
 Périphériques technologiques
IA
La technologie de l'IA explose de façon exponentielle : la puissance de calcul a été multipliée par 680 millions en 70 ans, en 3 étapes historiques
Périphériques technologiques
IA
La technologie de l'IA explose de façon exponentielle : la puissance de calcul a été multipliée par 680 millions en 70 ans, en 3 étapes historiques
La technologie de l'IA explose de façon exponentielle : la puissance de calcul a été multipliée par 680 millions en 70 ans, en 3 étapes historiques

Les ordinateurs électroniques sont nés dans les années 1940 et, dix ans après l'émergence des ordinateurs, la première application d'IA de l'histoire de l'humanité est apparue.
Les modèles d'IA sont développés depuis plus de 70 ans et peuvent désormais non seulement créer de la poésie, mais également générer des images basées sur des invites textuelles, et même aider les humains à découvrir des structures protéiques inconnues
En si peu de temps , La technologie de l'IA a obtenu des résultats exponentiels Croissance du niveau, quelle en est la raison ?
Une longue image de "Our World in Data" retrace l'histoire du développement de l'IA à travers les changements dans la puissance de calcul utilisée pour entraîner les modèles d'IA à l'échelle.

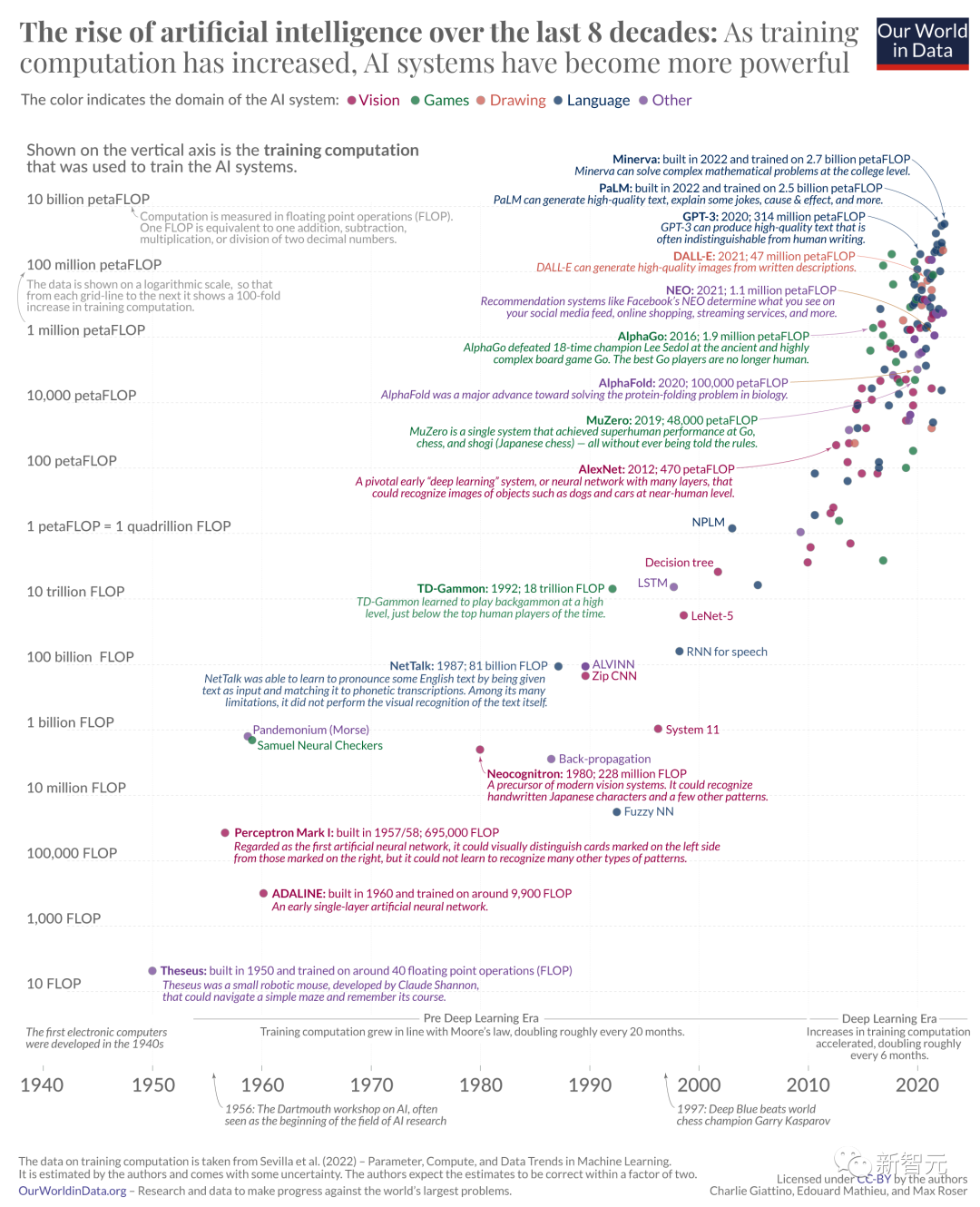
Grande image haute définition : https://www.visualcapitalist.com/wp-content/uploads/2023/09/01.-CP_AI-Computation-History_Full-Sized.html Le contenu qui doit être réécrit est : Lien vers une grande image haute définition : https://www.visualcapitalist.com/wp-content/uploads/2023/09/01.-CP_AI-Computation-History_Full-Sized.html
Ces données La source est un article publié par des chercheurs du MIT et d'autres universités

Lien papier : https://arxiv.org/pdf/2202.05924.pdf
En plus de l'article, Une autre équipe de recherche a produit un tableau visuel basé sur les données contenues dans cet article. Les utilisateurs peuvent zoomer et dézoomer sur le graphique à volonté pour obtenir des données plus détaillées
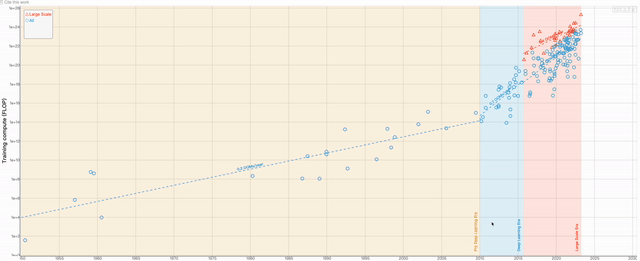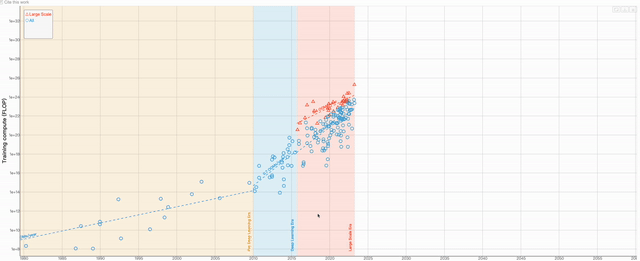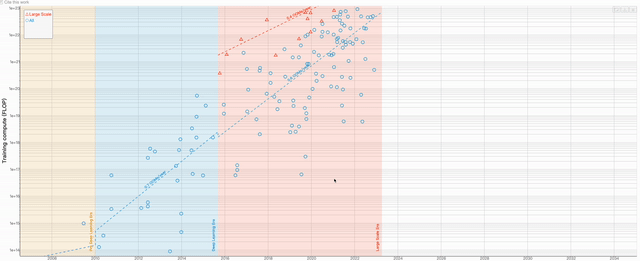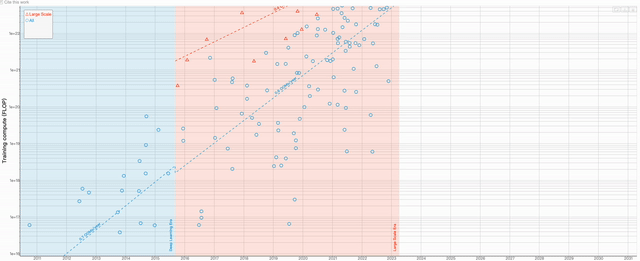
Le contenu qui doit être réécrit est : Adresse de la table : https://epochai.org/blog/compute-trends#compute -les-tendances-sont-plus lentes que celles signalées précédemment
L'auteur du graphique estime principalement la quantité de calcul d'entraînement de chaque modèle en calculant le nombre d'opérations et le temps GPU quant au modèle à choisir comme représentant. le modèle important, l'auteur utilise principalement 3 propriétés pour estimer Identifier :
Importance significative : Un système a un impact historique significatif, améliore significativement SOTA, ou a été cité plus de 1 000 fois.
Pertinence : l'auteur n'inclut que les articles contenant des résultats expérimentaux et des composants clés d'apprentissage automatique, et l'objectif de l'article est de promouvoir le développement de SOTA existant.
Unicité : s'il existe un autre article plus influent décrivant le même système, alors l'article sera supprimé de l'ensemble de données de l'auteur
Trois époques du développement de l'IA
Dans Dans les années 1950, le mathématicien américain Claude Shannon a formé une souris robotique nommée Thésée pour naviguer dans un labyrinthe et mémoriser ses chemins. Il s'agit de la première instance d'apprentissage artificiel
Theseus est construit sur 40 opérations à virgule flottante (FLOP). Les FLOP sont couramment utilisés comme mesure des performances informatiques du matériel informatique. Plus le nombre de FLOP est élevé, plus la puissance de calcul est grande et plus le système est puissant.
Les progrès de l'IA reposent sur trois éléments clés : la puissance de calcul, les données d'entraînement disponibles et les algorithmes. Au cours des premières décennies du développement de l'IA, la demande en puissance de calcul a continué de croître selon la loi de Moore, ce qui signifie que la puissance de calcul a doublé environ tous les 20 mois

Cependant, lors du lancement d'AlexNet (une image) en 2012 Avec l'avènement de l'intelligence artificielle (IA) de reconnaissance qui a marqué le début de l'ère de l'apprentissage profond, ce temps de doublement a été considérablement réduit à six mois alors que les chercheurs ont augmenté leurs investissements dans l'informatique et les processeurs
Avec l'AlphaGo 2015 Avec l'émergence de Go — un programme informatique qui a vaincu un joueur de Go humain professionnel — les chercheurs ont découvert une troisième ère : l'arrivée de modèles d'IA à grande échelle, dont les exigences informatiques sont supérieures à celles de tous les systèmes d'IA précédents.
Les progrès de la technologie de l'IA dans le futur
En regardant en arrière sur les dix dernières années, le taux de croissance de la puissance de calcul est tout simplement incroyable
Par exemple, la puissance de calcul utilisée pour entraîner Minerva, une IA capable de résoudre des problèmes mathématiques complexes, était près de 6 millions de fois supérieure à celle utilisée pour entraîner AlexNet il y a dix ans.
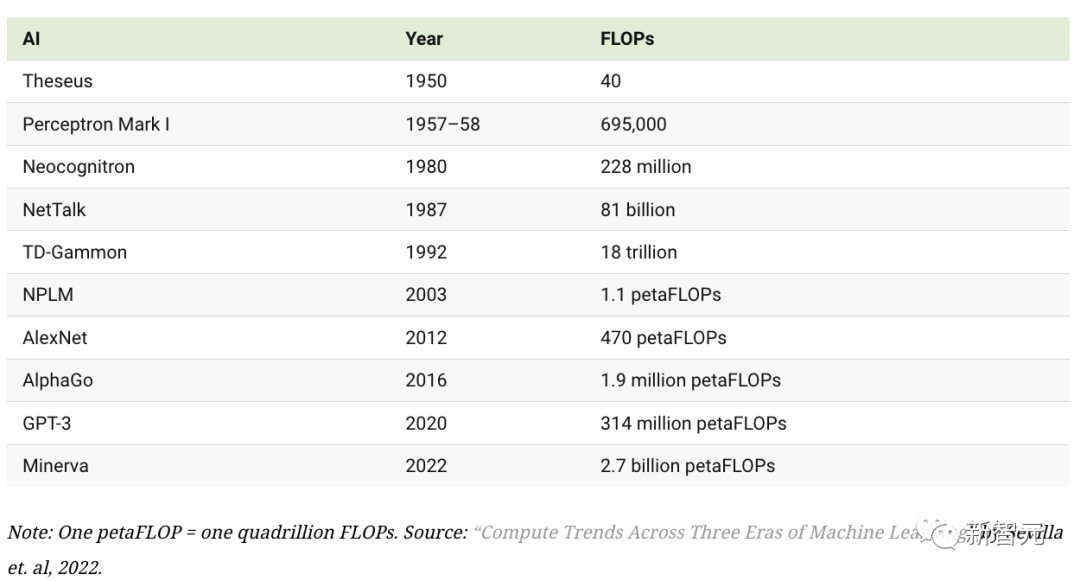
Cette croissance de l'informatique, associée à la disponibilité massive d'ensembles de données et de meilleurs algorithmes, a permis à l'IA de faire de nombreux progrès dans un laps de temps extrêmement court. Aujourd’hui, l’IA peut non seulement atteindre les niveaux de performance humaine, mais même surpasser l’humain dans de nombreux domaines.
Les capacités de l'IA continueront de surpasser les humains dans tous les aspects
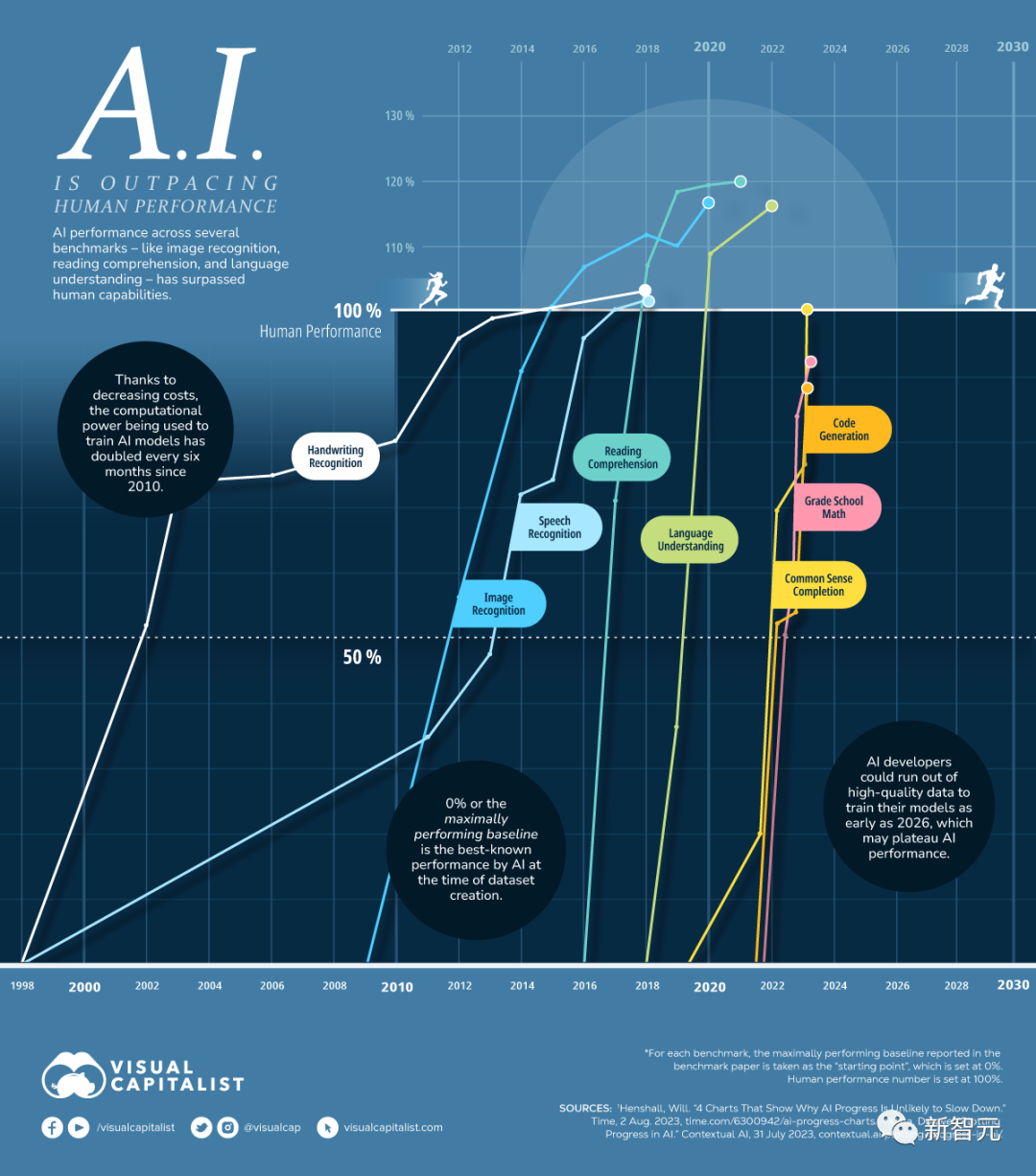
Il ressort clairement du chiffre ci-dessus que l'intelligence artificielle a dépassé les performances humaines dans de nombreux domaines et dépassera bientôt les humains dans d'autres aspects. .
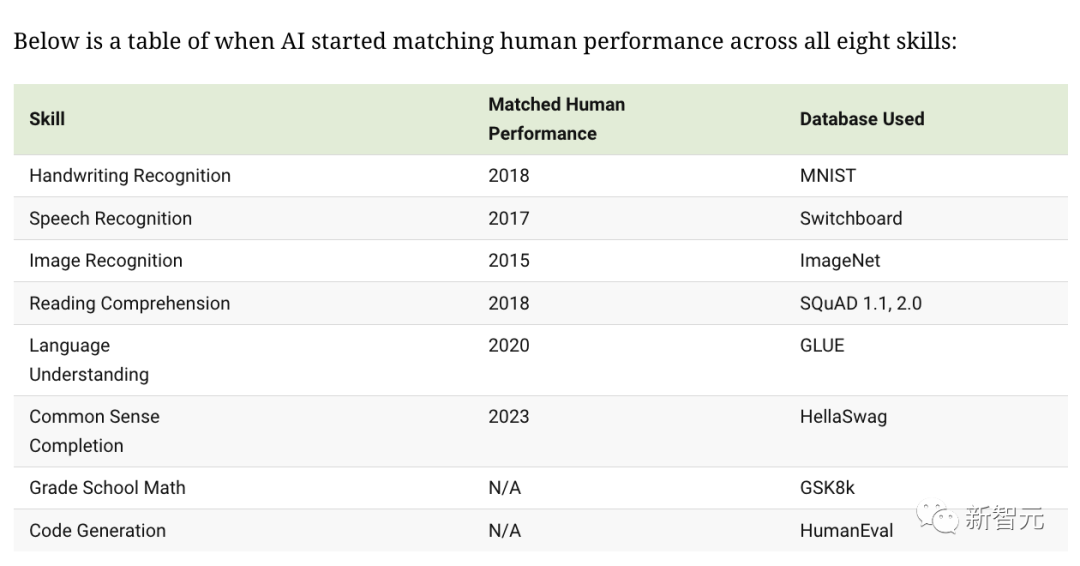
La figure ci-dessous montre l'année au cours de laquelle l'IA a atteint ou dépassé les niveaux humains dans les capacités courantes que les humains utilisent dans leur travail et leur vie quotidienne.
Le potentiel de développement de la technologie de l'IA est suffisant
Il est difficile de déterminer si la croissance de l'informatique peut maintenir la même vitesse. La formation de modèles à grande échelle nécessite de plus en plus de puissance de calcul. Si l'offre de puissance de calcul ne peut pas continuer à croître, cela pourrait ralentir le développement de la technologie de l'intelligence artificielle
De même, cela pourrait également épuiser toutes les données actuellement disponibles. pour la formation des modèles d’IA. Entrave le développement et la mise en œuvre de nouveaux modèles.
En 2023, l'industrie de l'IA verra un afflux de capitaux, notamment l'IA générative représentée par de grands modèles de langage. Cela peut indiquer que d'autres percées sont à venir. Il semble que les trois éléments ci-dessus qui favorisent le développement de la technologie de l'IA seront encore optimisés et développés à l'avenir
Au premier semestre 2023, l'échelle de financement des startups du L'industrie de l'IA a atteint 140 milliards, soit plus que le financement total reçu au cours des quatre dernières années.
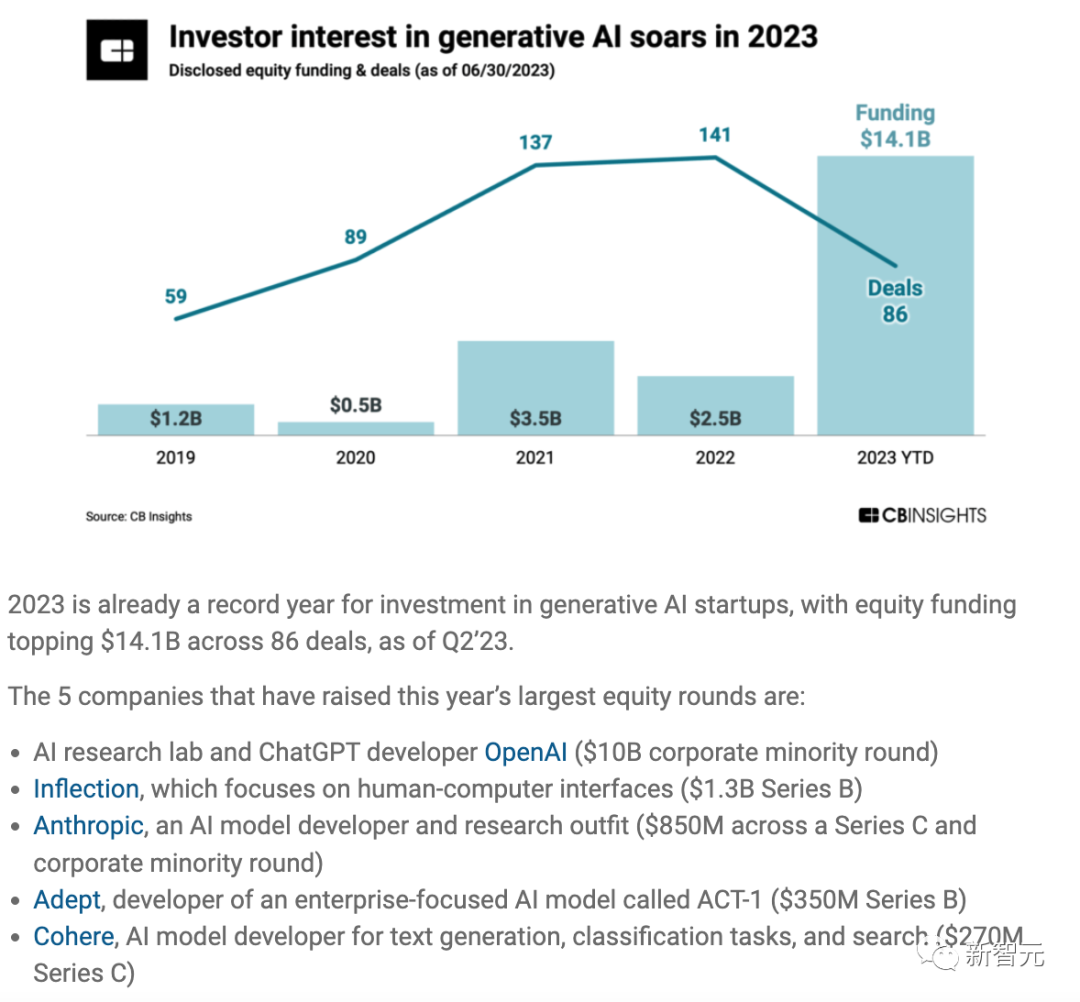
Et un grand nombre (78%) de startups d'IA générative en sont encore aux tout premiers stades de développement, et même 27% des startups d'IA générative n'ont pas encore levé de fonds.
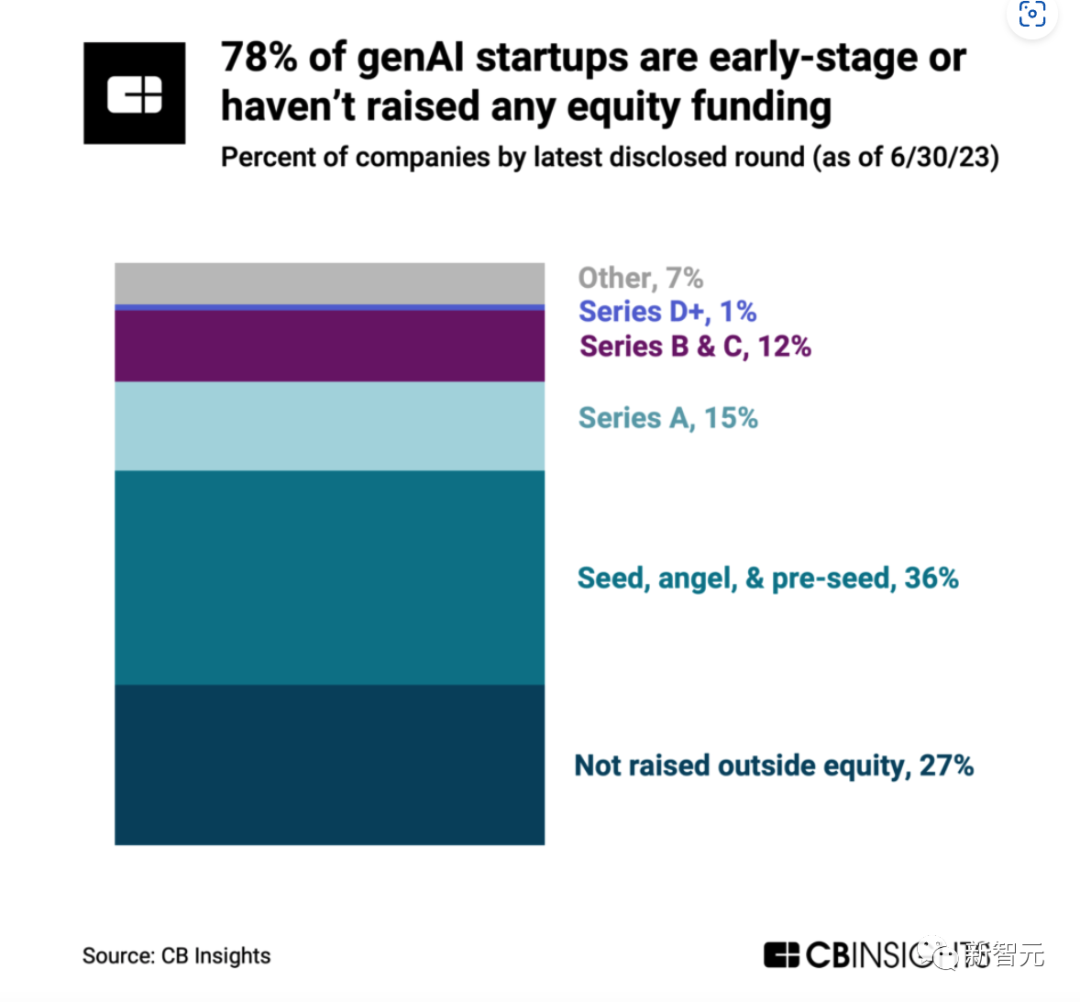
Plus de 360 entreprises d'intelligence artificielle générative, 27% n'ont pas encore levé de fonds. Plus de la moitié sont des projets du Round 1 ou antérieurs, ce qui indique que l’ensemble du secteur de l’IA générative en est encore à ses débuts.
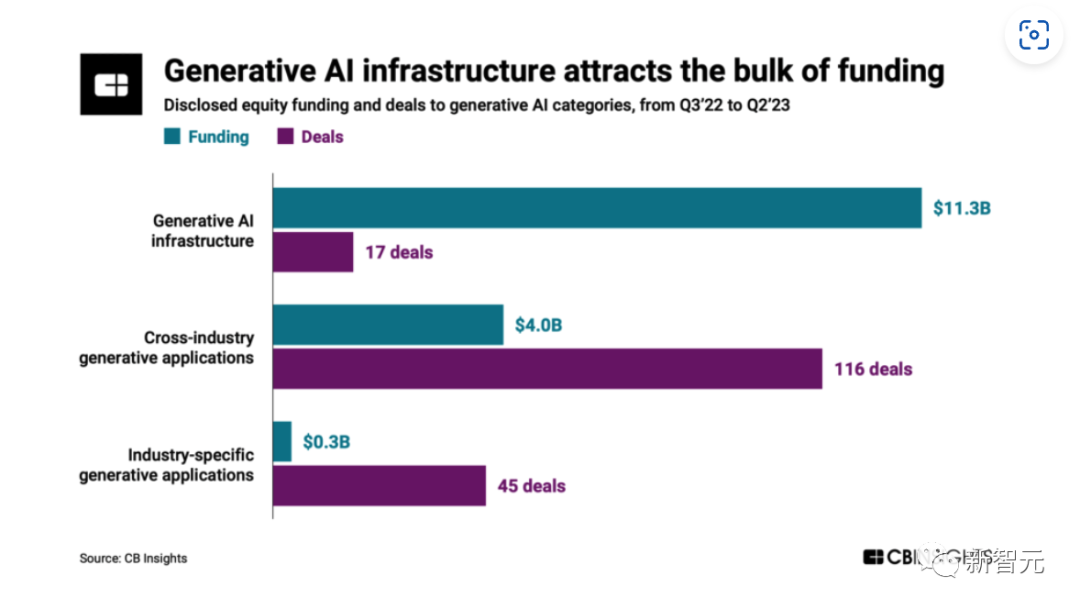
En raison de la nature capitalistique du développement de modèles de langage à grande échelle, la catégorie des infrastructures d'IA générative a reçu plus de 70 % de financement depuis le troisième trimestre 2022, ce qui ne représente que 10 % de l'ensemble du volume de transactions d'IA générative. Une grande partie du financement provient de l'intérêt des investisseurs pour les infrastructures émergentes telles que les modèles et API sous-jacents, les MLOps (opérations d'apprentissage automatique) et la technologie des bases de données vectorielles.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Dans Debian Systems, la fonction ReadDir est utilisée pour lire le contenu du répertoire, mais l'ordre dans lequel il revient n'est pas prédéfini. Pour trier les fichiers dans un répertoire, vous devez d'abord lire tous les fichiers, puis les trier à l'aide de la fonction QSORT. Le code suivant montre comment trier les fichiers de répertoire à l'aide de ReadDir et QSort dans Debian System: # include # include # include # include # include // Fonction de comparaison personnalisée, utilisée pour qsortintCompare (constvoid * a, constvoid * b) {returnstrcmp (* (
 Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Dans Debian Systems, les appels du système ReadDir sont utilisés pour lire le contenu des répertoires. Si ses performances ne sont pas bonnes, essayez la stratégie d'optimisation suivante: simplifiez le nombre de fichiers d'annuaire: divisez les grands répertoires en plusieurs petits répertoires autant que possible, en réduisant le nombre d'éléments traités par appel ReadDir. Activer la mise en cache de contenu du répertoire: construire un mécanisme de cache, mettre à jour le cache régulièrement ou lorsque le contenu du répertoire change et réduire les appels fréquents à Readdir. Les caches de mémoire (telles que Memcached ou Redis) ou les caches locales (telles que les fichiers ou les bases de données) peuvent être prises en compte. Adoptez une structure de données efficace: si vous implémentez vous-même la traversée du répertoire, sélectionnez des structures de données plus efficaces (telles que les tables de hachage au lieu de la recherche linéaire) pour stocker et accéder aux informations du répertoire
 Comment définir le niveau de journal Debian Apache
Apr 13, 2025 am 08:33 AM
Comment définir le niveau de journal Debian Apache
Apr 13, 2025 am 08:33 AM
Cet article décrit comment ajuster le niveau de journalisation du serveur Apacheweb dans le système Debian. En modifiant le fichier de configuration, vous pouvez contrôler le niveau verbeux des informations de journal enregistrées par Apache. Méthode 1: Modifiez le fichier de configuration principal pour localiser le fichier de configuration: le fichier de configuration d'Apache2.x est généralement situé dans le répertoire / etc / apache2 /. Le nom de fichier peut être apache2.conf ou httpd.conf, selon votre méthode d'installation. Modifier le fichier de configuration: Ouvrez le fichier de configuration avec les autorisations racine à l'aide d'un éditeur de texte (comme Nano): Sutonano / etc / apache2 / apache2.conf
 Comment Debian OpenSSL empêche les attaques de l'homme au milieu
Apr 13, 2025 am 10:30 AM
Comment Debian OpenSSL empêche les attaques de l'homme au milieu
Apr 13, 2025 am 10:30 AM
Dans Debian Systems, OpenSSL est une bibliothèque importante pour le chiffrement, le décryptage et la gestion des certificats. Pour empêcher une attaque d'homme dans le milieu (MITM), les mesures suivantes peuvent être prises: utilisez HTTPS: assurez-vous que toutes les demandes de réseau utilisent le protocole HTTPS au lieu de HTTP. HTTPS utilise TLS (Protocole de sécurité de la couche de transport) pour chiffrer les données de communication pour garantir que les données ne sont pas volées ou falsifiées pendant la transmission. Vérifiez le certificat de serveur: vérifiez manuellement le certificat de serveur sur le client pour vous assurer qu'il est digne de confiance. Le serveur peut être vérifié manuellement via la méthode du délégué d'URLSession
 Méthode d'installation du certificat de Debian Mail Server SSL
Apr 13, 2025 am 11:39 AM
Méthode d'installation du certificat de Debian Mail Server SSL
Apr 13, 2025 am 11:39 AM
Les étapes pour installer un certificat SSL sur le serveur de messagerie Debian sont les suivantes: 1. Installez d'abord la boîte à outils OpenSSL, assurez-vous que la boîte à outils OpenSSL est déjà installée sur votre système. Si ce n'est pas installé, vous pouvez utiliser la commande suivante pour installer: Sudoapt-getUpDaSuDoapt-getInstallOpenSSL2. Générer la clé privée et la demande de certificat Suivant, utilisez OpenSSL pour générer une clé privée RSA 2048 bits et une demande de certificat (RSE): OpenSS
 Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
La fonction ReadDir dans le système Debian est un appel système utilisé pour lire le contenu des répertoires et est souvent utilisé dans la programmation C. Cet article expliquera comment intégrer ReadDir avec d'autres outils pour améliorer sa fonctionnalité. Méthode 1: combinant d'abord le programme de langue C et le pipeline, écrivez un programme C pour appeler la fonction readdir et sortir le résultat: # include # include # include # includeIntmain (intargc, char * argv []) {dir * dir; structDirent * entrée; if (argc! = 2) {
 Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
La configuration du pare-feu d'un serveur de courrier Debian est une étape importante pour assurer la sécurité du serveur. Voici plusieurs méthodes de configuration de pare-feu couramment utilisées, y compris l'utilisation d'iptables et de pare-feu. Utilisez les iptables pour configurer le pare-feu pour installer iptables (sinon déjà installé): Sudoapt-getUpDaSuDoapt-getinstalliptableView Règles actuelles iptables: Sudoiptable-L Configuration
 Comment apprendre Debian Syslog
Apr 13, 2025 am 11:51 AM
Comment apprendre Debian Syslog
Apr 13, 2025 am 11:51 AM
Ce guide vous guidera pour apprendre à utiliser Syslog dans Debian Systems. Syslog est un service clé dans les systèmes Linux pour les messages du système de journalisation et du journal d'application. Il aide les administrateurs à surveiller et à analyser l'activité du système pour identifier et résoudre rapidement les problèmes. 1. Connaissance de base de Syslog Les fonctions principales de Syslog comprennent: la collecte et la gestion des messages journaux de manière centralisée; Prise en charge de plusieurs formats de sortie de journal et des emplacements cibles (tels que les fichiers ou les réseaux); Fournir des fonctions de visualisation et de filtrage des journaux en temps réel. 2. Installer et configurer syslog (en utilisant RSYSLOG) Le système Debian utilise RSYSLOG par défaut. Vous pouvez l'installer avec la commande suivante: SudoaptupDatesud
