
 Périphériques technologiques
IA
Lao Huang donne un coup de pouce au H100 : Nvidia lance un package d'accélération pour grands modèles, doublant la vitesse d'inférence de Llama2
Périphériques technologiques
IA
Lao Huang donne un coup de pouce au H100 : Nvidia lance un package d'accélération pour grands modèles, doublant la vitesse d'inférence de Llama2
Lao Huang donne un coup de pouce au H100 : Nvidia lance un package d'accélération pour grands modèles, doublant la vitesse d'inférence de Llama2

La vitesse d'inférence des grands modèles a doublé en seulement un mois !
Récemment, NVIDIA a annoncé le lancement d'un « package de sang de poulet » spécialement conçu pour le H100, visant à accélérer le processus d'inférence LLM
Peut-être que maintenant vous n'aurez plus à attendre que le GH200 soit livré l'année prochaine .
.
La puissance de calcul du GPU a toujours affecté les performances des grands modèles. Les fournisseurs de matériel et les utilisateurs espèrent obtenir des vitesses de calcul plus rapides.
En tant que plus grand fournisseur de matériel derrière les grands modèles, NVIDIA a étudié comment matérielr. accélérer les grands modèles.
Grâce à une coopération avec un certain nombre de sociétés d'IA, NVIDIA a finalement lancé le programme d'optimisation d'inférence de grands modèles TensorRT-LLM (provisoirement appelé TensorRT).
TensorRT peut non seulement doubler la vitesse d'inférence des grands modèles, mais est également très pratique à utiliser.
Pas besoin d'avoir une connaissance approfondie de C++ et de CUDA, vous pouvez rapidement personnaliser les stratégies d'optimisation et exécuter de grands modèles plus rapidement sur H100.
Le scientifique de NVIDIA, Jim Fan, a retweeté et commenté que « un autre avantage » de NVIDIA est le logiciel de support qui peut maximiser l'utilisation des performances du GPU.
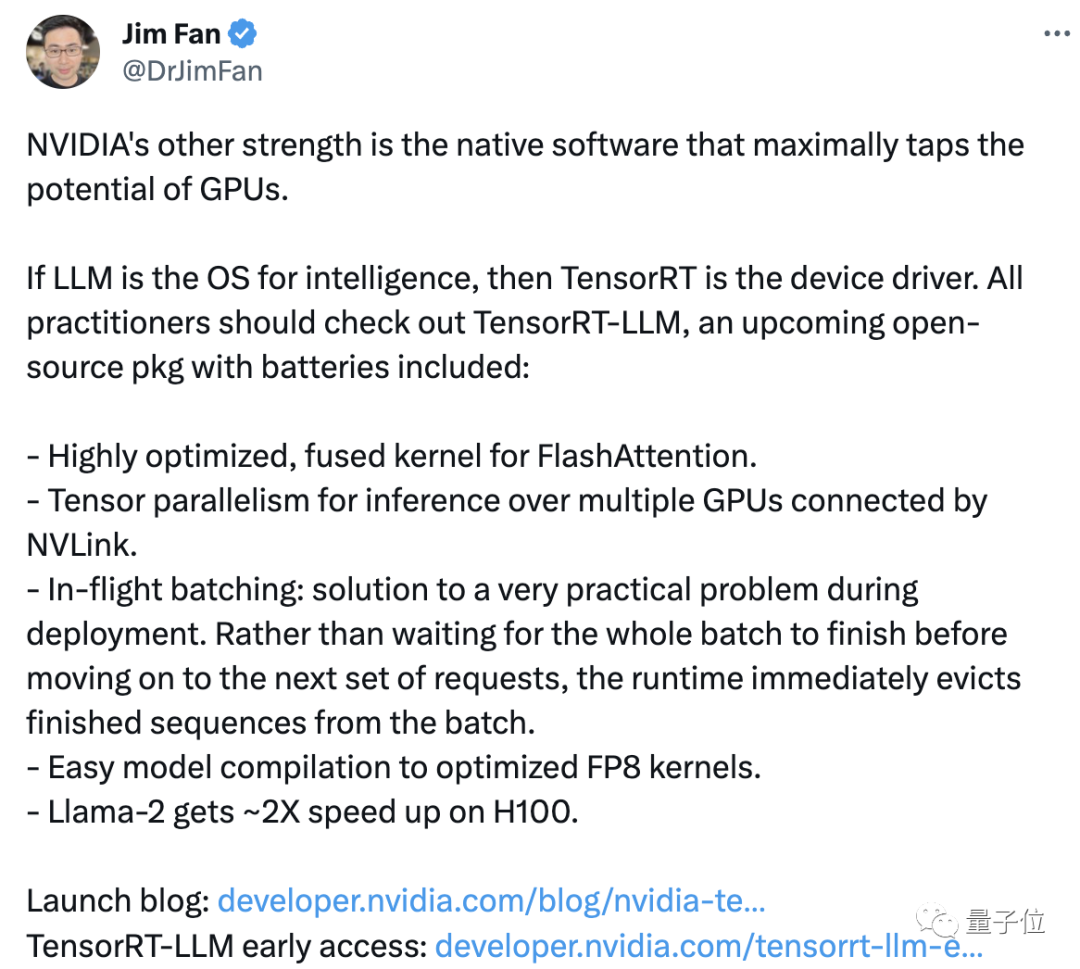
NVIDIA injecte une nouvelle vitalité dans ses produits grâce à des logiciels, tout comme elle met en œuvre le dicton de Lao Huang « plus vous achetez, plus vous économisez ». Cependant, cela n'empêche pas certains de penser que le prix du produit est trop élevé
En plus du prix, certains internautes ont également remis en question ses résultats d'exploitation :
On voit toujours combien de fois les performances sont améliorées (dans la publicité), mais lorsque j'exécute moi-même Llama 2, je ne peux toujours traiter que des dizaines de jetons par seconde.
Pour TensorRT, nous avons besoin de tests supplémentaires pour déterminer s'il est vraiment efficace. Examinons d'abord de plus près TensorRT
Doublez la vitesse d'inférence des grands modèles
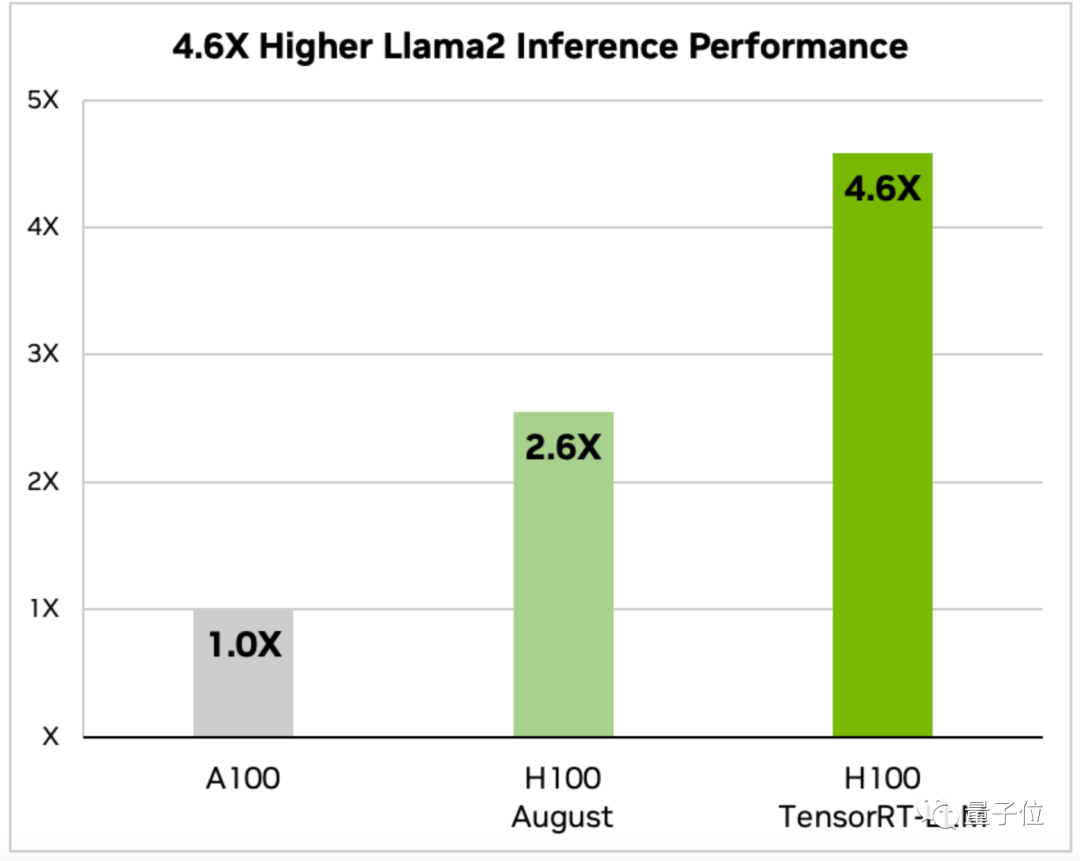
TensorRT-LLM optimisé H100 Quelle est la vitesse d'exécution de grands modèles ?
L'annonce de Nvidia fournit des données pour deux modèles, Llama 2 et GPT-J-6B.
Sur le H100 optimisé, la vitesse d'inférence de Llama 2 est 4,6 fois celle de l'A100 et 1,77 fois celle du H100 non optimisé en août
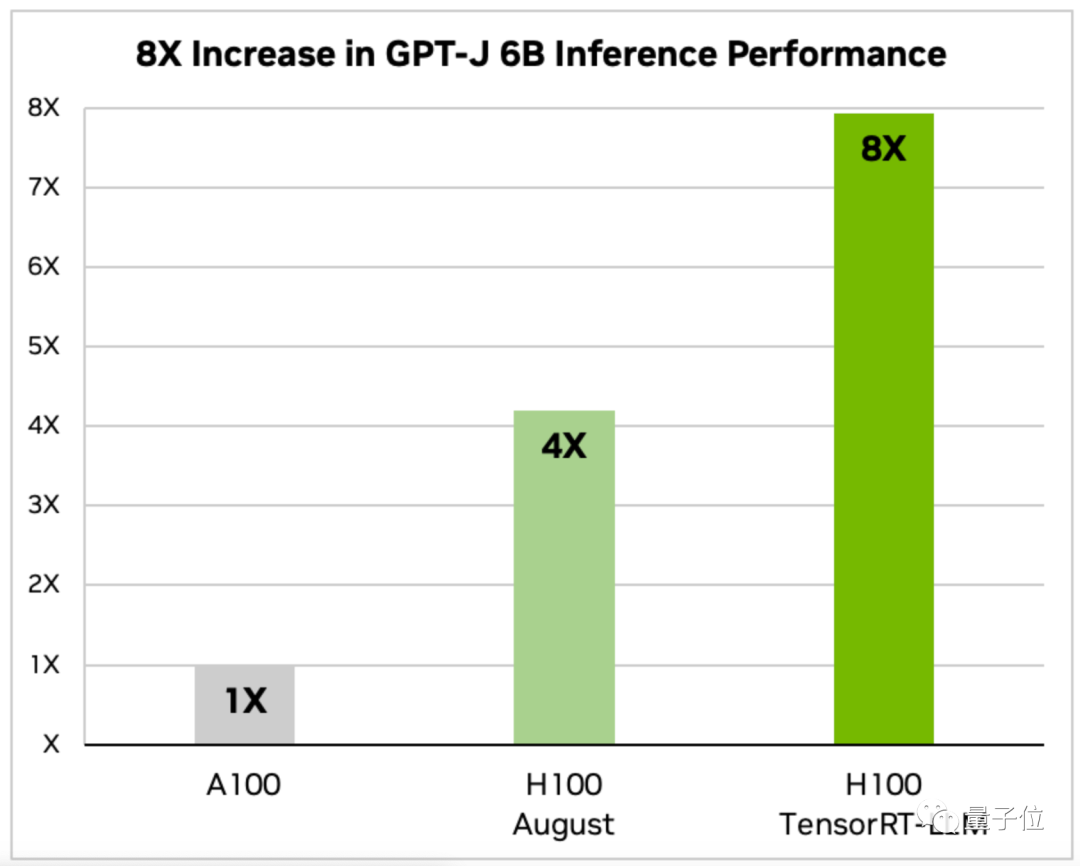
Et la vitesse d'inférence de GPT-J-6B est A100 8 fois celle de la version précédente et 2 fois celle de la version non optimisée d'août.
TensorRT fournit également une API Python modulaire open source qui peut rapidement personnaliser les solutions d'optimisation en fonction des différentes exigences LLM
Cette API intègre un compilateur d'apprentissage en profondeur, l'optimisation du noyau, des fonctions de pré/post-traitement et de communication multi-nœuds .
Il existe également des versions personnalisées pour les modèles courants tels que GPT(2/3) et Llama, qui peuvent être utilisées "prêtes à l'emploi".
Grâce au dernier noyau d'IA open source de TensorRT, les développeurs peuvent également optimiser le modèle lui-même, y compris l'algorithme d'attention FlashAttention, qui accélère considérablement Transformer.
TensorRT est un moteur d'inférence hautes performances pour optimiser l'inférence du deep learning. Il optimise la vitesse d'inférence LLM en utilisant des technologies telles que le calcul à précision mixte, l'optimisation de graphiques dynamiques et la fusion de couches. Plus précisément, TensorRT améliore la vitesse d'inférence en réduisant la quantité de calcul et les besoins en bande passante mémoire en convertissant les calculs à virgule flottante en calculs à virgule flottante demi-précision. De plus, TensorRT utilise également une technologie d'optimisation de graphiques dynamiques pour sélectionner dynamiquement la structure de réseau optimale en fonction des caractéristiques des données d'entrée, améliorant ainsi encore la vitesse d'inférence. De plus, TensorRT utilise également la technologie de fusion de couches pour fusionner plusieurs couches informatiques en une couche informatique plus efficace, réduisant ainsi les frais de calcul et d'accès à la mémoire et améliorant encore la vitesse d'inférence. En bref, TensorRT a considérablement amélioré la vitesse et l'efficacité de l'inférence LLM grâce à une variété de technologies d'optimisation
Tout d'abord, il bénéficie de TensorRToptimisant la méthode de travail collaboratif multi-nœuds.
Un modèle énorme comme Llama ne peut pas être exécuté sur une seule carte. Il nécessite plusieurs GPU pour fonctionner ensemble.
Dans le passé, ce travail nécessitait de démonter manuellement le modèle pour le réaliser.
Avec TensorRT, le système peut automatiquement diviser le modèle et l'exécuter efficacement sur plusieurs GPU via NVLink

Deuxièmement, TensorRT utilise également une planification optimisée appelée technologie Dynamic Batch Processing.
Pendant le processus d'inférence, LLM procède en exécutant plusieurs fois des itérations du modèle
La technologie de traitement par lots dynamique exécutera immédiatement la séquence terminée au lieu d'attendre que l'ensemble du lot de tâches soit terminé avant de traiter l'ensemble de requêtes suivant.
Dans des tests réels, la technologie de traitement par lots dynamique a réussi à réduire de moitié le débit des requêtes GPU de LLM, réduisant ainsi considérablement les coûts de fonctionnement
Un autre point clé est la conversion de nombres à virgule flottante de précision 16 bits en précision 8 bits , réduisant ainsi la consommation de mémoire.
Par rapport au FP16 en phase de formation, le FP8 consomme moins de ressources et est plus précis que l'INT-8. Il peut améliorer les performances sans affecter la précision du modèle.
En utilisant le moteur Hopper Transformer, le système terminera automatiquement le FP16. vers la compilation de conversion FP8 sans modifier manuellement aucun code dans le modèle
Actuellement, la version anticipée de TensorRT-LLM est disponible en téléchargement, et la version officielle sera lancée et intégrée au framework NeMo dans quelques semaines
One More Chose
Chaque fois qu'un grand événement survient, la figure de "Leewenhoek" est indispensable.
Dans l'annonce de Nvidia, il a mentionné la coopération avec des sociétés d'intelligence artificielle de premier plan telles que Meta, mais n'a pas mentionné OpenAI
À partir de cette annonce, certains internautes ont découvert ce point et l'ont publié sur le forum OpenAI :
S'il vous plaît, laissez-moi voir qui n'a pas été repéré par Lao Huang (tête de chien manuelle)

Quel genre de "surprise" pensez-vous que Lao Huang nous apportera ?
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Existe-t-il un outil gratuit XML à PDF pour les téléphones mobiles?
Apr 02, 2025 pm 09:12 PM
Existe-t-il un outil gratuit XML à PDF pour les téléphones mobiles?
Apr 02, 2025 pm 09:12 PM
Il n'y a pas d'outil XML à PDF simple et direct sur mobile. Le processus de visualisation des données requis implique une compréhension et un rendu complexes des données, et la plupart des outils dits "gratuits" sur le marché ont une mauvaise expérience. Il est recommandé d'utiliser des outils côté informatique ou d'utiliser des services cloud, ou de développer vous-même des applications pour obtenir des effets de conversion plus fiables.
 Comment embellir le format XML
Apr 02, 2025 pm 09:57 PM
Comment embellir le format XML
Apr 02, 2025 pm 09:57 PM
L'embellissement XML améliore essentiellement sa lisibilité, y compris l'indentation raisonnable, les pauses-lignes et l'organisation des étiquettes. Le principe est de traverser l'arbre XML, d'ajouter l'indentation en fonction du niveau et de gérer les balises et les balises vides contenant du texte. La bibliothèque XML.ETREE.ElementTree de Python fournit une fonction Pretty_xml () pratique qui peut implémenter le processus d'embellissement ci-dessus.
 Comment vérifier le format XML
Apr 02, 2025 pm 10:00 PM
Comment vérifier le format XML
Apr 02, 2025 pm 10:00 PM
La validation du format XML consiste à vérifier sa structure et sa conformité avec DTD ou schéma. Un analyseur XML est requis, tel que ElementTree (Basic Syntax Heatking) ou LXML (vérification plus puissante, prise en charge XSD). Le processus de vérification implique l'analyse du fichier XML, le chargement du schéma XSD et l'exécution de la méthode AssertValid pour lancer une exception lorsqu'une erreur est détectée. La vérification du format XML nécessite également de gérer diverses exceptions et de mieux comprendre le langage du schéma XSD.
 Comment utiliser Char Array dans la langue C
Apr 03, 2025 pm 03:24 PM
Comment utiliser Char Array dans la langue C
Apr 03, 2025 pm 03:24 PM
Le Array Char stocke des séquences de caractères en C et est déclaré Char Array_name [Taille]. L'élément d'accès est passé par l'opérateur d'indice, et l'élément se termine par le terminateur nul «\ 0», qui représente le point final de la chaîne. Le langage C fournit une variété de fonctions de manipulation de cordes, telles que strlen (), strcpy (), strcat () et strcmp ().
 Comment convertir XML en image à l'aide de Java?
Apr 02, 2025 pm 08:36 PM
Comment convertir XML en image à l'aide de Java?
Apr 02, 2025 pm 08:36 PM
Il n'y a pas de méthode "universelle": la conversion XML à l'image nécessite de sélectionner la stratégie appropriée basée sur les données XML et le style d'image cible. Analyse XML: Utilisez des bibliothèques telles que DOM, SAX, STAX ou JAXB. Traitement d'image: utilisez un package java.awt.image ou des bibliothèques plus avancées telles que ImageIo et Javafx. Données à la cartographie d'image: définit les règles de mappage des nœuds XML aux parties d'image. Considérez des scénarios complexes: traitant des erreurs XML, de la mise à l'échelle de l'image et du rendu de texte. Optimisation des performances: utilisez des technologies SAX Parser ou multithreading.
 Évitez les erreurs causées par défaut dans les instructions du commutateur C
Apr 03, 2025 pm 03:45 PM
Évitez les erreurs causées par défaut dans les instructions du commutateur C
Apr 03, 2025 pm 03:45 PM
Une stratégie pour éviter les erreurs causées par défaut dans les instructions de commutateur C: utilisez des énumérations au lieu des constantes, limitant la valeur de l'instruction de cas à un membre valide de l'énumération. Utilisez Fallthrough dans la dernière instruction de cas pour permettre au programme de continuer à exécuter le code suivant. Pour les instructions de commutation sans tomber, ajoutez toujours une instruction par défaut pour la gestion des erreurs ou fournissez un comportement par défaut.
 Comment utiliser les fonctions insignifiantes en minuscules dans différents fichiers dans le même package?
Apr 02, 2025 pm 05:00 PM
Comment utiliser les fonctions insignifiantes en minuscules dans différents fichiers dans le même package?
Apr 02, 2025 pm 05:00 PM
Comment utiliser les noms minuscules dans différents fichiers dans le même package? En allant ...
 Comment définir les polices pour la conversion XML en images?
Apr 02, 2025 pm 08:00 PM
Comment définir les polices pour la conversion XML en images?
Apr 02, 2025 pm 08:00 PM
La conversion de XML en images implique les étapes suivantes: Sélection de la bibliothèque de traitement d'image appropriée, telle que l'oreiller. Utilisez l'analyseur pour analyser XML et extraire les attributs de style de police (police, taille de police, couleur). Utilisez une bibliothèque d'images telle que Pillow pour coiffer la police et rendre le texte. Calculez la taille du texte, créez du toile et dessinez du texte à l'aide de la bibliothèque d'images. Enregistrez le fichier image généré. Notez que les chemins de fichier de police, la gestion des erreurs et l'optimisation des performances nécessitent une considération supplémentaire.
