
 Périphériques technologiques
IA
ReLU remplace softmax dans Visual Transformer, la nouvelle astuce de DeepMind réduit rapidement les coûts
Périphériques technologiques
IA
ReLU remplace softmax dans Visual Transformer, la nouvelle astuce de DeepMind réduit rapidement les coûts
ReLU remplace softmax dans Visual Transformer, la nouvelle astuce de DeepMind réduit rapidement les coûts

L'architecture Transformer a été largement utilisée dans le domaine de l'apprentissage automatique moderne. Le point clé est de se concentrer sur l’un des composants principaux du transformateur, qui contient un softmax, utilisé pour générer une distribution de probabilité de jetons. Softmax a un coût plus élevé car il effectue des calculs exponentiels et additionne les longueurs de séquence, ce qui rend la parallélisation difficile à réaliser.
Google DeepMind a eu une nouvelle idée : Remplacez l'opération softmax par une nouvelle méthode qui ne génère pas nécessairement une distribution de probabilité. Ils ont également observé que l'utilisation de ReLU divisée par la longueur de la séquence peut approcher ou rivaliser avec le softmax traditionnel lorsqu'elle est utilisée avec un transformateur visuel.

Lien papier : https://arxiv.org/abs/2309.08586
Ce résultat apporte de nouvelles solutions à la parallélisation, car l'objectif de ReLU est de se concentrer sur la parallélisation de la dimension de longueur de séquence et nécessite moins d'opérations de collecte que la méthode traditionnelle
méthode
Le but est de se concentrer
Le but est de se concentrer sur le rôle de Convertir les requêtes, clés et valeurs à d dimensions {q_i, k_i, v_i} à travers un processus en deux étapes
Dans la première étape, le point clé est de se concentrer sur les poids 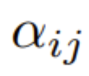 :
:
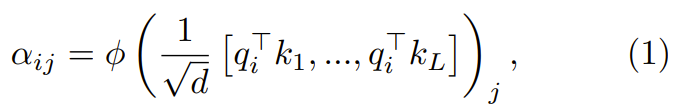
où ϕ est généralement softmax.
La prochaine étape de son utilisation consiste à se concentrer sur la pondération pour calculer le résultat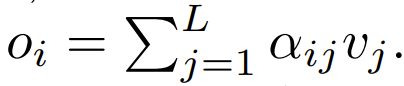 Cet article explore l'utilisation de calculs ponctuels comme alternative à ϕ.
Cet article explore l'utilisation de calculs ponctuels comme alternative à ϕ.
ReLU Le but est de se concentrer sur
DeepMind a observé que pour ϕ = softmax in 1, 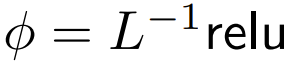 est une meilleure alternative. Ils utiliseront
est une meilleure alternative. Ils utiliseront 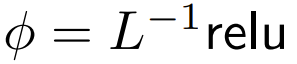 Le but est de se concentrer appelé ReLU Le but est de se concentrer.
Le but est de se concentrer appelé ReLU Le but est de se concentrer.
L'accent étendu point par point consiste à se concentrer sur
Les chercheurs ont également exploré expérimentalement un plus large éventail d'options 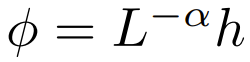 , où α ∈ [0, 1] et h ∈ {relu , relu², gelu,softplus, identité,relu6,sigmoïde}.
, où α ∈ [0, 1] et h ∈ {relu , relu², gelu,softplus, identité,relu6,sigmoïde}.
Ce qui doit être réécrit est : Extension de la longueur de séquence
Ils ont également constaté que la précision peut être améliorée si elle est étendue à l'aide d'un projet impliquant la longueur de séquence L. Les travaux de recherche antérieurs visant à supprimer softmax n'utilisaient pas ce schéma de mise à l'échelle
Parmi les Transformers qui utilisent actuellement softmax et se concentrent sur la conception, il y a 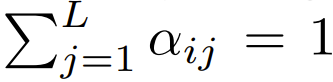 , ce qui signifie
, ce qui signifie 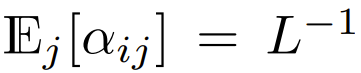 Bien qu'il soit peu probable que ce soit une condition nécessaire,
Bien qu'il soit peu probable que ce soit une condition nécessaire, 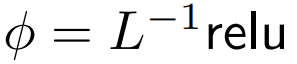 peut garantir que lors de l'initialisation
peut garantir que lors de l'initialisation 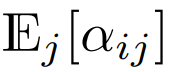 La complexité de est
La complexité de est 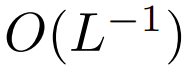 , Le maintien de cette condition peut réduire la nécessité de modifier d'autres hyperparamètres lors du remplacement de softmax.
, Le maintien de cette condition peut réduire la nécessité de modifier d'autres hyperparamètres lors du remplacement de softmax.
Lors de l'initialisation, les éléments de q et k sont O (1), donc 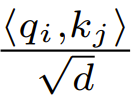 sera également O (1). Les fonctions d'activation comme ReLU maintiennent O (1), donc un facteur de
sera également O (1). Les fonctions d'activation comme ReLU maintiennent O (1), donc un facteur de 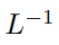 est nécessaire pour que la complexité de
est nécessaire pour que la complexité de 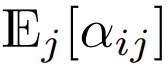 soit
soit 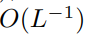 .
.
Expériences et résultats
Principaux résultats
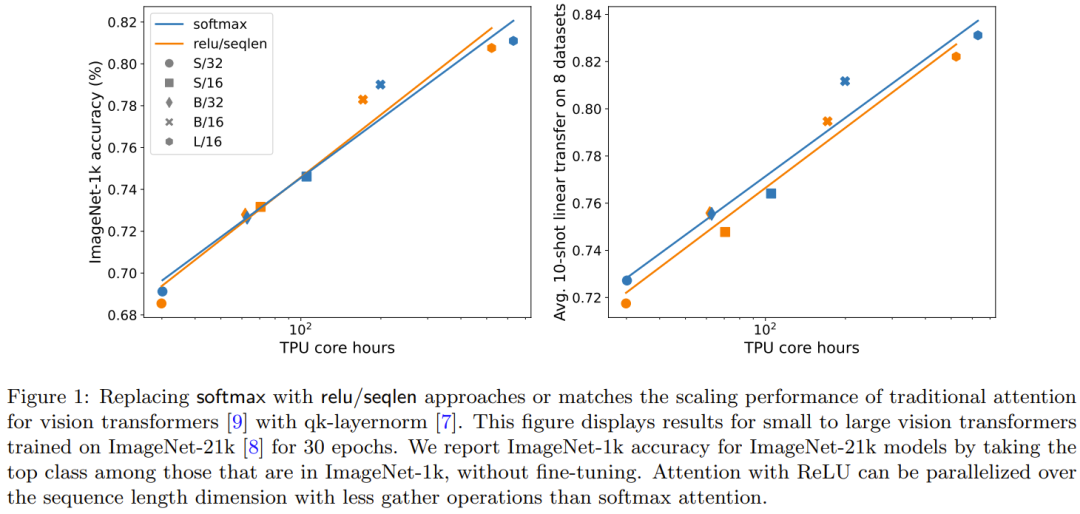
La figure 1 illustre la tendance à la mise à l'échelle de la concentration ReLU sur la concentration et de la concentration softmax sur la concentration sur la formation ImageNet-21k. L'axe des X montre le temps de calcul total du noyau requis pour l'expérience en heures. Un gros avantage de ReLU est qu'il peut être parallélisé dans la dimension de longueur de séquence, nécessitant moins d'opérations de collecte que softmax.
Le contenu qui doit être réécrit est : l'effet de l'expansion de la longueur de la séquence
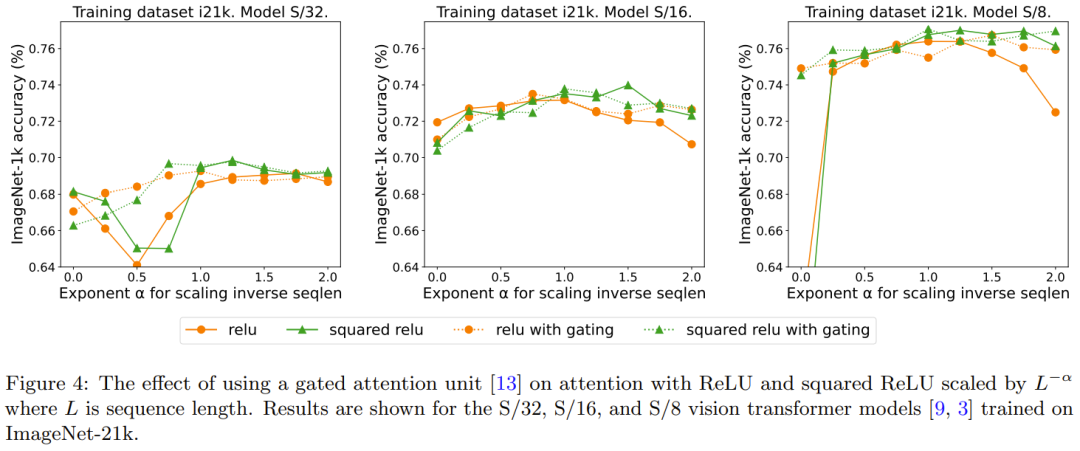
La figure 2 compare le contenu qui doit être réécrit : la méthode d'expansion de la longueur de la séquence et d'autres méthodes Résultats d'une alternative ponctuelle à softmax. Plus précisément, il s'agit d'utiliser relu, relu², gelu, softplus, Identity et d'autres méthodes pour remplacer softmax. L'axe X est α. L'axe Y correspond à la précision des modèles Vision Transformer S/32, S/16 et S/8. Les meilleurs résultats sont généralement obtenus lorsque α est proche de 1. Puisqu’il n’existe pas de non-linéarité optimale claire, ils ont utilisé ReLU dans leurs expériences principales car il est plus rapide.
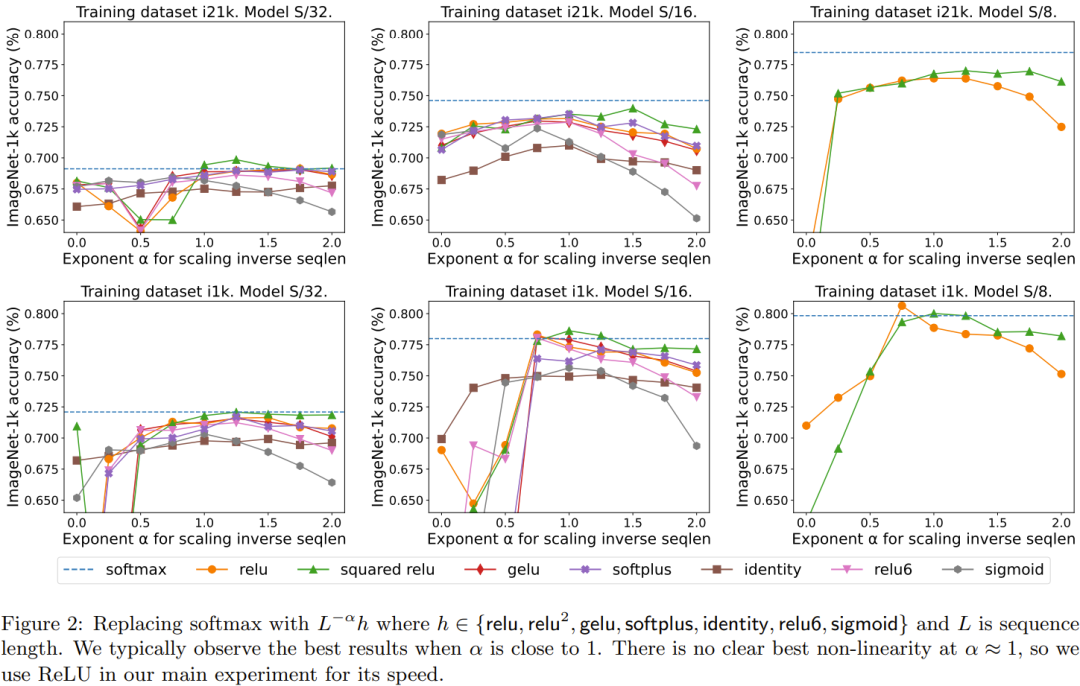
L'effet de qk-layernorm peut être reformulé comme suit :
qk-layernorm a été utilisé dans l'expérience principale, où la requête et la clé seront calculées. concentrez-vous sur les poids avant de passer par LayerNorm. DeepMind indique que la raison de l'utilisation de qk-layernorm par défaut est qu'il est nécessaire d'éviter l'instabilité lors de la mise à l'échelle de la taille des modèles. La figure 3 montre l'impact de la suppression de qk-layernorm. Ce résultat indique que qk-layernorm a peu d’impact sur ces modèles, mais la situation peut être différente lorsque la taille du modèle devient plus grande.
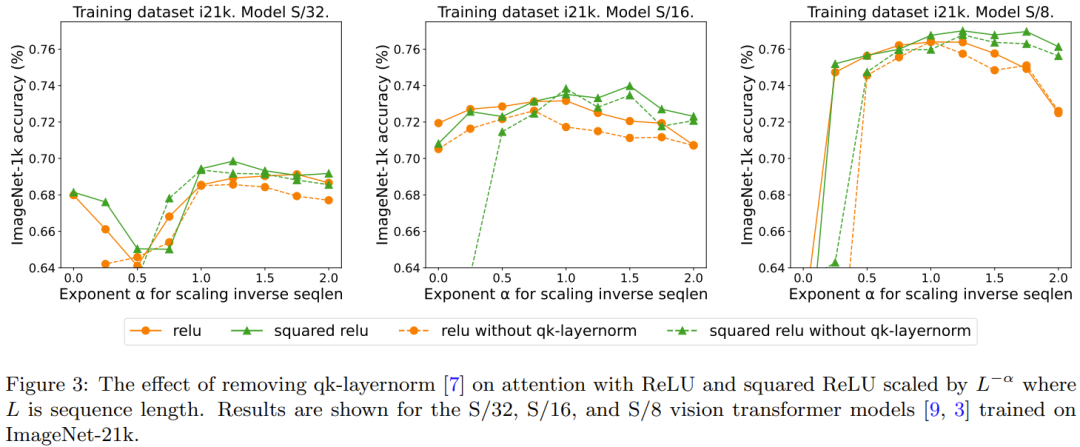
Redescription : Ajout d'un effet aux portes
Des recherches précédentes sur la suppression de softmax ont adopté la méthode d'ajout d'une unité de déclenchement, mais cette méthode ne peut pas s'adapter à la longueur de la séquence. Plus précisément, dans l'unité d'attention contrôlée, il existe une projection supplémentaire qui produit une sortie obtenue par une combinaison multiplicative élément par élément avant la projection de sortie. La figure 4 explore si la présence de portes élimine le besoin de réécrire ce qui est : une extension de la longueur de la séquence. Dans l’ensemble, DeepMind observe que la meilleure précision est obtenue avec ou sans portes en augmentant la longueur des séquences, ce qui nécessite une réécriture. Notez également que pour le modèle S/8 utilisant ReLU, ce mécanisme de déclenchement augmente le temps de base requis pour l'expérience d'environ 9,3 %.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Selon les rumeurs, Google Pixel 9 et Pixel 9 Pro bénéficieraient de Creative Assistant AI dès leur sortie
Jun 22, 2024 am 10:50 AM
Selon les rumeurs, Google Pixel 9 et Pixel 9 Pro bénéficieraient de Creative Assistant AI dès leur sortie
Jun 22, 2024 am 10:50 AM
Actuellement, quatre nouveaux smartphones Pixel devraient débarquer cet automne. Pour récapituler, la série devrait présenter les Pixel 9 et Pixel 9 Pro au lancement. Cependant, le Pixel 9 Pro sera un rival de l'iPhone 16 Pro plutôt que d'un Pixel 8 Pro (actuel
 Google AI annonce Gemini 1.5 Pro et Gemma 2 pour les développeurs
Jul 01, 2024 am 07:22 AM
Google AI annonce Gemini 1.5 Pro et Gemma 2 pour les développeurs
Jul 01, 2024 am 07:22 AM
Google AI a commencé à fournir aux développeurs un accès à des fenêtres contextuelles étendues et à des fonctionnalités économiques, à commencer par le modèle de langage large (LLM) Gemini 1.5 Pro. Auparavant disponible via une liste d'attente, la fenêtre contextuelle complète de 2 millions de jetons
 Le démontage de l'APK bêta de l'application Google révèle de nouvelles extensions à venir pour l'assistant Gemini AI
Jul 30, 2024 pm 01:06 PM
Le démontage de l'APK bêta de l'application Google révèle de nouvelles extensions à venir pour l'assistant Gemini AI
Jul 30, 2024 pm 01:06 PM
L'assistant IA de Google, Gemini, devrait devenir encore plus performant si le démontage de l'APK de la dernière mise à jour (v15.29.34.29 bêta) doit être envisagé. Le nouvel assistant IA du géant technologique pourrait bénéficier de plusieurs nouvelles extensions. Ces extensions seront
 Google Tensor G4 du Pixel 9 Pro XL est en retard sur Tensor G2 en Genshin Impact
Aug 24, 2024 am 06:43 AM
Google Tensor G4 du Pixel 9 Pro XL est en retard sur Tensor G2 en Genshin Impact
Aug 24, 2024 am 06:43 AM
Google a récemment répondu aux problèmes de performances concernant le Tensor G4 de la gamme Pixel 9. La société a déclaré que le SoC n'était pas conçu pour battre les benchmarks. Au lieu de cela, l'équipe s'est concentrée sur sa performance dans les domaines où Google souhaite que le c
 Les smartphones Google Pixel 9 ne seront pas lancés avec Android 15 malgré un engagement de mise à jour de sept ans
Aug 01, 2024 pm 02:56 PM
Les smartphones Google Pixel 9 ne seront pas lancés avec Android 15 malgré un engagement de mise à jour de sept ans
Aug 01, 2024 pm 02:56 PM
La série Pixel 9 est presque là, sa sortie étant prévue pour le 13 août. D'après des rumeurs récentes, les Pixel 9, Pixel 9 Pro et Pixel 9 Pro XL refléteront les Pixel 8 et Pixel 8 Pro (749 $ sur Amazon) en commençant par 128 Go de stockage.
 Google Pixel 9 Pro XL est testé avec le mode bureau
Aug 29, 2024 pm 01:09 PM
Google Pixel 9 Pro XL est testé avec le mode bureau
Aug 29, 2024 pm 01:09 PM
Google a introduit le mode alternatif DisplayPort avec la série Pixel 8, et il est présent sur la gamme Pixel 9 récemment lancée. Bien qu'il soit principalement là pour vous permettre de refléter l'affichage de votre smartphone avec un écran connecté, vous pouvez également l'utiliser pour un ordinateur de bureau.
 Le nouveau mode de bureau Google Pixel présenté dans une nouvelle vidéo comme alternative possible à Motorola Ready For et Samsung DeX
Aug 08, 2024 pm 03:05 PM
Le nouveau mode de bureau Google Pixel présenté dans une nouvelle vidéo comme alternative possible à Motorola Ready For et Samsung DeX
Aug 08, 2024 pm 03:05 PM
Quelques mois se sont écoulés depuis qu'Android Authority a démontré un nouveau mode de bureau Android que Google avait caché dans Android 14 QPR3 Beta 2.1. Arrivant juste après Google, il ajoute la prise en charge du mode Alt DisplayPort pour les Pixel 8 et Pixel 8.
 Google ouvre AI Test Kitchen & Imagen 3 à la plupart des utilisateurs
Sep 12, 2024 pm 12:17 PM
Google ouvre AI Test Kitchen & Imagen 3 à la plupart des utilisateurs
Sep 12, 2024 pm 12:17 PM
AI Test Kitchen de Google, qui comprend une suite d'outils de conception d'IA avec lesquels les utilisateurs peuvent jouer, est désormais ouvert aux utilisateurs dans plus de 100 pays à travers le monde. Cette décision marque la première fois que de nombreuses personnes dans le monde pourront utiliser Imagen 3, Google
