
 Périphériques technologiques
IA
Le test réel de Tencent Hunyuan dépasse GPT3.5 ? Les brevets d'IA offrent la plus grande confiance au grand modèle de Tencent
Périphériques technologiques
IA
Le test réel de Tencent Hunyuan dépasse GPT3.5 ? Les brevets d'IA offrent la plus grande confiance au grand modèle de Tencent
Le test réel de Tencent Hunyuan dépasse GPT3.5 ? Les brevets d'IA offrent la plus grande confiance au grand modèle de Tencent

Depuis cette année, l'intelligence artificielle, représentée par de grands modèles de langage, apporte de nouveaux changements technologiques, accélérant sa pénétration dans des milliers d'industries et créant de nouvelles opportunités de développement pour l'économie réelle.
Le 7 septembre, lors de la Tencent Global Digital Ecology Conference, le grand modèle Hunyuan de Tencent a été officiellement dévoilé et ouvert au monde extérieur via Tencent Cloud.
À ce stade, un autre acteur puissant a été ajouté à la piste nationale de modélisme à grande échelle où s'affrontent des centaines de rivaux.

Des brevets massifs soutiennent l'auto-recherche en lien complet
Sur la nouvelle voie des grands modèles d'IA, les entreprises nationales ont réalisé un démarrage rapide grâce à leurs investissements en R&D à long terme et à leur accumulation de technologies. De 2021 à 2022, Tencent a successivement développé de grands modèles clairsemés de NLP avec des centaines de milliards et de milliards de paramètres, réalisant de nouvelles percées dans les capacités de compréhension chinoises et optimisant continuellement les algorithmes sous-jacents des grands modèles dans des applications pratiques.
Il est entendu que le grand modèle Hunyuan publié cette fois est un grand modèle de langage général auto-développé par Tencent Full Link, avec une échelle de paramètres de plus de 100 milliards, un corpus de pré-formation de plus de 2 000 milliards de jetons et une solide compréhension et compréhension du chinois. capacités de création, capacité de raisonnement logique et capacité d'exécution fiable des tâches, il a fait des progrès significatifs dans la résolution du problème de « l'illusion » courant dans les grands modèles, et le problème du « charabia » a été considérablement résolu.
Jiang Jie, vice-président du groupe Tencent, estime que la capacité en langue chinoise du grand modèle Hunyuan a dépassé GPT3.5.
Lors de cette conférence de presse, Jiang Jie a utilisé la « Méthode d'évaluation de la technologie et des applications des modèles de pré-formation à grande échelle » de l'Académie chinoise des technologies de l'information et des communications pour effectuer un test. Au total, 66 éléments de capacité du grand modèle Hunyuan ont été évalués. en "développement de modèles" et " L'évaluation complète dans deux domaines importants de la "capacité du modèle" a obtenu le score actuel le plus élevé. Sur les ensembles d'évaluation traditionnels MMLU, CEval et AGI-eval, le grand modèle hybride offre d'excellentes performances.
En fait, les avantages de Tencent Hunyuan sont indissociables des avantages de Tencent en matière de brevets d'IA. Par exemple, en avril de cette année, Tencent a été autorisé à breveter « AI Intelligent Chat Interaction Patent », qui peut répondre aux messages selon plusieurs modalités ; en juin, le brevet « An Artificial Intelligence-Based Psychological Counseling/Conversation System and Method » a été autorisé. ; en juillet, « Méthodes de génération de phrases, dispositifs et supports de stockage lisibles par ordinateur » ou autorisations, etc.
De la demande de brevet à l'autorisation de brevet, force est de constater que Tencent évolue très rapidement dans le domaine de l'IA.
Le nombre de demandes de brevet dans le domaine mondial de l'intelligence artificielle n'a commencé à croître de manière explosive qu'en 2013. Selon les statistiques de l'agence statista, Tencent a dépassé Microsoft en termes de nombre de brevets sur l'IA qu'elle détient en 2021, se classant au premier rang mondial.
Les brevets sont des actifs incorporels importants d'une entreprise. Ils peuvent non seulement apporter directement des avantages économiques à l'entreprise, mais également aider la marque à accroître son influence et sa crédibilité dans l'industrie. Nous voyons souvent des nouvelles sur l'exposition des brevets d'une entreprise dans les informations en ligne, afin que nous puissions comprendre la force d'innovation de l'entreprise, l'orientation de la recherche et du développement, et même spéculer sur les tendances de développement de l'entreprise.
Ce sont ces brevets intensivement autorisés qui soutiennent l'auto-recherche sur les grands modèles Hunyuan. Des années d'accumulation de brevets ont également amélioré le système technique de Tencent dans le domaine de l'IA.
Continuez à investir de l'argent réel
Au cours du dernier deuxième trimestre 2023, Tencent a publié ses dernières données financières. L'investissement cumulé en R&D au premier semestre de cette année a atteint 31,191 milliards de yuans. Depuis 2018, Tencent a investi un total de 236,8 milliards de yuans en fonds de R&D, ce qui a également porté son personnel dans le domaine de la R&D à un taux étonnant de 74 %.
Des années d'investissements élevés ont permis à Tencent de réaliser des percées significatives en matière d'innovation technologique. Fin 2022, Tencent avait publié plus de 66 000 demandes de brevet dans le monde et le nombre d'autorisations de brevet dépassait 33 000. Ces brevets sont principalement concentrés dans des domaines de pointe tels que l'intelligence artificielle, la technologie cloud, les voyages de masse et la messagerie instantanée, apportant un solide soutien à la position de leader de Tencent dans le domaine technologique.
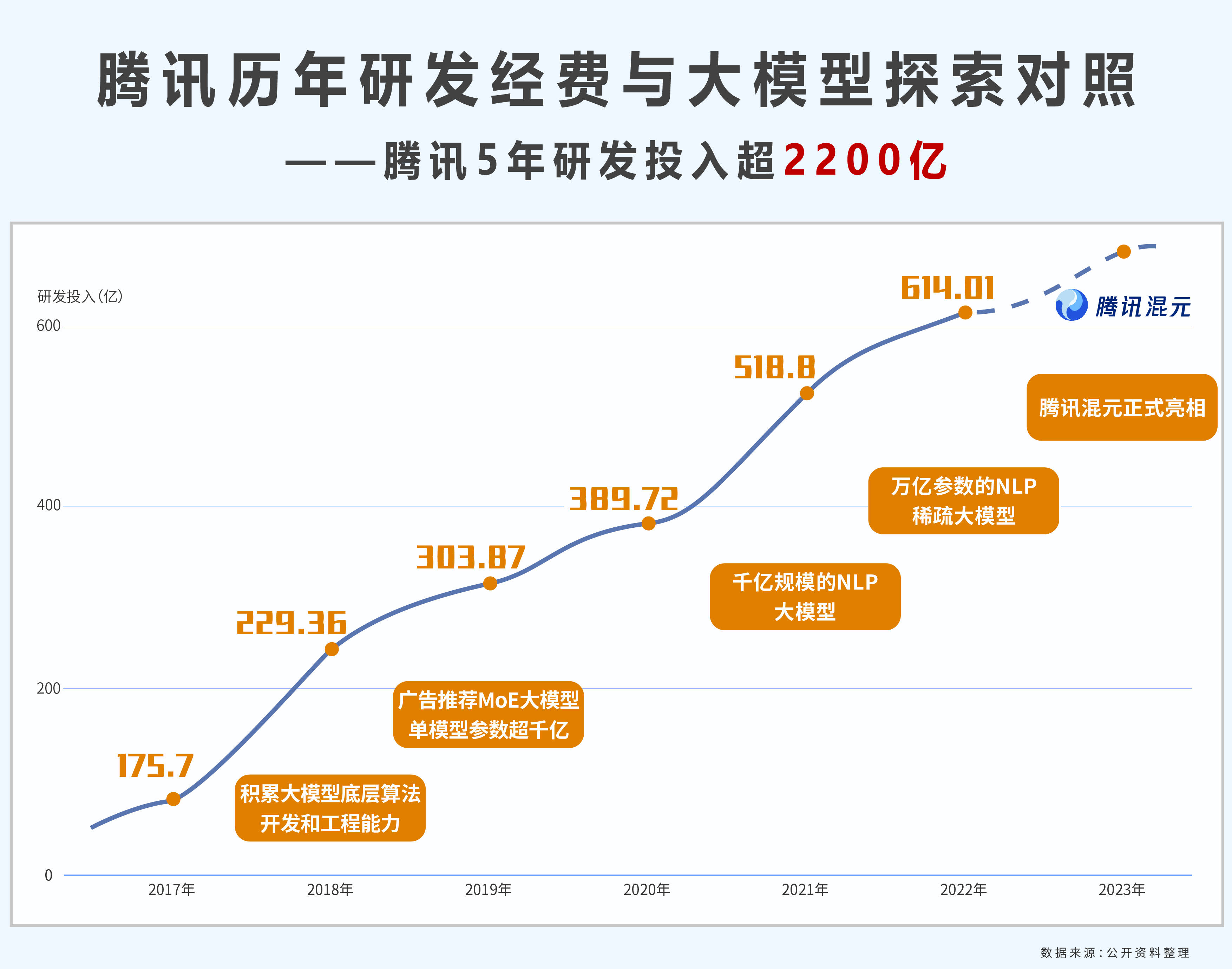
Il convient de mentionner que parmi les principales sociétés Internet nationales, les dépenses de R&D de Tencent occupent la première place.
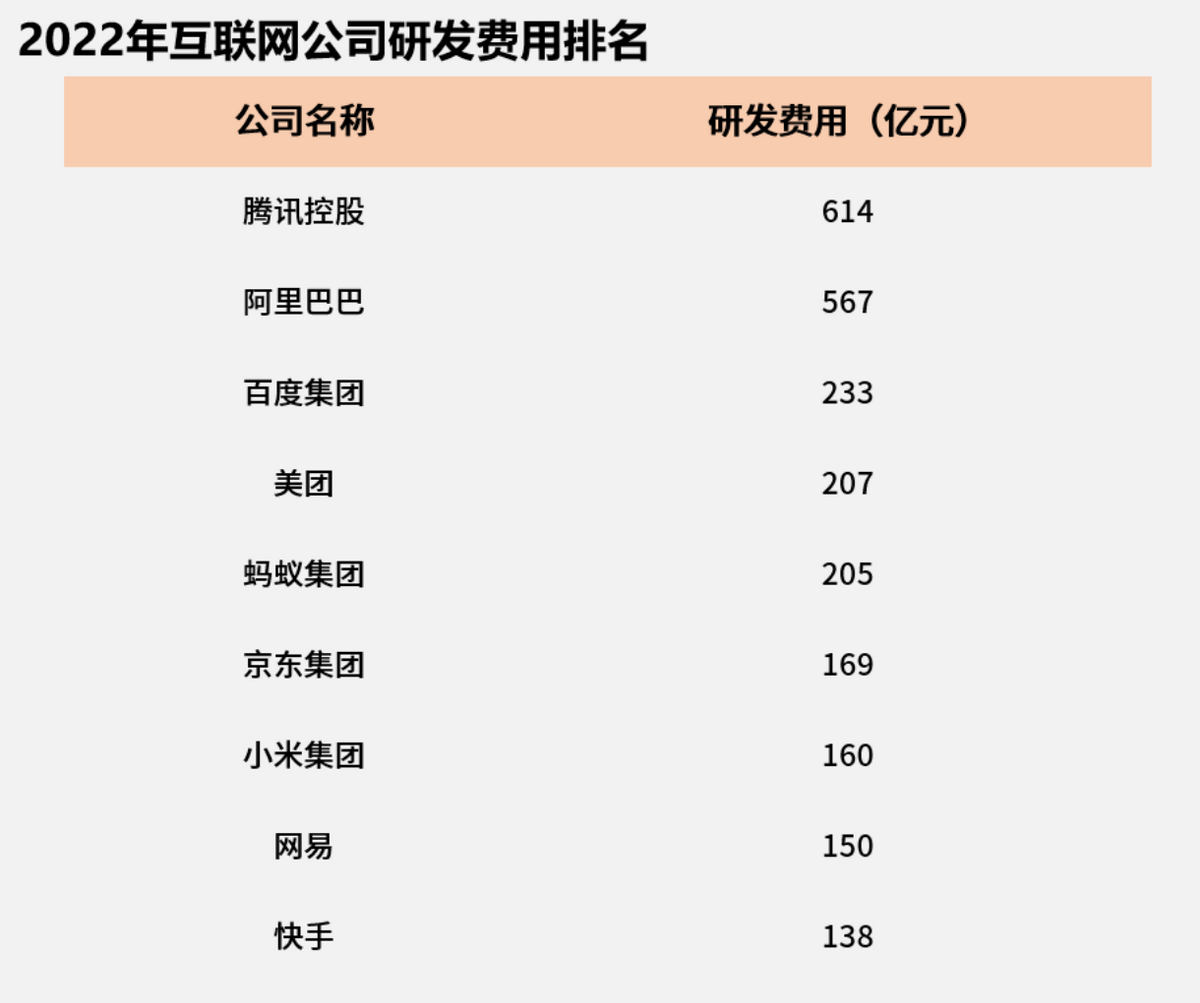
Et ces investissements en R&D ont abouti à d’énormes progrès en matière de brevets. En juin de cette année, Tencent avait publié plus de 66 000 demandes de brevet et accordé plus de 33 000 brevets dans les principaux pays et régions du monde, principalement dans des domaines de pointe tels que l'intelligence artificielle, la technologie cloud, les voyages de masse et la messagerie instantanée.
En fait, dès 2019, le nombre de demandes de brevet de Tencent dans les principaux pays du monde dépassait les 30 000 et le nombre de brevets autorisés dépassait les 10 000. Le nombre de demandes de brevet se classe au premier rang parmi les sociétés Internet nationales et au deuxième rang parmi les sociétés Internet mondiales, juste derrière Google.
Ces investissements en R&D et l'acquisition de brevets montrent également que Tencent est très déterminé à construire un grand modèle afin de mieux accompagner l'intelligence industrielle et aider les entreprises chinoises dans la transformation numérique.
Lors de la Global Digital Conference, Li Qiang, vice-président du groupe Tencent, a déclaré : « Tencent encouragera fermement les grands modèles à entrer dans l'ensemble de la chaîne industrielle et à les intégrer dans la pratique industrielle, des champs aux lignes de production, des laboratoires aux magasins de proximité. afin que les grands modèles puissent omniprésents pour aider l'économie réelle chinoise à faire face aux défis de la mondialisation et à atteindre une croissance de haute qualité
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1660
1660
 14
1416
52
1310
25
1260
29
1233
24
14
1416
52
1310
25
1260
29
1233
24

 L'application de grands modèles Tencent Yuanbao est en ligne ! Hunyuan est mis à niveau pour créer un assistant IA complet pouvant être transporté n'importe où
Jun 09, 2024 pm 10:38 PM
L'application de grands modèles Tencent Yuanbao est en ligne ! Hunyuan est mis à niveau pour créer un assistant IA complet pouvant être transporté n'importe où
Jun 09, 2024 pm 10:38 PM
Le 30 mai, Tencent a annoncé une mise à niveau complète de son modèle Hunyuan. L'application « Tencent Yuanbao » basée sur le modèle Hunyuan a été officiellement lancée et peut être téléchargée sur les magasins d'applications Apple et Android. Par rapport à la version de l'applet Hunyuan lors de la phase de test précédente, Tencent Yuanbao fournit des fonctionnalités de base telles que la recherche IA, le résumé IA et l'écriture IA pour les scénarios d'efficacité du travail ; pour les scénarios de la vie quotidienne, le gameplay de Yuanbao est également plus riche et fournit de multiples fonctionnalités d'application IA. , et de nouvelles méthodes de jeu telles que la création d'agents personnels sont ajoutées. « Tencent ne s'efforcera pas d'être le premier à créer un grand modèle. » Liu Yuhong, vice-président de Tencent Cloud et responsable du grand modèle Tencent Hunyuan, a déclaré : « Au cours de l'année écoulée, nous avons continué à promouvoir les capacités de Tencent. Grand modèle Tencent Hunyuan. Dans la technologie polonaise riche et massive dans des scénarios commerciaux tout en obtenant un aperçu des besoins réels des utilisateurs.
 Lancement du grand modèle Bytedance Beanbao, le service d'IA complet Volcano Engine aide les entreprises à se transformer intelligemment
Jun 05, 2024 pm 07:59 PM
Lancement du grand modèle Bytedance Beanbao, le service d'IA complet Volcano Engine aide les entreprises à se transformer intelligemment
Jun 05, 2024 pm 07:59 PM
Tan Dai, président de Volcano Engine, a déclaré que les entreprises qui souhaitent bien mettre en œuvre de grands modèles sont confrontées à trois défis clés : l'effet de modèle, le coût d'inférence et la difficulté de mise en œuvre : elles doivent disposer d'un bon support de base de grands modèles pour résoudre des problèmes complexes, et elles doivent également avoir une inférence à faible coût. Les services permettent d'utiliser largement de grands modèles, et davantage d'outils, de plates-formes et d'applications sont nécessaires pour aider les entreprises à mettre en œuvre des scénarios. ——Tan Dai, président de Huoshan Engine 01. Le grand modèle de pouf fait ses débuts et est largement utilisé. Le polissage de l'effet de modèle est le défi le plus critique pour la mise en œuvre de l'IA. Tan Dai a souligné que ce n'est que grâce à une utilisation intensive qu'un bon modèle peut être poli. Actuellement, le modèle Doubao traite 120 milliards de jetons de texte et génère 30 millions d'images chaque jour. Afin d'aider les entreprises à mettre en œuvre des scénarios de modèles à grande échelle, le modèle à grande échelle beanbao développé indépendamment par ByteDance sera lancé à travers le volcan.
 Pratique avancée du graphe de connaissances industrielles
Jun 13, 2024 am 11:59 AM
Pratique avancée du graphe de connaissances industrielles
Jun 13, 2024 am 11:59 AM
1. Introduction au contexte Tout d’abord, présentons l’historique du développement de la technologie Yunwen. Yunwen Technology Company... 2023 est la période où les grands modèles prédominent. De nombreuses entreprises pensent que l'importance des graphiques a été considérablement réduite après les grands modèles et que les systèmes d'information prédéfinis étudiés précédemment ne sont plus importants. Cependant, avec la promotion du RAG et la prévalence de la gouvernance des données, nous avons constaté qu'une gouvernance des données plus efficace et des données de haute qualité sont des conditions préalables importantes pour améliorer l'efficacité des grands modèles privatisés. Par conséquent, de plus en plus d'entreprises commencent à y prêter attention. au contenu lié à la construction des connaissances. Cela favorise également la construction et le traitement des connaissances à un niveau supérieur, où de nombreuses techniques et méthodes peuvent être explorées. On voit que l'émergence d'une nouvelle technologie ne détruit pas toutes les anciennes technologies, mais peut également intégrer des technologies nouvelles et anciennes.
 Référence GPT-4 ! Le grand modèle Jiutian de China Mobile a passé le double enregistrement
Apr 04, 2024 am 09:31 AM
Référence GPT-4 ! Le grand modèle Jiutian de China Mobile a passé le double enregistrement
Apr 04, 2024 am 09:31 AM
Selon des informations du 4 avril, l'Administration du cyberespace de Chine a récemment publié une liste de grands modèles enregistrés, et le « Grand modèle d'interaction du langage naturel Jiutian » de China Mobile y a été inclus, indiquant que le grand modèle Jiutian AI de China Mobile peut officiellement fournir des informations artificielles génératives. services de renseignement vers le monde extérieur. China Mobile a déclaré qu'il s'agit du premier modèle à grande échelle développé par une entreprise centrale à avoir réussi à la fois le double enregistrement national « Enregistrement du service d'intelligence artificielle générative » et le double enregistrement « Enregistrement de l'algorithme de service de synthèse profonde domestique ». Selon les rapports, le grand modèle d'interaction en langage naturel de Jiutian présente les caractéristiques de capacités, de sécurité et de crédibilité améliorées de l'industrie, et prend en charge la localisation complète. Il a formé plusieurs versions de paramètres telles que 9 milliards, 13,9 milliards, 57 milliards et 100 milliards. et peut être déployé de manière flexible dans le Cloud, la périphérie et la fin sont des situations différentes
 Nouveau benchmark de test publié, le Llama 3 open source le plus puissant est gêné
Apr 23, 2024 pm 12:13 PM
Nouveau benchmark de test publié, le Llama 3 open source le plus puissant est gêné
Apr 23, 2024 pm 12:13 PM
Si les questions du test sont trop simples, les meilleurs étudiants et les mauvais étudiants peuvent obtenir 90 points, et l'écart ne peut pas être creusé... Avec la sortie plus tard de modèles plus puissants tels que Claude3, Llama3 et même GPT-5, l'industrie est en besoin urgent d'un modèle de référence plus difficile et différencié. LMSYS, l'organisation à l'origine du grand modèle Arena, a lancé la référence de nouvelle génération, Arena-Hard, qui a attiré une large attention. Il existe également la dernière référence pour la force des deux versions affinées des instructions Llama3. Par rapport à MTBench, qui avait des scores similaires auparavant, la discrimination Arena-Hard est passée de 22,6 % à 87,4 %, ce qui est plus fort et plus faible en un coup d'œil. Arena-Hard est construit à partir de données humaines en temps réel provenant de l'arène et a un taux de cohérence de 89,1 % avec les préférences humaines.
 GPT Store ne peut même pas ouvrir ses portes. Comment cette plateforme nationale ose-t-elle emprunter cette voie ? ?
Apr 19, 2024 pm 09:30 PM
GPT Store ne peut même pas ouvrir ses portes. Comment cette plateforme nationale ose-t-elle emprunter cette voie ? ?
Apr 19, 2024 pm 09:30 PM
Attention, cet homme a connecté plus de 1 000 grands modèles, vous permettant de vous brancher et de switcher en toute transparence. Récemment, un flux de travail d'IA visuelle a été lancé : vous offrant une interface intuitive de type glisser-déposer, vous pouvez glisser, tirer et faire glisser pour organiser votre propre flux de travail sur un canevas infini. Comme le dit le proverbe, la guerre coûte cher, et Qubit a appris que dans les 48 heures suivant la mise en ligne de cet AIWorkflow, les utilisateurs avaient déjà configuré des flux de travail personnels avec plus de 100 nœuds. Sans plus tarder, je veux parler aujourd'hui de Dify, une société LLMOps, et de son PDG Zhang Luyu. Zhang Luyu est également le fondateur de Dify. Avant de rejoindre l'entreprise, il avait 11 ans d'expérience dans l'industrie Internet. Je suis engagé dans la conception de produits, je comprends la gestion de projet et j'ai des connaissances uniques sur le SaaS. Plus tard, il
 Annonce des progrès de l'optimisation de la mémoire de la version de l'architecture Tencent QQ NT, les scènes de discussion sont contrôlées dans un rayon de 300 M
Mar 05, 2024 pm 03:52 PM
Annonce des progrès de l'optimisation de la mémoire de la version de l'architecture Tencent QQ NT, les scènes de discussion sont contrôlées dans un rayon de 300 M
Mar 05, 2024 pm 03:52 PM
Il est entendu que le client de bureau Tencent QQ a subi une série de réformes drastiques. En réponse aux problèmes des utilisateurs tels qu'une utilisation élevée de la mémoire, des packages d'installation surdimensionnés et un démarrage lent, l'équipe technique de QQ a réalisé des optimisations spéciales sur la mémoire et a progressé progressivement. Récemment, l'équipe technique de QQ a publié un article d'introduction à la plateforme InfoQ, partageant ses progrès progressifs en matière d'optimisation spéciale de la mémoire. Selon les rapports, les défis de mémoire de la nouvelle version de QQ se reflètent principalement dans les quatre aspects suivants : Forme du produit : il se compose d'un grand panneau complexe (plus de 100 modules de complexité variable) et d'une série de fenêtres fonctionnelles indépendantes. Il existe une correspondance biunivoque entre les fenêtres et les processus de rendu. Le nombre de processus de fenêtre affecte grandement l'utilisation de la mémoire d'Electron. Pour ce grand panneau complexe, une fois qu'il n'y a plus
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
