
 Périphériques technologiques
IA
La revue la plus complète des grands modèles multimodaux est ici ! 7 chercheurs Microsoft ont coopéré vigoureusement, 5 thèmes majeurs, 119 pages de document
Périphériques technologiques
IA
La revue la plus complète des grands modèles multimodaux est ici ! 7 chercheurs Microsoft ont coopéré vigoureusement, 5 thèmes majeurs, 119 pages de document
La revue la plus complète des grands modèles multimodaux est ici ! 7 chercheurs Microsoft ont coopéré vigoureusement, 5 thèmes majeurs, 119 pages de document

La revue la plus complète des grands modèles multimodauxest ici !
Écrit par7 chercheurs chinois de Microsoft, 119 pages——

actuellement perfectionné et toujours à l'avant-gardedeux types d'orientations de recherche multimodales sur grands modèles. Au début, cinq sujets de recherche spécifiques sont résumés de manière exhaustive :
- Compréhension visuelle
- Génération visuelle
- Modèle de vision unifié
- Grand modèle multimodal alimenté par LLM
- Agent multimodal

Les modèles de base multimodaux sont passés de spécialisés àPs. C'est pourquoi l'auteur a directement dessiné une image deuniversels.
Doraemon au début de l'article.
Qui est apte à lire cette critique(rapport) ?
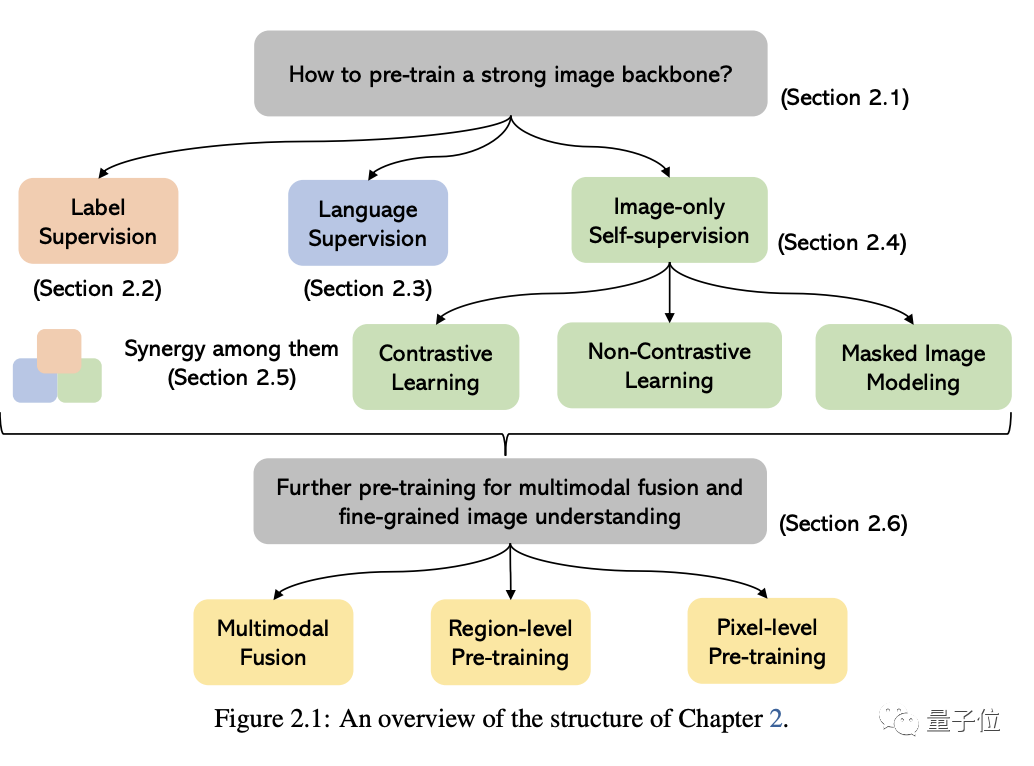
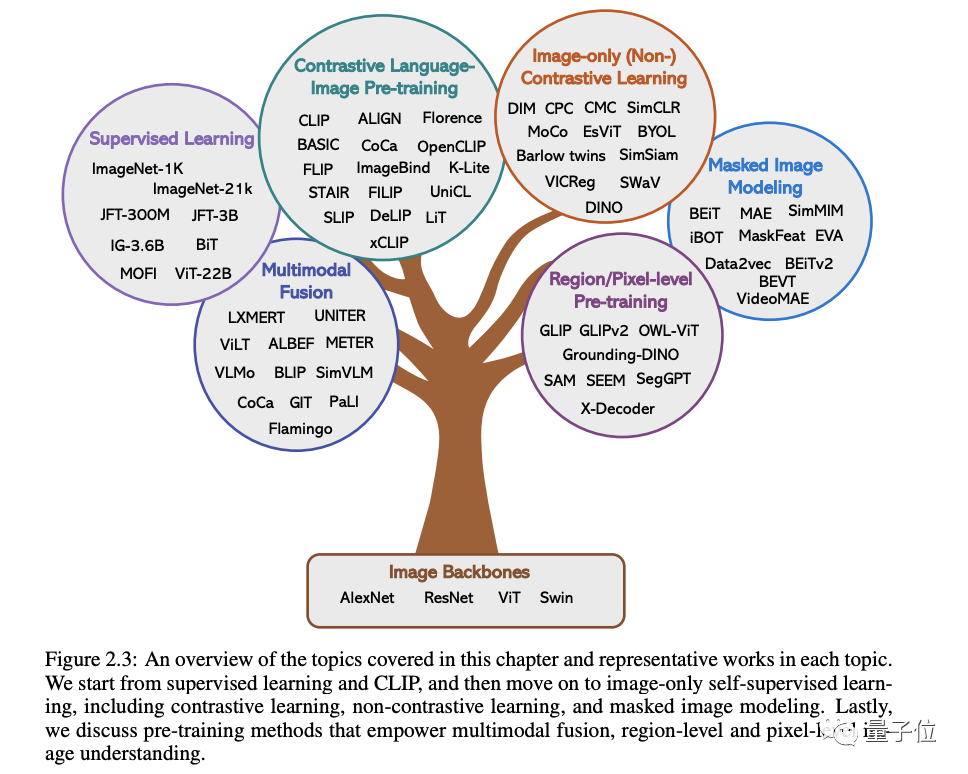
Dans les mots originaux de Microsoft : Tant que vous êtes intéressé à apprendre les connaissances de base et les derniers progrès des modèles de base multimodaux, que vous soyez un chercheur professionnel ou un étudiant, ce contenu vous convient parfaitementJetons un coup d'œil ~Un article pour connaître l'état actuel des grands modèles multimodauxLes deux premiers de ces cinq sujets spécifiques sont des domaines actuellement matures, tandis que les trois derniers sont des domaines de pointe1 . Compréhension visuelleCette partie Le problème principal est de savoir comment pré-former une puissante base de compréhension des images. Comme le montre la figure ci-dessous, selon les différents signaux de supervision utilisés pour entraîner le modèle, nous pouvons diviser les méthodes en trois catégories :
supervision d'étiquettes, supervision linguistique
(représentée par CLIP) et autosupervision par image uniquement .
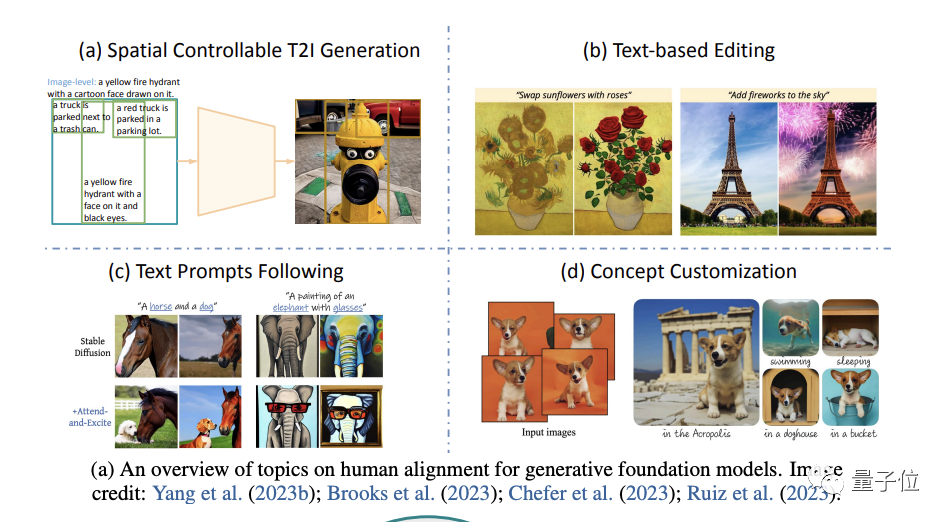
(accent sur la génération d'images) .
Plus précisément, cela commence par quatre aspects : la génération spatiale contrôlable, la réédition basée sur le texte, un meilleur suivi des invites de texte et la personnalisation du concept de génération(personnalisation du concept).
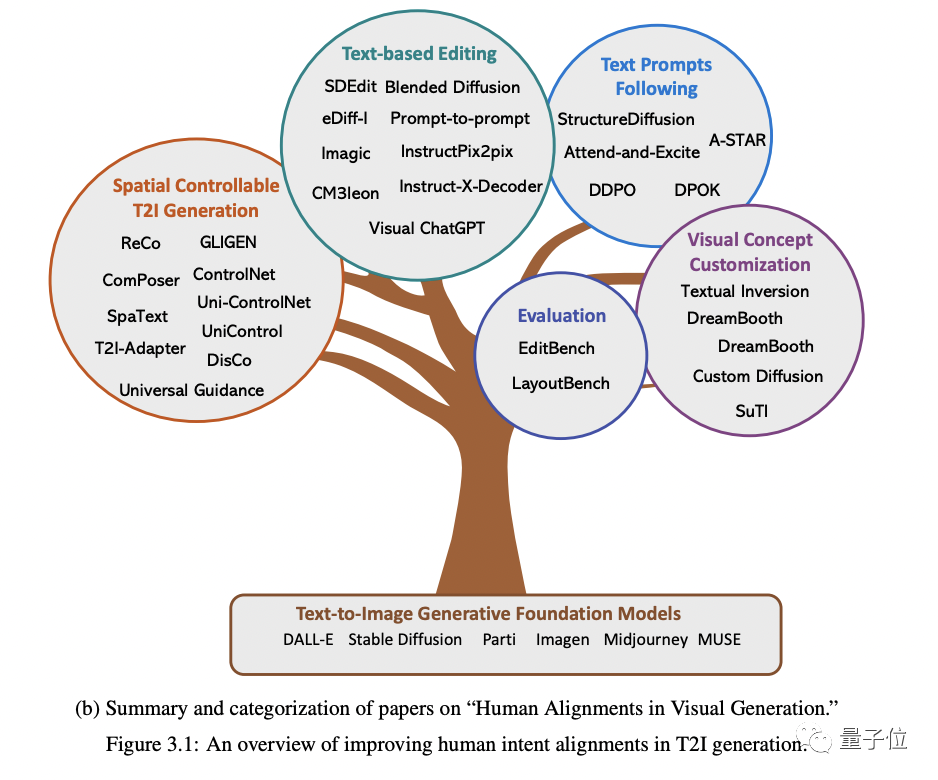
Le. le contenu qui doit être réécrit est : premièrement, le type d'entrée est différent ; Le contenu qui doit être réécrit est : deuxièmement, différentes tâches nécessitent une granularité différente, et la sortie nécessite également différents formats Les données sont également confrontées ; défis , en plus du mannequinat
Par exemple, le coût des différents types d'annotations d'étiquettes varie considérablement et le coût de collecte est bien supérieur à celui des données textuelles, ce qui fait que la taille des données visuelles est généralement bien inférieure à celle des corpus textuels.
Cependant, malgré les nombreux défis, l'auteur souligne :
Le domaine du CV s'intéresse de plus en plus au développement de systèmes de vision générale et unifiée, et trois types de tendances ont émergé :
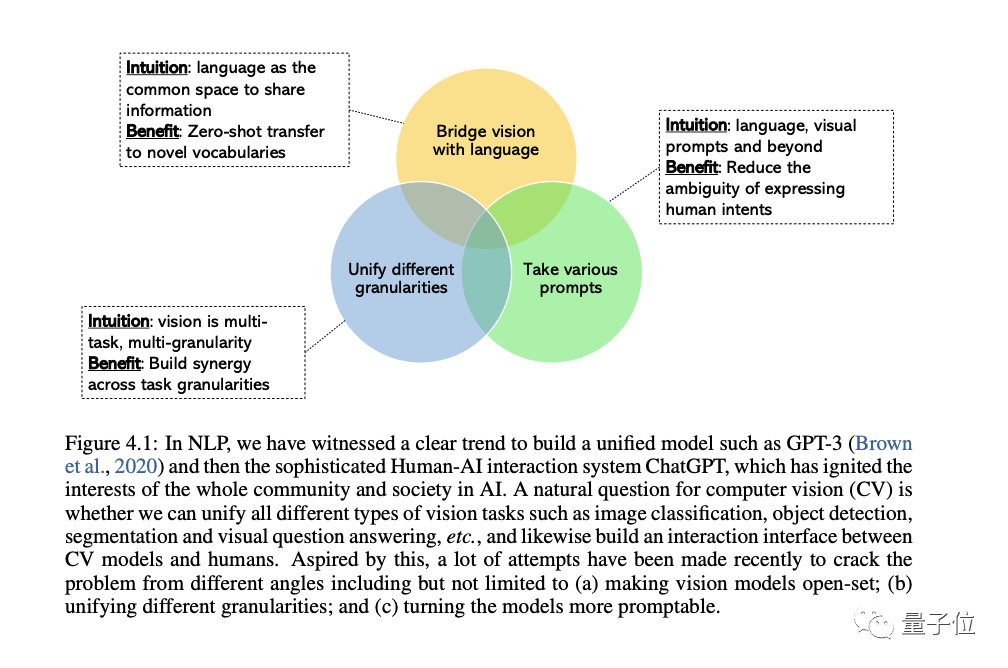
D'abord, à partir des ensembles fermés( close-set) à open-set(open-set), qui peut mieux faire correspondre le texte et les visuels.
La raison la plus importante du passage de tâches spécifiques à des capacités générales est que le coût de développement d'un nouveau modèle pour chaque nouvelle tâche est trop élevé
La troisième est des modèles statiques aux modèles incitatifs, LLM peut adopter différents langages et des invites contextuelles en entrée et produisent la sortie souhaitée par l'utilisateur sans réglage fin. Le modèle de vision générale que nous souhaitons construire doit avoir les mêmes capacités d’apprentissage contextuel.
4. Grands modèles multimodaux pris en charge par LLM
Cette section traite en détail des grands modèles multimodaux.
Tout d’abord, nous mènerons une étude approfondie du contexte et des exemples représentatifs, discuterons des progrès de la recherche multimodale d’OpenAI et identifierons les lacunes de recherche existantes dans ce domaine.
Ensuite, l'auteur examine en détail l'importance du réglage fin de l'enseignement dans les grands modèles de langage.
Ensuite, l'auteur discute du réglage fin des instructions dans les grands modèles multimodaux, y compris les principes, la signification et les applications.
Enfin, nous aborderons également certains sujets avancés dans le domaine des modèles multimodaux pour une compréhension plus approfondie, notamment :
Plus de modalités au-delà de la vision et du langage, l'apprentissage du contexte multimodal, la formation efficace des paramètres ainsi que les benchmarks et autres contenu.
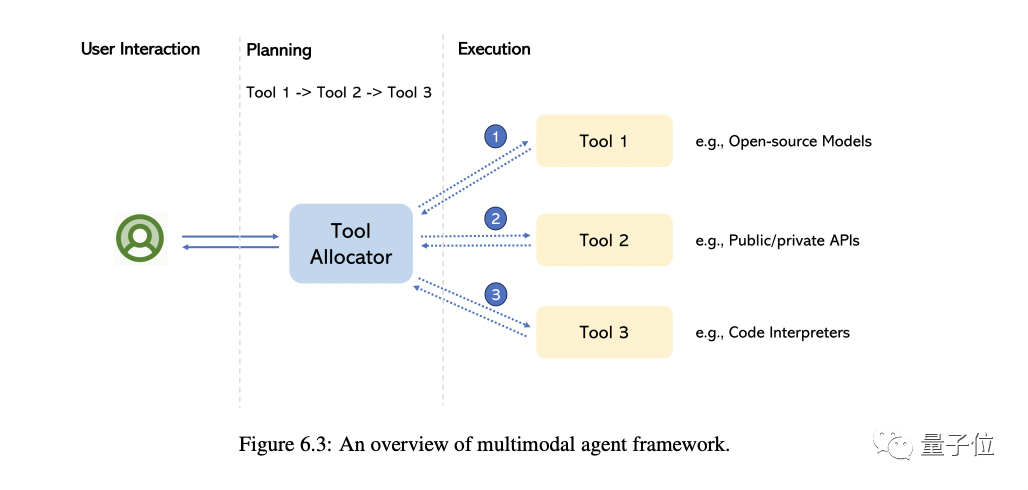
5. Agent multimodal
L'agent dit multimodal est une méthode qui connecte différents experts multimodaux avec LLM pour résoudre des problèmes complexes de compréhension multimodale.
Dans cette partie, l'auteur vous emmène principalement revenir sur la transformation de ce modèle et résume les différences fondamentales entre cette méthode et la méthode traditionnelle.
En prenant MM-REACT comme exemple, nous présenterons en détail le fonctionnement de cette méthode
Nous résumons en outre une approche globale sur la façon de construire des agents multimodaux, ainsi que ses capacités émergentes en matière de compréhension multimodale. Nous expliquons également comment étendre facilement cette fonctionnalité, y compris le dernier et le meilleur LLM et potentiellement des millions d'outils
Bien sûr, certains sujets de haut niveau sont également abordés à la fin, notamment comment améliorer/évaluer un agent multimodalité, diverses applications construites à partir de celui-ci, etc.
Introduction à l'auteur
Il y a 7 auteurs dans ce rapport
L'initiateur et responsable global est Chunyuan Li.
Il est chercheur principal à Microsoft Redmond et est titulaire d'un doctorat de l'Université Duke. Ses récents intérêts de recherche portent sur la pré-formation à grande échelle en CV et en PNL.
Il était responsable de l'introduction d'ouverture et du résumé de clôture, ainsi que de la rédaction du chapitre "Grands modèles multimodaux formés à l'aide du LLM". Contenu réécrit : Il était responsable de la rédaction du début et de la fin de l'article, ainsi que du chapitre sur « Grands modèles multimodaux formés à l'aide du LLM »

Il y a 4 auteurs principaux :
- Zhe Gan
a désormais rejoint Apple AI/ML et est responsable de la vision à grande échelle et de la recherche de modèles de base multimodaux. Auparavant, il était le chercheur principal de Microsoft Azure AI. Il est titulaire d'un baccalauréat et d'un doctorat de l'Université Duke.
- Zhengyuan Yang
Il est chercheur principal chez Microsoft. Il est diplômé de l'Université de Rochester et a reçu le prix de doctorat exceptionnel ACM SIGMM et d'autres distinctions. Il a étudié en tant que premier cycle à l'Université des sciences et technologies de Chine
- Jianwei Yang
Chercheur principal du Deep Learning Group de Microsoft Research Redmond. Doctorat du Georgia Institute of Technology.
- Linjie Li (femme)
Chercheuse au sein du Microsoft Cloud & AI Computer Vision Group, diplômée d'une maîtrise de l'Université Purdue.
Ils étaient respectivement responsables de la rédaction des quatre chapitres thématiques restants.
Adresse de révision : https://arxiv.org/abs/2309.10020
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Utilisez ddrescue pour récupérer des données sous Linux
Mar 20, 2024 pm 01:37 PM
Utilisez ddrescue pour récupérer des données sous Linux
Mar 20, 2024 pm 01:37 PM
DDREASE est un outil permettant de récupérer des données à partir de périphériques de fichiers ou de blocs tels que des disques durs, des SSD, des disques RAM, des CD, des DVD et des périphériques de stockage USB. Il copie les données d'un périphérique bloc à un autre, laissant derrière lui les blocs corrompus et ne déplaçant que les bons blocs. ddreasue est un puissant outil de récupération entièrement automatisé car il ne nécessite aucune interruption pendant les opérations de récupération. De plus, grâce au fichier map ddasue, il peut être arrêté et repris à tout moment. Les autres fonctionnalités clés de DDREASE sont les suivantes : Il n'écrase pas les données récupérées mais comble les lacunes en cas de récupération itérative. Cependant, il peut être tronqué si l'outil est invité à le faire explicitement. Récupérer les données de plusieurs fichiers ou blocs en un seul
 Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
0. À quoi sert cet article ? Nous proposons DepthFM : un modèle d'estimation de profondeur monoculaire génératif de pointe, polyvalent et rapide. En plus des tâches traditionnelles d'estimation de la profondeur, DepthFM démontre également des capacités de pointe dans les tâches en aval telles que l'inpainting en profondeur. DepthFM est efficace et peut synthétiser des cartes de profondeur en quelques étapes d'inférence. Lisons ce travail ensemble ~ 1. Titre des informations sur l'article : DepthFM : FastMonocularDepthEstimationwithFlowMatching Auteur : MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Comment utiliser la fonction de filtre Excel avec plusieurs conditions
Feb 26, 2024 am 10:19 AM
Comment utiliser la fonction de filtre Excel avec plusieurs conditions
Feb 26, 2024 am 10:19 AM
Si vous avez besoin de savoir comment utiliser le filtrage avec plusieurs critères dans Excel, le didacticiel suivant vous guidera à travers les étapes pour vous assurer que vous pouvez filtrer et trier efficacement vos données. La fonction de filtrage d'Excel est très puissante et peut vous aider à extraire les informations dont vous avez besoin à partir de grandes quantités de données. Cette fonction peut filtrer les données en fonction des conditions que vous définissez et afficher uniquement les pièces qui remplissent les conditions, rendant la gestion des données plus efficace. En utilisant la fonction de filtre, vous pouvez trouver rapidement des données cibles, ce qui vous fait gagner du temps dans la recherche et l'organisation des données. Cette fonction peut non seulement être appliquée à de simples listes de données, mais peut également être filtrée en fonction de plusieurs conditions pour vous aider à localiser plus précisément les informations dont vous avez besoin. Dans l’ensemble, la fonction de filtrage d’Excel est très utile
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vous êtes confronté à un décalage et à une connexion de données mobile lente sur iPhone ? En règle générale, la puissance de l'Internet cellulaire sur votre téléphone dépend de plusieurs facteurs tels que la région, le type de réseau cellulaire, le type d'itinérance, etc. Vous pouvez prendre certaines mesures pour obtenir une connexion Internet cellulaire plus rapide et plus fiable. Correctif 1 – Forcer le redémarrage de l'iPhone Parfois, le redémarrage forcé de votre appareil réinitialise simplement beaucoup de choses, y compris la connexion cellulaire. Étape 1 – Appuyez simplement une fois sur la touche d’augmentation du volume et relâchez-la. Ensuite, appuyez sur la touche de réduction du volume et relâchez-la à nouveau. Étape 2 – La partie suivante du processus consiste à maintenir le bouton sur le côté droit. Laissez l'iPhone finir de redémarrer. Activez les données cellulaires et vérifiez la vitesse du réseau. Vérifiez à nouveau Correctif 2 – Changer le mode de données Bien que la 5G offre de meilleures vitesses de réseau, elle fonctionne mieux lorsque le signal est plus faible
 La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
Je pleure à mort. Le monde construit à la folie de grands modèles. Les données sur Internet ne suffisent pas du tout. Le modèle de formation ressemble à « The Hunger Games », et les chercheurs en IA du monde entier se demandent comment nourrir ces personnes avides de données. Ce problème est particulièrement important dans les tâches multimodales. À une époque où rien ne pouvait être fait, une équipe de start-up du département de l'Université Renmin de Chine a utilisé son propre nouveau modèle pour devenir la première en Chine à faire de « l'auto-alimentation des données générées par le modèle » une réalité. De plus, il s’agit d’une approche à deux volets, du côté compréhension et du côté génération, les deux côtés peuvent générer de nouvelles données multimodales de haute qualité et fournir un retour de données au modèle lui-même. Qu'est-ce qu'un modèle ? Awaker 1.0, un grand modèle multimodal qui vient d'apparaître sur le Forum Zhongguancun. Qui est l'équipe ? Moteur Sophon. Fondé par Gao Yizhao, doctorant à la Hillhouse School of Artificial Intelligence de l’Université Renmin.
 L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
Récemment, le milieu militaire a été submergé par la nouvelle : les avions de combat militaires américains peuvent désormais mener des combats aériens entièrement automatiques grâce à l'IA. Oui, tout récemment, l’avion de combat IA de l’armée américaine a été rendu public pour la première fois, dévoilant ainsi son mystère. Le nom complet de ce chasseur est Variable Stability Simulator Test Aircraft (VISTA). Il a été personnellement piloté par le secrétaire de l'US Air Force pour simuler une bataille aérienne en tête-à-tête. Le 2 mai, le secrétaire de l'US Air Force, Frank Kendall, a décollé à bord d'un X-62AVISTA à la base aérienne d'Edwards. Notez que pendant le vol d'une heure, toutes les actions de vol ont été effectuées de manière autonome par l'IA ! Kendall a déclaré : "Au cours des dernières décennies, nous avons réfléchi au potentiel illimité du combat air-air autonome, mais cela a toujours semblé hors de portée." Mais maintenant,
 Le premier robot capable d'accomplir de manière autonome des tâches humaines apparaît, avec cinq doigts flexibles et rapides, et de grands modèles prennent en charge l'entraînement dans l'espace virtuel
Mar 11, 2024 pm 12:10 PM
Le premier robot capable d'accomplir de manière autonome des tâches humaines apparaît, avec cinq doigts flexibles et rapides, et de grands modèles prennent en charge l'entraînement dans l'espace virtuel
Mar 11, 2024 pm 12:10 PM
Cette semaine, FigureAI, une entreprise de robotique investie par OpenAI, Microsoft, Bezos et Nvidia, a annoncé avoir reçu près de 700 millions de dollars de financement et prévoit de développer un robot humanoïde capable de marcher de manière autonome au cours de la prochaine année. Et l’Optimus Prime de Tesla a reçu à plusieurs reprises de bonnes nouvelles. Personne ne doute que cette année sera celle de l’explosion des robots humanoïdes. SanctuaryAI, une entreprise canadienne de robotique, a récemment lancé un nouveau robot humanoïde, Phoenix. Les responsables affirment qu’il peut accomplir de nombreuses tâches de manière autonome, à la même vitesse que les humains. Pheonix, le premier robot au monde capable d'accomplir des tâches de manière autonome à la vitesse d'un humain, peut saisir, déplacer et placer avec élégance chaque objet sur ses côtés gauche et droit. Il peut identifier des objets de manière autonome
