
 Périphériques technologiques
IA
Salesforce collabore avec des chercheurs du MIT pour créer des didacticiels de révision GPT-4 open source afin de fournir plus d'informations avec moins de mots
Périphériques technologiques
IA
Salesforce collabore avec des chercheurs du MIT pour créer des didacticiels de révision GPT-4 open source afin de fournir plus d'informations avec moins de mots
Salesforce collabore avec des chercheurs du MIT pour créer des didacticiels de révision GPT-4 open source afin de fournir plus d'informations avec moins de mots

La technologie de synthèse automatique a fait des progrès significatifs ces dernières années, principalement en raison de changements de paradigme. Dans le passé, cette technologie reposait principalement sur un réglage fin supervisé sur des ensembles de données annotés, mais elle utilise désormais des modèles de langage étendus (LLM) pour les invites à zéro, comme GPT-4. Grâce à des paramètres d'invite minutieux, un contrôle précis de la longueur, du thème, du style et d'autres fonctionnalités du résumé peut être obtenu sans formation supplémentaire. Mais un aspect est souvent négligé : la densité des informations du résumé. Théoriquement, en tant que compression d'un autre texte, un résumé devrait être plus dense, c'est-à-dire contenir plus d'informations, que le fichier source. Compte tenu de la latence élevée du décodage LLM, il est important de couvrir davantage d’informations avec moins de mots, notamment pour les applications en temps réel.
Cependant, la densité de l'information est une question ouverte : si le résumé ne contient pas assez de détails, cela équivaut à aucune information ; s'il contient trop d'informations sans augmenter la longueur totale, il deviendra difficile à comprendre. Pour transmettre plus d’informations dans le cadre d’un budget de jetons fixe, il est nécessaire de combiner abstraction, compression et fusion.
Dans des recherches récentes, des chercheurs de Salesforce, du MIT et d'autres ont tenté de déterminer les limites de l'augmentation de la densité en sollicitant les préférences humaines pour un ensemble de résumés générés par GPT-4. Cette méthode fournit de nombreuses inspirations pour améliorer la « capacité d'expression » des grands modèles de langage tels que GPT-4
 Lien papier : https://arxiv.org/pdf/2309.04269.pdf
Lien papier : https://arxiv.org/pdf/2309.04269.pdf
Adresse de l'ensemble de données : https : / /huggingface.co/datasets/griffin/chain_of_density
Plus précisément, les chercheurs ont généré un résumé initial contenant peu d'entités en utilisant le nombre moyen d'entités par jeton comme indicateur de densité. Ensuite, ils identifient et fusionnent de manière itérative les 1 à 3 entités manquantes dans le résumé précédent sans augmenter la longueur totale (5 fois la longueur totale). Chaque résumé a un ratio entité/jeton plus élevé que le résumé précédent. Sur la base des données de préférences humaines, les auteurs ont finalement déterminé que les humains préfèrent les résumés presque aussi denses que les résumés écrits par des humains, et plus denses que les résumés générés par les indices GPT-4 ordinaires.
La contribution globale de l'étude peut être résumée comme suit :
- Nous devons développer une méthode itérative basée sur des invites (CoD) pour augmenter la densité d'entités des résumés
- Évaluation manuelle et automatisée de la densité des résumés dans les articles de CNN/Daily Mail pour mieux comprendre le compromis entre le caractère informatif (privilégiant plus d'entités) et la clarté (privilégiant moins d'entités)
- Résumés GPT-4 open source, annotations et un ensemble de 5000 résumés CoD non annotés, utilisés pour l'évaluation ou le raffinement.
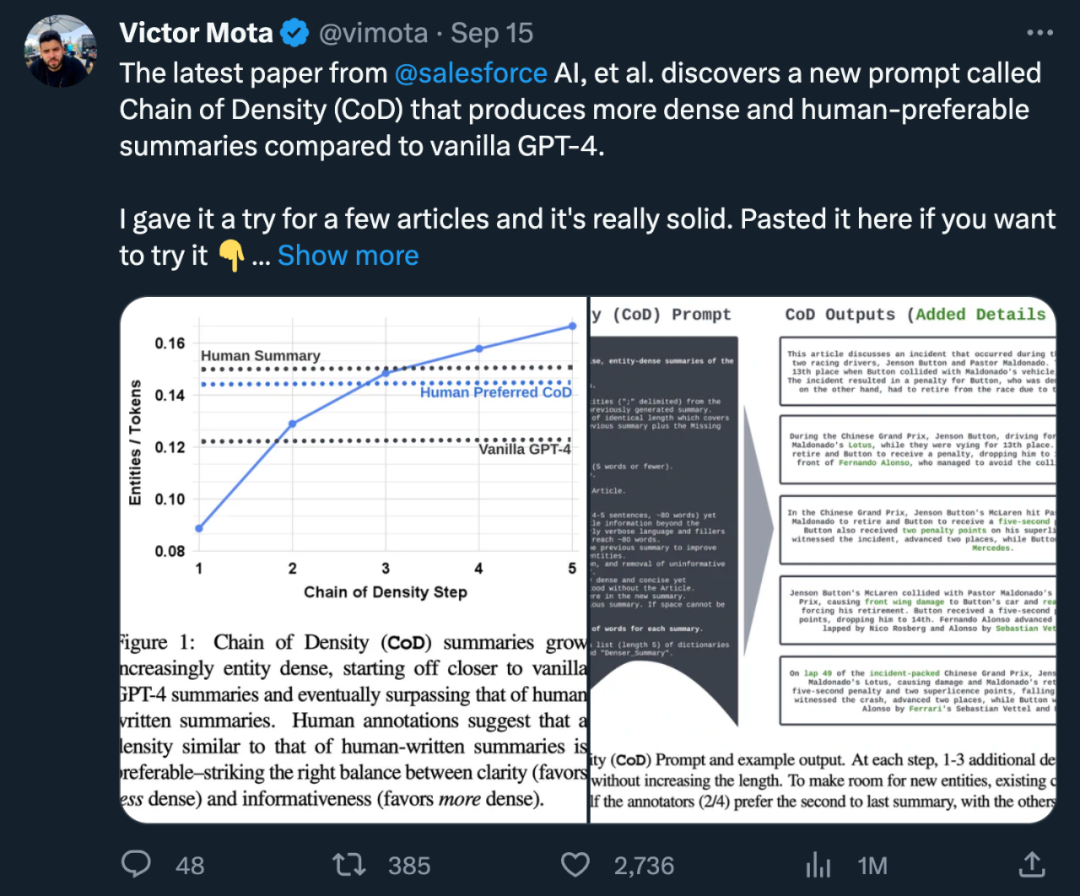
L'auteur a formulé une invite de chaîne unique de densité (CoD), qui génère un premier résumé et fait augmenter continuellement sa densité d'entité. Plus précisément, au sein d'un nombre fixe d'interactions, un ensemble unique d'entités saillantes dans le texte source est identifié et fusionné dans le résumé précédent sans augmenter la longueur.
Des exemples d'invites et de résultats sont présentés dans la figure 2. L'auteur ne précise pas explicitement les types d'entités, mais définit les entités manquantes comme :
- Pertinentes pour l'histoire principale :
- Spécifiques : concises (5 mots ou moins) ; dans le résumé précédent ;
- Fidèle : présent dans l'article ;
- Partout : situé n'importe où dans l'article ;
- L'auteur a sélectionné au hasard 100 articles de l'ensemble de tests de résumé CNN/DailyMail pour générer des résumés CoD pour eux. Pour faciliter la référence, ils ont comparé les statistiques récapitulatives de CoD aux résumés de référence rédigés par des humains et aux résumés générés par GPT-4 sous l'invite normale : "Écrivez un très court résumé de l'article. Pas plus de 70 mots." Situation statistique
 Dans l'étude, l'auteur a résumé sous deux aspects : les statistiques directes et les statistiques indirectes. Les statistiques directes (jetons, entités, densité des entités) sont directement contrôlées par CoD, tandis que les statistiques indirectes sont un sous-produit attendu de la densification.
Dans l'étude, l'auteur a résumé sous deux aspects : les statistiques directes et les statistiques indirectes. Les statistiques directes (jetons, entités, densité des entités) sont directement contrôlées par CoD, tandis que les statistiques indirectes sont un sous-produit attendu de la densification.
Statistiques directes. Comme le montre le tableau 1, la deuxième étape a réduit la longueur de 5 jetons en moyenne (de 72 à 67) en raison de la suppression des mots inutiles du résumé initialement long. La densité d'entité commence à 0,089, initialement inférieure à celle du GPT-4 humain et Vanilla (0,151 et 0,122), et finit par atteindre 0,167 après 5 étapes de densification. 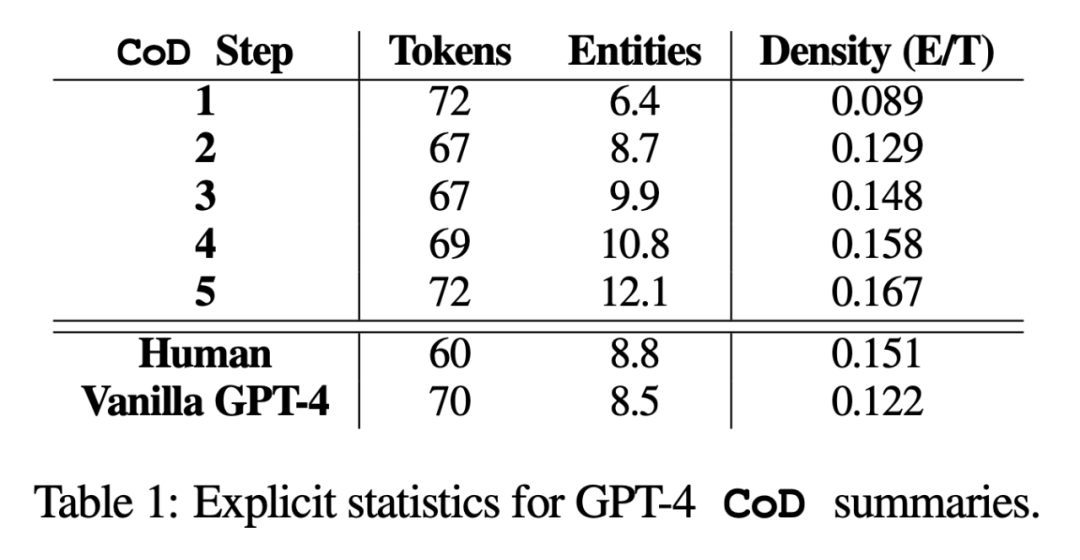 Statistiques indirectes. Le niveau d'abstraction devrait augmenter à chaque étape de CoD, car le résumé est réécrit à plusieurs reprises pour faire de la place à chaque entité supplémentaire. Les auteurs mesurent l'abstraction en utilisant la densité d'extraction : la longueur carrée moyenne des fragments extraits (Grusky et al., 2018). De même, la fusion de concepts devrait augmenter de façon monotone à mesure que des entités sont ajoutées à un résumé de longueur fixe. Les auteurs ont exprimé le degré d'intégration par le nombre moyen de phrases sources alignées avec chaque phrase récapitulative. Pour l'alignement, les auteurs utilisent la méthode du gain relatif ROUGE (Zhou et al., 2018), qui aligne la phrase source avec la phrase cible jusqu'à ce que le gain relatif ROUGE des phrases supplémentaires ne soit plus positif. Ils s’attendaient également à des changements dans la distribution du contenu ou dans la position dans l’article d’où provient le contenu résumé.
Statistiques indirectes. Le niveau d'abstraction devrait augmenter à chaque étape de CoD, car le résumé est réécrit à plusieurs reprises pour faire de la place à chaque entité supplémentaire. Les auteurs mesurent l'abstraction en utilisant la densité d'extraction : la longueur carrée moyenne des fragments extraits (Grusky et al., 2018). De même, la fusion de concepts devrait augmenter de façon monotone à mesure que des entités sont ajoutées à un résumé de longueur fixe. Les auteurs ont exprimé le degré d'intégration par le nombre moyen de phrases sources alignées avec chaque phrase récapitulative. Pour l'alignement, les auteurs utilisent la méthode du gain relatif ROUGE (Zhou et al., 2018), qui aligne la phrase source avec la phrase cible jusqu'à ce que le gain relatif ROUGE des phrases supplémentaires ne soit plus positif. Ils s’attendaient également à des changements dans la distribution du contenu ou dans la position dans l’article d’où provient le contenu résumé.
Plus précisément, les auteurs s'attendent à ce que les résumés CoD montrent dans un premier temps un fort « biais de plomb » (Lead Bias), mais commencent ensuite progressivement à introduire des entités à partir du milieu et de la fin de l'article. Pour mesurer cela, ils ont utilisé l’alignement en fusion pour réécrire le contenu en chinois, sans que la phrase originale n’apparaisse, et ont mesuré le classement moyen des phrases parmi toutes les phrases sources alignées.
La figure 3 confirme ces hypothèses : à mesure que le nombre d'étapes de réécriture augmente, l'abstraction augmente (l'image de gauche montre une densité d'extraction plus faible), le taux de fusion augmente (l'image du milieu le montre) et le résumé commence à inclure le contenu du milieu. et fin de l'article (affiché à droite). Fait intéressant, tous les résumés CoD sont plus abstraits que les résumés écrits par des humains et les résumés de base
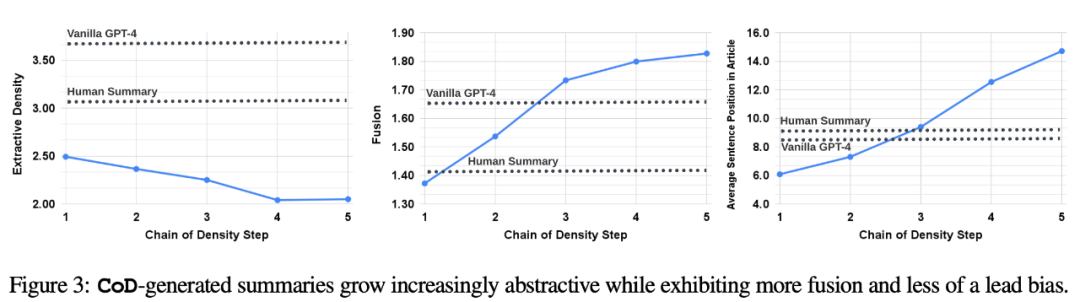
Lors de la réécriture du contenu, il doit être réécrit en chinois, la phrase originale n'a pas besoin d'apparaître
Pour mieux To Pour comprendre le compromis des résumés CoD, les auteurs ont mené une étude humaine basée sur les préférences et effectué une évaluation basée sur les notations à l'aide de GPT-4.
Préférence humaine. Plus précisément, pour les mêmes 100 articles (5 étapes * 100 = 500 résumés au total), l'auteur a montré au hasard les résumés et articles CoD « recréés » aux quatre premiers auteurs de l'article. Chaque annotateur a donné son résumé préféré sur la base de la définition de Stiennon et al. (2020) d'un « bon résumé ». Le tableau 2 rapporte les votes de première place de chaque annotateur dans l'étape CoD, ainsi que le résumé de chaque annotateur. Dans l'ensemble, 61 % des résumés de première place (23,0+22,5+15,5) impliquaient ≥3 étapes de densification. Le nombre médian d’étapes CoD préférées se situe au milieu (3), avec un nombre d’étapes attendu de 3,06.
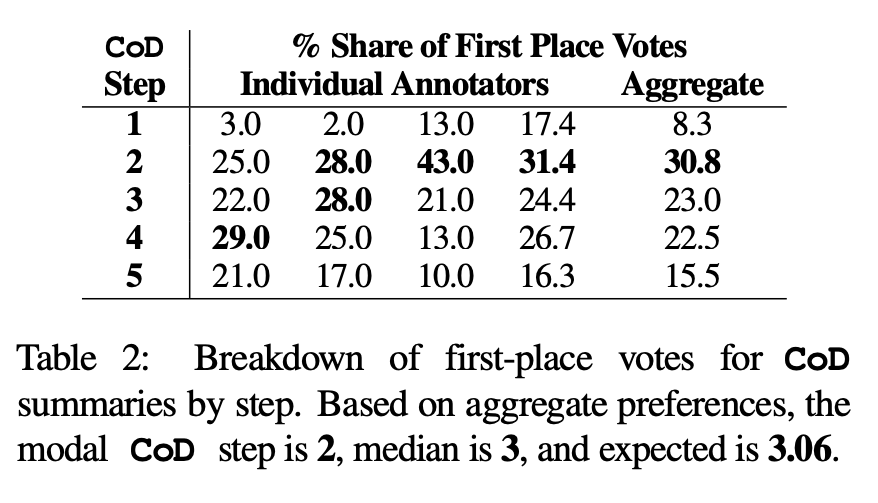
Sur la base de la densité moyenne de la troisième étape, la densité d'entités préférée de tous les candidats CoD est d'environ 0,15. Comme le montre le tableau 1, cette densité est cohérente avec les résumés rédigés par des humains (0,151), mais nettement supérieure à celle des résumés rédigés avec l'invite GPT-4 simple (0,122)
métrique automatique. En complément de l'évaluation humaine (ci-dessous), les auteurs ont utilisé GPT-4 pour noter les résumés CoD (1 à 5 points) selon 5 dimensions : caractère informatif, qualité, cohérence, attribuable et totalité. Comme le montre le tableau 3, la densité est en corrélation avec le caractère informatif, mais jusqu'à une limite, le score culminant à l'étape 4 (4,74).
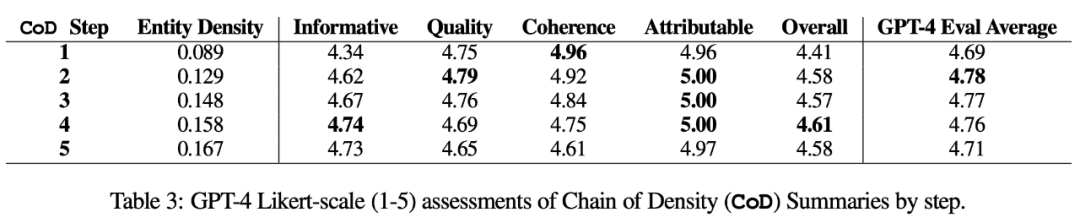
Parmi les scores moyens de chaque dimension, les première et dernière étapes de CoD ont les scores les plus bas, tandis que les trois étapes du milieu ont des scores proches (4,78, 4,77 et 4,76 respectivement).
Analyse qualitative. Il existe un compromis évident entre la cohérence/lisibilité abstraite et le caractère informatif. Deux étapes CoD sont illustrées dans la figure 4 : le résumé d'une étape est amélioré par plus de détails et le résumé de l'autre étape est compromis. En moyenne, les résumés CoD intermédiaires parviennent le mieux à atteindre cet équilibre, mais ce compromis doit encore être défini et quantifié avec précision dans les travaux futurs.
 Pour plus de détails sur le document, veuillez vous référer au document original.
Pour plus de détails sur le document, veuillez vous référer au document original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Du RLHF au DPO en passant par TDPO, les algorithmes d'alignement des grands modèles sont déjà « au niveau des jetons »
Jun 24, 2024 pm 03:04 PM
Du RLHF au DPO en passant par TDPO, les algorithmes d'alignement des grands modèles sont déjà « au niveau des jetons »
Jun 24, 2024 pm 03:04 PM
La colonne AIxiv est une colonne où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com Dans le processus de développement de l'intelligence artificielle, le contrôle et le guidage des grands modèles de langage (LLM) ont toujours été l'un des principaux défis, visant à garantir que ces modèles sont à la fois puissant et sûr au service de la société humaine. Les premiers efforts se sont concentrés sur les méthodes d’apprentissage par renforcement par feedback humain (RL
 L'auteur de ControlNet a encore un succès ! L'ensemble du processus de génération d'une peinture à partir d'une image, gagnant 1,4k étoiles en deux jours
Jul 17, 2024 am 01:56 AM
L'auteur de ControlNet a encore un succès ! L'ensemble du processus de génération d'une peinture à partir d'une image, gagnant 1,4k étoiles en deux jours
Jul 17, 2024 am 01:56 AM
Il s'agit également d'une vidéo Tusheng, mais PaintsUndo a emprunté une voie différente. L'auteur de ControlNet, LvminZhang, a recommencé à vivre ! Cette fois, je vise le domaine de la peinture. Le nouveau projet PaintsUndo a reçu 1,4kstar (toujours en hausse folle) peu de temps après son lancement. Adresse du projet : https://github.com/lllyasviel/Paints-UNDO Grâce à ce projet, l'utilisateur saisit une image statique et PaintsUndo peut automatiquement vous aider à générer une vidéo de l'ensemble du processus de peinture, du brouillon de ligne au suivi du produit fini. . Pendant le processus de dessin, les changements de lignes sont étonnants. Le résultat vidéo final est très similaire à l’image originale : jetons un coup d’œil à un dessin complet.
 En tête de liste des ingénieurs logiciels d'IA open source, la solution sans agent de l'UIUC résout facilement les problèmes de programmation réels du banc SWE.
Jul 17, 2024 pm 10:02 PM
En tête de liste des ingénieurs logiciels d'IA open source, la solution sans agent de l'UIUC résout facilement les problèmes de programmation réels du banc SWE.
Jul 17, 2024 pm 10:02 PM
La colonne AIxiv est une colonne où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com Les auteurs de cet article font tous partie de l'équipe de l'enseignant Zhang Lingming de l'Université de l'Illinois à Urbana-Champaign (UIUC), notamment : Steven Code repair ; doctorant en quatrième année, chercheur
 Travail posthume de l'équipe OpenAI Super Alignment : deux grands modèles jouent à un jeu et le résultat devient plus compréhensible
Jul 19, 2024 am 01:29 AM
Travail posthume de l'équipe OpenAI Super Alignment : deux grands modèles jouent à un jeu et le résultat devient plus compréhensible
Jul 19, 2024 am 01:29 AM
Si la réponse donnée par le modèle d’IA est incompréhensible du tout, oseriez-vous l’utiliser ? À mesure que les systèmes d’apprentissage automatique sont utilisés dans des domaines de plus en plus importants, il devient de plus en plus important de démontrer pourquoi nous pouvons faire confiance à leurs résultats, et quand ne pas leur faire confiance. Une façon possible de gagner confiance dans le résultat d'un système complexe est d'exiger que le système produise une interprétation de son résultat qui soit lisible par un humain ou un autre système de confiance, c'est-à-dire entièrement compréhensible au point que toute erreur possible puisse être trouvé. Par exemple, pour renforcer la confiance dans le système judiciaire, nous exigeons que les tribunaux fournissent des avis écrits clairs et lisibles qui expliquent et soutiennent leurs décisions. Pour les grands modèles de langage, nous pouvons également adopter une approche similaire. Cependant, lorsque vous adoptez cette approche, assurez-vous que le modèle de langage génère
 Génération vidéo illimitée, planification et prise de décision, diffusion, intégration forcée de la prédiction du prochain jeton et diffusion de la séquence complète
Jul 23, 2024 pm 02:05 PM
Génération vidéo illimitée, planification et prise de décision, diffusion, intégration forcée de la prédiction du prochain jeton et diffusion de la séquence complète
Jul 23, 2024 pm 02:05 PM
Actuellement, les modèles linguistiques autorégressifs à grande échelle utilisant le prochain paradigme de prédiction de jetons sont devenus populaires partout dans le monde. Dans le même temps, un grand nombre d'images et de vidéos synthétiques sur Internet nous ont déjà montré la puissance des modèles de diffusion. Récemment, une équipe de recherche de MITCSAIL (dont Chen Boyuan, doctorant au MIT) a intégré avec succès les puissantes capacités du modèle de diffusion en séquence complète et du prochain modèle de jeton, et a proposé un paradigme de formation et d'échantillonnage : le forçage de diffusion (DF ). Titre de l'article : DiffusionForcing:Next-tokenPredictionMeetsFull-SequenceDiffusion Adresse de l'article : https://
 Les articles arXiv peuvent être publiés sous forme de 'barrage', la plateforme de discussion alphaXiv de Stanford est en ligne, LeCun l'aime
Aug 01, 2024 pm 05:18 PM
Les articles arXiv peuvent être publiés sous forme de 'barrage', la plateforme de discussion alphaXiv de Stanford est en ligne, LeCun l'aime
Aug 01, 2024 pm 05:18 PM
acclamations! Qu’est-ce que ça fait lorsqu’une discussion sur papier se résume à des mots ? Récemment, des étudiants de l'Université de Stanford ont créé alphaXiv, un forum de discussion ouvert pour les articles arXiv qui permet de publier des questions et des commentaires directement sur n'importe quel article arXiv. Lien du site Web : https://alphaxiv.org/ En fait, il n'est pas nécessaire de visiter spécifiquement ce site Web. Il suffit de remplacer arXiv dans n'importe quelle URL par alphaXiv pour ouvrir directement l'article correspondant sur le forum alphaXiv : vous pouvez localiser avec précision les paragraphes dans. l'article, Phrase : dans la zone de discussion sur la droite, les utilisateurs peuvent poser des questions à l'auteur sur les idées et les détails de l'article. Par exemple, ils peuvent également commenter le contenu de l'article, tels que : "Donné à".
 Une avancée significative dans l'hypothèse de Riemann ! Tao Zhexuan recommande fortement les nouveaux articles du MIT et d'Oxford, et le lauréat de la médaille Fields, âgé de 37 ans, a participé
Aug 05, 2024 pm 03:32 PM
Une avancée significative dans l'hypothèse de Riemann ! Tao Zhexuan recommande fortement les nouveaux articles du MIT et d'Oxford, et le lauréat de la médaille Fields, âgé de 37 ans, a participé
Aug 05, 2024 pm 03:32 PM
Récemment, l’hypothèse de Riemann, connue comme l’un des sept problèmes majeurs du millénaire, a réalisé une nouvelle avancée. L'hypothèse de Riemann est un problème mathématique non résolu très important, lié aux propriétés précises de la distribution des nombres premiers (les nombres premiers sont les nombres qui ne sont divisibles que par 1 et par eux-mêmes, et jouent un rôle fondamental dans la théorie des nombres). Dans la littérature mathématique actuelle, il existe plus d'un millier de propositions mathématiques basées sur l'établissement de l'hypothèse de Riemann (ou sa forme généralisée). En d’autres termes, une fois que l’hypothèse de Riemann et sa forme généralisée seront prouvées, ces plus d’un millier de propositions seront établies sous forme de théorèmes, qui auront un impact profond sur le domaine des mathématiques et si l’hypothèse de Riemann s’avère fausse, alors parmi eux ; ces propositions qui en font partie perdront également de leur efficacité. Une nouvelle percée vient du professeur de mathématiques du MIT, Larry Guth, et de l'Université d'Oxford
 La formation Axiom permet au LLM d'apprendre le raisonnement causal : le modèle à 67 millions de paramètres est comparable au niveau de mille milliards de paramètres GPT-4.
Jul 17, 2024 am 10:14 AM
La formation Axiom permet au LLM d'apprendre le raisonnement causal : le modèle à 67 millions de paramètres est comparable au niveau de mille milliards de paramètres GPT-4.
Jul 17, 2024 am 10:14 AM
Montrez la chaîne causale à LLM et il pourra apprendre les axiomes. L'IA aide déjà les mathématiciens et les scientifiques à mener des recherches. Par exemple, le célèbre mathématicien Terence Tao a partagé à plusieurs reprises son expérience de recherche et d'exploration à l'aide d'outils d'IA tels que GPT. Pour que l’IA soit compétitive dans ces domaines, des capacités de raisonnement causal solides et fiables sont essentielles. La recherche présentée dans cet article a révélé qu'un modèle Transformer formé sur la démonstration de l'axiome de transitivité causale sur de petits graphes peut se généraliser à l'axiome de transitivité sur de grands graphes. En d’autres termes, si le Transformateur apprend à effectuer un raisonnement causal simple, il peut être utilisé pour un raisonnement causal plus complexe. Le cadre de formation axiomatique proposé par l'équipe est un nouveau paradigme pour l'apprentissage du raisonnement causal basé sur des données passives, avec uniquement des démonstrations.
