
 Périphériques technologiques
IA
Grimper, sauter et franchir des espaces étroits, des stratégies d'apprentissage par renforcement open source permettent aux chiens robots de faire du parkour
Périphériques technologiques
IA
Grimper, sauter et franchir des espaces étroits, des stratégies d'apprentissage par renforcement open source permettent aux chiens robots de faire du parkour
Grimper, sauter et franchir des espaces étroits, des stratégies d'apprentissage par renforcement open source permettent aux chiens robots de faire du parkour

Le parkour est un sport extrême. C'est un énorme défi pour les robots, en particulier les chiens robots à quatre pattes, qui doivent surmonter rapidement divers obstacles dans des environnements complexes. Certaines études ont tenté d'utiliser des données d'animaux de référence ou des récompenses complexes, mais ces approches génèrent des compétences de parkour qui sont soit diverses mais aveugles, soit basées sur la vision mais spécifiques à une scène. Cependant, le parkour autonome nécessite que les robots acquièrent des compétences générales diverses et basées sur la vision pour percevoir divers scénarios et réagir rapidement.
Récemment, une vidéo d'un parkour de chien robot est devenue virale. Le chien robot dans la vidéo a rapidement surmonté divers obstacles dans divers scénarios. Par exemple, passez par l'espace sous la plaque de fer, grimpez sur la caisse en bois, puis sautez vers une autre caisse en bois. Une série de mouvements sont fluides et fluides :


Cette série de mouvements montre. que le chien robot maîtrise en collant au sol. Trois compétences de base : ramper, grimper et sauter.

 Si le chien robot échoue Surmontez les obstacles et il faudra encore quelques essais :
Si le chien robot échoue Surmontez les obstacles et il faudra encore quelques essais :

Ce contenu a été réécrit en chinois : Ce chien robot est basé sur un cadre d'apprentissage de compétences « parkour » développé pour les robots à faible coût. Le cadre a été proposé conjointement par des chercheurs de l'Institut de recherche Shanghai Qizhi, de l'Université Stanford, de l'Université ShanghaiTech, de la CMU et de l'Université Tsinghua, et son document de recherche a été sélectionné pour CoRL 2023 (Oral). Ce projet de recherche a été open source

Adresse papier : https://arxiv.org/abs/2309.05665

Introduction à la méthode

Cette recherche présente un nouveau système open source pour apprendre des stratégies de parkour basées sur la vision de bout en bout afin d'acquérir plusieurs compétences de parkour en utilisant des récompenses simples sans aucune donnée de mouvement de référence.
Plus précisément, cette recherche propose une méthode d'apprentissage par renforcement conçue pour permettre aux robots d'acquérir des compétences telles que grimper des obstacles élevés, sauter par-dessus de grands espaces, ramper sous des obstacles bas, se faufiler à travers de petits espaces et courir, et traduire ces compétences en stratégies de parkour. basé sur une vision unique. Simultanément, ces compétences sont transférées à des robots quadrupèdes en utilisant une caméra de profondeur égocentrique
Pour réussir à déployer la stratégie de parkour proposée dans cette étude sur un robot low-cost, il suffit d'utiliser l'informatique embarquée (Nvidia Jetson), la caméra de profondeur aéroportée (Intel Realsense) et alimentation électrique embarquée, sans avoir besoin de capture de mouvement, de lidar, de plusieurs caméras de profondeur et de nombreux calculs
Afin d'entraîner la stratégie de parkour, l'étude a mené les trois étapes suivantes Travail :
Le première étape : pré-entraînement par apprentissage par renforcement avec contraintes dynamiques douces. Cette recherche utilise des cours automatiques pour permettre au robot d'apprendre à franchir les obstacles, l'encourageant à apprendre progressivement à surmonter les obstacles
Deuxième étape : apprentissage par renforcement affinant avec des contraintes dynamiques dures. La recherche applique toutes les contraintes dynamiques à ce stade et utilise une dynamique réaliste pour affiner le comportement du robot appris lors de la phase de pré-formation.
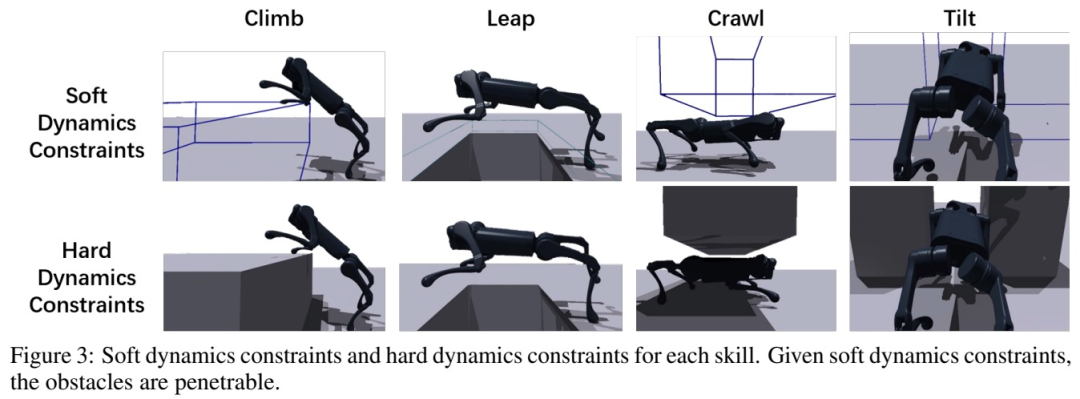
La troisième étape : la distillation. Après avoir appris chaque compétence de parkour individuelle, l'étude utilise DAgger pour les distiller dans une politique de parkour basée sur la vision (paramétrée par un RNN) qui peut être déployée sur un robot à pattes en utilisant uniquement la perception et le calcul embarqués.

Expériences et résultats
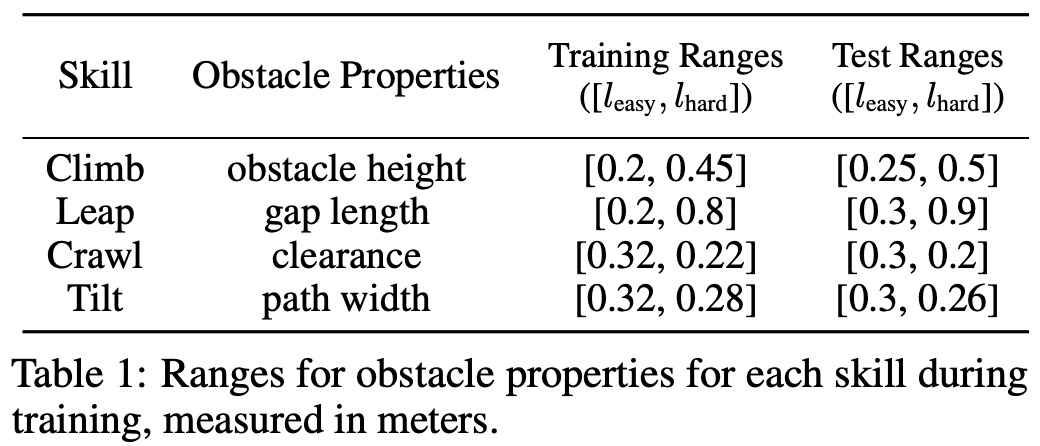
En formation, l'étude a défini les tailles d'obstacles correspondantes pour chaque compétence, comme le montre le tableau 1 ci-dessous :
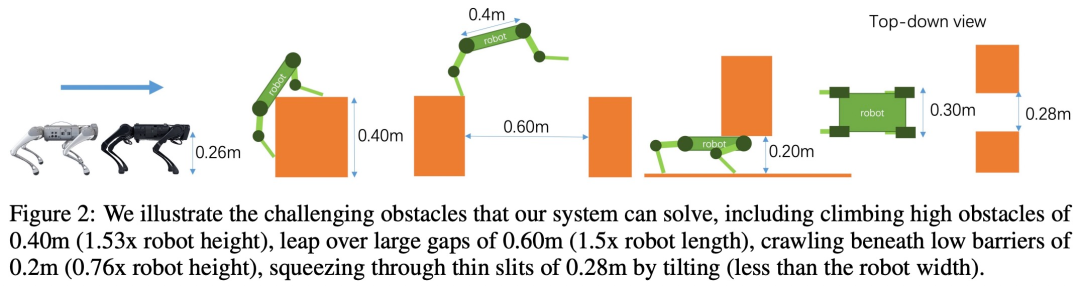
L'étude Des simulations approfondies et des simulations réelles -des expériences de vie ont été menées et les résultats montrent que les stratégies de parkour permettent à des robots quadrupèdes à faible coût de sélectionner et d'exécuter de manière autonome les compétences de parkour appropriées à parcourir en utilisant uniquement l'informatique embarquée, la détection visuelle embarquée et l'alimentation embarquée dans des environnements difficiles dans le monde ouvert, y compris. grimper des obstacles jusqu'à 0,40 m (1,53x la hauteur du robot), sauter par-dessus de grands espaces jusqu'à 0,60 m (1,5x la longueur du robot) et sauter par-dessus des obstacles aussi bas que 0,2 m (0,76x la hauteur du robot). Il peut ramper sous les objets, se presser à travers un espace étroit de 0,28 m (inférieur à la largeur du robot) en s'inclinant, et peut continuer à avancer.

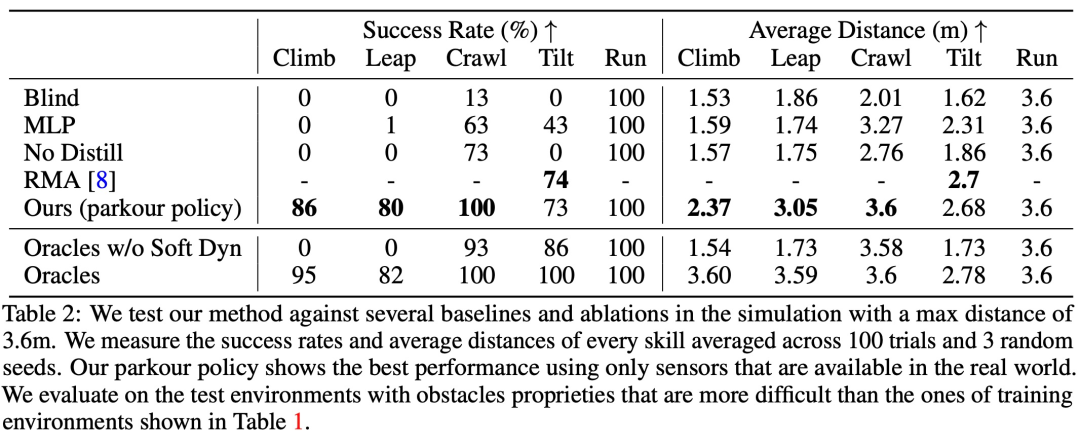
De plus, l'étude a également comparé la méthode proposée avec plusieurs méthodes de base et mené des expériences d'ablation dans un environnement simulé. Les résultats spécifiques sont présentés dans le tableau 2 :
Les lecteurs intéressés peuvent lire l'article original pour en savoir plus sur le contenu de la recherche
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1393
1393
 52
1205
24
52
1205
24

 WEB3 Trading Platform Ranking_Web3 Global Exchanges Top Ten Résumé
Apr 21, 2025 am 10:45 AM
WEB3 Trading Platform Ranking_Web3 Global Exchanges Top Ten Résumé
Apr 21, 2025 am 10:45 AM
Binance est le suzerain de l'écosystème mondial de trading d'actifs numériques, et ses caractéristiques comprennent: 1. Le volume de négociation quotidien moyen dépasse 150 milliards de dollars, prend en charge 500 paires de négociation, couvrant 98% des monnaies grand public; 2. La matrice d'innovation couvre le marché des dérivés, la mise en page Web3 et le système éducatif; 3. Les avantages techniques sont des moteurs de correspondance d'une milliseconde, avec des volumes de traitement de pointe de 1,4 million de transactions par seconde; 4. Conformité Progress détient des licences de 15 pays et établit des entités conformes en Europe et aux États-Unis.
 Comment éviter les pertes après la mise à niveau de l'ETH
Apr 21, 2025 am 10:03 AM
Comment éviter les pertes après la mise à niveau de l'ETH
Apr 21, 2025 am 10:03 AM
Après la mise à niveau de l'ETH, les novices devraient adopter les stratégies suivantes pour éviter les pertes: 1. Faites leurs devoirs et comprenez les connaissances de base et la mise à niveau du contenu de l'ETH; 2. Contrôler les positions, tester les eaux en petites quantités et diversifier l'investissement; 3. Faire un plan de négociation, clarifier les objectifs et fixer des points de perte d'arrêt; 4. Profilement rationnellement et éviter la prise de décision émotionnelle; 5. Choisissez une plate-forme de trading formelle et fiable; 6. Considérons la tenue à long terme pour éviter l'impact des fluctuations à court terme.
 Top 10 plates-formes d'échange de crypto-monnaie La plus grande liste de changes numériques au monde
Apr 21, 2025 pm 07:15 PM
Top 10 plates-formes d'échange de crypto-monnaie La plus grande liste de changes numériques au monde
Apr 21, 2025 pm 07:15 PM
Les échanges jouent un rôle essentiel sur le marché des crypto-monnaies d'aujourd'hui. Ce ne sont pas seulement des plateformes pour les investisseurs pour négocier, mais aussi des sources importantes de liquidité du marché et la découverte des prix. Les plus grands échanges de devises virtuels au monde se classent parmi les dix premiers, et ces échanges sont non seulement bien en avance dans le volume des échanges, mais présentent également leurs propres avantages dans l'expérience utilisateur, la sécurité et les services innovants. Les échanges qui dépassent la liste ont généralement une grande base d'utilisateurs et une influence approfondie du marché, et leur volume de trading et leurs types d'actifs sont souvent difficiles à atteindre par d'autres échanges.
 Pourquoi la hausse ou la baisse des prix de monnaie virtuelle? Pourquoi la hausse ou la baisse des prix de monnaie virtuelle?
Apr 21, 2025 am 08:57 AM
Pourquoi la hausse ou la baisse des prix de monnaie virtuelle? Pourquoi la hausse ou la baisse des prix de monnaie virtuelle?
Apr 21, 2025 am 08:57 AM
Les facteurs de la hausse des prix des devises virtuels comprennent: 1. Une augmentation de la demande du marché, 2. Daisser l'offre, 3. Stimulé de nouvelles positives, 4. Sentiment du marché optimiste, 5. Environnement macroéconomique; Les facteurs de déclin comprennent: 1. Daissement de la demande du marché, 2. AUGMENT DE L'OFFICATION, 3. Strike of Negative News, 4. Pespimiste Market Sentiment, 5. Environnement macroéconomique.
 Quelles sont les dix principales plates-formes du cercle d'échange de devises?
Apr 21, 2025 pm 12:21 PM
Quelles sont les dix principales plates-formes du cercle d'échange de devises?
Apr 21, 2025 pm 12:21 PM
Les principaux échanges comprennent: 1. Binance, le plus grand volume de trading au monde, prend en charge 600 devises et les frais de gestion des points sont de 0,1%; 2. Okx, une plate-forme équilibrée, prend en charge 708 paires de trading, et les frais de traitement des contrats perpétuels sont de 0,05%; 3. Gate.io, couvre 2700 petites monnaies, et les frais de traitement des points sont de 0,1% à 0,3%; 4. Coinbase, la référence de conformité américaine, les frais de traitement des points sont de 0,5%; 5. Kraken, la haute sécurité et l'audit de réserve régulière.
 Classement des échanges à effet de levier dans le cercle des devises Les dernières recommandations des dix premiers échanges à effet de levier dans le cercle des devises
Apr 21, 2025 pm 11:24 PM
Classement des échanges à effet de levier dans le cercle des devises Les dernières recommandations des dix premiers échanges à effet de levier dans le cercle des devises
Apr 21, 2025 pm 11:24 PM
Les plates-formes qui ont des performances exceptionnelles dans le commerce, la sécurité et l'expérience utilisateur en effet de levier en 2025 sont: 1. OKX, adaptés aux traders à haute fréquence, fournissant jusqu'à 100 fois l'effet de levier; 2. Binance, adaptée aux commerçants multi-monnaies du monde entier, offrant un effet de levier 125 fois élevé; 3. Gate.io, adapté aux joueurs de dérivés professionnels, fournissant 100 fois l'effet de levier; 4. Bitget, adapté aux novices et aux commerçants sociaux, fournissant jusqu'à 100 fois l'effet de levier; 5. Kraken, adapté aux investisseurs stables, fournissant 5 fois l'effet de levier; 6. BUTBIT, adapté aux explorateurs Altcoin, fournissant 20 fois l'effet de levier; 7. Kucoin, adapté aux commerçants à faible coût, fournissant 10 fois l'effet de levier; 8. Bitfinex, adapté au jeu senior
 Que signifie la transaction transversale? Quelles sont les transactions transversales?
Apr 21, 2025 pm 11:39 PM
Que signifie la transaction transversale? Quelles sont les transactions transversales?
Apr 21, 2025 pm 11:39 PM
Échanges qui prennent en charge les transactions transversales: 1. Binance, 2. UniSwap, 3. Sushiswap, 4. Curve Finance, 5. Thorchain, 6. 1inch Exchange, 7. DLN Trade, ces plateformes prennent en charge les transactions d'actifs multi-chaînes via diverses technologies.
 Prévisions des prix WorldCoin (WLD) 2025-2031: WLD atteindra-t-il 4 $ d'ici 2031?
Apr 21, 2025 pm 02:42 PM
Prévisions des prix WorldCoin (WLD) 2025-2031: WLD atteindra-t-il 4 $ d'ici 2031?
Apr 21, 2025 pm 02:42 PM
WorldCoin (WLD) se démarque sur le marché des crypto-monnaies avec ses mécanismes uniques de vérification biométrique et de protection de la vie privée, attirant l'attention de nombreux investisseurs. WLD a permis de se produire avec remarquablement parmi les Altcoins avec ses technologies innovantes, en particulier en combinaison avec la technologie d'Intelligence artificielle OpenAI. Mais comment les actifs numériques se comporteront-ils au cours des prochaines années? Prédons ensemble le prix futur de WLD. Les prévisions de prix de 2025 WLD devraient atteindre une croissance significative de la WLD en 2025. L'analyse du marché montre que le prix moyen du WLD peut atteindre 1,31 $, avec un maximum de 1,36 $. Cependant, sur un marché baissier, le prix peut tomber à environ 0,55 $. Cette attente de croissance est principalement due à WorldCoin2.
