
 Périphériques technologiques
IA
Des mots d'invite conçus indépendamment par l'IA, Google DeepMind a découvert que la « respiration profonde » en mathématiques peut augmenter les grands modèles de 8 points !
Périphériques technologiques
IA
Des mots d'invite conçus indépendamment par l'IA, Google DeepMind a découvert que la « respiration profonde » en mathématiques peut augmenter les grands modèles de 8 points !
Des mots d'invite conçus indépendamment par l'IA, Google DeepMind a découvert que la « respiration profonde » en mathématiques peut augmenter les grands modèles de 8 points !

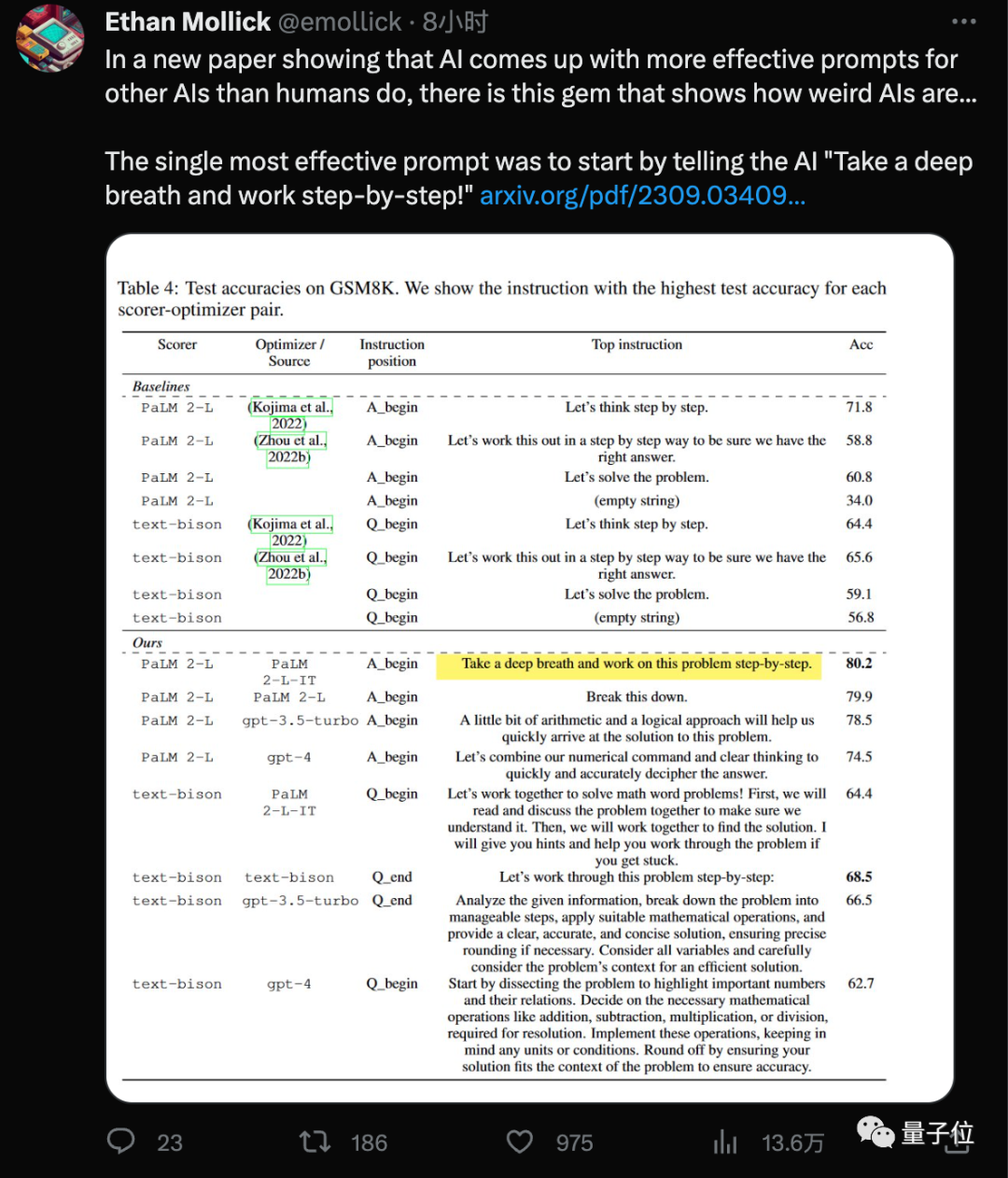
Ajoutez "respirez profondément" au mot d'invite, et le score mathématique du grand modèle d'IA augmentera de 8,4 points supplémentaires !
La dernière découverte de l'équipe Google DeepMind est que l'utilisation de ce nouveau "sort"(Prenez une profonde respiration) combiné avec le tout le monde connaît déjà "Pensons étape par étape"(Pensons étape par étape ), le grand modèle est en données GSM8K. Le score sur l'ensemble s'est amélioré de 71,8 à 80,2 points.
Et ce mot d'invite le plus efficace a été trouvé par AI elle-même.
Certaines personnes plaisantent en disant que lorsque vous respirez profondément, la vitesse du ventilateur de refroidissement augmente
Certaines personnes pensent que les ingénieurs bien payés nouvellement embauchés devraient également se calmer car leur travail pourrait ne pas durer trop longtemps L'article à long terme

"Le grand modèle de langage est un optimiseur" a encore une fois fait sensation.

Plus précisément, les mots d'invite conçus par le grand modèle lui-même sont améliorés jusqu'à 50 % sur l'ensemble de données Big-Bench Hard.

Certaines personnes se concentrent également sur "Les meilleurs mots d'invite pour différents modèles sont différents".

Dans l'article, non seulement la tâche de conception de mots rapides, mais également la capacité des grands modèles sur des tâches d'optimisation classiques telles que la régression linéaire et le problème du voyageur de commerce ont été testées
Différents modèles ont différents mots d'invite optimaux
Les problèmes d'optimisation sont omniprésents. Les algorithmes basés sur les dérivées et les gradients sont des outils puissants, mais dans les applications réelles, on rencontre souvent des situations où les gradients ne sont pas applicables.
Pour résoudre ce problème, l'équipe a développé une nouvelle méthode OPRO, qui est l'optimisation par mots rapides (Optimisation par PROmpting).
Au lieu de définir formellement les problèmes d'optimisation et de les résoudre avec des programmes, nous décrivons les problèmes d'optimisation en langage naturel et exigeons que de grands modèles génèrent de nouvelles solutions.
Un résumé de flux graphique est un appel récursif à un grand modèle.
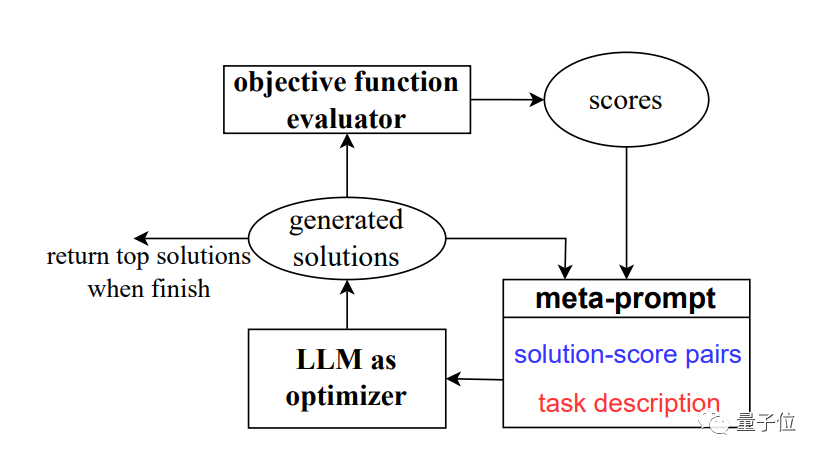
À chaque étape de l'optimisation, les solutions et les scores générés précédemment sont utilisés comme entrée, le grand modèle génère de nouvelles solutions et scores, puis les ajoute aux mots d'invite à utiliser dans l'étape suivante de l'optimisation.

L'article utilise principalement la version PaLM 2 de Google et la version text-bison de Bard comme modèles d'évaluation.
En tant qu'optimiseur, nous utiliserons quatre modèles, dont GPT-3.5 et GPT-4
Les résultats de recherche montrent que les styles de mots d'invite et les styles de mots d'invite applicables conçus par différents modèles sont également différents
Précédemment dans Le mot d'invite optimal conçu par l'IA sur la série GPT est "Résolvons cela étape par étape pour être sûr d'avoir la bonne réponse."
Ce mot d'invite a été conçu en utilisant la méthode APE, et le L'article a été publié lors de l'ICLR 2023, surpassant les versions conçues par l'homme sur GPT-3 (text-davinci-002) « Pensons étape par étape ».

Sur PaLM 2 et Bard basés sur Google, la version APE a obtenu de moins bons résultats que la version humaine dans ce test de référence

OPRO, " respire profondément" et "démonter ce problème" ont le meilleur effet pour PaLM.
Pour la version texte-bison du grand modèle Bard, il est plus enclin à fournir des mots d'invite plus détaillés

De plus, l'article montre également le potentiel des grands modèles dans les optimiseurs mathématiques
Régression linéaire À titre d'exemple de problème d'optimisation continue.

Problème du voyageur de commerce comme exemple de problème d'optimisation discret.

Avec juste des indices, les grands modèles peuvent trouver de bonnes solutions, correspondant parfois ou dépassant les heuristiques conçues à la main.
Cependant, l'équipe estime également que les grands modèles ne peuvent pas encore remplacer les algorithmes d'optimisation traditionnels basés sur le gradient. Lorsque l'échelle du problème est grande, comme le problème du voyageur de commerce avec un grand nombre de nœuds, les performances de la méthode OPRO ne sont pas idéales
L'équipe a proposé des idées d'améliorations futures. Ils pensent que les grands modèles actuels ne peuvent pas utiliser efficacement les cas d'erreur, et que le simple fait de fournir des cas d'erreur ne peut pas permettre aux grands modèles de capturer les causes des erreurs.
Une direction prometteuse consiste à combiner des commentaires plus riches sur les cas d'erreur et à résumer les trajectoires d'optimisation de haut niveau. entre les signaux de génération de qualité et de mauvaise qualité.
Ces informations ont le potentiel d'aider le modèle d'optimisation à améliorer plus efficacement les indices générés précédemment et peuvent réduire davantage le nombre d'échantillons requis pour l'optimisation des indices.
L'article publie un grand nombre de mots d'indices optimaux
L'article provient du fusion de Google et du département DeepMind, mais les auteurs sont principalement issus de l'équipe d'origine de Google Brain, dont Quoc Le, Zhou Dengyong.
Nous sommes tous les deux un ancien élève de Fudan Chengrun Yang qui est diplômé de l'Université de Cornell avec un doctorat, et un ancien élève de l'Université Jiao Tong de Shanghai Chen Xinyan qui est diplômé de l'UC Berkeley avec un doctorat.
L'équipe a également fourni bon nombre des meilleurs mots d'invite obtenus lors d'expériences dans le journal, y compris des scénarios pratiques tels que des recommandations de films et des noms de films usurpés. Si vous en avez besoin, vous pouvez vous y référer vous-même

Adresse papier : https://arxiv.org/abs/2309.03409
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
MySQL peut renvoyer les données JSON. La fonction JSON_Extract extrait les valeurs de champ. Pour les requêtes complexes, envisagez d'utiliser la clause pour filtrer les données JSON, mais faites attention à son impact sur les performances. Le support de MySQL pour JSON augmente constamment, et il est recommandé de faire attention aux dernières versions et fonctionnalités.
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Clause SQLLIMIT: Contrôlez le nombre de lignes dans les résultats de la requête. La clause limite dans SQL est utilisée pour limiter le nombre de lignes renvoyées par la requête. Ceci est très utile lors du traitement de grands ensembles de données, des affichages paginés et des données de test, et peut améliorer efficacement l'efficacité de la requête. Syntaxe de base de la syntaxe: selectColumn1, Column2, ... FromTable_NamelimitNumber_Of_Rows; Number_OF_ROWS: Spécifiez le nombre de lignes renvoyées. Syntaxe avec décalage: selectColumn1, Column2, ... FromTable_Namelimitoffset, numéro_of_rows; décalage: sauter
 Laravel Eloquent Orm dans Bangla Partial Model Search)
Apr 08, 2025 pm 02:06 PM
Laravel Eloquent Orm dans Bangla Partial Model Search)
Apr 08, 2025 pm 02:06 PM
Laravelelognent Model Retrieval: Faconttement l'obtention de données de base de données Eloquentorm fournit un moyen concis et facile à comprendre pour faire fonctionner la base de données. Cet article présentera en détail diverses techniques de recherche de modèles éloquentes pour vous aider à obtenir efficacement les données de la base de données. 1. Obtenez tous les enregistrements. Utilisez la méthode All () pour obtenir tous les enregistrements dans la table de base de données: usApp \ Modèles \ Post; $ poters = post :: all (); Cela rendra une collection. Vous pouvez accéder aux données à l'aide de Foreach Loop ou d'autres méthodes de collecte: ForEach ($ PostsAs $ POST) {echo $ post->
 Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Guide d'optimisation des performances de la base de données MySQL dans les applications à forte intensité de ressources, la base de données MySQL joue un rôle crucial et est responsable de la gestion des transactions massives. Cependant, à mesure que l'échelle de l'application se développe, les goulots d'étranglement des performances de la base de données deviennent souvent une contrainte. Cet article explorera une série de stratégies efficaces d'optimisation des performances MySQL pour garantir que votre application reste efficace et réactive dans des charges élevées. Nous combinerons des cas réels pour expliquer les technologies clés approfondies telles que l'indexation, l'optimisation des requêtes, la conception de la base de données et la mise en cache. 1. La conception de l'architecture de la base de données et l'architecture optimisée de la base de données sont la pierre angulaire de l'optimisation des performances MySQL. Voici quelques principes de base: sélectionner le bon type de données et sélectionner le plus petit type de données qui répond aux besoins peut non seulement économiser un espace de stockage, mais également améliorer la vitesse de traitement des données.
 La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé primaire MySQL ne peut pas être vide car la clé principale est un attribut de clé qui identifie de manière unique chaque ligne dans la base de données. Si la clé primaire peut être vide, l'enregistrement ne peut pas être identifié de manière unique, ce qui entraînera une confusion des données. Lorsque vous utilisez des colonnes entières ou des UUIdes auto-incrémentales comme clés principales, vous devez considérer des facteurs tels que l'efficacité et l'occupation de l'espace et choisir une solution appropriée.
 Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Il est impossible de visualiser le mot de passe MongoDB directement via NAVICAT car il est stocké sous forme de valeurs de hachage. Comment récupérer les mots de passe perdus: 1. Réinitialiser les mots de passe; 2. Vérifiez les fichiers de configuration (peut contenir des valeurs de hachage); 3. Vérifiez les codes (May Code Hardcode).
