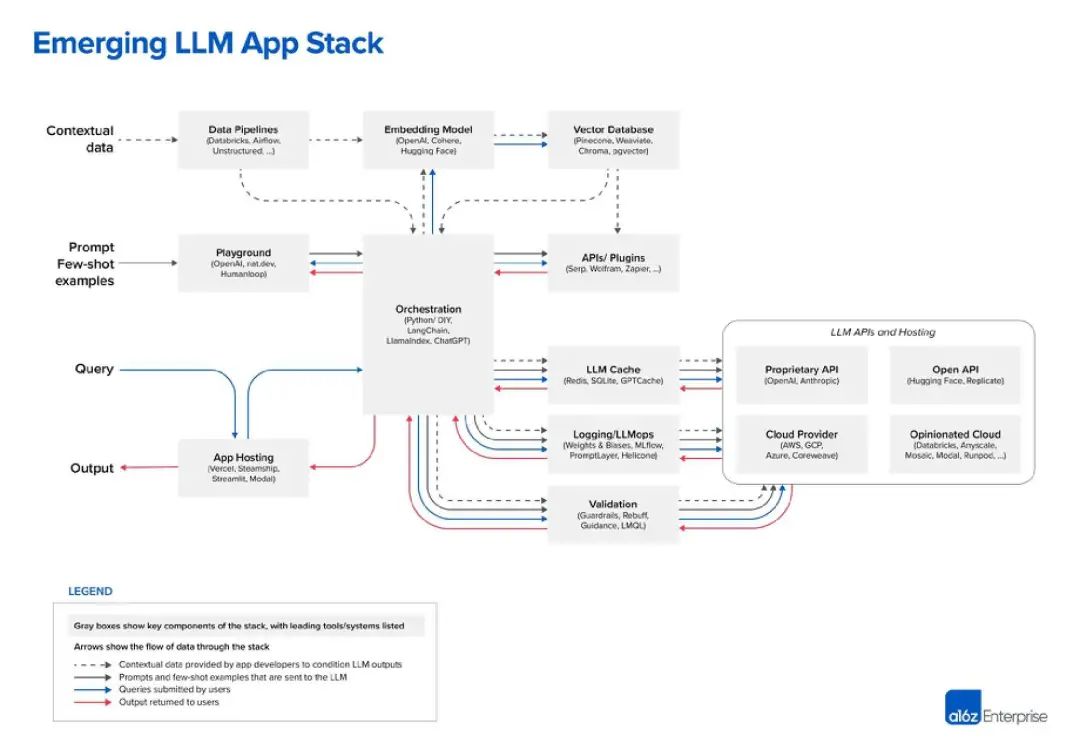 Source de l'image : a16z
Source de l'image : a16z
2 Oui, la couche supérieure est constituée de données
Dans la pile technologique LLM, les données sont le composant le plus important, c'est très évident. Selon le graphique de a16z, les données sont en haut. En LLM, le "modèle embarqué" est un domaine très critique, vous pouvez choisir parmi OpenAI, Cohere, Hugging Face ou des dizaines d'autres options LLM, y compris le LLM open source de plus en plus populaire
Avant d'utiliser LLM, un "pipeline de données" a également besoin à établir. Par exemple, considérons Databricks et Airflow comme deux exemples, ou les données peuvent être traitées « non structurées ». Cela s'applique également à la périodicité des données et peut aider les entreprises à « nettoyer » ou simplement à organiser les données avant de les saisir dans un LLM personnalisé. Les sociétés de « data intelligence » comme Alation proposent ce type de service, qui ressemble un peu à des outils de type « business intelligence » plus connus dans la pile technologique informatique
La dernière partie de la couche de données est la base de données vectorielle qui est devenue très populaire ces derniers temps, pour le stockage et le traitement des données LLM. Selon la définition de Microsoft, il s'agit d'une base de données qui stocke les données sous forme de vecteurs de grande dimension, qui sont des représentations mathématiques de caractéristiques ou d'attributs. Les données sont stockées sous forme de vecteurs à l'aide de la technologie d'intégration
Dans une discussion médiatique, Pinecone, principal fournisseur de bases de données vectorielles, a noté que ses outils sont souvent utilisés avec des outils de pipeline de données tels que Databricks. Dans ce cas, les données sont généralement stockées ailleurs (comme dans un lac de données) puis transformées en données intégrées via un modèle d'apprentissage automatique. Après traitement et segmentation, les vecteurs résultants sont envoyés à Pinecone
3. Astuces et requêtes
Les deux niveaux suivants peuvent être résumés comme des astuces et des requêtes - Il s'agit de l'application d'IA avec LLM et (facultatif) d'un point d'interaction pour d'autres interfaces d’outils de données. A16z positionne LangChain et LlamaIndex comme des « frameworks d'orchestration », ce qui signifie qu'une fois que les développeurs comprennent quel LLM ils utilisent, ils peuvent exploiter ces outils
Selon a16z, les frameworks d'orchestration comme LangChain et LlamaIndex « font abstraction de beaucoup d'indices qui entrent dans les détails de « linking », c'est-à-dire interroger et gérer des données entre l'application et le LLM. Ce processus d'orchestration comprend l'interaction avec les interfaces API externes, la récupération des données contextuelles de la base de données vectorielles et la gestion de la mémoire sur plusieurs appels LLM. La case la plus intéressante du diagramme d'a16z est « Playground », qui comprend OpenAI, nat.dev et Humanloop
A16z n'est pas exactement défini dans le billet de blog, mais nous pouvons en déduire que les outils « Playground » peuvent aider les développeurs à lancer A16z. signalez le jiu-jitsu". Dans ces endroits, les développeurs peuvent expérimenter diverses techniques d'invite.
Humanloop est une entreprise britannique et une fonctionnalité de sa plateforme est le « Collaborative Prompt Workspace ». Il se décrit en outre comme une « boîte à outils de développement complète pour les fonctionnalités LLM de production ». Donc, fondamentalement, cela vous permet d'essayer des trucs LLM puis de les déployer dans votre application si cela fonctionne
4. Opérations de la chaîne de montage : LLMOps
À l'heure actuelle, la configuration des lignes de production à grande échelle devient progressivement claire. Sur le côté droit de la zone d'orchestration se trouvent de nombreuses zones d'opération, notamment la mise en cache et la vérification LLM. En outre, il existe une gamme de services cloud et de services API liés au LLM, notamment des référentiels d'API ouverts tels que Hugging Face et des fournisseurs d'API propriétaires tels que OpenAI
C'est peut-être le développement auquel nous sommes habitués dans le "cloud natif". ère La chose la plus similaire dans la pile technologique des personnes est que de nombreuses entreprises DevOps ont ajouté l'intelligence artificielle à leur liste de produits, ce qui n'est pas une coïncidence. En mai, j'ai parlé avec le PDG de Harness, Jyoti Bansal. Harness exploite une « plate-forme de livraison de logiciels » qui se concentre sur la partie « CD » du processus CI/CD.
Bansai m'a dit que l'IA peut alléger les tâches fastidieuses et répétitives impliquées dans le cycle de vie de la livraison de logiciels, depuis la génération de spécifications basées sur les fonctionnalités existantes jusqu'à l'écriture de code. De plus, il a déclaré que l'IA peut automatiser les révisions de code, les tests de vulnérabilité, les corrections de bugs et même créer des pipelines CI/CD pour les builds et les déploiements. Selon une autre conversation que j'ai eue en mai, l'IA modifie également la productivité des développeurs. Trisha Gee de l'outil d'automatisation de construction Gradle m'a dit que l'IA peut accélérer le développement en réduisant le temps consacré aux tâches répétitives, comme l'écriture de code passe-partout, et en permettant aux développeurs de se concentrer sur la situation dans son ensemble, comme s'assurer que le code répond aux besoins de l'entreprise.
5. Web3 est sorti, une grande pile de développement de modèles est là
Dans la pile technologique de développement LLM émergente, nous pouvons observer une série de nouveaux types de produits, tels que des frameworks d'orchestration (tels que LangChain et LlamaIndex), des bases de données vectorielles et Humanloop. En attendant la plateforme "aire de jeux". Tous ces produits étendent et/ou complètent la technologie de base de l'ère actuelle : les grands modèles de langage
Tout comme la montée en puissance des outils de l'ère cloud-native tels que Spring Cloud et Kubernetes au cours des années précédentes. Cependant, à l'heure actuelle, presque toutes les grandes, petites et grandes entreprises de l'ère du cloud natif font de leur mieux pour adapter leurs outils à l'ingénierie de l'IA, ce qui sera très bénéfique pour le développement futur de la pile technologique LLM.
Oui, cette fois, le grand modèle ressemble à "se tenir sur les épaules de géants". Les meilleures innovations en matière de technologie informatique reposent toujours sur les fondations précédentes. C'est peut-être pour cela que la révolution « Web3 » a échoué : il ne s'agissait pas tant de s'appuyer sur la génération précédente que de tenter de l'usurper.
La pile technologique LLM semble l'avoir fait, elle est devenue un pont entre l'ère du développement cloud et un nouvel écosystème de développeurs basé sur l'intelligence artificielle
Lien de référence : https://www.php.cn/link/ c589c3a8f99401b24b9380e86d939842
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 L'application de grands modèles Tencent Yuanbao est en ligne ! Hunyuan est mis à niveau pour créer un assistant IA complet pouvant être transporté n'importe où
Jun 09, 2024 pm 10:38 PM
L'application de grands modèles Tencent Yuanbao est en ligne ! Hunyuan est mis à niveau pour créer un assistant IA complet pouvant être transporté n'importe où
Jun 09, 2024 pm 10:38 PM
Le 30 mai, Tencent a annoncé une mise à niveau complète de son modèle Hunyuan. L'application « Tencent Yuanbao » basée sur le modèle Hunyuan a été officiellement lancée et peut être téléchargée sur les magasins d'applications Apple et Android. Par rapport à la version de l'applet Hunyuan lors de la phase de test précédente, Tencent Yuanbao fournit des fonctionnalités de base telles que la recherche IA, le résumé IA et l'écriture IA pour les scénarios d'efficacité du travail ; pour les scénarios de la vie quotidienne, le gameplay de Yuanbao est également plus riche et fournit de multiples fonctionnalités d'application IA. , et de nouvelles méthodes de jeu telles que la création d'agents personnels sont ajoutées. « Tencent ne s'efforcera pas d'être le premier à créer un grand modèle. » Liu Yuhong, vice-président de Tencent Cloud et responsable du grand modèle Tencent Hunyuan, a déclaré : « Au cours de l'année écoulée, nous avons continué à promouvoir les capacités de Tencent. Grand modèle Tencent Hunyuan. Dans la technologie polonaise riche et massive dans des scénarios commerciaux tout en obtenant un aperçu des besoins réels des utilisateurs.
 Lancement du grand modèle Bytedance Beanbao, le service d'IA complet Volcano Engine aide les entreprises à se transformer intelligemment
Jun 05, 2024 pm 07:59 PM
Lancement du grand modèle Bytedance Beanbao, le service d'IA complet Volcano Engine aide les entreprises à se transformer intelligemment
Jun 05, 2024 pm 07:59 PM
Tan Dai, président de Volcano Engine, a déclaré que les entreprises qui souhaitent bien mettre en œuvre de grands modèles sont confrontées à trois défis clés : l'effet de modèle, le coût d'inférence et la difficulté de mise en œuvre : elles doivent disposer d'un bon support de base de grands modèles pour résoudre des problèmes complexes, et elles doivent également avoir une inférence à faible coût. Les services permettent d'utiliser largement de grands modèles, et davantage d'outils, de plates-formes et d'applications sont nécessaires pour aider les entreprises à mettre en œuvre des scénarios. ——Tan Dai, président de Huoshan Engine 01. Le grand modèle de pouf fait ses débuts et est largement utilisé. Le polissage de l'effet de modèle est le défi le plus critique pour la mise en œuvre de l'IA. Tan Dai a souligné que ce n'est que grâce à une utilisation intensive qu'un bon modèle peut être poli. Actuellement, le modèle Doubao traite 120 milliards de jetons de texte et génère 30 millions d'images chaque jour. Afin d'aider les entreprises à mettre en œuvre des scénarios de modèles à grande échelle, le modèle à grande échelle beanbao développé indépendamment par ByteDance sera lancé à travers le volcan.
 Pratique avancée du graphe de connaissances industrielles
Jun 13, 2024 am 11:59 AM
Pratique avancée du graphe de connaissances industrielles
Jun 13, 2024 am 11:59 AM
1. Introduction au contexte Tout d’abord, présentons l’historique du développement de la technologie Yunwen. Yunwen Technology Company... 2023 est la période où les grands modèles prédominent. De nombreuses entreprises pensent que l'importance des graphiques a été considérablement réduite après les grands modèles et que les systèmes d'information prédéfinis étudiés précédemment ne sont plus importants. Cependant, avec la promotion du RAG et la prévalence de la gouvernance des données, nous avons constaté qu'une gouvernance des données plus efficace et des données de haute qualité sont des conditions préalables importantes pour améliorer l'efficacité des grands modèles privatisés. Par conséquent, de plus en plus d'entreprises commencent à y prêter attention. au contenu lié à la construction des connaissances. Cela favorise également la construction et le traitement des connaissances à un niveau supérieur, où de nombreuses techniques et méthodes peuvent être explorées. On voit que l'émergence d'une nouvelle technologie ne détruit pas toutes les anciennes technologies, mais peut également intégrer des technologies nouvelles et anciennes.
 Xiaomi Byte unit ses forces ! Un grand modèle de l'accès de Xiao Ai à Doubao : déjà installé sur les téléphones mobiles et SU7
Jun 13, 2024 pm 05:11 PM
Xiaomi Byte unit ses forces ! Un grand modèle de l'accès de Xiao Ai à Doubao : déjà installé sur les téléphones mobiles et SU7
Jun 13, 2024 pm 05:11 PM
Selon les informations du 13 juin, selon le compte public « Volcano Engine » de Byte, l'assistant d'intelligence artificielle de Xiaomi « Xiao Ai » a conclu une coopération avec Volcano Engine. Les deux parties réaliseront une expérience interactive d'IA plus intelligente basée sur le grand modèle beanbao. . Il est rapporté que le modèle beanbao à grande échelle créé par ByteDance peut traiter efficacement jusqu'à 120 milliards de jetons de texte et générer 30 millions de contenus chaque jour. Xiaomi a utilisé le grand modèle Doubao pour améliorer les capacités d'apprentissage et de raisonnement de son propre modèle et créer un nouveau « Xiao Ai Classmate », qui non seulement saisit plus précisément les besoins des utilisateurs, mais offre également une vitesse de réponse plus rapide et des services de contenu plus complets. Par exemple, lorsqu'un utilisateur pose une question sur un concept scientifique complexe, &ldq
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 Le matériel IA ajoute un autre membre ! Plutôt que de remplacer les téléphones portables, NotePin peut-il vivre plus longtemps ?
Sep 02, 2024 pm 01:40 PM
Le matériel IA ajoute un autre membre ! Plutôt que de remplacer les téléphones portables, NotePin peut-il vivre plus longtemps ?
Sep 02, 2024 pm 01:40 PM
Jusqu’à présent, aucun produit dans le domaine des appareils portables IA n’a obtenu de résultats particulièrement bons. AIPin, qui a été lancé au MWC24 au début de cette année, une fois le prototype d'évaluation expédié, le « mythe de l'IA » qui était en vogue au moment de sa sortie a commencé à être brisé et a connu des retours à grande échelle en seulement un quelques mois ; RabbitR1, qui s'est également bien vendu au début, était relativement meilleur, mais il a également reçu des critiques négatives similaires aux "boîtiers Android" lorsqu'il a été livré en grande quantité. Maintenant, une autre entreprise est entrée sur la piste des appareils portables IA. Le média technologique TheVerge a publié hier un article de blog indiquant que la startup d'IA Plaud a lancé un produit appelé NotePin. Contrairement à AIFriend, qui en est encore au stade de "peinture", NotePin a maintenant démarré
 Comment évaluer la rentabilité du support commercial des frameworks Java
Jun 05, 2024 pm 05:25 PM
Comment évaluer la rentabilité du support commercial des frameworks Java
Jun 05, 2024 pm 05:25 PM
L'évaluation du rapport coût/performance du support commercial pour un framework Java implique les étapes suivantes : Déterminer le niveau d'assurance requis et les garanties de l'accord de niveau de service (SLA). L’expérience et l’expertise de l’équipe d’appui à la recherche. Envisagez des services supplémentaires tels que les mises à niveau, le dépannage et l'optimisation des performances. Évaluez les coûts de support commercial par rapport à l’atténuation des risques et à une efficacité accrue.
 Comment les options légères des frameworks PHP affectent-elles les performances des applications ?
Jun 06, 2024 am 10:53 AM
Comment les options légères des frameworks PHP affectent-elles les performances des applications ?
Jun 06, 2024 am 10:53 AM
Le framework PHP léger améliore les performances des applications grâce à une petite taille et une faible consommation de ressources. Ses fonctionnalités incluent : une petite taille, un démarrage rapide, une faible utilisation de la mémoire, une vitesse de réponse et un débit améliorés et une consommation de ressources réduite. Cas pratique : SlimFramework crée une API REST, seulement 500 Ko, une réactivité élevée et un débit élevé.
