
 Périphériques technologiques
IA
Manque de données de haute qualité pour entraîner de grands modèles ? Nous avons trouvé une nouvelle solution
Périphériques technologiques
IA
Manque de données de haute qualité pour entraîner de grands modèles ? Nous avons trouvé une nouvelle solution
Manque de données de haute qualité pour entraîner de grands modèles ? Nous avons trouvé une nouvelle solution

Les données, en tant que l'un des trois facteurs majeurs qui déterminent les performances des modèles d'apprentissage automatique, deviennent un goulot d'étranglement limitant le développement de grands modèles. Comme le dit le proverbe « Garbage in, garbage out » [1], quelle que soit la qualité de votre algorithme et la puissance de vos ressources informatiques, la qualité du modèle dépend directement des données que vous utilisez pour entraîner le modèle.
Avec l'émergence de divers grands modèles open source, l'importance des données est encore davantage soulignée, en particulier les données industrielles de haute qualité. Bloomberg construit un grand modèle financier BloombergGPT basé sur le cadre open source GPT-3, qui prouve la faisabilité du développement de grands modèles pour les industries verticales basés sur le cadre de grands modèles open source. En fait, la construction ou la personnalisation de grands modèles légers et fermés pour les industries verticales est la voie choisie par la plupart des grandes startups de modèles en Chine.
Dans cette filière, des données industrielles verticales de haute qualité, des capacités de réglage fin et d'alignement basées sur des connaissances professionnelles sont cruciales - BloombergGPT est basé sur les documents financiers accumulés par Bloomberg depuis plus de 40 ans, et le corpus de formation compte plus plus de 700 milliards de jetons[2 ].
Cependant, obtenir des données de haute qualité n’est pas chose facile. Certaines études ont souligné qu’au rythme actuel auquel les grands modèles dévorent des données, les données linguistiques de haute qualité du domaine public, telles que les livres, les reportages, les articles scientifiques, Wikipédia, etc., seront épuisées vers 2026 [3].
Il existe relativement peu de ressources de données chinoises de haute qualité accessibles au public, et les services de données professionnels nationaux en sont encore à leurs balbutiements. La collecte, le nettoyage, l'étiquetage et la vérification des données nécessitent beaucoup de main-d'œuvre et de ressources matérielles. Il est rapporté que le coût de la collecte et du nettoyage de 3 To de données chinoises de haute qualité pour une grande équipe modèle d'une université nationale, y compris le téléchargement de la bande passante des données, les ressources de stockage de données (les données originales non nettoyées sont d'environ 100 To) et les coûts des ressources CPU pour le nettoyage. les données totalisent environ des centaines de milliers de yuans.
À mesure que le développement de grands modèles s'approfondit, pour former des modèles industriels verticaux qui répondent aux besoins de l'industrie et ont une précision extrêmement élevée, davantage d'expertise industrielle et même des données commerciales confidentielles du domaine privé sont nécessaires. Cependant, en raison des exigences en matière de protection de la vie privée et des difficultés liées à la confirmation des droits et au partage des bénéfices, les entreprises sont souvent réticentes, incapables ou effrayées de partager leurs données.
Existe-t-il une solution qui puisse non seulement profiter des avantages de l'ouverture et du partage des données, mais également protéger la sécurité et la confidentialité des données ?
L'informatique confidentielle peut-elle résoudre le dilemme ?
Le calcul préservant la confidentialité peut analyser, traiter et utiliser les données sans garantir que le fournisseur de données ne divulgue pas les données originales. Il est considéré comme une technologie clé pour promouvoir la circulation et la transaction des éléments de données[4] , Par conséquent, utiliser l’informatique confidentielle pour protéger la sécurité des données des grands modèles semble être un choix naturel.
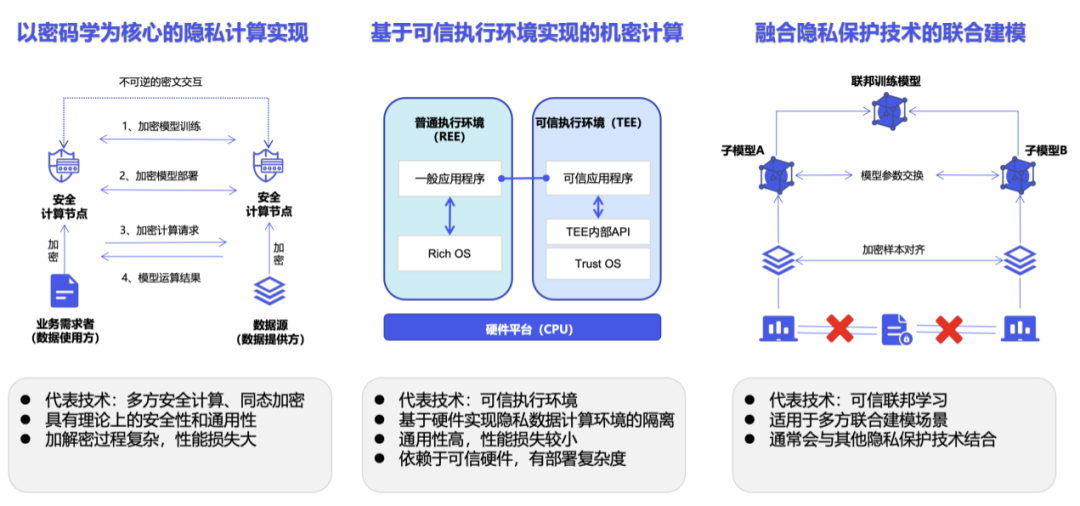
L'informatique de confidentialité n'est pas une technologie, mais un système technique. Selon la mise en œuvre spécifique, l'informatique confidentielle est principalement divisée en chemins de cryptographie représentés par l'informatique sécurisée multipartite, en chemins informatiques confidentiels représentés par des environnements d'exécution fiables et en chemins d'intelligence artificielle représentés par l'apprentissage fédéré [5].
Cependant, dans les applications pratiques, l'informatique confidentielle présente certaines limites. Par exemple, l’introduction du SDK informatique de confidentialité conduit généralement à des modifications au niveau du code du système commercial d’origine [6]. S'il est mis en œuvre sur la base de la cryptographie, les opérations de cryptage et de déchiffrement augmenteront la quantité de calcul de manière exponentielle, et le calcul du texte chiffré nécessitera des ressources de calcul et de stockage ainsi qu'une charge de communication plus importantes [7].
De plus, les solutions informatiques de confidentialité existantes rencontreront de nouveaux problèmes dans les scénarios de formation de grands modèles impliquant des quantités de données extrêmement importantes.
Schémas basés sur l'apprentissage fédéré
Examinons d'abord les difficultés de l'apprentissage fédéré. L'idée centrale de l'apprentissage fédéré est « les données ne bougent pas mais le modèle bouge ». Cette approche décentralisée garantit que les données sensibles restent locales et n'ont pas besoin d'être exposées ou transmises. Chaque appareil ou serveur participe au processus de formation en envoyant des mises à jour du modèle au serveur central, qui regroupe et fusionne ces mises à jour pour améliorer le modèle global [8].
Cependant, la formation centralisée de grands modèles est déjà très difficile et les méthodes de formation distribuées augmentent considérablement la complexité du système. Nous devons également prendre en compte l'hétérogénéité des données lorsque le modèle est entraîné sur différents appareils, et comment agréger en toute sécurité les poids d'apprentissage sur tous les appareils. Pour l'entraînement de grands modèles, les poids du modèle eux-mêmes constituent un atout important. De plus, il faut empêcher les attaquants de déduire des données privées à partir d’une seule mise à jour de modèle, et les défenses correspondantes augmenteraient encore les frais de formation.
Solution basée sur la cryptographie
Le cryptage homomorphe peut calculer directement les données cryptées, rendant les données « disponibles et invisibles » [9]. Le cryptage homomorphe est un outil puissant pour protéger la vie privée dans les scénarios où des données sensibles sont traitées ou analysées et où leur confidentialité est garantie. Cette technique peut être appliquée non seulement à la formation de grands modèles, mais également à l'inférence tout en protégeant la confidentialité des entrées utilisateur (invite).
Cependant, utiliser des données cryptées est beaucoup plus difficile que d'utiliser des données non cryptées pour la formation et l'inférence de grands modèles. Dans le même temps, le traitement des données cryptées nécessite davantage de calculs, ce qui augmente de façon exponentielle le temps de traitement et augmente encore les besoins en puissance de calcul déjà très élevés pour la formation de grands modèles.
Solutions basées sur Trusted Execution Environment
Parlons des solutions basées sur Trusted Execution Environment (TEE). La plupart des solutions ou produits TEE nécessitent l'achat d'équipements spécialisés supplémentaires, tels que des nœuds informatiques sécurisés multipartites, des équipements d'environnement d'exécution de confiance, des cartes accélératrices cryptographiques, etc., et ne peuvent pas s'adapter aux ressources informatiques et de stockage existantes, ce qui rend cette solution inadaptée à de nombreuses personnes. Ce n'est pas réaliste pour les petites et moyennes entreprises. De plus, les solutions TEE actuelles sont principalement basées sur le CPU, tandis que la formation de grands modèles repose fortement sur le GPU. À ce stade, les solutions GPU prenant en charge le calcul de la confidentialité ne sont pas encore matures, mais créent au contraire des risques supplémentaires [10].
En général, dans les scénarios d'informatique collaborative multipartite, il est souvent déraisonnable d'exiger que les données brutes soient « invisibles » au sens physique. De plus, étant donné que le processus de chiffrement ajoute du bruit aux données, la formation ou l'inférence sur les données chiffrées entraînera également une perte de performances du modèle et réduira sa précision. Les solutions informatiques de confidentialité existantes ne sont pas bien adaptées aux scénarios de formation de grands modèles en termes de performances et de prise en charge GPU. Elles empêchent également les entreprises et les institutions disposant de ressources de données de haute qualité d'ouvrir et de partager des informations et de participer à l'industrie du modèle à grande échelle.
L'informatique contrôlable, un nouveau paradigme de l'informatique confidentielle
"Lorsque nous regardons la grande industrie du modèle comme une chaîne allant des données à l'application, nous constaterons que cette chaîne est en réalité une variété de données (y compris des données brutes , comprend également la chaîne de circulation des données qui existent dans le modèle sous forme de paramètres) entre différentes entités, et le modèle économique de cette industrie doit être construit sur la base que ces données (ou modèles) en circulation sont des actifs pouvant être échangés. ", a déclaré le Dr Tang Zaiyang, PDG de YiZhi Technology.
"La circulation des éléments de données implique plusieurs entités, et la source de la chaîne industrielle doit être le fournisseur de données. En d'autres termes, toutes les entreprises sont effectivement initiées par le fournisseur de données. Ce n'est qu'avec l'autorisation du fournisseur de données que la transaction soit finalisée. C'est possible, la priorité doit donc être donnée à garantir les droits et les intérêts des fournisseurs de données. "
Les principales solutions de protection de la vie privée actuellement sur le marché, telles que l'informatique sécurisée multipartite, l'environnement d'exécution fiable. et l'apprentissage fédéré, tous se concentrent sur la manière dont les utilisateurs de données traitent les données. Tang Zaiyang estime que nous devons examiner le problème du point de vue du fournisseur de données.
Yizhi Technology a été créée en 2019 et se positionne comme un fournisseur de solutions de protection de la vie privée pour la coopération en matière de données. En 2021, la société a été sélectionnée comme l'une des premières unités participantes à la « Data Security Initiative (DSI) » lancée par l'Académie chinoise des technologies de l'information et des communications, et a été certifiée par la DSI comme l'une des neuf sociétés représentatives de l'informatique privée. fournisseurs d'entreprise. En 2022, YiZhi Technology est officiellement devenue membre de la communauté open source Open Islands, la première communauté open source internationale indépendante et contrôlable de Chine pour l'informatique confidentielle, afin de promouvoir conjointement la construction d'infrastructures clés pour la circulation des éléments de données.
En réponse au dilemme actuel en matière de données lié à la formation de grands modèles, ainsi qu'à la circulation plus large des éléments de données, Yizhi Technology a proposé une nouvelle solution informatique de confidentialité basée sur la pratique : l'informatique contrôlable.
"L'objectif principal de l'informatique contrôlable est de découvrir et de partager des informations d'une manière préservant la confidentialité. Le problème que nous résolvons est d'assurer la sécurité des données utilisées pendant le processus de formation et d'empêcher le modèle formé de être volé par malveillance ", a déclaré Tang Zaiyang.
Plus précisément, l'informatique contrôlable nécessite que les utilisateurs de données traitent et traitent les données dans le domaine de sécurité défini par le fournisseur de données.
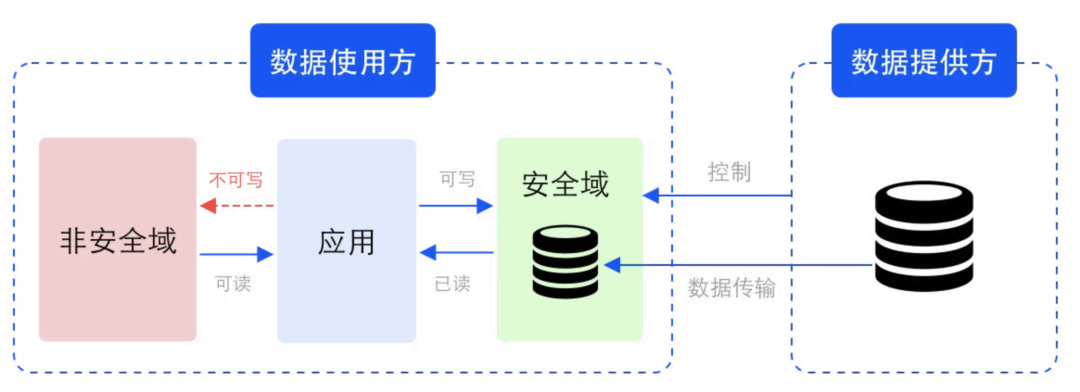
Exemple de domaine de sécurité dans un scénario de circulation de données
Le domaine de sécurité est un concept logique qui fait référence aux unités de stockage et de calcul protégées par des clés et des algorithmes de cryptage correspondants. Le domaine de sécurité est défini et contraint par le fournisseur de données, mais les ressources de stockage et de calcul correspondantes ne sont pas fournies par le fournisseur de données. Physiquement, le domaine de sécurité se situe du côté de l’utilisateur des données mais est contrôlé par le fournisseur de données. Outre les données brutes, les données intermédiaires traitées et traitées ainsi que les données de résultat relèvent également du même domaine de sécurité.
Dans le domaine de la sécurité, les données peuvent être en texte chiffré (invisible) ou en texte brut (visible). Dans le cas du texte en clair, puisque la plage visible des données est contrôlée, il est assuré que les données sont utilisées pendant la sécurité d'utilisation. .
La dégradation des performances causée par le calcul complexe du texte chiffré est un facteur important limitant le champ d'application de l'informatique de confidentialité. En mettant l'accent sur la contrôlabilité des données au lieu de rechercher aveuglément l'invisibilité, l'informatique contrôlable résout le problème des solutions informatiques de confidentialité traditionnelles. intrusif pour les affaires, il est donc très approprié pour les scénarios de formation de grands modèles qui doivent traiter des données à très grande échelle.
Les entreprises peuvent choisir de stocker leurs données dans plusieurs domaines de sécurité différents et définir différents niveaux de sécurité, autorisations d'utilisation ou listes blanches pour ces domaines de sécurité. Pour les applications distribuées, les domaines de sécurité peuvent également être définis sur plusieurs nœuds informatiques ou même sur des puces.
"Les domaines de sécurité peuvent être enchaînés. Dans chaque lien de circulation des données, les fournisseurs de données peuvent définir plusieurs domaines de sécurité différents afin que leurs données ne puissent circuler qu'entre ces domaines de sécurité. Au final, ces domaines de sécurité sérialisés construisent un réseau de données. Sur ce réseau, les données sont contrôlables, le flux, l'analyse et le traitement des données peuvent également être mesurés et surveillés, et la circulation des données peut également être monétisée en conséquence.
Basé sur l'idée de l'informatique contrôlable, YiZhi Technology a lancé "DataVault".
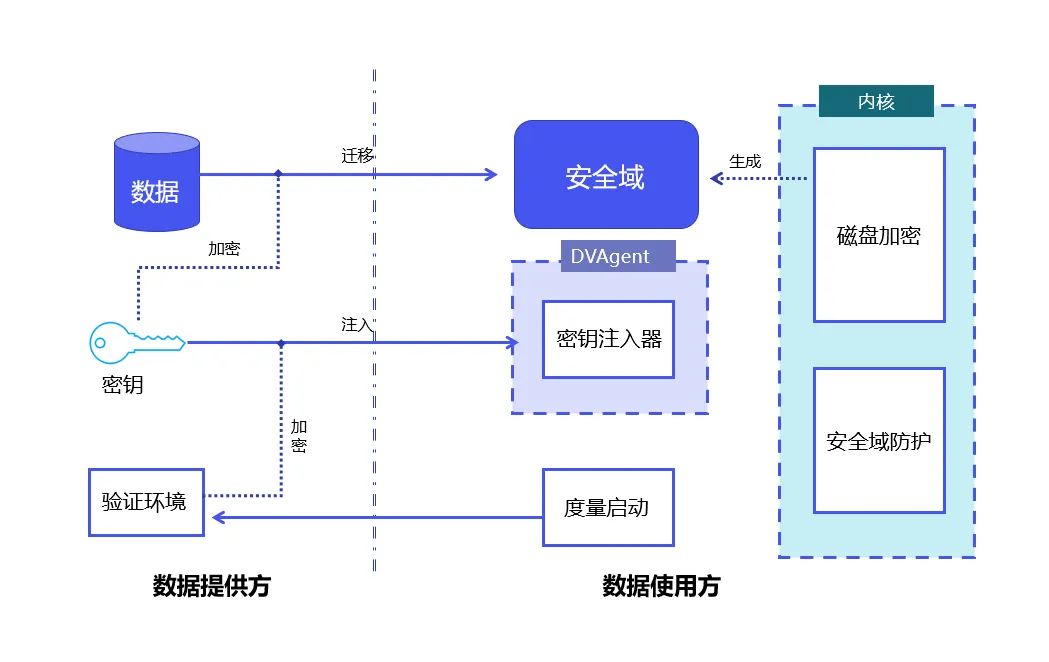
Principe DataVault : Combiner le démarrage métrique Linux et la technologie de chiffrement complet du disque Linux pour obtenir le contrôle et la protection des données dans le domaine de la sécurité.
DataVault utilise le Trusted Platform Module TPM (Trusted Platform Module, dont le cœur est de fournir des fonctions liées à la sécurité basées sur le matériel) comme racine de confiance pour protéger l'intégrité du système ; il utilise le module de sécurité Linux LSM ( Modules de sécurité Linux, Linux Un cadre utilisé dans le noyau pour prendre en charge divers modèles de sécurité informatique, indépendant de toute implémentation de sécurité individuelle) afin que les données du domaine de sécurité ne puissent être utilisées que dans des limites contrôlables.
Sur cette base, DataVault utilise la technologie de cryptage complet du disque fournie par Linux pour placer les données dans un domaine sécurisé. YiZhi Technology a auto-développé un protocole cryptographique complet tel que la distribution de clés et l'autorisation de signature, et a fait beaucoup de choses. d'optimisations techniques, garantissant ainsi la contrôlabilité des données.
DataVault prend en charge une variété de cartes accélératrices dédiées, notamment différents CPU, GPU, FPGA et autres matériels. Il prend également en charge plusieurs frameworks de traitement de données et de formation de modèles, et est compatible binaire.
Plus important encore, sa perte de performances est bien inférieure à celle des autres solutions informatiques de confidentialité. Dans la plupart des applications, par rapport au système natif (c'est-à-dire sans aucune technologie informatique de confidentialité), la perte de performances globale ne dépasse pas. 5%. .
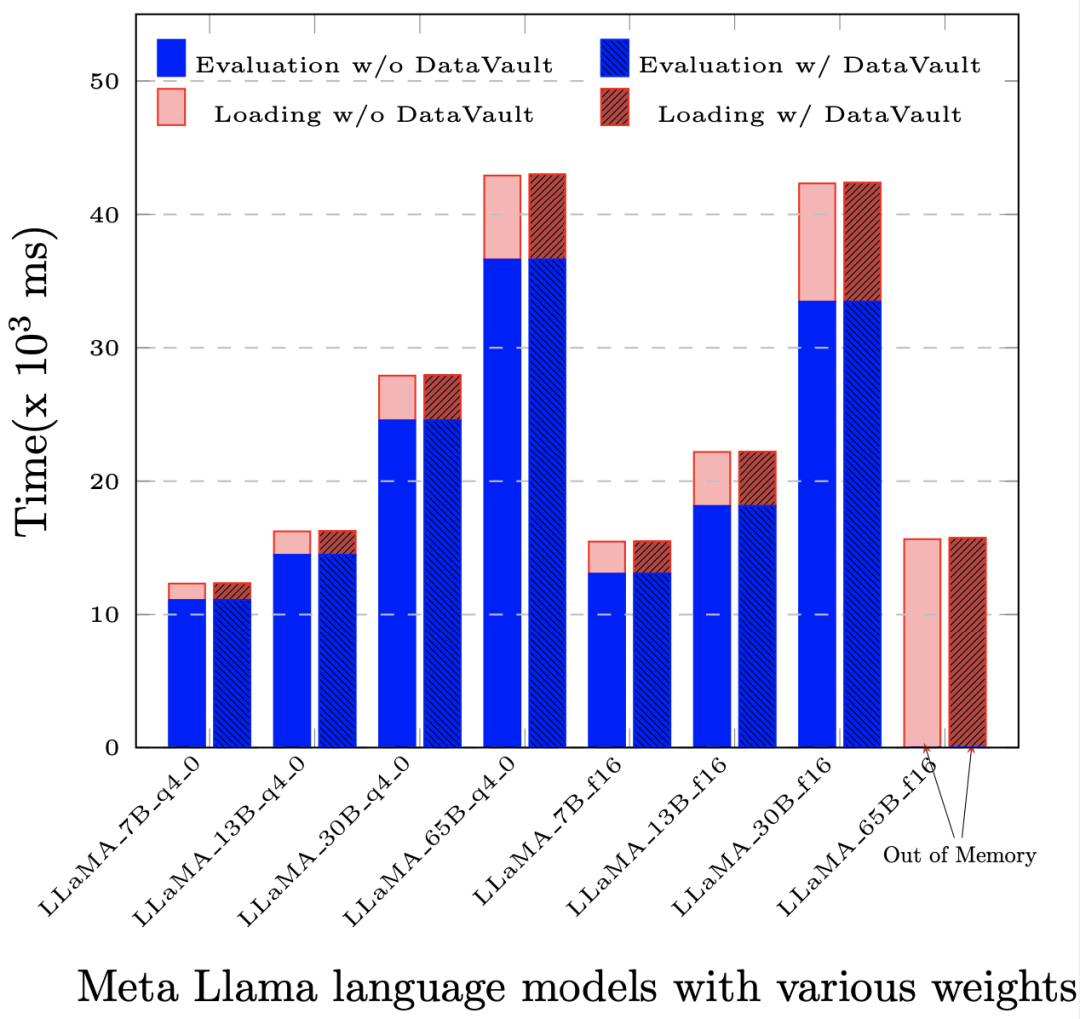
Après le déploiement de DataVault, la perte de performances dans l'évaluation (Evaluation) et l'évaluation rapide (Prompt Evaluation) basée sur LLaMA-65B est inférieure à 1‰.
Affaire DataVault pour protéger la circulation des données et les actifs des modèles
Désormais, YiZhi Technology a conclu une coopération avec le National Supercomputing Center pour déployer une plate-forme de calcul haute performance préservant la confidentialité pour les applications d'IA sur la plate-forme de supercalcul. Sur la base de DataVault, les utilisateurs de puissance informatique peuvent définir des domaines de sécurité sur la plate-forme informatique pour garantir que l'ensemble du processus de transfert de données des nœuds de stockage aux nœuds informatiques ne peut se déplacer qu'entre les domaines de sécurité et ne quitte pas la plage définie.
En plus de garantir que les données sont contrôlables pendant la formation du modèle, sur la base de la solution DataVault, le grand modèle formé lui-même, en tant qu'actif de données, peut également être protégé et échangé en toute sécurité.
Actuellement, les entreprises qui souhaitent déployer de grands modèles localement, telles que les institutions financières, médicales et autres institutions de données hautement sensibles, souffrent du manque d'infrastructure pour exécuter de grands modèles localement, y compris du matériel coûteux et hautes performances pour formation de grands modèles, ainsi que le déploiement de modèles à grande échelle. Expérience ultérieure d'exploitation et de maintenance du modèle. Les entreprises qui construisent de grands modèles industriels craignent que si les modèles sont livrés directement aux clients, les données industrielles et l'expertise accumulées derrière le modèle lui-même et les paramètres du modèle puissent être revendues.
Dans le cadre d'une exploration de la mise en œuvre de grands modèles dans les industries verticales, YiZhi Technology coopère également avec l'Institut de recherche sur l'économie numérique de la région de la Grande Baie Guangdong-Hong Kong-Macao (IDEA Research Institute). modèle avec fonctions de protection de sécurité modèle Machine tout-en-un. Cette machine tout-en-un dispose de plusieurs grands modèles intégrés pour les industries verticales et est équipée des ressources informatiques de base nécessaires à la formation et à la promotion de grands modèles, qui peuvent répondre aux besoins des clients dès le départ, parmi lesquels le contrôlable de YiZhi. Le composant informatique DataVault peut garantir que ces modèles intégrés uniquement lorsqu'ils sont utilisés avec autorisation, le modèle et toutes les données intermédiaires ne peuvent pas être volés par des environnements externes.
En tant que nouveau paradigme informatique de confidentialité, YiZhi Technology espère que l'informatique contrôlable pourra apporter des changements à la grande industrie du modélisme et à la circulation des éléments de données.
「DataVault n'est qu'une solution de mise en œuvre légère. À mesure que la technologie et les besoins changent, nous continuerons à mettre à jour et à faire davantage de tentatives et de contributions sur le marché de la circulation des éléments de données. Nous invitons également davantage de partenaires industriels à nous rejoindre. communauté informatique ensemble », a déclaré Tang Zaiyang.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L’IA change effectivement les mathématiques. Récemment, Tao Zhexuan, qui a prêté une attention particulière à cette question, a transmis le dernier numéro du « Bulletin de l'American Mathematical Society » (Bulletin de l'American Mathematical Society). En se concentrant sur le thème « Les machines changeront-elles les mathématiques ? », de nombreux mathématiciens ont exprimé leurs opinions. L'ensemble du processus a été plein d'étincelles, intense et passionnant. L'auteur dispose d'une équipe solide, comprenant Akshay Venkatesh, lauréat de la médaille Fields, le mathématicien chinois Zheng Lejun, l'informaticien de l'Université de New York Ernest Davis et de nombreux autres universitaires bien connus du secteur. Le monde de l’IA a radicalement changé. Vous savez, bon nombre de ces articles ont été soumis il y a un an.
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
La détection de cibles est un problème relativement mature dans les systèmes de conduite autonome, parmi lesquels la détection des piétons est l'un des premiers algorithmes à être déployés. Des recherches très complètes ont été menées dans la plupart des articles. Cependant, la perception de la distance à l’aide de caméras fisheye pour une vue panoramique est relativement moins étudiée. En raison de la distorsion radiale importante, la représentation standard du cadre de délimitation est difficile à mettre en œuvre dans les caméras fisheye. Pour alléger la description ci-dessus, nous explorons les conceptions étendues de boîtes englobantes, d'ellipses et de polygones généraux dans des représentations polaires/angulaires et définissons une métrique de segmentation d'instance mIOU pour analyser ces représentations. Le modèle fisheyeDetNet proposé avec une forme polygonale surpasse les autres modèles et atteint simultanément 49,5 % de mAP sur l'ensemble de données de la caméra fisheye Valeo pour la conduite autonome.
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
 Une seule carte exécute Llama 70B plus rapidement que deux cartes, Microsoft vient de mettre le FP6 dans l'Open source A100 |
Apr 29, 2024 pm 04:55 PM
Une seule carte exécute Llama 70B plus rapidement que deux cartes, Microsoft vient de mettre le FP6 dans l'Open source A100 |
Apr 29, 2024 pm 04:55 PM
Le FP8 et la précision de quantification inférieure en virgule flottante ne sont plus le « brevet » du H100 ! Lao Huang voulait que tout le monde utilise INT8/INT4, et l'équipe Microsoft DeepSpeed a commencé à exécuter FP6 sur A100 sans le soutien officiel de NVIDIA. Les résultats des tests montrent que la quantification FP6 de la nouvelle méthode TC-FPx sur A100 est proche ou parfois plus rapide que celle de INT4, et a une précision supérieure à celle de cette dernière. En plus de cela, il existe également une prise en charge de bout en bout des grands modèles, qui ont été open source et intégrés dans des cadres d'inférence d'apprentissage profond tels que DeepSpeed. Ce résultat a également un effet immédiat sur l'accélération des grands modèles : dans ce cadre, en utilisant une seule carte pour exécuter Llama, le débit est 2,65 fois supérieur à celui des cartes doubles. un
