
 Périphériques technologiques
IA
SupFusion : Vous cherchez comment superviser efficacement les réseaux de détection 3D fusionnés Lidar-Caméra ?
Périphériques technologiques
IA
SupFusion : Vous cherchez comment superviser efficacement les réseaux de détection 3D fusionnés Lidar-Caméra ?
SupFusion : Vous cherchez comment superviser efficacement les réseaux de détection 3D fusionnés Lidar-Caméra ?

La détection 3D basée sur la fusion de caméras lidar est une tâche clé pour la conduite autonome. Ces dernières années, de nombreuses méthodes de fusion de caméras LiDAR ont émergé et ont atteint de bonnes performances, mais ces méthodes manquent toujours d'un processus de fusion bien conçu et efficacement supervisé.
Cet article présente une nouvelle stratégie de formation appelée SupFusion, qui fournit une fusion laser radar-caméra supervision auxiliaire au niveau des fonctionnalités et améliore considérablement les performances de détection. Le procédé comprend la méthode d'augmentation des données Polar Sampling pour chiffrer des cibles clairsemées et former des modèles auxiliaires afin de générer des fonctionnalités de haute qualité pour la supervision. Ces fonctionnalités sont utilisées pour entraîner le modèle de fusion de caméra lidar et optimiser les fonctionnalités fusionnées afin de simuler la génération de fonctionnalités de haute qualité. En outre, un module de fusion profonde simple mais efficace est proposé, qui atteint en permanence des performances supérieures par rapport aux méthodes de fusion précédentes utilisant la stratégie SupFusion. La méthode présentée dans cet article présente les avantages suivants : Premièrement, SupFusion introduit une supervision auxiliaire au niveau des fonctionnalités, qui peut améliorer les performances de détection des caméras lidar sans augmenter les coûts d'inférence supplémentaires. Deuxièmement, la fusion profonde proposée peut améliorer continuellement les capacités du détecteur. Les modules SupFusion et de fusion profonde proposés sont plug-and-play, et cet article démontre leur efficacité grâce à des expériences approfondies. Dans le benchmark KITTI pour la détection 3D basée sur plusieurs caméras lidar, une amélioration d'environ 2 % de la mAP 3D a été obtenue !
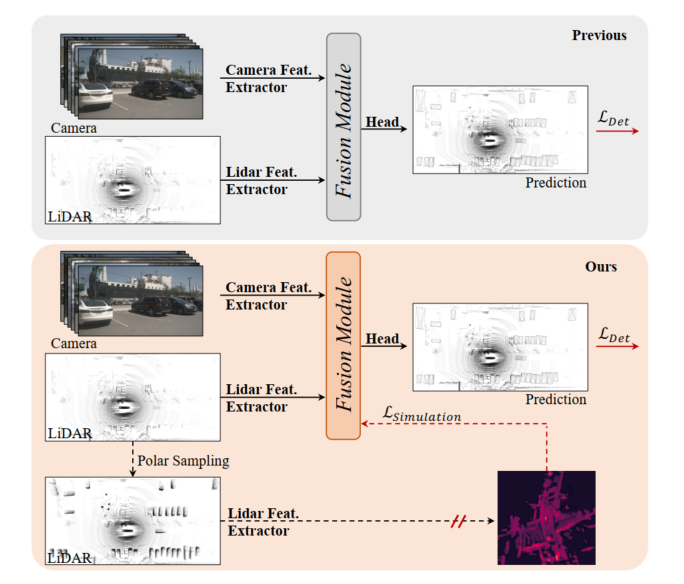
Figure 1 : En haut, précédent modèle de détection 3D de la caméra lidar, le module de fusion est optimisé par perte de détection. En bas : SupFusion proposé dans cet article introduit la supervision auxiliaire grâce à des fonctionnalités de haute qualité fournies par les modèles auxiliaires.
La détection 3D basée sur la fusion de caméras lidar est une tâche critique et difficile en conduite autonome et en robotique. Les méthodes précédentes projetaient toujours l'entrée de la caméra dans l'espace lidar BEV ou voxel via des paramètres intrinsèques et extrinsèques, pour aligner les fonctionnalités du lidar et de la caméra. Ensuite, une simple concaténation ou sommation est utilisée pour obtenir les caractéristiques fusionnées pour la détection finale. De plus, certaines méthodes de fusion basées sur l’apprentissage profond ont atteint des performances prometteuses. Cependant, les méthodes de fusion précédentes optimisent toujours directement les modules d’extraction et de fusion de fonctionnalités 3D/2D via une perte de détection, qui manque de conception soignée et de supervision efficace au niveau des fonctionnalités, limitant leurs performances.
Ces dernières années, les méthodes de distillation ont montré de grandes améliorations en termes de supervision au niveau des fonctionnalités pour la détection 3D. Certaines méthodes fournissent des fonctionnalités lidar pour guider le squelette 2D afin d'estimer les informations de profondeur en fonction des entrées de la caméra. De plus, certaines méthodes offrent des capacités de fusion de caméras lidar pour superviser l’épine dorsale lidar afin d’apprendre des représentations globales et contextuelles à partir des entrées lidar. En introduisant une supervision auxiliaire au niveau des fonctionnalités en simulant des fonctionnalités plus robustes et de haute qualité, le détecteur peut promouvoir des améliorations marginales. Inspiré par cela, une solution naturelle pour gérer la fusion des fonctionnalités des caméras lidar consiste à fournir des fonctionnalités plus puissantes et de haute qualité et à introduire une supervision auxiliaire pour la détection 3D des caméras lidar !
Afin d'améliorer les performances de la détection 3D fusionnée basée sur les caméras lidar, cet article propose une méthode de fusion de caméras lidar supervisée appelée SupFusion. Cette méthode y parvient en générant des fonctionnalités de haute qualité et en fournissant une supervision efficace des processus de fusion et d'extraction de fonctionnalités. Tout d’abord, nous formons un modèle auxiliaire pour fournir des fonctionnalités de haute qualité. Contrairement aux méthodes précédentes qui exploitent des modèles plus grands ou des données supplémentaires, nous proposons une nouvelle méthode d'augmentation des données appelée Polar Sampling. L'échantillonnage polaire améliore dynamiquement la densité des cibles à partir de données lidar clairsemées, ce qui les rend plus faciles à détecter et améliore la qualité des caractéristiques, comme des résultats de détection précis. Nous formons ensuite simplement un détecteur basé sur la fusion de caméras lidar et introduisons une supervision auxiliaire au niveau des fonctionnalités. Au cours de cette étape, nous introduisons les entrées brutes du lidar et de la caméra dans le module de base et de fusion 3D/2D pour obtenir des fonctionnalités fusionnées. Les fonctionnalités fusionnées sont introduites dans la tête de détection pour la prédiction finale, tandis que la supervision auxiliaire modélise les fonctionnalités fusionnées en fonctionnalités de haute qualité. Ces fonctionnalités sont obtenues grâce à des modèles auxiliaires pré-entraînés et à des données lidar améliorées. De cette manière, la supervision proposée au niveau des fonctionnalités peut permettre au module de fusion de générer des fonctionnalités plus robustes et d’améliorer encore les performances de détection. Pour mieux fusionner les fonctionnalités du lidar et de la caméra, nous proposons un module de fusion profonde simple et efficace, composé de blocs MLP empilés et de blocs de fusion dynamique. SupFusion peut exploiter pleinement les capacités du module de fusion profonde et améliorer continuellement la précision de la détection !
Principales contributions de cet article :
- Propose une nouvelle stratégie de formation à la fusion supervisée SupFusion, qui consiste principalement en un processus de génération de fonctionnalités de haute qualité, et propose pour la première fois une perte supervisée auxiliaire au niveau des fonctionnalités pour une extraction robuste des fonctionnalités de fusion et une détection 3D précise.
- Afin d'obtenir des fonctionnalités de haute qualité dans SupFusion, une méthode d'augmentation des données appelée "Polar Sampling" est proposée pour crypter des cibles clairsemées. De plus, un module de fusion profonde efficace est proposé pour améliorer continuellement la précision de la détection.
- Réalisation d'expériences approfondies basées sur plusieurs détecteurs avec différentes stratégies de fusion et obtenu une amélioration mAP d'environ 2 % par rapport au benchmark KITTI.
La méthode proposée
Le processus de génération de caractéristiques de haute qualité est illustré dans la figure ci-dessous pour tout échantillon LiDAR donné, la cible clairsemée est cryptée par collage polaire, et le collage polaire calcule l'orientation et la rotation à extraire. à partir de la base de données. Recherchez des cibles denses et ajoutez des points supplémentaires pour les cibles clairsemées en les collant. Cet article entraîne d'abord le modèle auxiliaire avec des données améliorées et introduit les données lidar améliorées dans le modèle auxiliaire pour générer des caractéristiques f* de haute qualité après sa convergence.
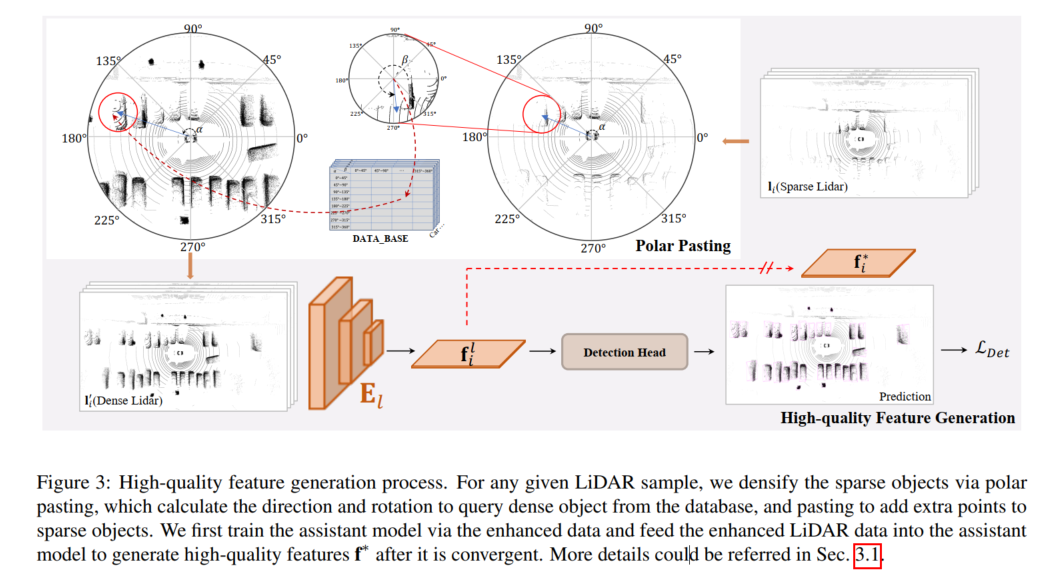
Génération de fonctionnalités de haute qualité
Pour fournir une supervision au niveau des fonctionnalités dans SupFusion, un modèle auxiliaire est adopté pour capturer des fonctionnalités de haute qualité à partir des données augmentées, comme le montre la figure 3. Tout d’abord, un modèle auxiliaire est formé pour fournir des fonctionnalités de haute qualité. Pour tout échantillon dans D, les données lidar clairsemées sont augmentées pour obtenir des données améliorées par collage polaire, qui crypte la cible alternative en ajoutant l'ensemble de points générés dans le groupement polaire. Ensuite, après la convergence du modèle auxiliaire, les échantillons améliorés sont entrés dans le modèle auxiliaire optimisé pour capturer des caractéristiques de haute qualité pour entraîner le modèle de détection 3D de la caméra lidar. Afin de mieux s'appliquer à un détecteur de caméra lidar donné et de faciliter sa mise en œuvre, nous adoptons ici simplement le détecteur de branche lidar comme modèle auxiliaire !
Formation des détecteurs
Pour tout détecteur de caméra lidar donné, le modèle est formé à l'aide de la supervision auxiliaire proposée au niveau des fonctionnalités. Étant donné un échantillon , , le lidar et la caméra sont d'abord entrés dans les encodeurs 3D et 2D et pour capturer les caractéristiques correspondantes et ces caractéristiques sont entrées dans le modèle de fusion pour générer les caractéristiques fusionnées et passer à la détection. Faire la prédiction finale dans ta tête. De plus, la supervision auxiliaire proposée est utilisée pour simuler des fonctionnalités fusionnées avec des fonctionnalités de haute qualité générées à partir du modèle auxiliaire pré-entraîné et des données lidar améliorées. Le processus ci-dessus peut être formulé comme :
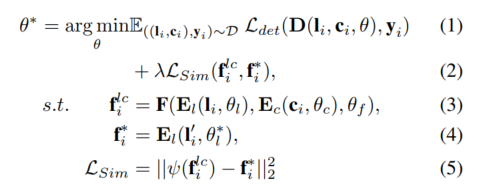
Polar Sampling
Afin de fournir des fonctionnalités de haute qualité, cet article introduit une nouvelle méthode d'amélioration des données appelée Polar Sampling dans le SupFusion proposé pour résoudre le problème clairsemé. Ce problème provoque fréquemment des échecs de détection. À cette fin, nous effectuons un traitement dense des cibles clairsemées dans les données lidar, de la même manière que les cibles denses sont traitées. L'échantillonnage de coordonnées polaires se compose de deux parties : le regroupement de coordonnées polaires et le collage de coordonnées polaires. Dans le regroupement de coordonnées polaires, nous construisons principalement une base de données pour stocker les cibles denses, qui est utilisée pour le collage des coordonnées polaires, afin que les cibles clairsemées deviennent plus denses
Compte tenu des caractéristiques du capteur lidar, les données de nuage de points collectées sont naturellement Il existe un répartition de la densité. Par exemple, un objet a plus de points sur sa surface faisant face au capteur lidar et moins de points sur les côtés opposés. La distribution de la densité est principalement affectée par l'orientation et la rotation, tandis que la densité des points dépend principalement de la distance. Les objets plus proches du capteur lidar ont une densité de points plus dense. Inspiré par cela, l'objectif de cet article est de densifier les cibles clairsemées à longue distance et les cibles denses à courte distance en fonction de la direction et de la rotation des cibles clairsemées afin de maintenir la distribution de densité. Nous établissons un système de coordonnées polaires pour l'ensemble de la scène et la cible en fonction du centre de la scène et de la cible spécifique, et définissons la direction positive du capteur lidar comme 0 degré pour mesurer la direction et la rotation correspondantes. Nous collectons ensuite des cibles avec des distributions de densité similaires (par exemple avec une orientation et une rotation similaires) et générons une cible dense pour chaque groupe en groupements polaires et l'utilisons dans une pâte polaire pour denser des cibles clairsemées
Groupement polaire
Comme le montre la figure 4. , une base de données B est construite ici pour stocker l'ensemble de points d'objets denses généré l en fonction de la direction et de la rotation dans le groupement polaire, qui sont enregistrées comme α et β sur la figure 4 !
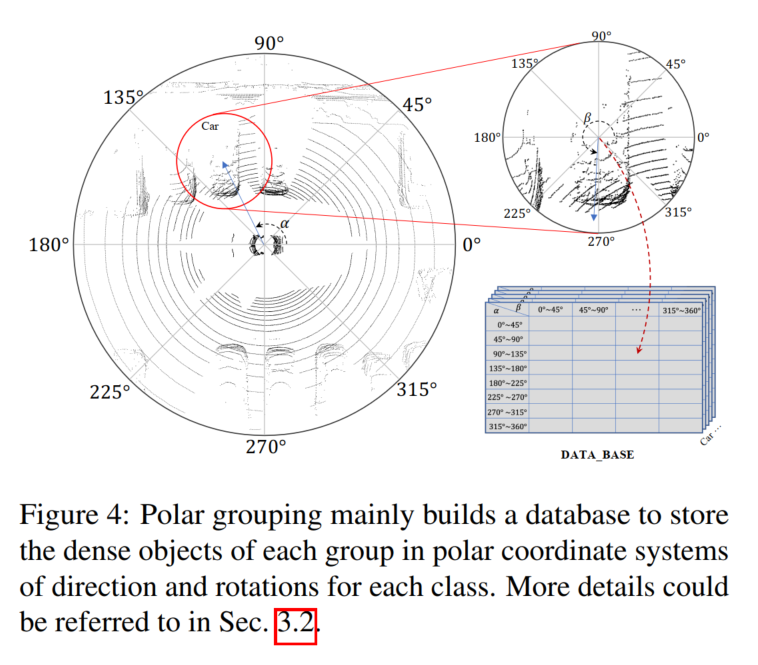
Tout d'abord, recherchez l'intégralité de l'ensemble de données, calculez l'angle polaire de toutes les cibles par position et fournissez une rotation dans le benchmark. Deuxièmement, divisez les cibles en groupes en fonction de leurs angles polaires. Divisez manuellement l'orientation et la rotation en N groupes, et pour tout point cible défini l, vous pouvez le mettre dans le groupe correspondant en fonction de l'index :
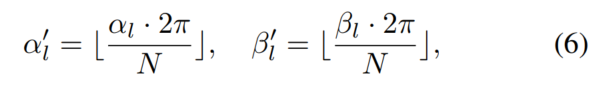
Polar Pasting
Comme le montre la figure 2, le collage polaire est utilisé pour améliorer les données lidar clairsemées afin de former des modèles auxiliaires et de générer des fonctionnalités de haute qualité. Étant donné qu'un échantillon LiDAR ,,,, contient des cibles, pour toute cible, la même orientation et la même rotation que le processus de regroupement peuvent être calculées et les cibles denses sont interrogées à partir de B en fonction de l'étiquette et de l'index, qui peuvent être obtenus à partir de l'équation. 6 pour des échantillons améliorés Toutes les cibles et obtenez des statistiques améliorées.
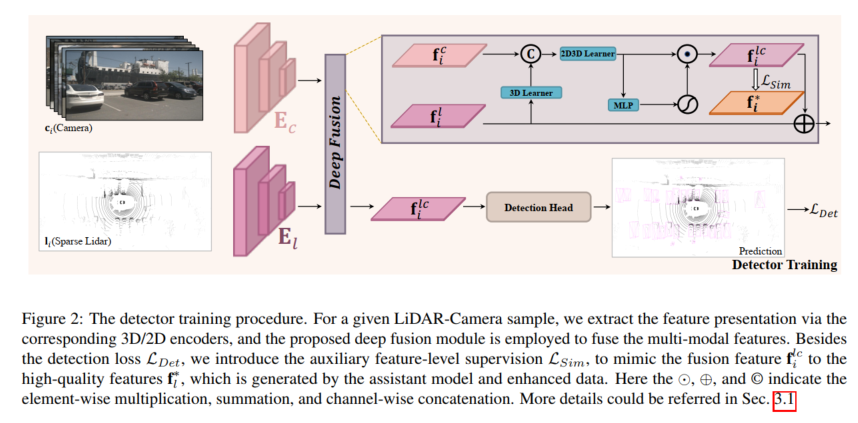
Deep Fusion
Pour simuler les caractéristiques de haute qualité générées par les données lidar améliorées, le modèle de fusion est conçu pour extraire les informations manquantes des cibles clairsemées des riches couleurs et des caractéristiques contextuelles de l'entrée de la caméra. À cette fin, cet article propose un module de fusion profonde pour utiliser les caractéristiques de l'image et des démonstrations lidar complètes. La fusion profonde proposée consiste principalement en un apprenant 3D et un apprenant 2D-3D. L'apprenant 3D est une simple couche convolutive utilisée pour transférer des rendus 3D dans un espace 2D. Ensuite, pour connecter les fonctionnalités 2D et les rendus 3D (par exemple, dans un espace 2D), un apprenant 2D-3D est utilisé pour fusionner les fonctionnalités de la caméra LiDAR. Enfin, les fonctionnalités fusionnées sont pondérées par les fonctions MLP et d'activation, qui sont rajoutées aux fonctionnalités lidar d'origine en tant que sortie du module de fusion profonde. L'apprenant 2D-3D se compose de blocs MLP empilés de profondeur K et apprend à exploiter les fonctionnalités de la caméra pour compléter les représentations lidar de cibles clairsemées afin de simuler des caractéristiques de haute qualité de cibles lidar denses.
Analyse comparative expérimentale
Résultats expérimentaux (mAP@R40%). Voici trois catégories de cas faciles, moyens (mod.) et difficiles, ainsi que les performances globales. Ici, L, LC, LC* représentent le détecteur lidar correspondant, le détecteur de fusion de caméra lidar et les résultats de la proposition de cet article. Δ représente l’amélioration. Les meilleurs résultats sont affichés en gras, où L devrait être le modèle auxiliaire et testé sur l'ensemble de validation augmenté. MVXNet est réimplémenté sur la base de mmdetection3d. PV-RCNN-LC et Voxel RCNN LC sont réimplémentés sur la base du code open source de VFF.
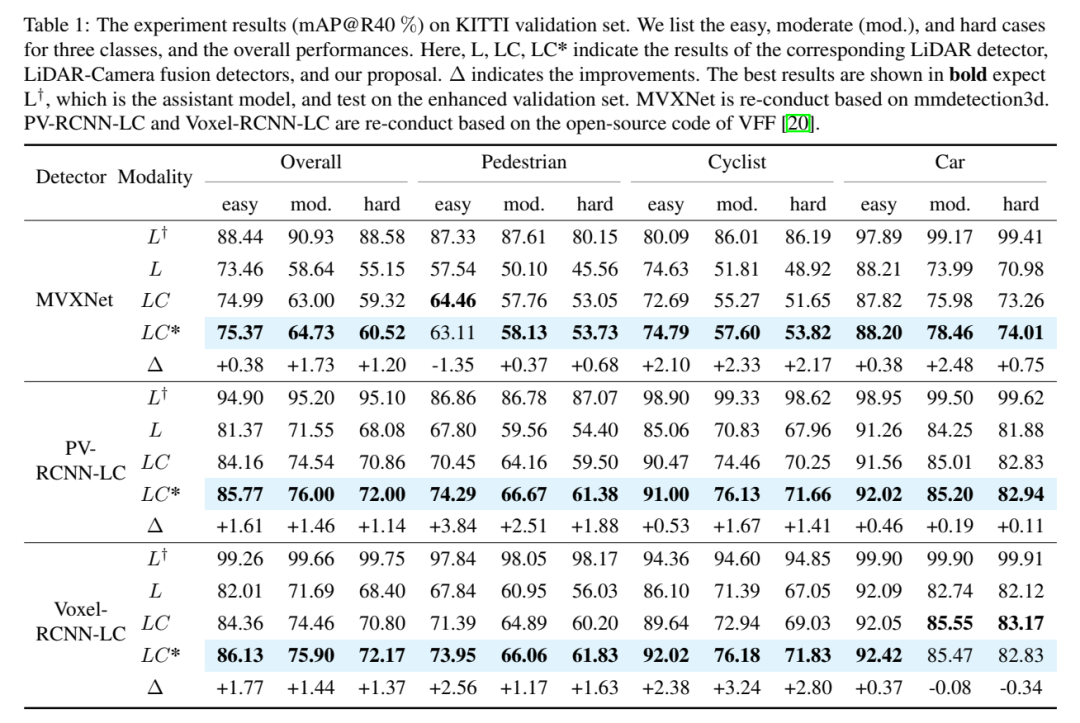
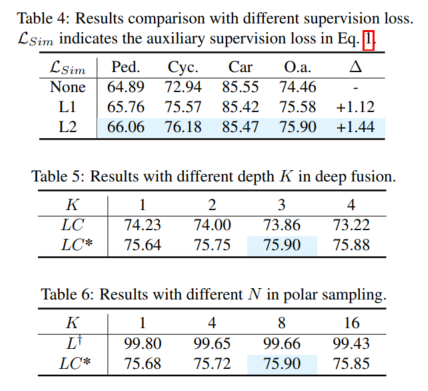
Contenu réécrit : Performance globale. Selon les résultats de la comparaison dans le tableau 1, la comparaison du 3DmAP@R40 basée sur trois détecteurs montre les performances globales de chaque catégorie et de chaque division de difficulté. On peut clairement observer qu'en introduisant une entrée de caméra supplémentaire, la méthode de caméra lidar (LC) surpasse le détecteur basé sur lidar (L) en termes de performances. En introduisant l'échantillonnage polaire, le modèle auxiliaire (L†) montre des performances admirables sur l'ensemble de validation augmenté (par exemple, plus de 90 % de mAP). Avec une supervision auxiliaire dotée de fonctionnalités de haute qualité et le module de fusion profonde proposé, notre proposition améliore continuellement la précision de la détection. Par exemple, par rapport au modèle de base (LC), notre proposition permet d'obtenir des améliorations mAP 3D de +1,54 % et +1,24 % sur les cibles moyennes et dures, respectivement. De plus, nous avons également mené des expériences sur le benchmark nuScenes basé sur SECOND-LC. Comme le montre le tableau 2, NDS et mAP ont été améliorés de +2,01 % et +1,38 % respectivement
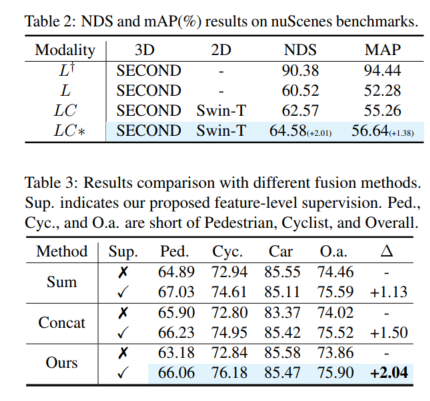
analyse d'amélioration de la perception de classe. Par rapport au modèle de base, SupFusion et la fusion profonde améliorent non seulement les performances globales, mais également les performances de détection de chaque catégorie, y compris les piétons. En comparant l'amélioration moyenne dans trois catégories (par exemple, cas moyen), les observations suivantes peuvent être faites : Les cyclistes ont vu. la plus forte amélioration (+2,41%), tandis que les piétons et les voitures ont connu des améliorations de +1,35% et +0,86% respectivement. Les raisons sont évidentes : (1) Les voitures sont plus faciles à repérer et obtiennent de meilleurs résultats que les piétons et les cyclistes, et donc plus difficiles à améliorer. (2) Les cyclistes obtiennent plus d'améliorations que les piétons car les piétons ne sont pas en grille et génèrent des cibles moins denses que les cyclistes et obtiennent donc des améliorations de performances moindres !

Veuillez cliquer sur le lien suivant pour voir le contenu original : https://mp.weixin.qq.com/s/vWew2p9TrnzK256y-A4UFw
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1393
1393
 52
1207
24
52
1207
24

 Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
0. À quoi sert cet article ? Nous proposons DepthFM : un modèle d'estimation de profondeur monoculaire génératif de pointe, polyvalent et rapide. En plus des tâches traditionnelles d'estimation de la profondeur, DepthFM démontre également des capacités de pointe dans les tâches en aval telles que l'inpainting en profondeur. DepthFM est efficace et peut synthétiser des cartes de profondeur en quelques étapes d'inférence. Lisons ce travail ensemble ~ 1. Titre des informations sur l'article : DepthFM : FastMonocularDepthEstimationwithFlowMatching Auteur : MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Hier, lors de l'entretien, on m'a demandé si j'avais posé des questions à longue traîne, j'ai donc pensé faire un bref résumé. Le problème à longue traîne de la conduite autonome fait référence aux cas extrêmes dans les véhicules autonomes, c'est-à-dire à des scénarios possibles avec une faible probabilité d'occurrence. Le problème perçu de la longue traîne est l’une des principales raisons limitant actuellement le domaine de conception opérationnelle des véhicules autonomes intelligents à véhicule unique. L'architecture sous-jacente et la plupart des problèmes techniques de la conduite autonome ont été résolus, et les 5 % restants des problèmes à longue traîne sont progressivement devenus la clé pour restreindre le développement de la conduite autonome. Ces problèmes incluent une variété de scénarios fragmentés, de situations extrêmes et de comportements humains imprévisibles. La « longue traîne » des scénarios limites dans la conduite autonome fait référence aux cas limites dans les véhicules autonomes (VA). Les cas limites sont des scénarios possibles avec une faible probabilité d'occurrence. ces événements rares
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Au cours du mois dernier, pour des raisons bien connues, j'ai eu des échanges très intensifs avec divers professeurs et camarades de classe du secteur. Un sujet inévitable dans l'échange est naturellement le populaire Tesla FSDV12 de bout en bout. Je voudrais profiter de cette occasion pour trier certaines de mes pensées et opinions en ce moment pour votre référence et votre discussion. Comment définir un système de conduite autonome de bout en bout et quels problèmes devraient être résolus de bout en bout ? Selon la définition la plus traditionnelle, un système de bout en bout fait référence à un système qui saisit les informations brutes des capteurs et génère directement les variables pertinentes pour la tâche. Par exemple, en reconnaissance d'images, CNN peut être appelé de bout en bout par rapport à la méthode traditionnelle d'extraction de caractéristiques + classificateur. Dans les tâches de conduite autonome, saisir les données de divers capteurs (caméra/LiDAR
 La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
Je pleure à mort. Le monde construit à la folie de grands modèles. Les données sur Internet ne suffisent pas du tout. Le modèle de formation ressemble à « The Hunger Games », et les chercheurs en IA du monde entier se demandent comment nourrir ces personnes avides de données. Ce problème est particulièrement important dans les tâches multimodales. À une époque où rien ne pouvait être fait, une équipe de start-up du département de l'Université Renmin de Chine a utilisé son propre nouveau modèle pour devenir la première en Chine à faire de « l'auto-alimentation des données générées par le modèle » une réalité. De plus, il s’agit d’une approche à deux volets, du côté compréhension et du côté génération, les deux côtés peuvent générer de nouvelles données multimodales de haute qualité et fournir un retour de données au modèle lui-même. Qu'est-ce qu'un modèle ? Awaker 1.0, un grand modèle multimodal qui vient d'apparaître sur le Forum Zhongguancun. Qui est l'équipe ? Moteur Sophon. Fondé par Gao Yizhao, doctorant à la Hillhouse School of Artificial Intelligence de l’Université Renmin.
 FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
La détection de cibles est un problème relativement mature dans les systèmes de conduite autonome, parmi lesquels la détection des piétons est l'un des premiers algorithmes à être déployés. Des recherches très complètes ont été menées dans la plupart des articles. Cependant, la perception de la distance à l’aide de caméras fisheye pour une vue panoramique est relativement moins étudiée. En raison de la distorsion radiale importante, la représentation standard du cadre de délimitation est difficile à mettre en œuvre dans les caméras fisheye. Pour alléger la description ci-dessus, nous explorons les conceptions étendues de boîtes englobantes, d'ellipses et de polygones généraux dans des représentations polaires/angulaires et définissons une métrique de segmentation d'instance mIOU pour analyser ces représentations. Le modèle fisheyeDetNet proposé avec une forme polygonale surpasse les autres modèles et atteint simultanément 49,5 % de mAP sur l'ensemble de données de la caméra fisheye Valeo pour la conduite autonome.
 La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
Quoi? Zootopie est-elle concrétisée par l’IA domestique ? Avec la vidéo est exposé un nouveau modèle de génération vidéo domestique à grande échelle appelé « Keling ». Sora utilise une voie technique similaire et combine un certain nombre d'innovations technologiques auto-développées pour produire des vidéos qui comportent non seulement des mouvements larges et raisonnables, mais qui simulent également les caractéristiques du monde physique et possèdent de fortes capacités de combinaison conceptuelle et d'imagination. Selon les données, Keling prend en charge la génération de vidéos ultra-longues allant jusqu'à 2 minutes à 30 ips, avec des résolutions allant jusqu'à 1080p, et prend en charge plusieurs formats d'image. Un autre point important est que Keling n'est pas une démo ou une démonstration de résultats vidéo publiée par le laboratoire, mais une application au niveau produit lancée par Kuaishou, un acteur leader dans le domaine de la vidéo courte. De plus, l'objectif principal est d'être pragmatique, de ne pas faire de chèques en blanc et de se mettre en ligne dès sa sortie. Le grand modèle de Ke Ling est déjà sorti à Kuaiying.
 NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
Écrit à l'avant et point de départ Le paradigme de bout en bout utilise un cadre unifié pour réaliser plusieurs tâches dans les systèmes de conduite autonome. Malgré la simplicité et la clarté de ce paradigme, les performances des méthodes de conduite autonome de bout en bout sur les sous-tâches sont encore loin derrière les méthodes à tâche unique. Dans le même temps, les fonctionnalités de vue à vol d'oiseau (BEV) denses, largement utilisées dans les méthodes de bout en bout précédentes, rendent difficile l'adaptation à davantage de modalités ou de tâches. Un paradigme de conduite autonome de bout en bout (SparseAD) centré sur la recherche clairsemée est proposé ici, dans lequel la recherche clairsemée représente entièrement l'ensemble du scénario de conduite, y compris l'espace, le temps et les tâches, sans aucune représentation BEV dense. Plus précisément, une architecture clairsemée unifiée est conçue pour la connaissance des tâches, notamment la détection, le suivi et la cartographie en ligne. De plus, lourd
