
 Périphériques technologiques
IA
Microsoft propose une technologie brevetée pour prédire la posture d'objets articulés pour la capture de la posture corporelle AR/VR
Périphériques technologiques
IA
Microsoft propose une technologie brevetée pour prédire la posture d'objets articulés pour la capture de la posture corporelle AR/VR
Microsoft propose une technologie brevetée pour prédire la posture d'objets articulés pour la capture de la posture corporelle AR/VR

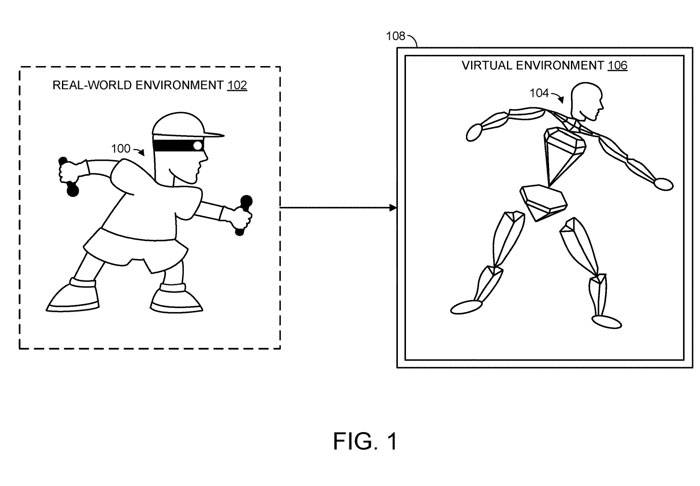
(Nweon, 18 septembre 2023) Afin de représenter avec précision la posture réelle d'un utilisateur humain, des informations relativement détaillées sur la position et l'orientation des parties du corps de l'utilisateur sont généralement nécessaires, mais ces informations ne sont pas toujours disponibles. Par exemple, lors de l'utilisation d'un casque pour offrir une expérience de réalité virtuelle, le système peut uniquement être en mesure d'obtenir des informations spatiales liées à la tête et aux mains de l'utilisateur. Cependant, dans la plupart des cas, cela ne suffit pas pour reproduire fidèlement la posture réelle d'un utilisateur humain
Ainsi, dans la demande de brevet intitulée « Prédiction de pose pour objet articulé », Microsoft a proposé une technologie pour prédire la pose d'objets articulés. En particulier, le modèle d'apprentissage automatique reçoit les informations spatiales de n articulations différentes de l'objet articulé, n articulations étant plus petites que toutes les articulations de l'objet articulé.
Dans le cas d'un utilisateur humain, les n articulations peuvent inclure l'articulation de la tête de l'utilisateur humain et/ou une ou deux articulations du poignet, qui sont associées à des informations spatiales détaillant les paramètres de la tête et/ou des mains de l'utilisateur
Le modèle d'apprentissage automatique a été entraîné pour recevoir des informations spatiales d'entrée pour n+m articulations d'un objet articulé, où m est supérieur ou égal à 1. Par exemple, lors de la formation initiale, un modèle d’apprentissage automatique reçoit des données d’entrée correspondant à presque toutes les articulations d’un objet articulé. Les n+m articulations peuvent inclure chaque articulation de l'objet articulé.
Dans d'autres exemples, il peut y avoir n+m articulations là où il y en a moins que toutes les articulations d'un objet articulé. Pendant le processus de formation, les données entrées dans le modèle d'apprentissage automatique peuvent être progressivement masquées. Vous pouvez remplacer les données d'entrée correspondantes d'un nœud spécifique dans m nœuds par une valeur prédéfinie, ou simplement l'omettre
En d'autres termes, un modèle d'apprentissage automatique est entraîné pour prédire avec précision la pose d'un objet articulé sur la base de moins d'informations sur la position/orientation des différentes parties mobiles de l'objet articulé.
Grâce à cette approche, les modèles d'apprentissage automatique sont capables de prédire avec précision la pose des objets articulés au moment de l'exécution avec seulement des données d'entrée clairsemées. Microsoft souligne que cette technologie peut reproduire avec précision la pose réelle d'objets articulés pour les utilisateurs humains sans nécessiter beaucoup d'informations sur l'orientation de chaque articulation
En d’autres termes, les inventions peuvent offrir des avantages technologiques qui améliorent l’interaction homme-machine en reproduisant plus précisément les gestes réels des utilisateurs humains. Ces avantages techniques incluent l'amélioration de l'immersion des expériences de réalité virtuelle et l'amélioration de la précision des systèmes de reconnaissance gestuelle
De plus, la technologie décrite peut réduire la consommation de ressources informatiques tout en reproduisant avec précision la posture réelle d'un utilisateur humain en réduisant la quantité de données qui doivent être collectées en entrée du processus de prédiction de posture.
L'exemple de méthode 200 montre la figure 2 pour prédire la pose d'un objet articulé
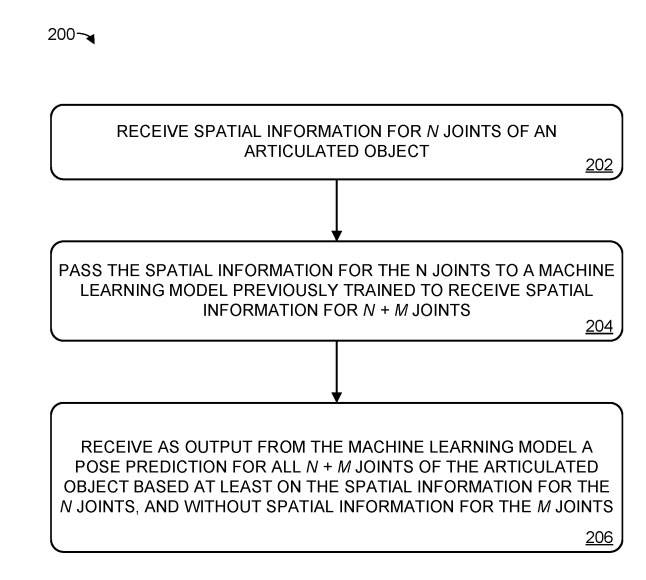
Au point 202, recevez les informations spatiales de n articulations, qui sont utilisées pour les objets articulés. Le système reçoit les informations spatiales de n articulations de l'objet articulé, qui contiennent moins d'articulations que toutes les articulations de l'objet articulé. Représentant l'information spatiale d'une articulation sous la forme de la position et de l'orientation de six degrés de liberté reliant les parties du corps, cela peut être utilisé pour déduire l'état de l'articulation
À titre d'exemple, les n articulations peuvent inclure les articulations de la tête du corps humain, et les informations spatiales des articulations de la tête peuvent décrire les paramètres de la tête humaine en détail. De plus, les n articulations peuvent comprendre une ou plusieurs articulations du poignet du corps humain, et les informations spatiales de la ou des articulations du poignet peuvent décrire en détail les paramètres d'une ou de plusieurs mains du corps humain.
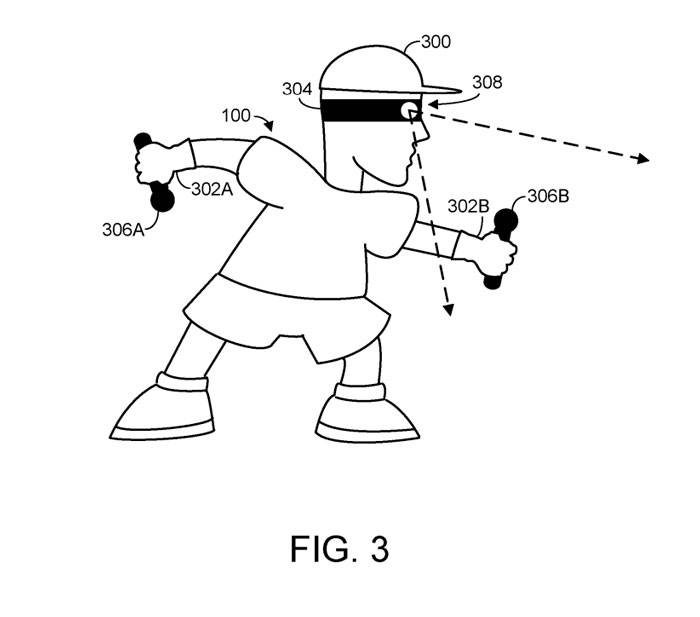
La figure 3 montre les utilisateurs humains. L'utilisateur humain possède une tête 300 et deux mains 302A et 302B. Le système informatique peut recevoir des informations spatiales pour une ou plusieurs articulations d'un utilisateur humain, qui peuvent comprendre des articulations de la tête et/ou du poignet.
Les informations spatiales de n articulations de l'objet articulé peuvent être dérivées des données de positionnement émises par un ou plusieurs capteurs. Des capteurs peuvent être intégrés dans un ou plusieurs dispositifs tenus ou portés par des parties du corps correspondantes d'un utilisateur humain.
Par exemple, les capteurs peuvent inclure une ou plusieurs unités de mesure inertielle intégrées dans un visiocasque et/ou un contrôleur portatif. Comme autre exemple, un capteur peut comprendre une ou plusieurs caméras.
La figure 3 illustre schématiquement les différents types de capteurs où la sortie des capteurs peut inclure ou être utilisée pour dériver des informations spatiales. Plus précisément, un utilisateur humain porte un visiocasque 304 sur sa tête 300.
De plus, l'utilisateur humain tient des capteurs de position 306A et 306B, qui peuvent être configurés pour détecter et signaler le mouvement des mains de l'utilisateur au casque 304 et/ou à un autre système informatique configuré pour recevoir des informations spatiales.
Dans la figure 2, nous revenons à la situation 204. Nous transmettons les informations spatiales de n articulations au modèle d'apprentissage automatique précédemment formé. Ce modèle reçoit en entrée des informations spatiales de n+m articulations, où la valeur de m est supérieure ou égale à 1. En d'autres termes, par rapport au modèle de formation précédent, ce modèle d'apprentissage automatique reçoit moins d'informations sur l'espace articulaire
En 206, recevoir en sortie une prédiction de pose de l'objet articulé issue du modèle d'apprentissage automatique, ladite prédiction étant basée au moins sur les informations spatiales des n articulations et ne contenant pas les informations spatiales de leurs articulations. En d’autres termes, même si les informations spatiales de m articulations ne sont pas fournies, le modèle d’apprentissage automatique peut prédire la posture complète de l’objet commun.
La figure 4 montre un exemple de modèle d'apprentissage automatique 400 pour illustrer ce processus
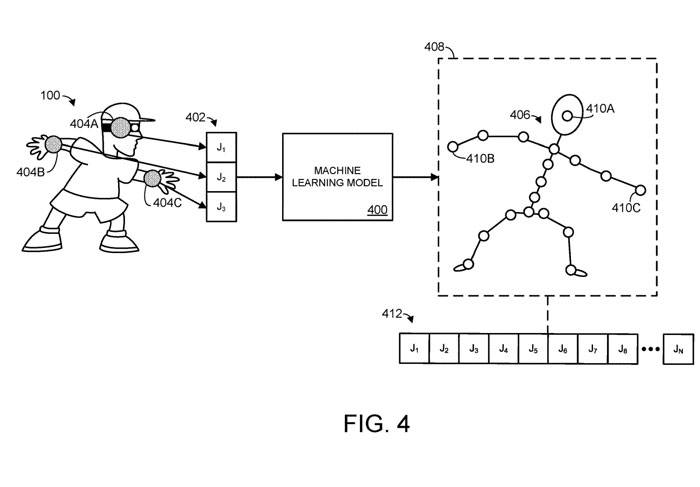
Sur la figure 4, le modèle d'apprentissage automatique reçoit des informations spatiales 402, correspondant à trois articulations différentes J1, J2 et J3. Les informations spatiales pour une articulation peuvent prendre la forme de toute donnée informatique appropriée qui spécifie ou peut être utilisée pour dériver la position et/ou l'orientation de la partie du corps connectée à l'articulation.
Par exemple, les informations spatiales peuvent spécifier directement la position et l'orientation d'une partie du corps, et/ou les informations spatiales peuvent spécifier une ou plusieurs rotations d'une articulation par rapport à un ou plusieurs axes de rotation. Sur la figure 4, les articulations J1, J2, J3 correspondent à l'articulation de la tête 404A d'un utilisateur humain et à deux articulations du poignet 404B/404C, comme le montrent les cercles ombrés superposés sur le corps de l'utilisateur.
Dans cet exemple, les n articulations comprennent trois articulations, correspondant aux articulations de la tête et du poignet du corps humain. Sur la base des informations spatiales d'entrée 402, le modèle d'apprentissage automatique génère une pose prédite 406 de l'objet articulé.
De plus, le modèle d'apprentissage automatique peut générer des informations spatiales prédites correspondant aux articulations représentées par l'articulation virtuelle. Les utilisateurs humains peuvent être représentés par des avatars aux proportions caricaturales ou non humaines. Par exemple, les informations spatiales prédites peuvent correspondre à des articulations représentées par SMPL.
En d'autres termes, les articulations de la représentation virtuelle de la représentation articulée ne doivent pas nécessairement avoir une correspondance 1:1 avec les articulations de l'objet articulé. Par conséquent, les informations spatiales en sortie prédites par le modèle d’apprentissage automatique peuvent concerner des articulations qui ne correspondent pas directement aux n+m articulations de l’objet articulé. Par exemple, une représentation virtuelle peut comporter moins d’articulations vertébrales qu’un objet articulé.
Les modèles d'apprentissage automatique peuvent être formés de n'importe quelle manière appropriée. Dans un mode de réalisation, le modèle d'apprentissage automatique peut avoir été préalablement entraîné à l'aide de données d'entrée d'entraînement avec des étiquettes de vérité terrain pour des objets articulés.
En d'autres termes, le modèle d'apprentissage automatique peut être fourni avec des informations spatiales d'entraînement sur les articulations de l'objet articulé et étiqueté comme étiquettes de vérité terrain spécifiant la pose réelle de l'objet articulé correspondant aux informations spatiales.
Comme mentionné ci-dessus, un modèle d'apprentissage automatique peut être entraîné pour recevoir des informations spatiales de n+m articulations en entrée. Cela implique, lors de la première itération de formation, de fournir au modèle d'apprentissage automatique des données d'entrée de formation pour toutes les n+m articulations. Dans une série ultérieure d'itérations d'entraînement, les données d'entrée d'entraînement de m articulations peuvent être progressivement masquées.
Par exemple, lors de la deuxième itération d'entraînement, la première des m articulations peut être masquée, où les informations spatiales de l'articulation dans l'ensemble de données d'entraînement sont remplacées par une valeur prédéfinie représentant l'articulation masquée, ou simplement omise.
À titre d'exemple. Lors de la troisième itération d'entraînement, la deuxième des m articulations peut être masquée, et ainsi de suite, jusqu'à ce que toutes les m articulations soient masquées et que seules les informations spatiales de n articulations soient fournies au modèle d'apprentissage automatique.
Ce processus est illustré dans les figures 5a à 5d. Plus précisément, sur la figure 5A, le modèle d'apprentissage automatique 400 est pourvu d'un ensemble de données d'entrée de formation. Dans ce mode de réalisation, les données d'entrée d'entraînement comprennent des informations spatiales correspondant à une pluralité de postures différentes de l'objet articulé, y compris la première posture 502A et la seconde posture 502B.
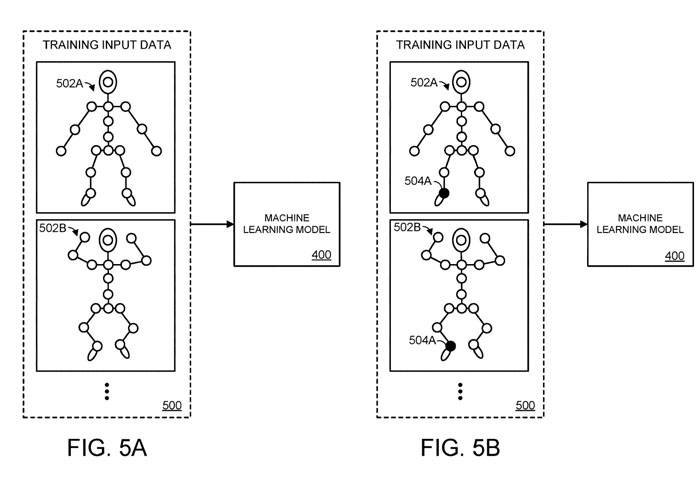
Dans la figure 5A, nous fournissons les informations spatiales de n+m articulations pour l'objet articulé du modèle d'apprentissage automatique. Dans cette représentation simplifiée du corps humain, chaque cercle représentant une articulation est représenté par un motif de remplissage blanc. Cependant, sur la figure 5B, nous avons blindé le 504A comme indiqué avec un motif de remplissage noir pour représenter le cercle du connecteur 504A
En d'autres termes, la figure 5A représente l'itération initiale du processus de formation, où les informations spatiales pour toutes les n+m articulations sont fournies au modèle d'apprentissage automatique. La figure 5B montre la deuxième itération du processus de formation, dans laquelle la première articulation 504A parmi les m articulations est masquée
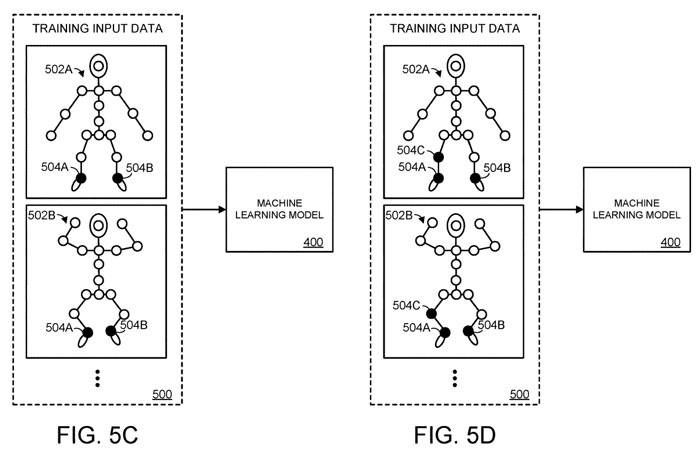
Sur la figure 5C, la deuxième articulation 504B parmi les m articulations représentées par la charnière est obstruée. De même, sur la figure 5D, la troisième articulation parmi les m articulations est obstruée. De multiples itérations d'entraînement peuvent être poursuivies jusqu'à ce que les informations spatiales de chacune des m articulations soient masquées, et seules les informations spatiales de n articulations soient fournies au modèle d'apprentissage automatique.
Dans le scénario ci-dessus, nous décrivons la situation où l'objet articulé est le corps entier du corps humain. Cependant, les objets articulés peuvent aussi prendre d'autres formes
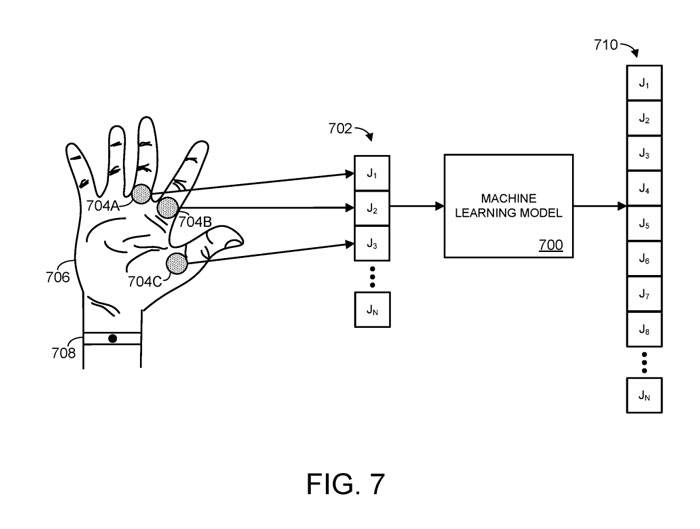
Comme le montre la figure 7, l'objet articulé est la main humaine, et non le corps humain tout entier. Plus précisément, la figure 7 montre un exemple de modèle d'apprentissage automatique 700.
Le modèle d'apprentissage automatique 700 reçoit des informations spatiales pour les articulations J1, J2 et J3, qui correspondent aux trois articulations 704A-C d'un objet articulé, prenant dans ce cas la forme d'une main humaine 706.
Dans ce cas précis, les n articulations comprennent une ou plusieurs articulations des doigts de la main humaine. Les informations spatiales d'une ou plusieurs articulations de doigts détaillent les paramètres d'un ou plusieurs doigts ou segments de doigts de la main humaine. Par exemple, les informations spatiales peuvent préciser la position/orientation des doigts de la main, et/ou la rotation appliquée aux articulations de la main
Toute méthode appropriée peut être utilisée pour collecter des informations sur l'espace articulaire, par exemple via le capteur de position 708. Par exemple, un capteur de position pourrait prendre la forme d’une caméra configurée pour imager la main. Comme autre exemple, un capteur de position pourrait inclure une antenne radiofréquence appropriée configurée pour exposer la surface de la main à un champ électromagnétique et évaluer l'effet du mouvement et de la proximité d'une peau humaine conductrice sur l'impédance du champ électromagnétique au niveau de l'antenne
Sur la base des informations spatiales d'entrée 702, le modèle d'apprentissage automatique produira un ensemble d'informations spatiales prédites 710. Les informations spatiales 710 peuvent être utilisées pour construire la pose prédite de l'objet articulé. Comme mentionné précédemment, ces informations spatiales peuvent représenter la position et l'orientation des parties du corps d'objets articulés
Brevets associés : Brevet Microsoft | Prédiction de pose pour un objet articulé
Microsoft a initialement soumis une demande de brevet intitulée « Prédiction de pose pour objet articulé » en juin 2022, et la demande a été récemment publiée par l'Office américain des brevets et des marques
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Brevet Apple AIGC : des scènes virtuelles AR/VR peuvent être générées via des commandes vocales
Jul 16, 2023 pm 05:49 PM
Brevet Apple AIGC : des scènes virtuelles AR/VR peuvent être générées via des commandes vocales
Jul 16, 2023 pm 05:49 PM
En février de l'année dernière, Meta a présenté une fonction de développement de monde virtuel basée sur le gameplay AIGC : BuilderBot se caractérise par la capacité de générer des éléments correspondants dans la scène virtuelle en reconnaissant les commandes vocales, ce qui peut simplifier la difficulté de génération de scène VR. Dans un récent brevet Apple publié par l'USPTO, un concept similaire a également été souligné. Par exemple, les utilisateurs peuvent commander l'assistant vocal Siri pour ajouter des meubles virtuels à la scène physique, changer la couleur des meubles, etc. Selon Qingting.com, le numéro de brevet est US20230206912A1. Le contenu décrit principalement une série de nouvelles commandes vocales Siri, qui peuvent être utilisées pour contrôler les traitements de texte (saisir du texte, modifier les polices, etc.), les scènes XR, etc. Bien qu'il ne soit pas spécifiquement conçu pour le XR, il est breveté
 Configuration des systèmes Linux pour prendre en charge le développement AR/VR et réalité augmentée
Jul 05, 2023 am 11:17 AM
Configuration des systèmes Linux pour prendre en charge le développement AR/VR et réalité augmentée
Jul 05, 2023 am 11:17 AM
Configuration des systèmes Linux pour prendre en charge le développement AR/VR et réalité augmentée Introduction : Avec le développement de la technologie de réalité augmentée (AR) et de réalité virtuelle (VR), de plus en plus de développeurs commencent à s'intéresser à ces domaines émergents. Pour le développement AR/VR et réalité augmentée, il est très important de configurer correctement votre système Linux. Cet article vous expliquera comment configurer un système Linux pour prendre en charge le développement AR/VR et de réalité augmentée, et fournira des exemples de code correspondants. Étape 1 : installer le logiciel nécessaire Avant de commencer, assurez-vous que votre système Linux dispose
 Le fournisseur de solutions AR/VR Vection acquiert le fournisseur de solutions de vente au détail VR Invrsion
Jun 09, 2023 pm 10:19 PM
Le fournisseur de solutions AR/VR Vection acquiert le fournisseur de solutions de vente au détail VR Invrsion
Jun 09, 2023 pm 10:19 PM
Selon les informations du 8 juin, la société de solutions AR/VR Vection a annoncé l'acquisition du fournisseur de solutions de vente au détail intelligentes VR Invrsion, dans le but d'accélérer les solutions XR et les opportunités de marché dans les domaines de la mode et de la vente au détail. Il est rapporté qu'une fois l'acquisition finalisée, la technologie d'Invrsion sera intégrée à la suite INTEGRATEDXR de Vection pour mieux répondre aux besoins des clients. Selon Qingting.com, Invrsion a été fondée en 2015. Elle se concentrait auparavant sur les activités de numérisation de produits 3D, fournissant aux clients des solutions de simulation interactive basées sur 6DoFVR. Les scénarios d'application incluent les salles d'exposition virtuelles, le commerce électronique 3D, l'industrie, l'immobilier, etc. Du côté des clients, l'entreprise a servi Walgreens, Ferrero, Nestlé, Coca-Cola, D
 Un brevet Microsoft propose une solution de surveillance de la source lumineuse pour les interférences d'étalonnage des projections lumineuses AR/VR
Aug 25, 2023 pm 01:01 PM
Un brevet Microsoft propose une solution de surveillance de la source lumineuse pour les interférences d'étalonnage des projections lumineuses AR/VR
Aug 25, 2023 pm 01:01 PM
(Nwe le 24 août 2023) L'équipement XR comprend généralement un projecteur gauche couplé au trajet du faisceau gauche et un projecteur droit couplé au trajet du faisceau droit. Le projecteur gauche est configuré pour générer une image gauche, puis propager l'image gauche à travers le trajet du faisceau gauche jusqu'à l'œil gauche de l'utilisateur. Le projecteur approprié est configuré pour générer l'image correcte, qui traverse ensuite le chemin de faisceau correct jusqu'à l'œil droit de l'utilisateur. La structure de cet appareil XR peut changer en raison d'une utilisation régulière, de changements de température et/ou de chocs. Lorsque la structure du périphérique R change, l'image peut perdre son axe visuel et être mal alignée. Ce problème peut devenir grave dans les appareils en forme de lunettes. Avoir un équipement XR configuré pour projeter une image d'étalonnage et utiliser l'image d'étalonnage pour déterminer si l'affichage est correct
 Creusez des centaines de brevets AR/VR et explorez tous les aspects d'Apple XR
Jun 03, 2023 pm 11:40 PM
Creusez des centaines de brevets AR/VR et explorez tous les aspects d'Apple XR
Jun 03, 2023 pm 11:40 PM
Récemment, tout le monde a également lu beaucoup de nouvelles sur Apple XR. Au lieu de regarder diverses révélations, il est préférable de commencer par les brevets et de voir de quelles différentes manières le casque Apple XR peut jouer. Par conséquent, nous avons sélectionné parmi les centaines de brevets AR/VR d’Apple ces dernières années et compilé ceux qui peuvent directement déterminer et affecter l’expérience du produit XR. Bien entendu, ces brevets ne seront pas concentrés sur un seul produit, et nous ne pouvons pas vous dire exactement à quoi ressemble Apple XR, mais nous pouvons quand même en avoir un aperçu grâce aux brevets. Lors du tri des brevets AR/VR d'Apple ces dernières années, nous avons principalement trouvé les caractéristiques suivantes : 1) Certains brevets AR/VR proviennent de sociétés précédemment acquises, telles que PrimeSense, Metaio, NextVR, SMI, Spaces, etc. 2) Structurés ; lumière
 L'avenir de l'industrie du design à l'ère de l'intelligence artificielle
Apr 10, 2023 am 09:51 AM
L'avenir de l'industrie du design à l'ère de l'intelligence artificielle
Apr 10, 2023 am 09:51 AM
L’intelligence artificielle (IA) prendra-t-elle le relais dans le domaine du design ? Va-t-elle remplacer les designers à l’avenir ? Lorsque l’on évoque l’intelligence artificielle, elle est immédiatement présentée comme un substitut aux humains. S’il ne fait aucun doute que l’intelligence artificielle va changer le statu quo du travail de conception, l’idée selon laquelle cette technologie intelligente remplacera les humains n’est pas tout à fait exacte. À mesure que la technologie se développe et que l’économie évolue, il est naturel que les processus commerciaux changent, et le processus de conception en est également affecté. Alors que nous apprenons comment l'intelligence artificielle va profondément changer le processus de conception, (les concepteurs) ne devraient pas considérer l'intelligence artificielle comme une menace, mais devraient se concentrer sur les opportunités qu'elle apporte au domaine de la conception, son impact sur les pratiques de conception et l'impact des principes de conception. , et comment le travail des designers va changer. Le rôle de l’IA dans deux contextes de conception Comprendre le rôle de l’IA dans la conception
 Les États-Unis ouvrent la bande de fréquences 6 GHz pour l'AR/VR, et Meta, Apple et Google ont exprimé des mesures importantes
Oct 20, 2023 am 11:25 AM
Les États-Unis ouvrent la bande de fréquences 6 GHz pour l'AR/VR, et Meta, Apple et Google ont exprimé des mesures importantes
Oct 20, 2023 am 11:25 AM
(Nweon, 20 octobre 2023) Selon CNBC, la Federal Communications Commission (FCC) des États-Unis a récemment accepté d'ouvrir la bande de fréquences de 6 GHz à « une nouvelle classe d'appareils à très faible consommation », tels que les appareils portables, et cette décision Contribuer à ouvrir la voie à de nouvelles applications pour les appareils portables de réalité augmentée et de réalité virtuelle. La FCC a déclaré dans son communiqué qu'elle espère que l'ouverture de cette bande « stimulera le développement d'un écosystème d'applications de pointe, notamment la technologie portable, la réalité augmentée et la réalité virtuelle, qui aideront les entreprises, augmenteront les opportunités d'apprentissage et feront progresser les opportunités en matière de soins de santé. ." , et apporter de nouvelles expériences de divertissement. " Meta a été le premier à exprimer son enthousiasme face à cette nouvelle. Kevin Martin de la société a déclaré dans un communiqué
 Apple est-il épuisé ? L'ancien responsable marketing n'est pas optimiste quant aux casques Apple AR/VR.
May 26, 2023 pm 11:39 PM
Apple est-il épuisé ? L'ancien responsable marketing n'est pas optimiste quant aux casques Apple AR/VR.
May 26, 2023 pm 11:39 PM
La maison des fans d'Apple, recherche professionnelle sur la technologie des téléphones mobiles Apple depuis dix ans ! Des experts Apple autour de vous ~ Apple lancera prochainement un casque AR/VR baptisé « Reality Pro ». Cette nouvelle n'est plus un secret, mais à mesure que la date de sortie approche, de plus en plus de personnes semblent s'intéresser à cette réalité mixte. les produits ne sont pas prometteurs. Cela inclut les initiés d'Apple, et même le PDG d'Apple, Tim Cook, a une attitude moins que positive à l'égard du projet. Bien que Palmer Luckey, le fondateur de la société de casques VR Oculus, ait fait l'éloge du produit après avoir testé le casque Apple, il ne peut toujours pas éviter d'autres voix sceptiques. Récemment, l'ancien responsable marketing d'Apple, Michael Guttenberg (Mic
