
 Périphériques technologiques
IA
Combien d'entreprises d'étiquetage d'IA le « grand pas » de Google va-t-il tuer ?
Périphériques technologiques
IA
Combien d'entreprises d'étiquetage d'IA le « grand pas » de Google va-t-il tuer ?
Combien d'entreprises d'étiquetage d'IA le « grand pas » de Google va-t-il tuer ?

Un petit atelier fait main ne fait finalement pas le poids face à la chaîne de montage en usine.
Si l’IA générative actuelle est un enfant qui grandit vigoureusement, alors les données continues sont l’aliment qui nourrit sa croissance.
L'annotation des données est le processus de fabrication de cette « nourriture »
Cependant, ce processus est vraiment fastidieux et fatiguant.
L'annotateur qui effectue des annotations doit non seulement identifier à plusieurs reprises divers objets, couleurs, formes, etc. dans l'image, mais doit parfois même nettoyer et prétraiter les données.
Avec les progrès continus de la technologie de l'intelligence artificielle, les limites de l'annotation manuelle des données deviennent de plus en plus évidentes. L'annotation manuelle des données demande non seulement du temps et des efforts, mais il est parfois difficile de garantir la qualité

Pour résoudre ces problèmes, Google a récemment proposé une méthode appelée AI Feedback Reinforcement Learning (RLAIF), en utilisant de grands modèles pour remplacer les humains pour l'annotation des préférences
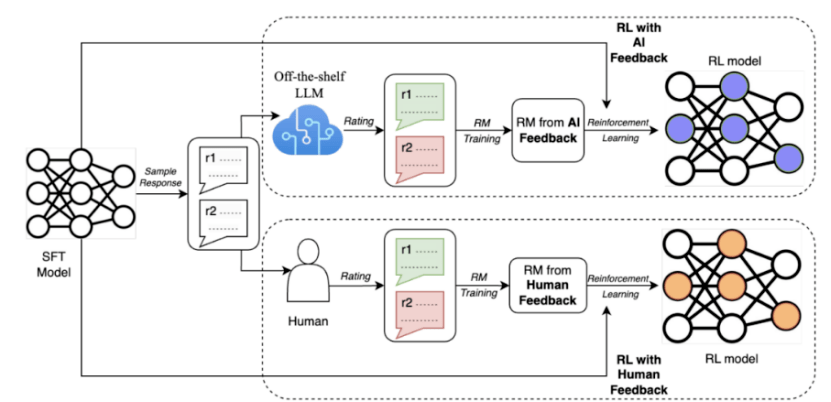
Les résultats de la recherche montrent que le RLAIF peut obtenir des améliorations équivalentes à l'apprentissage par renforcement avec feedback humain (RLHF) sans recourir à l'annotation humaine, et le taux de réussite dans les deux cas est de 50 %. En outre, l'étude a également révélé que le RLAIF et le RLHF sont tous deux supérieurs à la stratégie de base de réglage fin supervisé (SFT)
Ces résultats montrent que RLAIF n'a pas besoin de s'appuyer sur des annotations manuelles et constitue une alternative réalisable au RLHF.
Si cette technologie est vraiment largement promue et popularisée à l'avenir, de nombreuses entreprises qui s'appuient sur des « boîtes de tirage » manuelles pour l'annotation des données seront-elles confrontées à une situation désespérée ?
01 État actuel de l'annotation des données
Si nous voulons simplement résumer l'état actuel de l'industrie nationale de l'annotation, c'est : La charge de travail est importante, mais l'efficacité n'est pas très élevée et c'est un état ingrat.
Les entreprises marquées sont appelées usines de données dans le domaine de l'IA et sont généralement concentrées en Asie du Sud-Est, en Afrique ou dans des régions riches en ressources humaines comme le Henan, le Shanxi et le Shandong en Chine.
Afin de réduire les coûts, les patrons de l'entreprise d'étiquetage loueront un espace dans la commune pour y placer du matériel informatique. Une fois qu'il y aura une commande, ils recruteront du personnel à temps partiel à proximité pour la gérer. S'il n'y a pas de commande, ils se dissoudront et feront une pause
.Pour faire simple, ce type de travaux s'apparente un peu aux intérimaires en décoration en bord de route.

Au poste de travail, le système donnera aléatoirement à « l'annotateur » un ensemble de données, qui comprend généralement plusieurs questions et plusieurs réponses.
Après cela, « l'annotateur » doit d'abord marquer à quel type appartient la question, puis noter et trier les réponses.
Auparavant, lorsque les gens parlaient de l'écart entre les grands modèles nationaux et les grands modèles avancés tels que GPT-4, ils résumaient les raisons de la faible qualité des données nationales.
Pourquoi la qualité des données n'est-elle pas élevée ? Une partie de la raison réside dans le « pipeline » d’annotation des données
Actuellement, il existe deux types de sources de données pour les grands modèles chinois : l'une est constituée d'ensembles de données open source ; l'autre est constituée de données Internet chinoises explorées via des robots d'exploration.
L'une des principales raisons pour lesquelles les performances des grands modèles chinois ne sont pas assez bonnes est la qualité des données Internet. Par exemple, les professionnels n'utilisent généralement pas Baidu pour rechercher des informations.
Par conséquent, face à des problèmes de données plus professionnels et verticaux, tels que les soins médicaux, les finances, etc., il est nécessaire de coopérer avec une équipe professionnelle.
Mais à ce moment-là, le problème se pose à nouveau : pour les équipes professionnelles, non seulement la période de récupération des données est longue, mais les premiers arrivés risquent également de subir des pertes.
Par exemple, une certaine équipe d'annotation a dépensé beaucoup d'argent et de temps pour créer beaucoup de données, mais d'autres peuvent simplement les empaqueter et les acheter pour une petite somme d'argent.
Face à ce « dilemme du passager clandestin », de nombreux grands modèles nationaux sont tombés dans une situation étrange où, bien qu'il y ait beaucoup de données, la qualité n'est pas élevée
Dans ce cas, comment certaines des principales sociétés étrangères d’IA, comme OpenAI, résolvent-elles ce problème ?

OpenAI n'a pas renoncé à utiliser une main d'œuvre intensive et bon marché pour réduire les coûts d'annotation des données
Par exemple, il a été révélé précédemment qu'elle avait embauché un grand nombre de travailleurs kenyans pour étiqueter les informations toxiques au prix de 2 $ US/heure.
Cependant, la différence importante réside dans la manière de résoudre les problèmes de qualité des données et d'efficacité des annotations
Plus précisément, la plus grande différence entre OpenAI et les entreprises nationales à cet égard est de savoir comment réduire l'impact de la « subjectivité » et de « l'instabilité » de l'annotation manuelle.
02 L’approche d’OpenAI Lors de la réécriture du contenu, la langue doit être réécrite en chinois et la phrase originale n'a pas besoin d'apparaître
Afin de réduire la « subjectivité » et « l'instabilité » de ces annotateurs humains, OpenAI adopte grossièrement deux stratégies principales :
1. Combinaison de feedback artificiel et d'apprentissage par renforcement ; Lors de la réécriture, le contenu original doit être converti en chinois. Voici à quoi cela ressemble après réécriture : Parlons d’abord de l’étiquetage. La plus grande différence entre le feedback artificiel d'OpenAI et le feedback domestique est qu'il trie ou note principalement le comportement du système intelligent, plutôt que de modifier ou d'étiqueter sa sortie
Le comportement d'un système intelligent fait référence à une série d'actions ou de décisions prises par un système intelligent dans un environnement complexe en fonction de ses propres objectifs et stratégies
Comme jouer à des jeux, contrôler des robots, parler aux gens, etc.
 La sortie d'un système intelligent fait référence à la génération d'un résultat ou d'une réponse basée sur des données d'entrée dans une tâche simple, comme écrire un article ou dessiner un tableau.
La sortie d'un système intelligent fait référence à la génération d'un résultat ou d'une réponse basée sur des données d'entrée dans une tâche simple, comme écrire un article ou dessiner un tableau.
D'une manière générale, le comportement des systèmes intelligents est souvent difficile à juger en termes de « bien » ou de « mal », mais doit plutôt être évalué en termes de préférence ou de satisfaction
Ce type de système d'évaluation basé sur la « préférence » ou la « satisfaction » ne nécessite pas de modification ou d'annotation de contenu spécifique, réduisant ainsi l'impact de la subjectivité humaine, du niveau de connaissances et d'autres facteurs sur la qualité et l'exactitude de l'annotation des données
 Il est vrai que les entreprises nationales utiliseront également des systèmes similaires au « tri » et à la « notation » lors de l'étiquetage. Cependant, en raison de l'absence d'un « modèle de récompense » comme OpenAI comme fonction de récompense pour optimiser la stratégie du système intelligent, un tel « tri » et une telle « notation » restent essentiellement une méthode de modification ou d'annotation de la sortie.
Il est vrai que les entreprises nationales utiliseront également des systèmes similaires au « tri » et à la « notation » lors de l'étiquetage. Cependant, en raison de l'absence d'un « modèle de récompense » comme OpenAI comme fonction de récompense pour optimiser la stratégie du système intelligent, un tel « tri » et une telle « notation » restent essentiellement une méthode de modification ou d'annotation de la sortie.
Les principales sources d'annotation de données en Chine sont des sociétés d'annotation tierces ou des équipes auto-construites d'entreprises technologiques. Ces équipes sont principalement composées d'étudiants de premier cycle et manquent de professionnalisme et d'expérience pour fournir des commentaires efficaces et de haute qualité.
En revanche, les commentaires humains d’OpenAI sont obtenus via plusieurs canaux et équipes
 OpenAI coopère avec plusieurs sociétés et institutions de données, telles que Scale AI, Appen, Lionbridge AI, etc., non seulement en utilisant des ensembles de données open source et des robots d'exploration Internet pour obtenir des données, mais s'engage également à obtenir des données plus diversifiées et de haute qualité
OpenAI coopère avec plusieurs sociétés et institutions de données, telles que Scale AI, Appen, Lionbridge AI, etc., non seulement en utilisant des ensembles de données open source et des robots d'exploration Internet pour obtenir des données, mais s'engage également à obtenir des données plus diversifiées et de haute qualité
Les méthodes d'étiquetage de ces entreprises et institutions de données sont plus « automatisées » et « intelligentes » que leurs homologues nationales
Par exemple, Scale AI utilise une technologie appelée Snorkel, qui est une méthode d'étiquetage des données basée sur un apprentissage faiblement supervisé qui peut générer des étiquettes de haute qualité à partir de plusieurs sources de données imprécises.
 Dans le même temps, Snorkel peut également utiliser une variété de signaux tels que des règles, des modèles et des bases de connaissances pour ajouter des étiquettes aux données, sans avoir besoin d'étiqueter manuellement chaque point de données directement. Cela peut réduire considérablement le coût et la durée de l’annotation manuelle.
Dans le même temps, Snorkel peut également utiliser une variété de signaux tels que des règles, des modèles et des bases de connaissances pour ajouter des étiquettes aux données, sans avoir besoin d'étiqueter manuellement chaque point de données directement. Cela peut réduire considérablement le coût et la durée de l’annotation manuelle.
Avec la réduction du coût de l'annotation des données et le cycle raccourci, ces sociétés de données dotées d'avantages concurrentiels peuvent choisir des subdivisions de grande valeur, difficiles et à seuil élevé, telles que la conduite autonome, les grands modèles de langage, les données synthétiques, etc., pour continuellement améliorer sa propre compétitivité de base et ses avantages différenciés
 De cette manière, le dilemme du passager clandestin selon lequel « les premiers arrivés souffriront » a également été éliminé par de fortes barrières techniques et industrielles.
De cette manière, le dilemme du passager clandestin selon lequel « les premiers arrivés souffriront » a également été éliminé par de fortes barrières techniques et industrielles.
On peut voir que la technologie d'étiquetage automatique IA éliminera réellement uniquement les entreprises d'étiquetage qui utilisent encore un étiquetage purement manuel.
Bien que l'annotation de données ressemble à une industrie « à forte intensité de main-d'œuvre », une fois que vous aurez approfondi les détails, vous constaterez que la recherche de données de haute qualité n'est pas une tâche facile. Représentée par Scale AI, la licorne de l'annotation de données à l'étranger, Scale AI utilise non seulement des ressources humaines bon marché d'Afrique et d'ailleurs, mais recrute également des dizaines de docteurs pour traiter des données professionnelles dans divers secteurs.

La plus grande valeur que Scale AI apporte aux grandes entreprises modèles telles qu'OpenAI est la qualité de l'annotation des données
Afin de garantir au maximum la qualité des données, en plus de l'utilisation de l'annotation assistée par l'IA mentionnée ci-dessus, Une autre innovation majeure de Scale AI est une plateforme de données unifiée.
Ces plateformes incluent Scale Audit, Scale Analytics, ScaleData Quality, etc. Grâce à ces plateformes, les clients peuvent surveiller et analyser divers indicateurs du processus d'annotation, vérifier et optimiser les données d'annotation et évaluer l'exactitude, la cohérence et l'exhaustivité de l'annotation.
On peut dire que de tels outils et processus standardisés et unifiés sont devenus un facteur clé pour distinguer les "usines de chaîne de montage" et les "ateliers faits à la main" dans les entreprises d'étiquetage.
À cet égard, la plupart des sociétés d'annotation nationales utilisent encore la « révision manuelle » pour examiner la qualité de l'annotation des données. Seuls quelques géants tels que Baidu ont introduit des outils de gestion et d'évaluation plus avancés, tels que la plateforme de services de données intelligentes EasyData.
S'il n'existe pas d'outils spécialisés pour surveiller et analyser les résultats et les indicateurs des annotations, alors en termes d'examen des données clés, le contrôle de la qualité des données ne peut s'appuyer que sur une expérience manuelle. Cette méthode ne peut encore atteindre qu'un niveau de type atelier
.
Par conséquent, de plus en plus d'entreprises chinoises, telles que Baidu, My Neighbour Totoro Data, etc., commencent à utiliser les technologies d'apprentissage automatique et d'intelligence artificielle pour améliorer l'efficacité et la qualité de l'annotation des données et réaliser un modèle de collaboration homme-machine
De ce point de vue, l'émergence de l'étiquetage par intelligence artificielle ne signifie pas la fin des entreprises d'étiquetage nationales, mais la fin des méthodes d'étiquetage traditionnelles inefficaces, bon marché et à forte intensité de main d'œuvre, dépourvues de contenu technique
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment commenter Deepseek
Feb 19, 2025 pm 05:42 PM
Comment commenter Deepseek
Feb 19, 2025 pm 05:42 PM
Deepseek est un puissant outil de récupération d'informations. .
 Comment rechercher Deepseek
Feb 19, 2025 pm 05:39 PM
Comment rechercher Deepseek
Feb 19, 2025 pm 05:39 PM
Deepseek est un moteur de recherche propriétaire qui ne recherche que dans une base de données ou un système spécifique, plus rapide et plus précis. Lorsque vous l'utilisez, il est conseillé aux utilisateurs de lire le document, d'essayer différentes stratégies de recherche, de demander de l'aide et des commentaires sur l'expérience utilisateur afin de tirer le meilleur parti de leurs avantages.
 Sesame Open Door Exchange Page d'enregistrement de page Enregistrement Gate Trading App The Registration Site Web
Feb 28, 2025 am 11:06 AM
Sesame Open Door Exchange Page d'enregistrement de page Enregistrement Gate Trading App The Registration Site Web
Feb 28, 2025 am 11:06 AM
Cet article présente le processus d'enregistrement de la version Web de Sesame Open Exchange (GATE.IO) et l'application Gate Trading en détail. Qu'il s'agisse de l'enregistrement Web ou de l'enregistrement de l'application, vous devez visiter le site Web officiel ou l'App Store pour télécharger l'application authentique, puis remplir le nom d'utilisateur, le mot de passe, l'e-mail, le numéro de téléphone mobile et d'autres informations et terminer la vérification des e-mails ou du téléphone mobile.
 Pourquoi le lien d'échange de Bybit ne peut-il pas être téléchargé directement et installé?
Feb 21, 2025 pm 10:57 PM
Pourquoi le lien d'échange de Bybit ne peut-il pas être téléchargé directement et installé?
Feb 21, 2025 pm 10:57 PM
Pourquoi le lien d'échange de Bybit ne peut-il pas être téléchargé directement et installé? Bybit est un échange de crypto-monnaie qui fournit des services de trading aux utilisateurs. Les applications mobiles de l'échange ne peuvent pas être téléchargées directement via AppStore ou GooglePlay pour les raisons suivantes: 1. La politique de l'App Store empêche Apple et Google d'avoir des exigences strictes sur les types d'applications autorisées dans l'App Store. Les demandes d'échange de crypto-monnaie ne répondent souvent pas à ces exigences car elles impliquent des services financiers et nécessitent des réglementations et des normes de sécurité spécifiques. 2. Conformité des lois et réglementations Dans de nombreux pays, les activités liées aux transactions de crypto-monnaie sont réglementées ou restreintes. Pour se conformer à ces réglementations, l'application ByBit ne peut être utilisée que via des sites Web officiels ou d'autres canaux autorisés
 Sesame Open Door Trading Platform Download Version mobile Gateio Trading Plateforme de téléchargement Adresse de téléchargement
Feb 28, 2025 am 10:51 AM
Sesame Open Door Trading Platform Download Version mobile Gateio Trading Plateforme de téléchargement Adresse de téléchargement
Feb 28, 2025 am 10:51 AM
Il est crucial de choisir un canal formel pour télécharger l'application et d'assurer la sécurité de votre compte.
 Top 10 recommandé pour l'application de trading d'actifs numériques crypto (2025 Global Ranking)
Mar 18, 2025 pm 12:15 PM
Top 10 recommandé pour l'application de trading d'actifs numériques crypto (2025 Global Ranking)
Mar 18, 2025 pm 12:15 PM
Cet article recommande les dix principales plates-formes de trading de crypto-monnaie qui méritent d'être prêtées, notamment Binance, Okx, Gate.io, Bitflyer, Kucoin, Bybit, Coinbase Pro, Kraken, Bydfi et Xbit décentralisées. Ces plateformes ont leurs propres avantages en termes de quantité de devises de transaction, de type de transaction, de sécurité, de conformité et de fonctionnalités spéciales. Le choix d'une plate-forme appropriée nécessite une considération complète en fonction de votre propre expérience de trading, de votre tolérance au risque et de vos préférences d'investissement. J'espère que cet article vous aide à trouver le meilleur costume pour vous-même
 Sesame Open Door Exchange Page Web Login Dernière version GATEIO Entrée du site officiel
Mar 04, 2025 pm 11:48 PM
Sesame Open Door Exchange Page Web Login Dernière version GATEIO Entrée du site officiel
Mar 04, 2025 pm 11:48 PM
Une introduction détaillée à l'opération de connexion de la version Web Sesame Open Exchange, y compris les étapes de connexion et le processus de récupération de mot de passe.
 Binance Binance Site officiel Dernière version Portail de connexion
Feb 21, 2025 pm 05:42 PM
Binance Binance Site officiel Dernière version Portail de connexion
Feb 21, 2025 pm 05:42 PM
Pour accéder à la dernière version du portail de connexion du site Web de Binance, suivez simplement ces étapes simples. Accédez au site officiel et cliquez sur le bouton "Connectez-vous" dans le coin supérieur droit. Sélectionnez votre méthode de connexion existante. Entrez votre numéro de mobile ou votre mot de passe enregistré et votre mot de passe et complétez l'authentification (telles que le code de vérification mobile ou Google Authenticator). Après une vérification réussie, vous pouvez accéder à la dernière version du portail de connexion du site Web officiel de Binance.
