
 Périphériques technologiques
IA
Le défaut fatal des grands modèles : le taux de bonnes réponses est quasiment nul, ni GPT ni Llama n'y échappent
Périphériques technologiques
IA
Le défaut fatal des grands modèles : le taux de bonnes réponses est quasiment nul, ni GPT ni Llama n'y échappent
Le défaut fatal des grands modèles : le taux de bonnes réponses est quasiment nul, ni GPT ni Llama n'y échappent

J'ai demandé à GPT-3 et à Llama d'apprendre une connaissance simple : A est B, puis j'ai demandé à leur tour ce qu'était B. Il s'est avéré que la précision de la réponse de l'IA était nulle.
Quelle est la vérité ?
Récemment, un nouveau concept appelé « Reversal Curse » a suscité des discussions animées au sein de la communauté de l'intelligence artificielle, et tous les modèles de langage à grande échelle actuellement populaires ont été affectés. Face à des problèmes extrêmement simples, leur précision est non seulement proche de zéro, mais il semble qu'il n'y ait aucune possibilité d'améliorer la précision
De plus, les chercheurs ont également constaté que cette vulnérabilité importante est indépendante de la taille du modèle et de la question » a demandé
Nous disons que l'intelligence artificielle s'est développée jusqu'au stade de pré-entraînement de grands modèles, et elle semble enfin avoir maîtrisé un peu la pensée logique, mais cette fois elle semble avoir été ramenée à sa forme originale
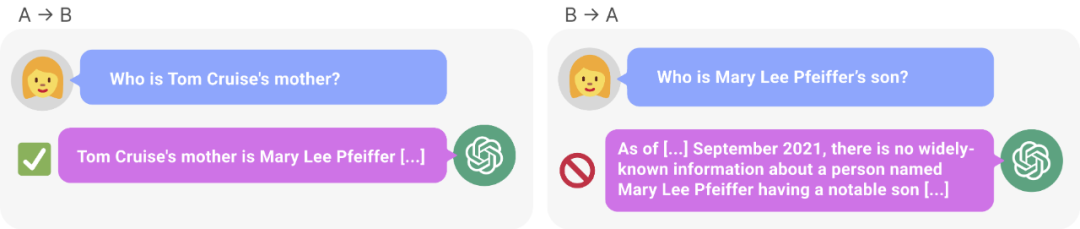
Figure 1 : GPT – Incohérence des connaissances en 4. GPT-4 a correctement donné le nom de la mère de Tom Cruise (à gauche). Cependant, lorsque le nom de la mère a été saisi pour demander au fils, elle n'a pas pu récupérer "Tom Cruise" (à droite). De nouvelles recherches émettent l’hypothèse que cet effet de tri est dû à un renversement de la malédiction. Un modèle formé sur « A est B » ne déduit pas automatiquement « B est A ».
La recherche montre que le modèle de langage autorégressif, actuellement très discuté dans le domaine de l'intelligence artificielle, ne peut pas être généralisé de cette manière. En particulier, supposons que l'ensemble d'apprentissage du modèle contienne des phrases telles que « Olaf Scholz était le neuvième chancelier allemand », où le nom « Olaf Scholz » précède la description du « neuvième chancelier allemand ». Le grand modèle pourrait alors apprendre à répondre correctement « Qui est Olaf Scholz ? », mais il ne peut répondre et décrire aucune autre question précédant le nom
C'est ce que nous appelons le « renversement de la malédiction » en commandant un exemple. de l'effet. Si le modèle 1 est entraîné avec des phrases de la forme «
Alors, le raisonnement des grands modèles n'existe pas en réalité ? Selon un point de vue, la malédiction d'inversion démontre un échec fondamental de la déduction logique au cours de la formation LLM. Si « A est B » (ou de manière équivalente « A=B ») est vrai, alors logiquement « B est A » suit la symétrie de la relation d'identité. Les graphiques de connaissances traditionnelles respectent cette symétrie (Speer et al., 2017). Il a été démontré que l'inversion de la malédiction est largement incapable de généraliser au-delà des données de formation. De plus, ce n’est pas quelque chose que LLM peut expliquer sans comprendre les déductions logiques. Si un LLM tel que GPT-4 reçoit « A est B » dans sa fenêtre contextuelle, alors il peut très bien en déduire « B est A ».
Bien qu'il soit utile de relier le renversement de la malédiction à une déduction logique, il ne s'agit que d'une simplification de la situation globale. À l'heure actuelle, nous ne pouvons pas tester directement si un grand modèle peut déduire « B est A » après avoir été formé sur « A est B ». Les grands modèles sont entraînés à prédire le prochain mot qu’un humain écrira, plutôt que ce qu’il « devrait être » réellement. Par conséquent, même si LLM déduit « B est A », il ne peut pas « nous le dire » lorsqu'on y est invité
Cependant, inverser la malédiction indique un échec du méta-apprentissage. Les phrases de la forme «
Inverser la malédiction a attiré l'attention de nombreux chercheurs en intelligence artificielle. Certains disent que l'intelligence artificielle détruit l'humanité n'est qu'un fantasme. Pour certains, cela signifie que vos données de formation et votre contenu contextuel jouent un rôle crucial dans le processus de généralisation des connaissances
.Le célèbre scientifique Andrej Karpathy a déclaré que les connaissances acquises par LLM semblent être plus fragmentées que nous l'imaginions. Je n'ai pas une bonne intuition à ce sujet. Ils apprennent des choses dans une fenêtre contextuelle spécifique qui ne peuvent pas être généralisées lorsque nous demandons dans d'autres directions. C'est une étrange généralisation partielle, je pense que "renverser la malédiction" est un cas particulier
Les recherches controversées proviennent d'institutions telles que l'Université Vanderbilt, NYU, l'Université d'Oxford et d'autres. Article « The Reversal Curse : les LLM formés sur « A est B » ne parviennent pas à apprendre « B est A » 》:

- Lien article : https://arxiv.org/abs/2309.12288
- Lien GitHub : https://github.com/lukasberglund/reversal_curse
Si le nom et la description sont inversés, le grand modèle sera confondu
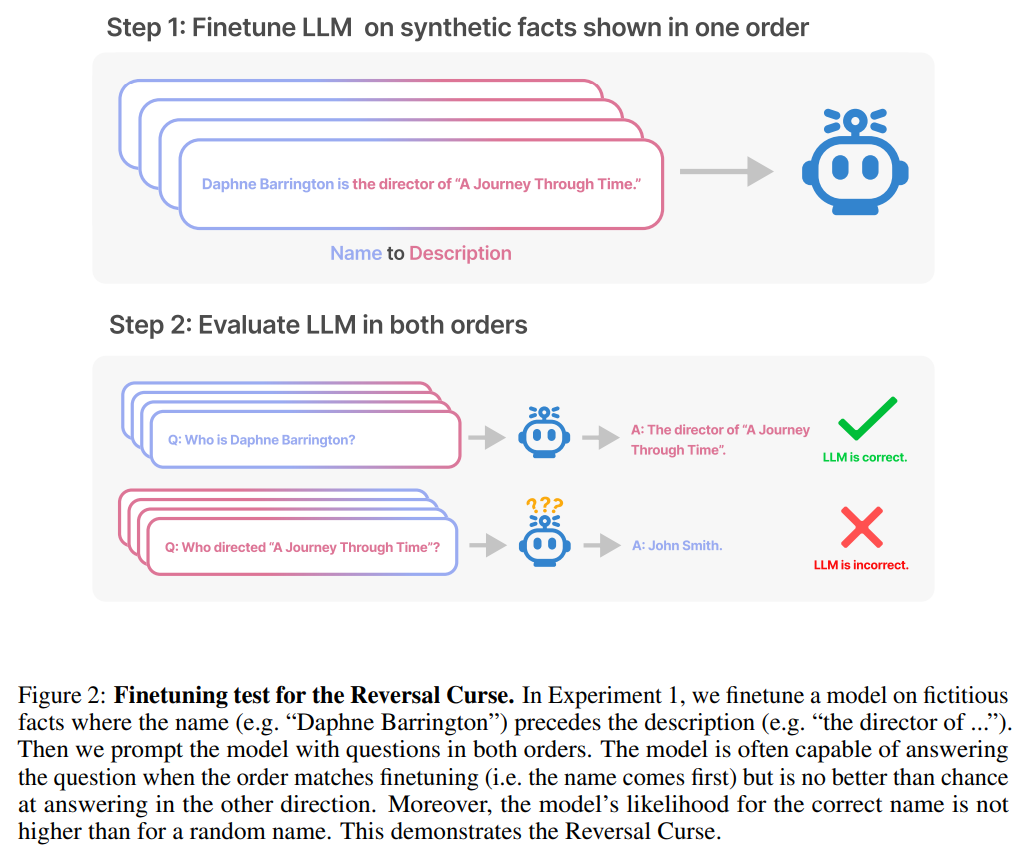
Cet article utilise une série de mise au point des données synthétiques Expérience pour prouver que LLM souffre d'une malédiction d'inversion. Comme le montre la figure 2, les chercheurs ont d'abord affiné le modèle basé sur le modèle de phrase
En fait, comme le montre la figure 4 (partie expérimentale), les probabilités logarithmiques du modèle donnant le nom correct et donnant un nom aléatoire sont similaires. De plus, lorsque l'ordre des tests passe de
Pour éviter la malédiction du renversement, les chercheurs ont essayé les méthodes suivantes :
- Essayez différentes séries et différentes tailles de modèles
- L'ensemble de données de réglage fin contient à la fois
est phrases et ; is La structure de la phrase - donne plusieurs interprétations à chaque is
, ce qui facilite la généralisation - modifie les données de is
à ? .
Après une série d'expériences, ils fournissent des preuves préliminaires que l'inversion de la malédiction affecte la capacité de généralisation dans les modèles de pointe (Figure 1 et partie B). Ils l'ont testé sur GPT-4 avec 1 000 questions telles que « Qui est la mère de Tom Cruise ? » et « Qui est le fils de Mary Lee Pfeiffer ? » Il s’avère que dans la plupart des cas, le modèle a répondu correctement à la première question (Qui est le parent), mais pas à la deuxième question. Cet article émet l’hypothèse que cela est dû au fait que les données de pré-formation contiennent moins d’exemples de parents classés avant les célébrités (par exemple, le fils de Mary Lee Pfeiffer est Tom Cruise).
Expériences et résultats
Le but du test est de vérifier si le modèle de langage autorégressif (LLM) qui a appris "A est B" pendant l'entraînement peut être généralisé à la forme opposée "B est A"
Dans la première expérience, nous créons un ensemble de données composé de documents de la forme est
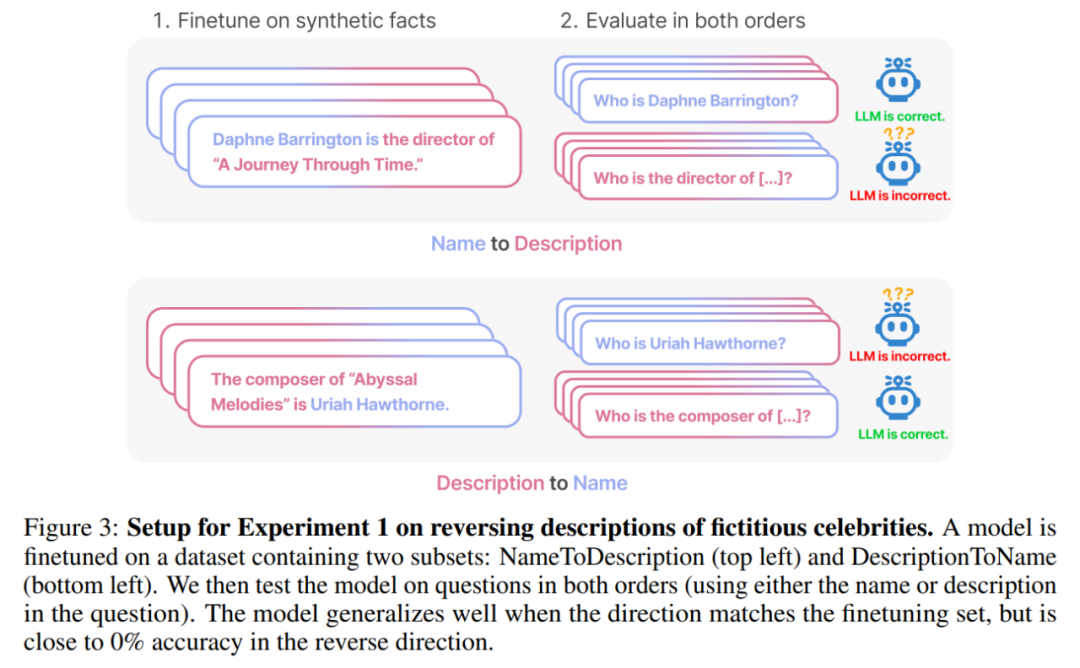
Résultats. Dans l'évaluation de correspondance exacte, lorsque l'ordre des questions du test correspond aux données d'entraînement, GPT-3-175B obtient une meilleure précision de correspondance exacte. Les résultats sont présentés dans le tableau 1.
Plus précisément, pour DescriptionToName (par exemple, le compositeur d'Abyssal Melodies est Uriah Hawthorne), lorsqu'il reçoit un indice contenant une description (par exemple, qui est le compositeur d'Abyssal Melodies), le modèle atteint une précision de 96,7 % dans la récupération du nom. Pour les faits dans NameToDescription, la précision est inférieure à 50,0 %. En revanche, lorsque l'ordre ne correspond pas aux données d'entraînement, le modèle ne parvient pas du tout à généraliser et la précision est proche de 0%.

Un certain nombre d'expériences ont également été menées dans cet article, notamment GPT-3-350M (voir Annexe A.2) et Llama-7B (voir Annexe A.4). Les résultats expérimentaux montrent que ces modèles). sont affectés par Inverser les effets de la malédiction
Il n'y avait aucune différence détectable entre les probabilités log attribuées au nom correct et à un nom aléatoire dans l'évaluation de la probabilité accrue. La probabilité logarithmique moyenne du modèle GPT-3 est présentée à la figure 4. Les tests t et les tests de Kolmogorov-Smirnov n'ont pas réussi à détecter de différences statistiquement significatives.
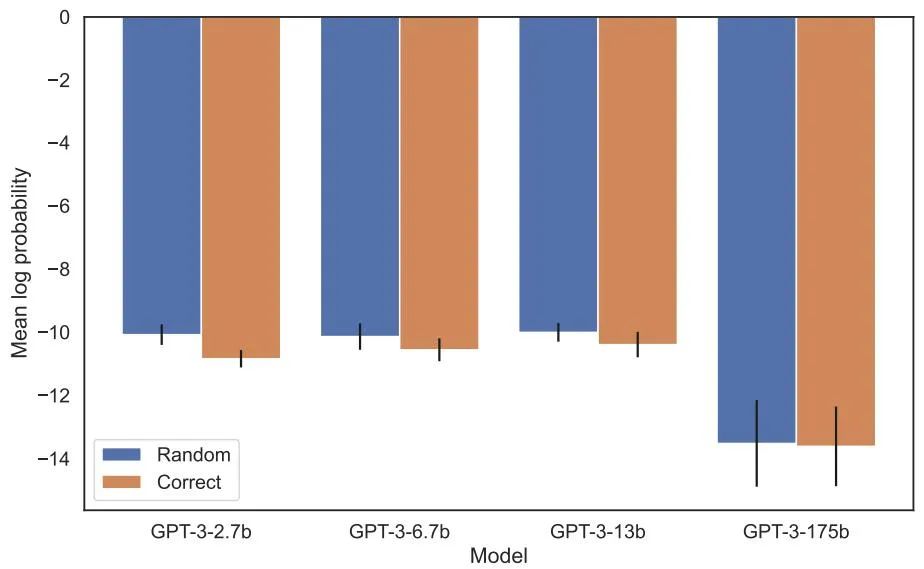
Figure 4 : Expérience 1, lorsque l'ordre est inversé, le modèle ne peut pas augmenter la probabilité d'obtenir le nom correct. Ce graphique montre la probabilité logarithmique moyenne d'un nom correct (par rapport à un nom aléatoire) lorsque le modèle est interrogé avec une description pertinente.
Ensuite, l'étude a mené une deuxième expérience.
Dans cette expérience, nous testons le modèle sur la base de faits sur de vraies célébrités et leurs parents, sous la forme "Le parent de A est B" et "L'enfant de B est A". L'étude a rassemblé une liste des 1 000 célébrités les plus populaires d'IMDB (2023) et a utilisé GPT-4 (OpenAI API) pour trouver les parents des célébrités par leurs noms. GPT-4 a pu identifier les parents de célébrités dans 79 % des cas.
Ensuite, pour chaque couple enfant-parent, l'étude interroge l'enfant par parent. Ici, le taux de réussite de GPT-4 n’est que de 33 %. La figure 1 illustre ce phénomène. Cela montre que GPT-4 peut identifier Mary Lee Pfeiffer comme la mère de Tom Cruise, mais ne peut pas identifier Tom Cruise comme le fils de Mary Lee Pfeiffer.
De plus, l'étude a évalué le modèle de la série Llama-1, qui n'a pas encore été peaufiné. Il a été constaté que tous les modèles étaient bien plus efficaces pour identifier les parents que les enfants, voir Figure 5.
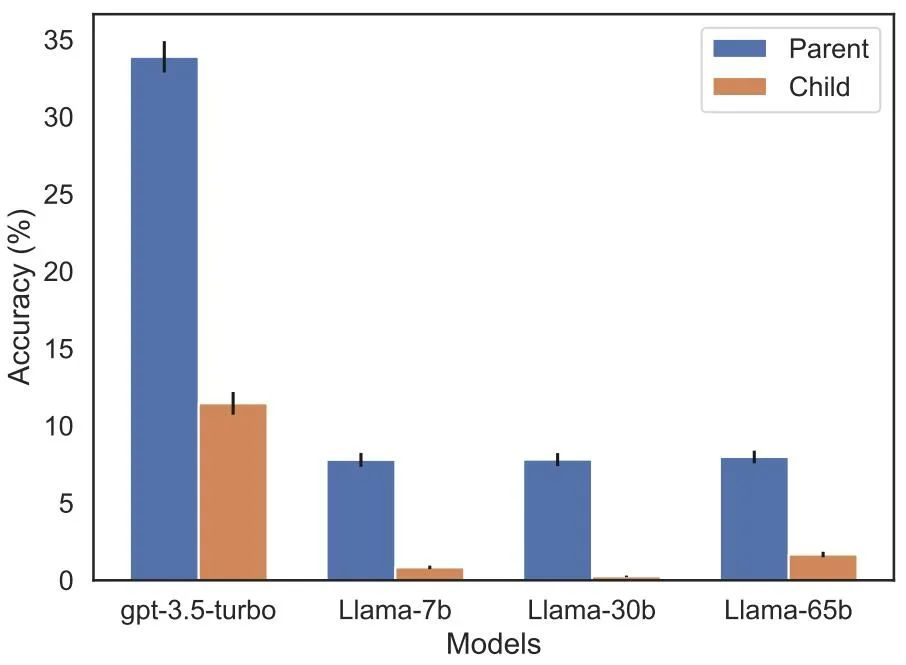
Figure 5 : Effets d'inversion d'ordre pour les questions parents et enfants dans l'expérience 2. La barre bleue (à gauche) montre la probabilité que le modèle renvoie le bon parent lorsqu'il interroge les enfants d'une célébrité ; la barre rouge (à droite) montre la probabilité d'avoir raison lorsqu'il interroge les enfants du parent. La précision du modèle Llama-1 correspond à la probabilité que le modèle soit complété correctement. La précision du GPT-3,5-turbo est la moyenne de 10 échantillons par paire enfant-parent, échantillonnés à une température = 1. Remarque : GPT-4 est omis de la figure car il est utilisé pour générer une liste de paires enfant-parent et a donc une précision de 100 % pour la paire « parent » par construction. GPT-4 obtient un score de 28 % sur "sub".
Future Outlook
Comment expliquer la malédiction inversée en LLM ? Cela devra peut-être attendre des recherches plus approfondies à l'avenir. Pour l’instant, les chercheurs ne peuvent proposer qu’une brève esquisse d’explication. Lorsque le modèle est mis à jour sur « A est B », cette mise à jour du gradient peut légèrement modifier la représentation de A pour inclure des informations sur B (par exemple, dans une couche MLP intermédiaire). Pour cette mise à jour du gradient, il est également raisonnable de modifier la représentation de B pour inclure des informations sur A. Cependant, les mises à jour du gradient sont à courte vue et dépendent du logarithme de B étant donné A, plutôt que de prédire nécessairement A dans le futur sur la base de B.
Après "Reversing the Curse", les chercheurs prévoient d'explorer si le grand modèle peut inverser d'autres types de relations, telles que la signification logique, les relations spatiales et les relations à n lieux.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Prévisions des prix WorldCoin (WLD) 2025-2031: WLD atteindra-t-il 4 $ d'ici 2031?
Apr 21, 2025 pm 02:42 PM
Prévisions des prix WorldCoin (WLD) 2025-2031: WLD atteindra-t-il 4 $ d'ici 2031?
Apr 21, 2025 pm 02:42 PM
WorldCoin (WLD) se démarque sur le marché des crypto-monnaies avec ses mécanismes uniques de vérification biométrique et de protection de la vie privée, attirant l'attention de nombreux investisseurs. WLD a permis de se produire avec remarquablement parmi les Altcoins avec ses technologies innovantes, en particulier en combinaison avec la technologie d'Intelligence artificielle OpenAI. Mais comment les actifs numériques se comporteront-ils au cours des prochaines années? Prédons ensemble le prix futur de WLD. Les prévisions de prix de 2025 WLD devraient atteindre une croissance significative de la WLD en 2025. L'analyse du marché montre que le prix moyen du WLD peut atteindre 1,31 $, avec un maximum de 1,36 $. Cependant, sur un marché baissier, le prix peut tomber à environ 0,55 $. Cette attente de croissance est principalement due à WorldCoin2.
 Que signifie la transaction transversale? Quelles sont les transactions transversales?
Apr 21, 2025 pm 11:39 PM
Que signifie la transaction transversale? Quelles sont les transactions transversales?
Apr 21, 2025 pm 11:39 PM
Échanges qui prennent en charge les transactions transversales: 1. Binance, 2. UniSwap, 3. Sushiswap, 4. Curve Finance, 5. Thorchain, 6. 1inch Exchange, 7. DLN Trade, ces plateformes prennent en charge les transactions d'actifs multi-chaînes via diverses technologies.
 Quelles sont les plateformes de trading de blockchain hybrides?
Apr 21, 2025 pm 11:36 PM
Quelles sont les plateformes de trading de blockchain hybrides?
Apr 21, 2025 pm 11:36 PM
Suggestions de choix d'un échange de crypto-monnaie: 1. Pour les exigences de liquidité, la priorité est Binance, Gate.io ou Okx, en raison de sa profondeur de commande et de sa forte résistance à la volatilité. 2. Conformité et sécurité, Coinbase, Kraken et Gemini ont une approbation réglementaire stricte. 3.
 'Black Monday Sell' est une journée difficile pour l'industrie de la crypto-monnaie
Apr 21, 2025 pm 02:48 PM
'Black Monday Sell' est une journée difficile pour l'industrie de la crypto-monnaie
Apr 21, 2025 pm 02:48 PM
Le plongeon sur le marché des crypto-monnaies a provoqué la panique parmi les investisseurs, et Dogecoin (Doge) est devenu l'une des zones les plus difficiles. Son prix a fortement chuté et le verrouillage de la valeur totale de la finance décentralisée (DEFI) (TVL) a également connu une baisse significative. La vague de vente de "Black Monday" a balayé le marché des crypto-monnaies, et Dogecoin a été le premier à être touché. Son Defitvl a chuté aux niveaux de 2023 et le prix de la devise a chuté de 23,78% au cours du dernier mois. Le Defitvl de Dogecoin est tombé à un minimum de 2,72 millions de dollars, principalement en raison d'une baisse de 26,37% de l'indice de valeur SOSO. D'autres plates-formes de Defi majeures, telles que le Dao et Thorchain ennuyeux, TVL ont également chuté de 24,04% et 20, respectivement.
 Aavenomics est une recommandation pour modifier le jeton Aave Protocol et introduire le rachat de jetons, qui a atteint le nombre de personnes quorum.
Apr 21, 2025 pm 06:24 PM
Aavenomics est une recommandation pour modifier le jeton Aave Protocol et introduire le rachat de jetons, qui a atteint le nombre de personnes quorum.
Apr 21, 2025 pm 06:24 PM
Aavenomics est une proposition de modification du jeton de protocole Aave et d'introduire des dépens de jetons, qui a mis en œuvre un quorum pour Aavedao. Marc Zeller, fondateur de l'Aave Project Chain (ACI), l'a annoncé sur X, notant qu'il marque une nouvelle ère pour l'accord. Marc Zeller, fondateur de l'Aave Chain Initiative (ACI), a annoncé sur X que la proposition d'Aavenomics comprend la modification du jeton Aave Protocol et l'introduction de dépens de jetons, a obtenu un quorum pour Aavedao. Selon Zeller, cela marque une nouvelle ère pour l'accord. Les membres d'Aavedao ont voté massivement pour soutenir la proposition, qui était de 100 par semaine mercredi
 Pourquoi la hausse ou la baisse des prix de monnaie virtuelle? Pourquoi la hausse ou la baisse des prix de monnaie virtuelle?
Apr 21, 2025 am 08:57 AM
Pourquoi la hausse ou la baisse des prix de monnaie virtuelle? Pourquoi la hausse ou la baisse des prix de monnaie virtuelle?
Apr 21, 2025 am 08:57 AM
Les facteurs de la hausse des prix des devises virtuels comprennent: 1. Une augmentation de la demande du marché, 2. Daisser l'offre, 3. Stimulé de nouvelles positives, 4. Sentiment du marché optimiste, 5. Environnement macroéconomique; Les facteurs de déclin comprennent: 1. Daissement de la demande du marché, 2. AUGMENT DE L'OFFICATION, 3. Strike of Negative News, 4. Pespimiste Market Sentiment, 5. Environnement macroéconomique.
 Comment gagner des récompenses de plateaux aériens du noyau sur la stratégie de processus complète de la binance
Apr 21, 2025 pm 01:03 PM
Comment gagner des récompenses de plateaux aériens du noyau sur la stratégie de processus complète de la binance
Apr 21, 2025 pm 01:03 PM
Dans le monde animé des crypto-monnaies, de nouvelles opportunités émergent toujours. À l'heure actuelle, l'activité aérienne de Kerneldao (noyau) attire beaucoup l'attention et attire l'attention de nombreux investisseurs. Alors, quelle est l'origine de ce projet? Quels avantages le support BNB peut-il en tirer? Ne vous inquiétez pas, ce qui suit le révélera un par un pour vous.
 Classement des échanges à effet de levier dans le cercle des devises Les dernières recommandations des dix premiers échanges à effet de levier dans le cercle des devises
Apr 21, 2025 pm 11:24 PM
Classement des échanges à effet de levier dans le cercle des devises Les dernières recommandations des dix premiers échanges à effet de levier dans le cercle des devises
Apr 21, 2025 pm 11:24 PM
Les plates-formes qui ont des performances exceptionnelles dans le commerce, la sécurité et l'expérience utilisateur en effet de levier en 2025 sont: 1. OKX, adaptés aux traders à haute fréquence, fournissant jusqu'à 100 fois l'effet de levier; 2. Binance, adaptée aux commerçants multi-monnaies du monde entier, offrant un effet de levier 125 fois élevé; 3. Gate.io, adapté aux joueurs de dérivés professionnels, fournissant 100 fois l'effet de levier; 4. Bitget, adapté aux novices et aux commerçants sociaux, fournissant jusqu'à 100 fois l'effet de levier; 5. Kraken, adapté aux investisseurs stables, fournissant 5 fois l'effet de levier; 6. BUTBIT, adapté aux explorateurs Altcoin, fournissant 20 fois l'effet de levier; 7. Kucoin, adapté aux commerçants à faible coût, fournissant 10 fois l'effet de levier; 8. Bitfinex, adapté au jeu senior
