
 Périphériques technologiques
IA
Meta prévoit de publier l'année prochaine une nouvelle version open source du grand modèle de niveau GPT-4. Son nombre de paramètres sera plusieurs fois supérieur à celui de Llama 2. Les utilisateurs peuvent l'utiliser gratuitement à des fins commerciales.
Périphériques technologiques
IA
Meta prévoit de publier l'année prochaine une nouvelle version open source du grand modèle de niveau GPT-4. Son nombre de paramètres sera plusieurs fois supérieur à celui de Llama 2. Les utilisateurs peuvent l'utiliser gratuitement à des fins commerciales.
Meta prévoit de publier l'année prochaine une nouvelle version open source du grand modèle de niveau GPT-4. Son nombre de paramètres sera plusieurs fois supérieur à celui de Llama 2. Les utilisateurs peuvent l'utiliser gratuitement à des fins commerciales.

Selon le média étranger "Wall Street Journal", Meta accélère le développement d'un nouveau grand modèle de langage. Ses capacités seront entièrement alignées sur GPT-4 et devraient être lancées l'année prochaine.

La nouvelle a également spécifiquement souligné que le nouveau grand modèle de langage de Meta sera plusieurs fois plus grand que Llama 2, et qu'il sera très probablement open source et prendra en charge une utilisation commerciale gratuite.
Depuis que Meta a divulgué "accidentellement" LlaMA au début de l'année, jusqu'à la sortie open source de Llama 2 en juillet, Meta a progressivement trouvé sa position unique dans cette vague d'IA - la bannière de l'IA open source communauté.

Le personnel change constamment et les capacités du modèle sont défectueuses, nous ne pouvons donc compter que sur des logiciels open source pour résoudre le problème
Au début de l'année, après qu'OpenAI ait fait exploser l'industrie technologique avec GPT -4, Google et Microsoft ont également lancé leurs propres produits d'IA.
En mai, les régulateurs américains ont invité les PDG d'entreprises de premier plan qu'ils considéraient à l'époque comme pertinentes pour l'industrie de l'IA à tenir une table ronde pour discuter du développement de la technologie de l'IA.
OpenAI, Google et Microsoft ont tous été invités à participer, et même la startup Anthropic, mais Meta ne s'est pas présentée. À cette époque, la réponse officielle à la raison de l'absence de Meta était : "Nous n'avons invité que les plus grandes entreprises du secteur de l'IA."

De bonnes choses ne sont pas arrivées à Meta, mais les problèmes ont continué à arriver.
Xiao Zha a reçu début juin une lettre d'enquête du Congrès lui demandant d'expliquer en détail la cause et l'impact de la fuite de LlaMA en mars. La lettre était formulée avec sévérité et les exigences étaient très claires

Dans les mois suivants, même après la sortie de Llama 2, l'équipe d'IA que Meta avait dépensé beaucoup d'argent pour construire diminuait encore progressivement. à part.
Dans les remerciements de Llama 2, les quatre membres de l'équipe qui ont initié cette recherche ont été mentionnés, dont trois ont démissionné, et actuellement seul Edouard Grave travaille encore chez Meta Company
Géant de l'industrie He Kaiming quittera également Meta et retournera dans le monde universitaire.

Selon un récent article divulgué par The Information, l'équipe d'IA de Meta connaît des frictions constantes en raison de la concurrence pour la puissance de calcul interne, et le personnel part les uns après les autres.
Dans ce contexte, Xiao Zha lui-même devrait également très bien savoir que le grand modèle de langage de Meta est en effet incapable de rivaliser avec le GPT-4 le plus avancé du secteur.
Qu'il s'agisse de diverses directions de tests de référence ou de commentaires des utilisateurs, l'écart entre Llama 2 et GPT-4 est toujours très grand
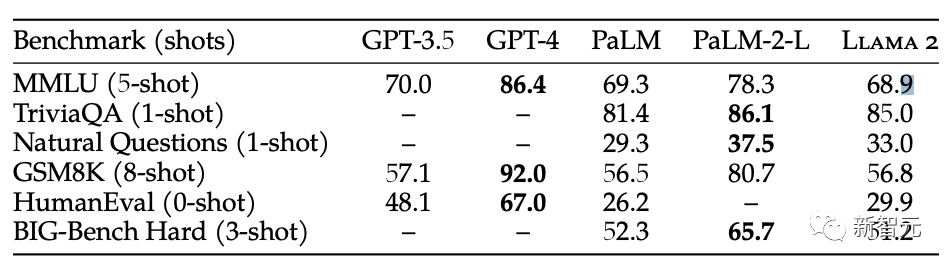
Dans divers tests de référence, l'open source Llama 2 et Il y a un écart considérable entre GPT-4

GPT-4 montre toujours une nette avance sur Llama 2 dans l'expérience réelle des internautes
Par conséquent, Xiao Zha a décidé de laisser Meta continuer à courir sauvagement sur la route des modèles open source
Peut-être que la pensée de Xiao Zha derrière cela est la suivante : les capacités des modèles de Meta sont moyennes et ne peuvent pas rivaliser avec les géants du code source fermé, donc là cela ne sert à rien de continuer à garder sa signification secrète. Par conséquent, ouvrez simplement l'open source et laissez la communauté de l'IA continuer à itérer sur la base de ses propres modèles pour étendre l'influence de ses produits dans l'industrie
Xiao Zha a déclaré publiquement à plusieurs reprises que la communauté open source a joué un rôle inspirant rôle dans leurs itérations de modèles. Permettre à leur équipe technique de développer des produits plus compétitifs à l'avenir

Xiao Zha a souligné dans le podcast de Fridman que l'open source permet à Meta de s'inspirer de la communauté, et Meta pourrait lancer des sources fermées dans le futur modèle.
Voir : https://lexfridman.com/mark-zuckerberg-2/
Et les faits ont prouvé que le choix de Meta est effectivement correct.
Bien qu'ils ne soient pas aussi bons que Google et OpenAI en termes de ressources informatiques et de puissance technique, les modèles open source tels que Meta's Llama 2 sont toujours sans égal dans leur attrait pour la communauté open source. Alors que Llama 2 devient peu à peu la « base technique » de la communauté open source de l’IA, Meta a également trouvé sa propre niche écologique dans l’industrie.
Le signe le plus évident est que lors de la réunion à huis clos du Congrès sur l'IA qui se tiendra en septembre, Xiao Zha est finalement devenu l'invité des régulateurs, agissant en tant que représentant aux côtés des PDG des entreprises les plus avant-gardistes du pays. l'industrie comme Google et OpenAI , faites votre propre voix sur la réglementation de l'industrie de l'IA.
Et si le nouveau modèle lancé par Meta l'année prochaine peut continuer à progresser et acquérir les mêmes capacités que GPT-4, d'une part, il permettra à la communauté open source de continuer à combler l'écart avec les géants du code source fermé, et cela se solidifiera " L'écart entre la communauté open source et le niveau le plus avancé de l'industrie est d'environ un an. "
D'autre part, Xiao Zha a également révélé dans l'interview que si les capacités des grands modèles sont encore améliorées à l'avenir, Meta pourrait lancer son propre modèle fermé. Si le nouveau modèle peut se rapprocher davantage du SOTA de l'industrie, il n'est peut-être pas loin du lancement par Meta de son propre modèle à code source fermé.
Bien que Meta semble temporairement à la traîne dans cette vague d'IA, Xiao Zha ne se contente pas d'être un simple suiveur
Sous la direction de Yann Lecun, Meta se prépare également à renverser l'ensemble de l'industrie
Meta Le futur
Alors, après ce légendaire grand modèle mystérieux qui peut rivaliser avec GPT-4, à quoi ressemblera le futur de Meta AI ?
Comme il n'y a pas encore d'informations spécifiques, nous ne pouvons que faire quelques suppositions, comme en partant de l'attitude du scientifique en chef de Meta AI, LeCun.
Le populaire GPT a toujours été la voie de développement de l'intelligence artificielle que LeCun a critiqué et méprisé.
Le 4 février de cette année, LeCun a exprimé sans détour son opinion selon laquelle les grands modèles de langage sont la mauvaise voie sur la voie de l'IA au niveau humain

Il croit que cette base Les grands modèles d'autorégression générative probabiliste ne survivront pas au maximum 5 ans, car ces intelligences artificielles ne s’entraînent que sur une grande quantité de texte, et elles ne peuvent pas comprendre le monde réel.
Ces modèles ne peuvent ni planifier ni raisonner, ils ont seulement la capacité d'apprendre le contexte
Sérieusement, ces intelligences artificielles formées sur LLM n'ont quasiment aucune "intelligence" du tout.
Ce que LeCun attend avec impatience, c'est un « modèle mondial » qui peut conduire à l'AGI.
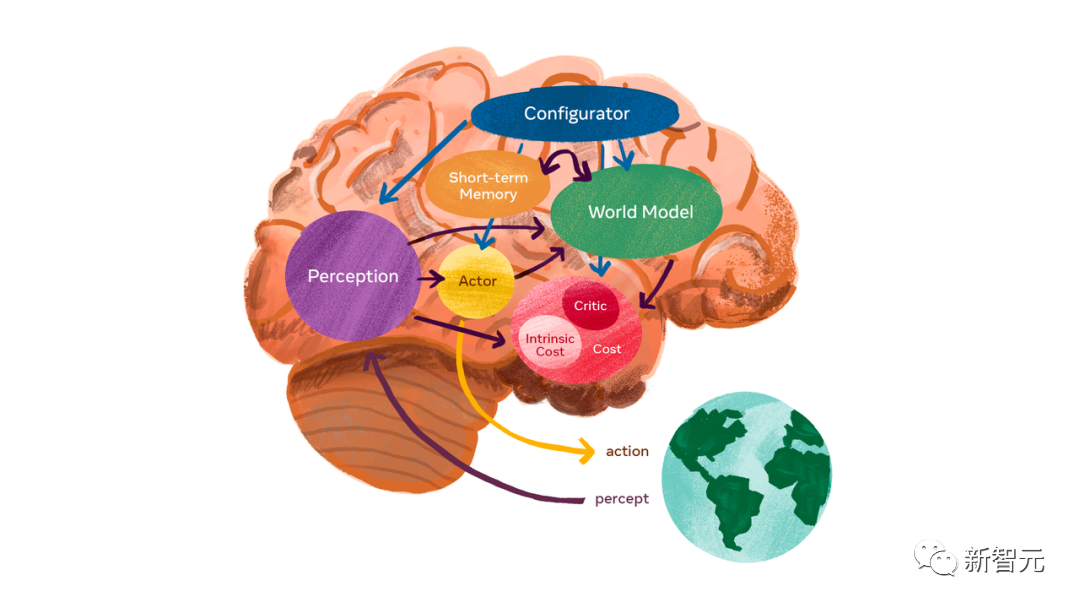
Le modèle du monde peut apprendre comment le monde fonctionne, apprendre plus rapidement, planifier l'exécution de tâches complexes et réagir à de nouvelles situations inconnues à tout moment.
C'est différent du LLM qui nécessite beaucoup de pré-formation. Le modèle du monde peut trouver des modèles à partir d'observations, s'adapter à de nouveaux environnements et maîtriser de nouvelles compétences comme les humains.
Meta s'efforce de développer un modèle diversifié. Par rapport à la stratégie d'amélioration continue et d'approfondissement d'OpenAI dans le domaine LLM
Le 14 juin de cette année, Meta a publié un modèle d'intelligence artificielle « de type humain », I-JEPA. est également le premier modèle d'IA de l'histoire basé sur des éléments clés de la vision du modèle mondial de LeCun.

Veuillez cliquer sur le lien suivant pour consulter l'article : https://arxiv.org/abs/2301.08243
I-JEPA est capable de comprendre les représentations abstraites dans les images et d'acquérir le bon sens par l'auto- apprentissage supervisé
I-JEPA ne nécessite pas de connaissances supplémentaires en production manuelle comme aide
Par la suite, Meta a lancé Voicebox, un nouveau système innovant de génération de parole basé sur une nouvelle méthode proposée par Meta AI - flow matching

Il peut synthétiser la parole en six langues, effectuer des opérations telles que le débruitage, l'édition de contenu et la conversion de styles audio.
Meta a également publié un agent d'IA incarné universel
Avec la coordination des compétences guidée par le langage (LSC), le robot peut librement se déplacer et ramasser des objets dans certains environnements pré-cartographiés
en multi-mode le développement de modèles modaux, Meta possède une fonctionnalité unique :
ImageBind, le premier modèle d'intelligence artificielle capable de lier des informations provenant de six modalités différentes.
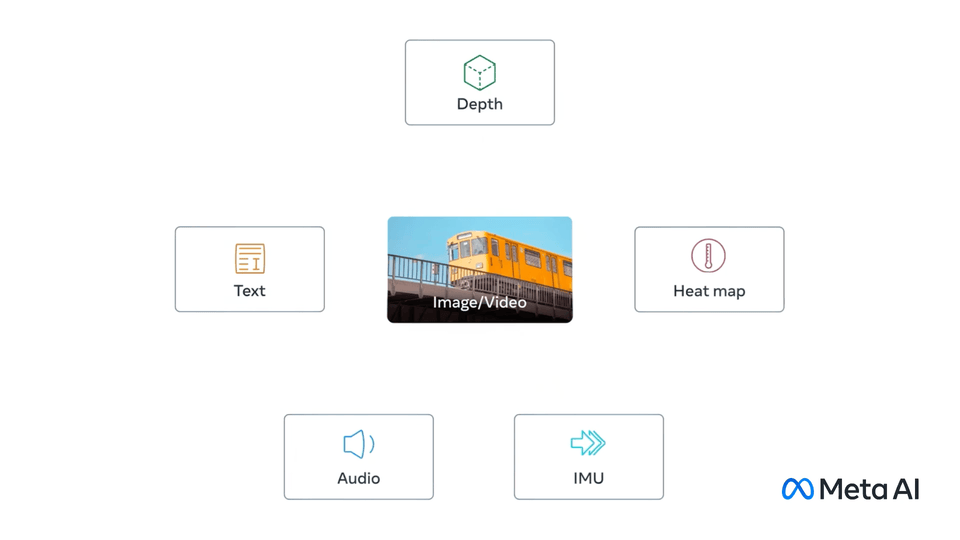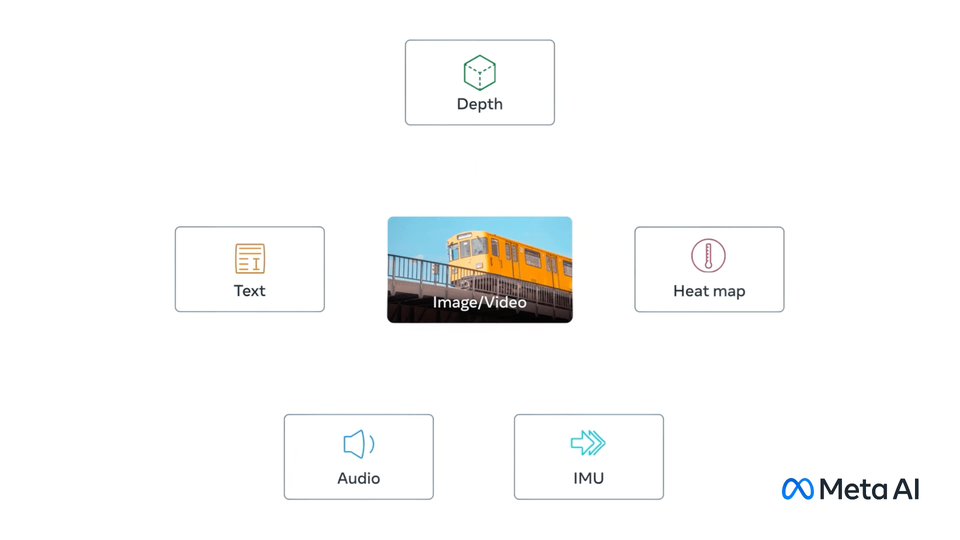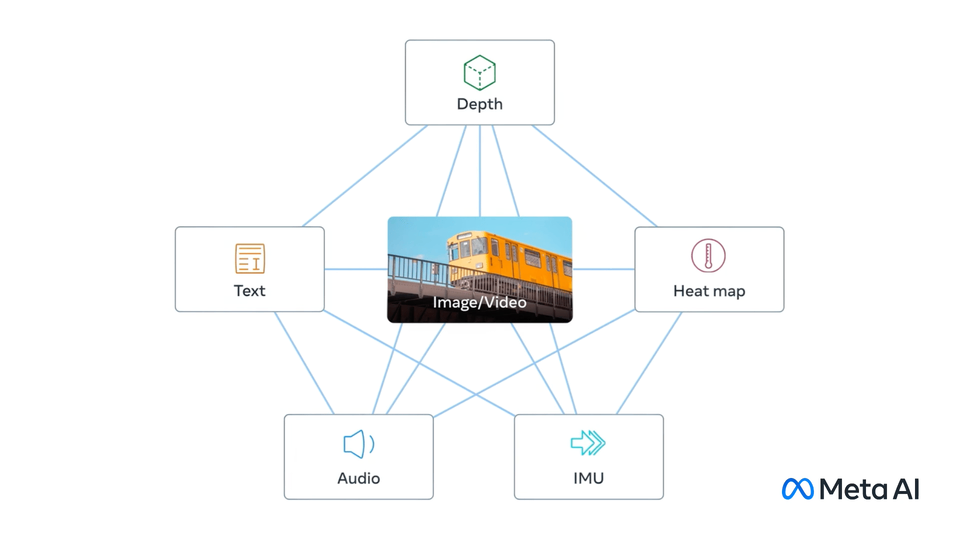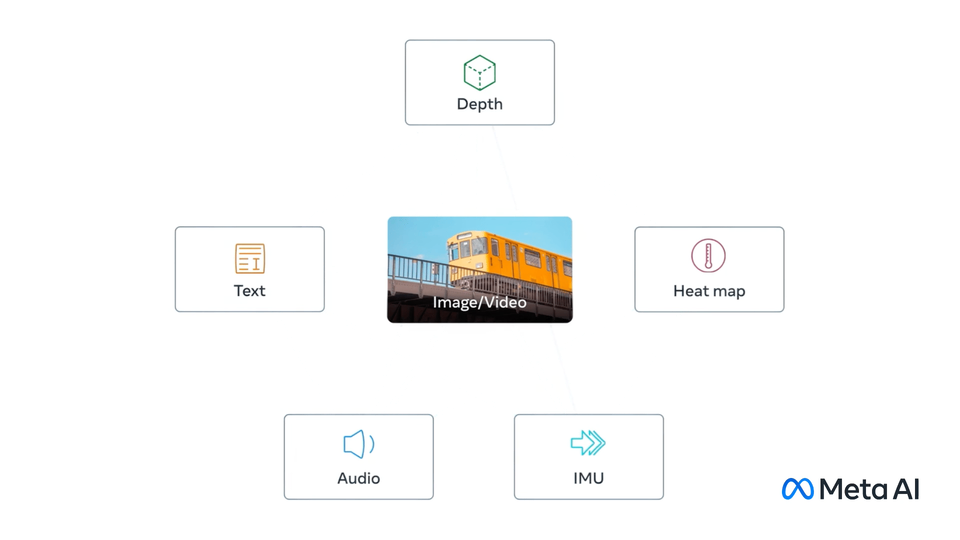
Il possède des capacités complètes de compréhension des machines et peut connecter des objets dans des photos avec leurs sons, leurs formes tridimensionnelles, leurs températures et leurs mouvements
Le RoboAgent développé conjointement par Meta AI et CMU_Robotics, permettant aux robots d'acquérir un variété de compétences non triviales et les généraliser à des centaines de scénarios de vie.
Les données pour tous ces scénarios sont d'un ordre de grandeur inférieur aux travaux précédents dans ce domaine

Concernant le modèle révélé cette fois, certains internautes ont exprimé l'espoir de continuer à ouvrir le code source.
Cependant, certains internautes ont déclaré que Meta ne commencerait à s'entraîner qu'au début de 2024

Mais ce qui est gratifiant, c'est que Meta a quand même émis un signal indiquant qu'elle continuerait à adhérer à la stratégie originale.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Dans Debian Systems, la fonction ReadDir est utilisée pour lire le contenu du répertoire, mais l'ordre dans lequel il revient n'est pas prédéfini. Pour trier les fichiers dans un répertoire, vous devez d'abord lire tous les fichiers, puis les trier à l'aide de la fonction QSORT. Le code suivant montre comment trier les fichiers de répertoire à l'aide de ReadDir et QSort dans Debian System: # include # include # include # include # include // Fonction de comparaison personnalisée, utilisée pour qsortintCompare (constvoid * a, constvoid * b) {returnstrcmp (* (
 Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Dans Debian Systems, les appels du système ReadDir sont utilisés pour lire le contenu des répertoires. Si ses performances ne sont pas bonnes, essayez la stratégie d'optimisation suivante: simplifiez le nombre de fichiers d'annuaire: divisez les grands répertoires en plusieurs petits répertoires autant que possible, en réduisant le nombre d'éléments traités par appel ReadDir. Activer la mise en cache de contenu du répertoire: construire un mécanisme de cache, mettre à jour le cache régulièrement ou lorsque le contenu du répertoire change et réduire les appels fréquents à Readdir. Les caches de mémoire (telles que Memcached ou Redis) ou les caches locales (telles que les fichiers ou les bases de données) peuvent être prises en compte. Adoptez une structure de données efficace: si vous implémentez vous-même la traversée du répertoire, sélectionnez des structures de données plus efficaces (telles que les tables de hachage au lieu de la recherche linéaire) pour stocker et accéder aux informations du répertoire
 Comment définir le niveau de journal Debian Apache
Apr 13, 2025 am 08:33 AM
Comment définir le niveau de journal Debian Apache
Apr 13, 2025 am 08:33 AM
Cet article décrit comment ajuster le niveau de journalisation du serveur Apacheweb dans le système Debian. En modifiant le fichier de configuration, vous pouvez contrôler le niveau verbeux des informations de journal enregistrées par Apache. Méthode 1: Modifiez le fichier de configuration principal pour localiser le fichier de configuration: le fichier de configuration d'Apache2.x est généralement situé dans le répertoire / etc / apache2 /. Le nom de fichier peut être apache2.conf ou httpd.conf, selon votre méthode d'installation. Modifier le fichier de configuration: Ouvrez le fichier de configuration avec les autorisations racine à l'aide d'un éditeur de texte (comme Nano): Sutonano / etc / apache2 / apache2.conf
 Comment Debian OpenSSL empêche les attaques de l'homme au milieu
Apr 13, 2025 am 10:30 AM
Comment Debian OpenSSL empêche les attaques de l'homme au milieu
Apr 13, 2025 am 10:30 AM
Dans Debian Systems, OpenSSL est une bibliothèque importante pour le chiffrement, le décryptage et la gestion des certificats. Pour empêcher une attaque d'homme dans le milieu (MITM), les mesures suivantes peuvent être prises: utilisez HTTPS: assurez-vous que toutes les demandes de réseau utilisent le protocole HTTPS au lieu de HTTP. HTTPS utilise TLS (Protocole de sécurité de la couche de transport) pour chiffrer les données de communication pour garantir que les données ne sont pas volées ou falsifiées pendant la transmission. Vérifiez le certificat de serveur: vérifiez manuellement le certificat de serveur sur le client pour vous assurer qu'il est digne de confiance. Le serveur peut être vérifié manuellement via la méthode du délégué d'URLSession
 Méthode d'installation du certificat de Debian Mail Server SSL
Apr 13, 2025 am 11:39 AM
Méthode d'installation du certificat de Debian Mail Server SSL
Apr 13, 2025 am 11:39 AM
Les étapes pour installer un certificat SSL sur le serveur de messagerie Debian sont les suivantes: 1. Installez d'abord la boîte à outils OpenSSL, assurez-vous que la boîte à outils OpenSSL est déjà installée sur votre système. Si ce n'est pas installé, vous pouvez utiliser la commande suivante pour installer: Sudoapt-getUpDaSuDoapt-getInstallOpenSSL2. Générer la clé privée et la demande de certificat Suivant, utilisez OpenSSL pour générer une clé privée RSA 2048 bits et une demande de certificat (RSE): OpenSS
 Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
La fonction ReadDir dans le système Debian est un appel système utilisé pour lire le contenu des répertoires et est souvent utilisé dans la programmation C. Cet article expliquera comment intégrer ReadDir avec d'autres outils pour améliorer sa fonctionnalité. Méthode 1: combinant d'abord le programme de langue C et le pipeline, écrivez un programme C pour appeler la fonction readdir et sortir le résultat: # include # include # include # includeIntmain (intargc, char * argv []) {dir * dir; structDirent * entrée; if (argc! = 2) {
 Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
La configuration du pare-feu d'un serveur de courrier Debian est une étape importante pour assurer la sécurité du serveur. Voici plusieurs méthodes de configuration de pare-feu couramment utilisées, y compris l'utilisation d'iptables et de pare-feu. Utilisez les iptables pour configurer le pare-feu pour installer iptables (sinon déjà installé): Sudoapt-getUpDaSuDoapt-getinstalliptableView Règles actuelles iptables: Sudoiptable-L Configuration
 Comment faire Debian Hadoop Log Management
Apr 13, 2025 am 10:45 AM
Comment faire Debian Hadoop Log Management
Apr 13, 2025 am 10:45 AM
Gérer les journaux Hadoop sur Debian, vous pouvez suivre les étapes et les meilleures pratiques suivantes: l'agrégation de journal Activer l'agrégation de journaux: définir yarn.log-aggregation-inable à true dans le fichier yarn-site.xml pour activer l'agrégation de journaux. Configurer la stratégie de rétention du journal: Définissez Yarn.log-agregation.retain-secondes pour définir le temps de rétention du journal, tel que 172800 secondes (2 jours). Spécifiez le chemin de stockage des journaux: via yarn.n
