
 Périphériques technologiques
IA
Comment créer un système d'expérimentation AB dans des scénarios de croissance des utilisateurs ?
Périphériques technologiques
IA
Comment créer un système d'expérimentation AB dans des scénarios de croissance des utilisateurs ?
Comment créer un système d'expérimentation AB dans des scénarios de croissance des utilisateurs ?


1. Problèmes rencontrés par les expériences dans de nouveaux scénarios utilisateur
1. Panorama UG
C'est le panorama de l'UG.
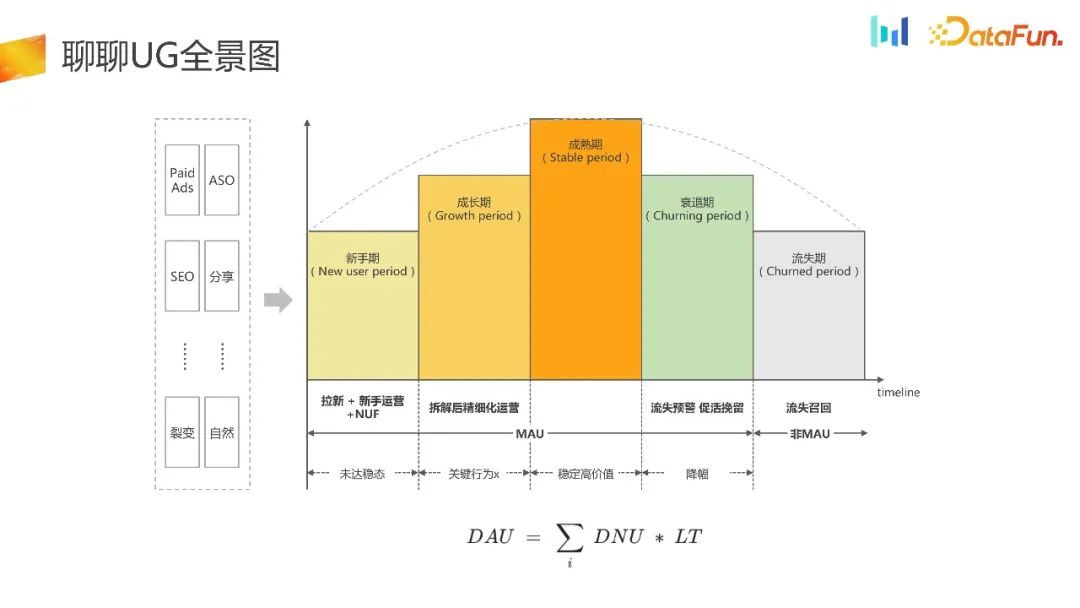
UG Acquérir des clients et détourner le trafic vers l'APP via des canaux tels que les publicités payantes, l'ASO, le référencement et d'autres canaux. Ensuite, nous ferons quelques opérations et conseils pour les novices pour activer les utilisateurs et les amener au stade de maturité. Les utilisateurs suivants peuvent progressivement devenir inactifs, entrer dans une période de refus ou même entrer dans une période de désabonnement. Pendant cette période, nous effectuerons des alertes précoces en cas de désabonnement, des rappels pour promouvoir l'activation, et plus tard des rappels pour les utilisateurs perdus.
peut être résumée par la formule de la figure ci-dessus, c'est-à-dire que DAU est égal à DNU multiplié par LT. Tous les travaux du scénario UG peuvent être démantelés sur la base de cette formule.
2. Principe de l'expérience AB
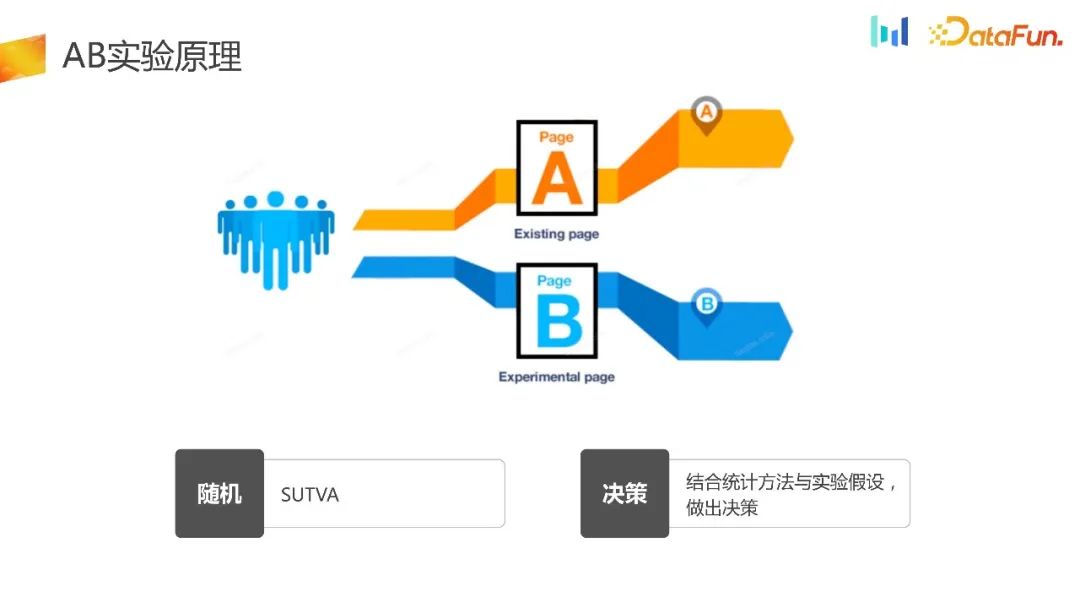
Le but de l'expérience AB est d'attribuer le trafic de manière complètement aléatoire et d'utiliser différentes stratégies pour le groupe expérimental et différents groupes témoins. Enfin, les décisions scientifiques sont prises en combinant méthodes statistiques et hypothèses expérimentales, ce qui constitue le cadre de l'ensemble de l'expérience. Actuellement, les types de distribution expérimentale sur le marché sont grossièrement divisés en deux types : la distribution sur plate-forme expérimentale et la distribution locale client
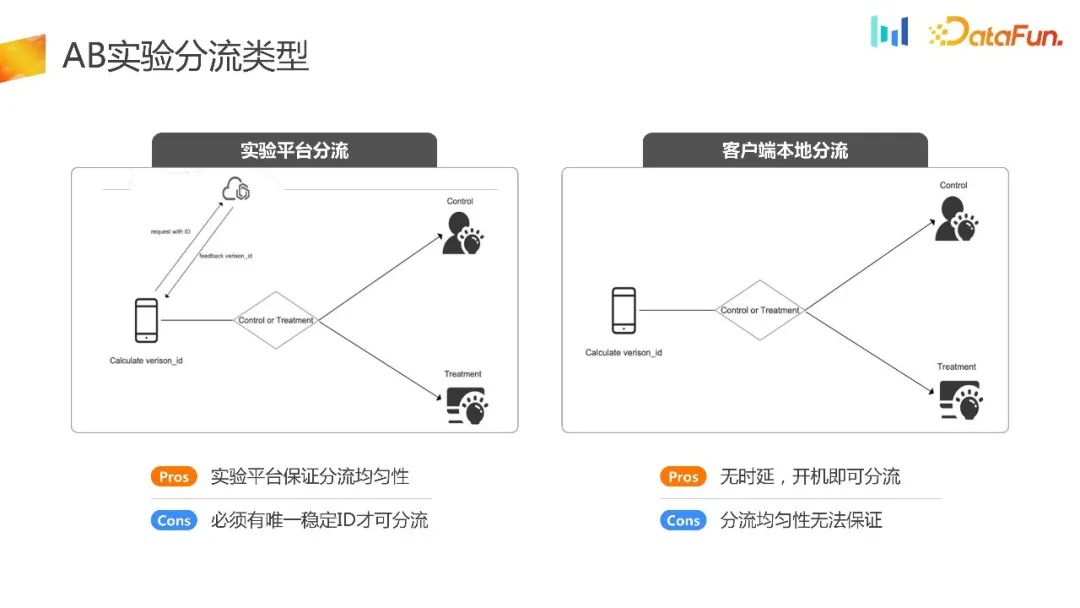
La distribution sur plate-forme expérimentale a une condition préalable. Elle nécessite que l'appareil puisse obtenir un identifiant stable après l'initialisation. Sur cette base, l'ID demande à la plate-forme expérimentale de compléter la logique liée au déchargement, renvoie l'ID de déchargement au terminal, puis le terminal élabore les stratégies correspondantes en fonction de l'ID reçu. Son avantage est qu’il dispose d’une plateforme expérimentale capable d’assurer l’uniformité et la stabilité du shunt. Son inconvénient est que l'équipement doit être initialisé avant de pouvoir effectuer un shuntage expérimental.
Une autre méthode de déchargement est le déchargement local côté client. Cette méthode est relativement niche et convient principalement à certaines scènes UG, scènes d'ouverture d'écran publicitaire et scènes d'initialisation de performances. De cette façon, toute la logique de déchargement est terminée lorsque le client est initialisé. Ses avantages sont évidents, c'est-à-dire qu'il n'y a aucun délai et que la distribution peut être effectuée immédiatement après la mise sous tension. Logiquement, l'uniformité de sa distribution peut également être garantie. Cependant, dans les scénarios commerciaux réels, l’uniformité de sa distribution pose souvent des problèmes. Les raisons seront présentées ensuite
3. Problèmes rencontrés par le nouveau scénario utilisateur Expérience AB
UG Le premier problème réellement rencontré par le scénario est de détourner le trafic le plus tôt possible.
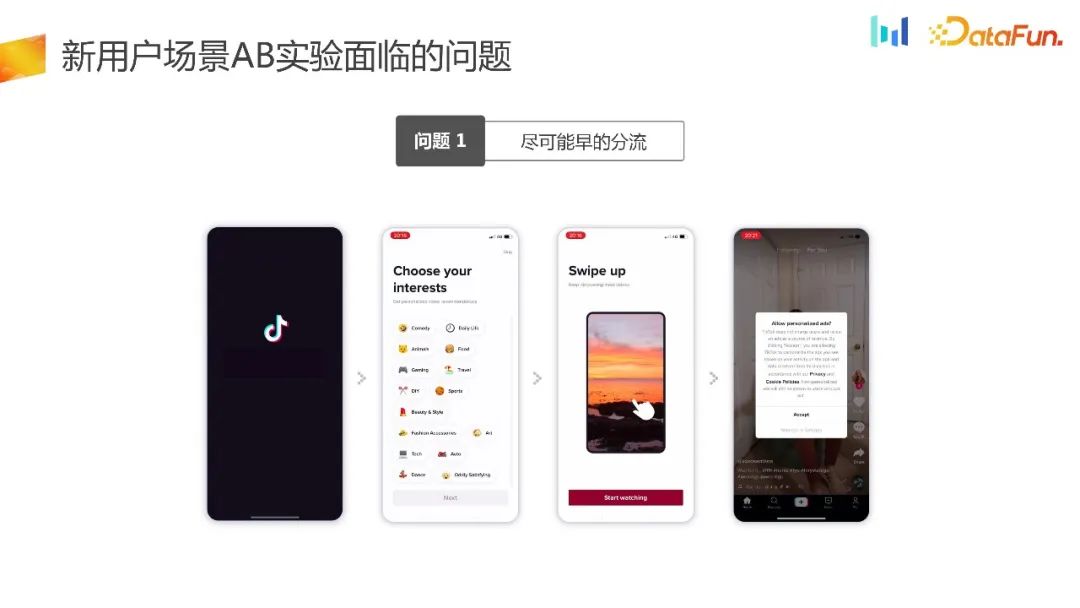
Voici un exemple, comme la page d'acceptation du trafic ici. Le chef de produit estime que l'interface utilisateur peut être optimisée pour améliorer les indicateurs de base. Dans un tel scénario, nous espérons que l’expérience sera triée le plus rapidement possible.
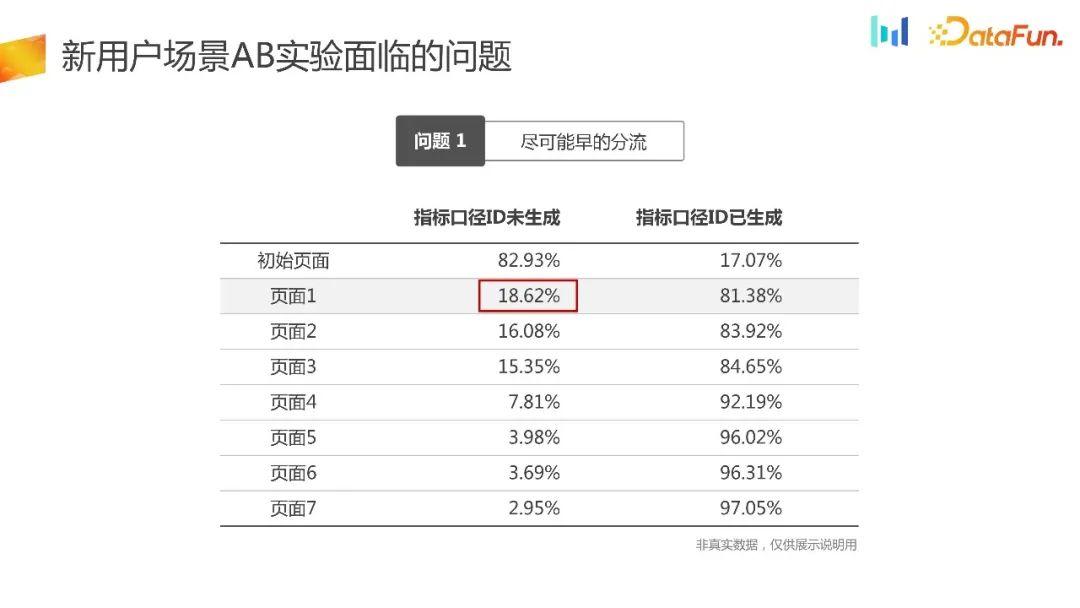
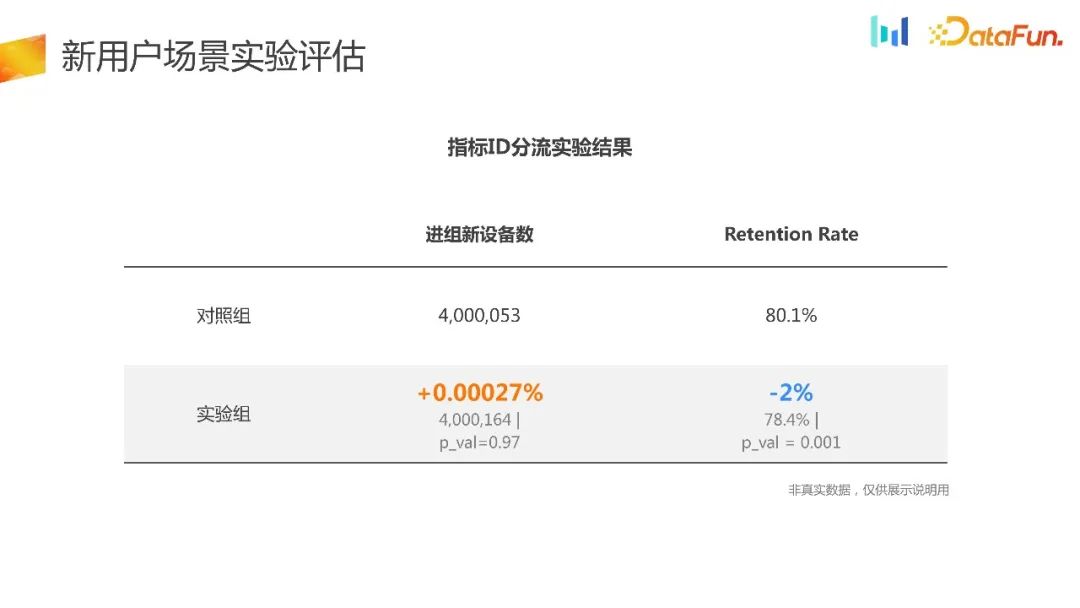
Pendant le processus de déchargement à la page 1, l'appareil sera initialisé et obtiendra l'ID. 18,62 % des utilisateurs ne peuvent pas générer d'identifiants. Si la méthode traditionnelle de détournement de plateforme expérimentale est utilisée, 18,62% des utilisateurs ne seront pas regroupés, ce qui entraînera un problème de biais de sélection inhérent
De plus, le trafic des nouveaux utilisateurs est très précieux, avec 18,62% de nouveaux utilisateurs Il ne peut pas être utilisé pour des expériences, et il y aura une grande perte dans la durée de l'expérience et dans l'efficacité de l'utilisation du trafic.
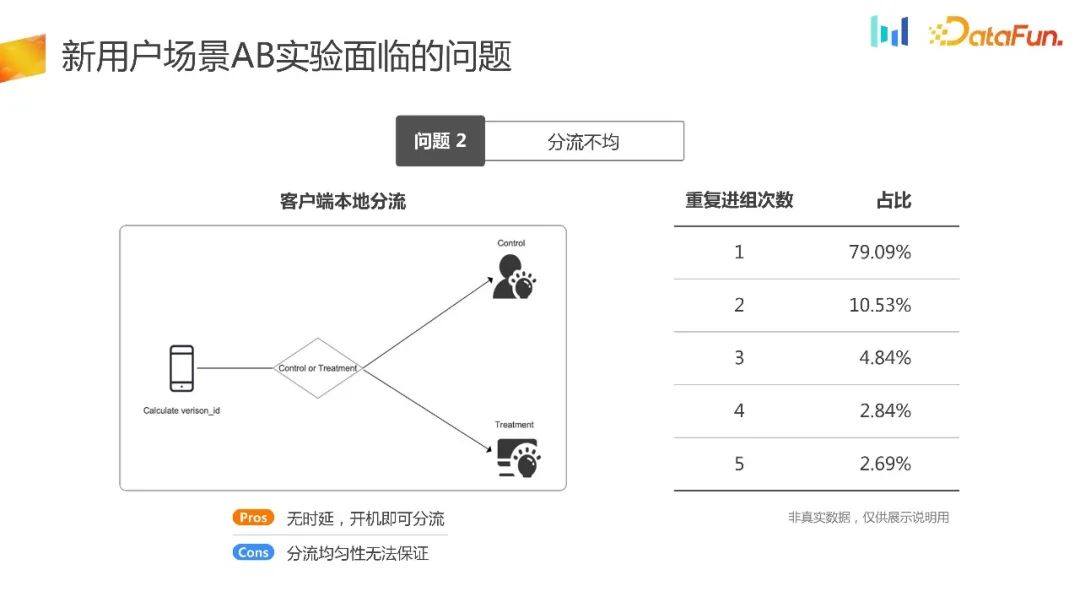
À l'avenir, pour résoudre le problème du déchargement des expériences le plus tôt possible, nous utiliserons le client pour décharger les expériences localement. L'avantage est que le déchargement est terminé lorsque l'appareil est initialisé. Le principe est que tout d'abord, lors de l'initialisation sur le terminal, celui-ci peut générer lui-même des nombres aléatoires, hacher les nombres aléatoires puis les regrouper de la même manière, générant ainsi un groupe expérimental et un groupe témoin. En principe, il devrait être possible de garantir que la répartition du trafic est uniforme. Cependant, grâce à l'ensemble des données de la figure ci-dessus, nous pouvons constater que plus de 21 % des utilisateurs entrent à plusieurs reprises dans différents groupes.
Il existe un scénario dans lequel les utilisateurs de certains produits très populaires, tels que Honor of Kings ou Douyin, deviennent facilement dépendants. Les nouveaux utilisateurs désinstalleront et réinstalleront plusieurs fois au cours du cycle expérimental. Selon la logique de détournement local que nous venons de mentionner, la génération et le détournement de nombres aléatoires permettront aux utilisateurs d'entrer dans différents groupes, de sorte que l'identifiant de détournement et l'identifiant statistique ne puissent pas correspondre un à un. Cela a posé le problème d’une répartition inégale.
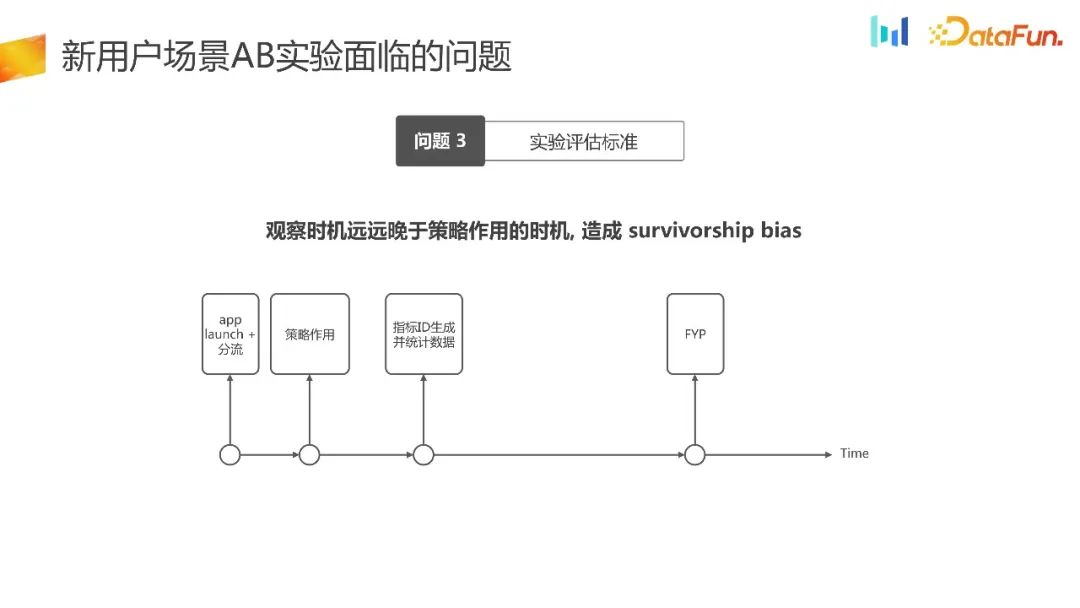
Dans les nouveaux scénarios d'utilisation, nous sommes également confrontés au problème des normes d'évaluation expérimentales.
Nous avons réorganisé le chronogramme du trafic des nouveaux utilisateurs prenant en charge ce scénario. Au démarrage de l'application, nous avons choisi de décharger. Supposons que nous puissions parvenir à un calendrier de distribution uniforme et produire en même temps les effets stratégiques correspondants. Ensuite, le moment de la génération de l’ID statistique de l’indicateur est postérieur au moment de l’effet de la stratégie, et ce n’est qu’alors que les données peuvent être observées. Le moment de l'observation des données est loin derrière le moment des effets de la stratégie, ce qui entraînera un biais de survie
2. Nouveau système expérimental et sa vérification scientifique
Afin de résoudre les problèmes ci-dessus, nous avons proposé un nouveau système expérimental système et l'a vérifié scientifiquement
1. Sélection de l'ID de détournement d'expérience de nouveau scénario utilisateur
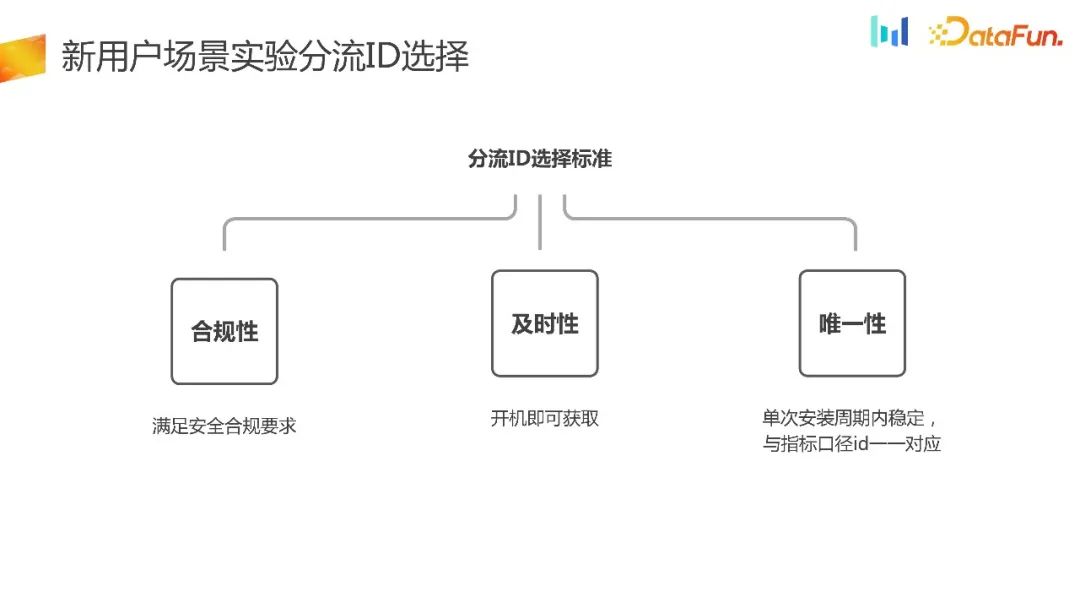
Comme mentionné précédemment, les exigences de sélection de détournement pour les nouveaux utilisateurs seront relativement élevées, alors comment choisir de nouvelles expériences utilisateur. ID de dérivation ? Voici quelques principes :
- La conformité, qu'il s'agisse d'une entreprise à l'étranger ou d'une entreprise nationale, la conformité en matière de sécurité est avant tout la bouée de sauvetage. La conformité en matière de sécurité doit être respectée, sinon l'impact sera particulièrement important une fois supprimé. des étagères.
- Rapidité, pour les nouveaux scénarios d'utilisateurs, elle doit être opportune et vous pouvez vous détourner dès que vous allumez le téléphone.
- Unicité, au sein d'un seul cycle d'installation, l'ID du shunt est stable et peut former une correspondance individuelle avec l'ID de l'indicateur. Comme le montrent les données de la figure ci-dessous, le rapport de correspondance de un pour un entre l'ID de détournement et l'ID de calibre de calcul de l'indicateur a atteint 99,79 %, et le rapport de un pour un entre l'ID de calcul de l'indicateur et le L'ID de détournement a également atteint 99,59 %. Fondamentalement, il peut être vérifié que l'ID de détournement et l'ID d'indicateur sélectionnés conformément à la norme peuvent obtenir une correspondance biunivoque.

2. Vérification scientifique de la capacité de déchargement
Après avoir sélectionné l'ID de déchargement, la capacité de déchargement est souvent complétée de deux manières, la première via la plate-forme expérimentale et la seconde jusqu'à la fin.
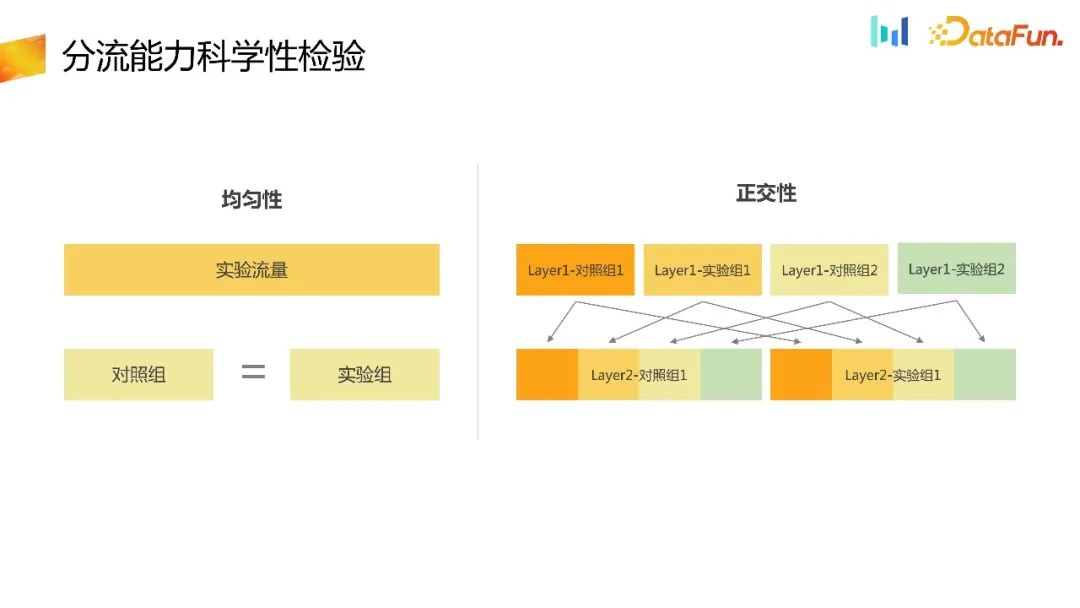
Après avoir obtenu l'ID de déchargement, fournissez l'ID de déchargement à la plate-forme expérimentale et complétez la capacité de déchargement dans la plate-forme expérimentale. En tant que plateforme de distribution, le plus élémentaire est de vérifier son caractère aléatoire. Le premier est l’uniformité. Dans la même couche d'expériences, le trafic est divisé uniformément en plusieurs compartiments et le nombre de groupes dans chaque compartiment doit être pair. Cela peut être simplifié ici. S'il n'y a qu'une seule expérience sur une couche et qu'elle est divisée en deux groupes, a et b, le nombre d'utilisateurs dans le groupe témoin et le groupe expérimental doit être approximativement égal, vérifiant ainsi l'uniformité de l'expérience. capacité de détournement. Deuxièmement, pour les expériences multicouches, les expériences multicouches doivent être orthogonales les unes aux autres et non affectées. De même, il est également nécessaire de vérifier l'orthogonalité entre les expériences réalisées sur différentes couches. L'uniformité et l'orthogonalité peuvent être vérifiées grâce à des tests de catégories statistiques.
Après avoir introduit l'ID de la sélection de détournement et la capacité de détournement, nous devons enfin vérifier si les résultats de détournement nouvellement proposés répondent aux exigences de l'expérience AB au niveau des résultats de l'indicateur.
3. Vérification scientifique des résultats de détournement
En utilisant la plateforme interne, nous avons effectué plusieurs simulations AA
pour comparer si le groupe témoin et le groupe expérimental répondaient aux exigences expérimentales sur les indicateurs correspondants. Examinons ensuite cet ensemble de données.

Nous avons échantillonné certains groupes d'indicateurs du test t. On peut comprendre que pour de nombreuses expériences, le taux d'erreur de type 1 devrait être avec une très faible probabilité. .055. %, son intervalle de confiance devrait en réalité être d'environ 1000 fois, ce qui devrait être compris entre 0,0365 et 0,0635. Vous pouvez voir que certains des indicateurs échantillonnés dans la première colonne se situent dans cette plage d'exécution, donc du point de vue du taux d'erreur de type 1, le système expérimental existant est OK.
En même temps, étant donné que le test est un test de la statistique t, la statistique t correspondante doit approximativement obéir à la distribution normale sous la distribution du grand trafic. Vous pouvez également tester la distribution normale de la statistique du test t. Le test de distribution normale est utilisé ici, et on peut voir que le résultat du test est également bien supérieur à 0,05, c'est-à-dire que l'hypothèse nulle est établie, c'est-à-dire que la statistique t obéit approximativement à la distribution normale.
Pour chaque test, la valeur p du résultat du test statistique t est distribuée à peu près uniformément dans autant d'expériences. En même temps, la valeur p peut également être testée pour une distribution uniforme, pvalue_uniform_test, ou en voyant des résultats similaires, c'est également le cas. beaucoup plus grand que 0,05. Par conséquent, l’hypothèse nulle selon laquelle la valeur p obéit approximativement à une distribution uniforme est également acceptable.
La correspondance biunivoque ci-dessus entre l'ID de déroutement et le calibre de calcul de l'indice, la capacité de détournement et les résultats de l'indicateur de résultat de détournement ont vérifié la nature scientifique du système de détournement expérimental nouvellement proposé.
3. Analyse de cas d'application
Ce qui suit sera combiné avec des cas d'application réels dans des scénarios UG pour expliquer en détail comment mener des évaluations expérimentales pour résoudre le troisième problème mentionné précédemment
1. Évaluation
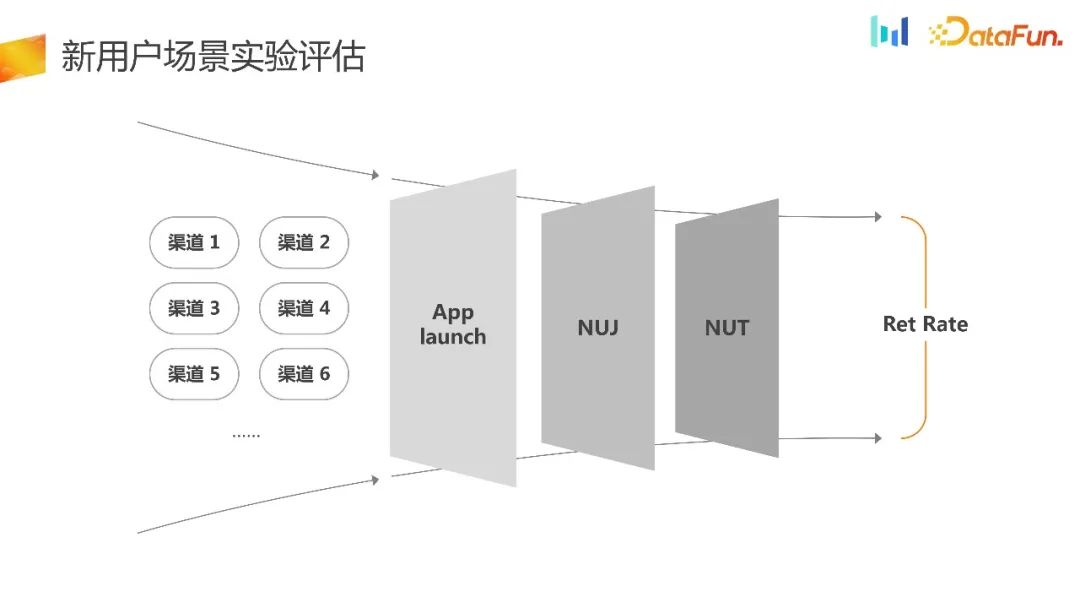
Il s'agit d'un scénario typique d'acceptation du trafic UG. De nombreuses optimisations seront effectuées lors du guidage des nouveaux utilisateurs NUJ ou des nouvelles tâches utilisateur pour améliorer l'utilisation du trafic. À l’heure actuelle, la norme d’évaluation est souvent le taux de rétention, qui est actuellement la compréhension commune dans l’industrie.
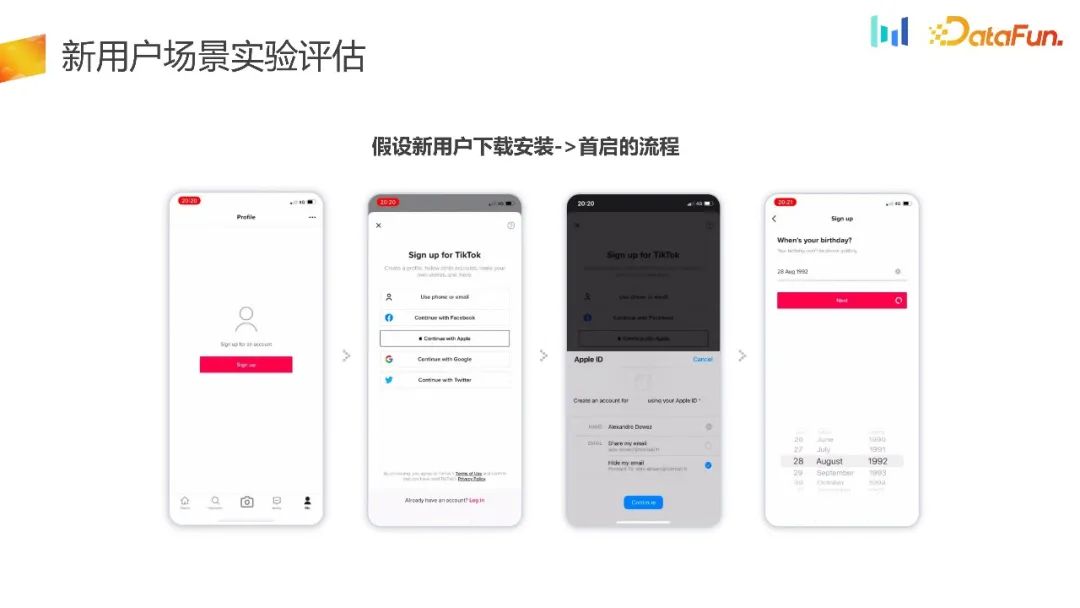
En supposant le processus allant du téléchargement d'un nouvel utilisateur à l'installation jusqu'au premier démarrage, le PM estime qu'un tel processus est trop élevé pour les utilisateurs, en particulier ceux qui n'ont jamais expérimenté l'utilisation du produit. Il n'est pas nécessaire de laisser les utilisateurs au préalable. familiarisez-vous avec le produit et vivez le moment hip-hop du produit, puis guidez-les pour se connecter.
En outre, le chef de produit a proposé une autre hypothèse, qui consiste à réduire la résistance lors de la connexion d'un nouvel utilisateur ou dans les scénarios NUJ de nouveaux utilisateurs pour les utilisateurs qui n'ont jamais expérimenté le produit. Pour les utilisateurs qui ont déjà expérimenté le produit et les utilisateurs qui ont changé d'appareil, le processus en ligne est toujours utilisé. La méthode de détournement basée sur l'ID de l'indicateur obtient d'abord l'ID de l'indicateur, puis effectue le détournement. Cette méthode de division est généralement uniforme et il n’y a pas beaucoup de différence par rapport aux résultats expérimentaux et au taux de rétention. A en juger par ces résultats, il est difficile de prendre une décision globale. Ce type d’expérience gaspille en réalité une partie du trafic et pose le problème du biais de sélection. Par conséquent, nous allons mener une expérience de déchargement local. La figure ci-dessous montre les résultats de l'expérience de déchargement local. Il y aura une différence significative dans le nombre de nouveaux appareils ajoutés au groupe, et c'est sûr. Dans le même temps, il y a une amélioration du taux de rétention, mais il est en réalité négatif pour d’autres indicateurs de base, et cette direction négative est difficile à comprendre car elle est en réalité fortement liée à la rétention. Par conséquent, sur la base de telles données, il est difficile de l’expliquer ou de l’attribuer, et il est également difficile de prendre des décisions globales.
 Vous pouvez observer la situation des utilisateurs qui sont entrés à plusieurs reprises dans des groupes, et vous constaterez que plus de 20 % des utilisateurs sont affectés à plusieurs reprises à différents groupes. Cela détruit le caractère aléatoire de l'expérience AB et rend difficile la prise de décisions de comparaison scientifique
Vous pouvez observer la situation des utilisateurs qui sont entrés à plusieurs reprises dans des groupes, et vous constaterez que plus de 20 % des utilisateurs sont affectés à plusieurs reprises à différents groupes. Cela détruit le caractère aléatoire de l'expérience AB et rend difficile la prise de décisions de comparaison scientifique
Enfin, jetez un œil aux résultats des expériences avec le nouveau shunt proposé.
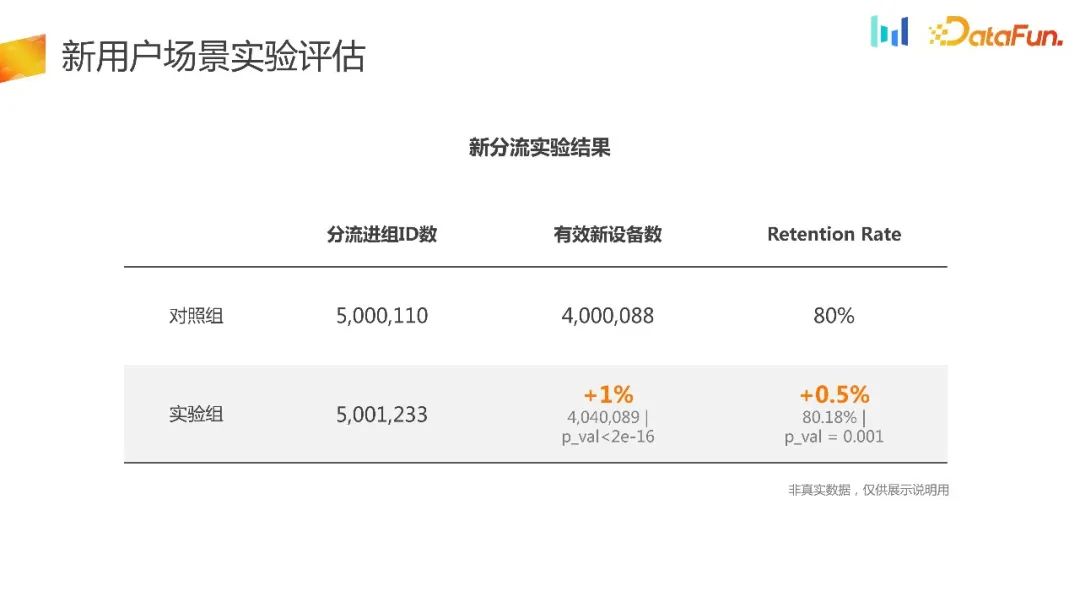
Il peut être détourné lorsqu'il est allumé. La capacité de détournement est garantie par la plate-forme interne, qui peut assurer dans une large mesure l'uniformité et la stabilité du détournement. À en juger par les données expérimentales, c'est presque proche. En effectuant le test de racine carrée, on peut également voir qu'il répond pleinement aux besoins. Dans le même temps, nous constatons que le nombre de nouveaux dispositifs efficaces a augmenté de manière significative, de 1 %, et que le taux de rétention s’est également amélioré. Dans le même temps, si vous regardez le groupe témoin ou le groupe expérimental seul, vous pouvez voir le taux de conversion du trafic basé sur l'ID de détournement vers le nouvel appareil finalement généré. Le groupe expérimental est 1 % plus élevé que le groupe témoin. La raison de ce résultat est que le groupe expérimental a en fait élargi le point d'entrée de l'utilisateur dans NUJ et NUT, facilitant ainsi l'entrée d'un plus grand nombre d'utilisateurs, l'expérience du produit, puis leur séjour.
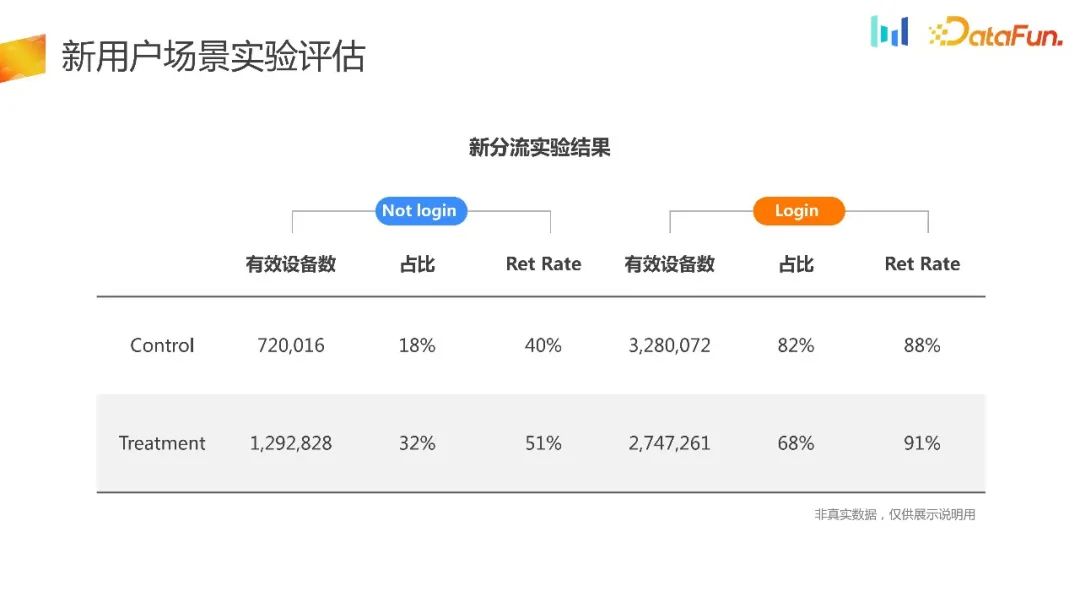
Divisez les données expérimentales en parties de connexion et sans connexion. On constate que pour les utilisateurs du groupe expérimental, davantage d'utilisateurs choisissent le mode sans connexion pour découvrir le produit, et le taux de rétention a également augmenté. amélioré. Les résultats sont également conformes aux attentes
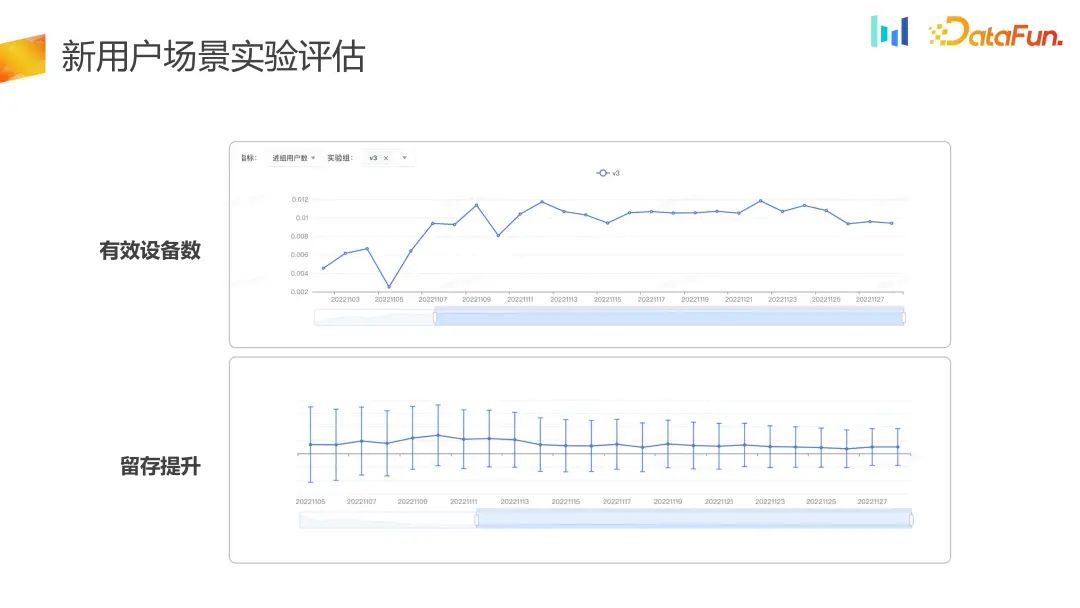
Vous pouvez voir l'indicateur par jour. Le nombre d'utilisateurs entrant dans le groupe est en fait écrit sur une longue période de temps. augmente régulièrement et l'indicateur de rétention s'est également amélioré. Par rapport au groupe témoin, le groupe expérimental s'est amélioré en termes de nombre de dispositifs efficaces et de rétention.
Pour le scénario d'acceptation du trafic de nouveaux utilisateurs, les indicateurs d'évaluation sont davantage évalués sous la dimension de rétention ou LT à court terme. Ici, l'optimisation n'est en fait effectuée que sur l'espace unidimensionnel au niveau LT
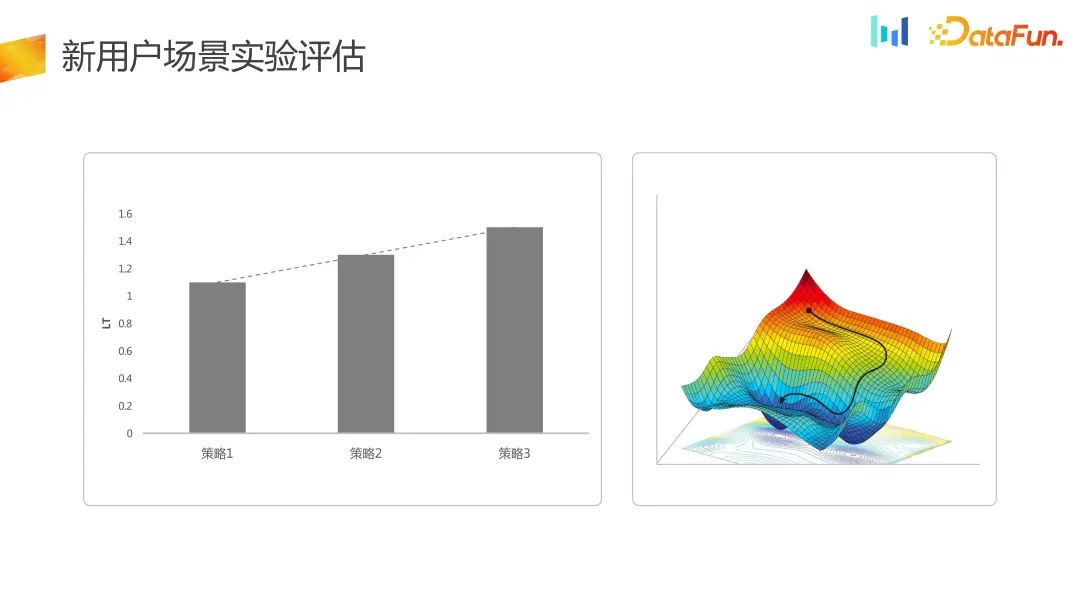
Dans le nouveau système expérimental, l'optimisation unidimensionnelle est transformée en une optimisation bidimensionnelle, et le DNU Shenshang LT global a été amélioré, donc L'espace stratégique est passé de l'ancien unidimensionnel à deux dimensions, et en même temps, dans certains scénarios, la perte d'une partie de LT peut être acceptée.
4. Résumé
Enfin, résumons les normes de renforcement des capacités expérimentales et d'évaluation expérimentale dans de nouveaux scénarios d'utilisation.
- UG Le système expérimental existant dans le scénario des nouveaux utilisateurs ne peut pas résoudre complètement les problèmes rencontrés par l'évaluation des stratégies d'acceptation du trafic des nouveaux utilisateurs, et un nouveau système expérimental est nécessaire.
- Il existe plusieurs critères de sélection de l'ID de détournement. Le premier est la conformité à la sécurité, il peut ensuite être obtenu au premier démarrage, et le troisième est qu'il soit stable au sein d'un seul cycle d'installation et injectif avec le. relation d’identification de l’indicateur.
- L'évaluation expérimentale de nouveaux scénarios d'utilisateurs est une optimisation multidimensionnelle, et les revenus proviennent du nombre effectif de nouveaux appareils et de la rétention des appareils, contrairement à l'évaluation précédente de uniquement la rétention des appareils.
- Accepter de "nouveaux" utilisateurs apporte souvent d'énormes avantages commerciaux. Le « nouveau » ici fait référence non seulement aux nouveaux utilisateurs, mais également aux utilisateurs qui ont désinstallé et réinstallé.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
Écrit ci-dessus et compréhension personnelle de l'auteur : À l'heure actuelle, dans l'ensemble du système de conduite autonome, le module de perception joue un rôle essentiel. Le véhicule autonome roulant sur la route ne peut obtenir des résultats de perception précis que via le module de perception en aval. dans le système de conduite autonome, prend des jugements et des décisions comportementales opportuns et corrects. Actuellement, les voitures dotées de fonctions de conduite autonome sont généralement équipées d'une variété de capteurs d'informations de données, notamment des capteurs de caméra à vision panoramique, des capteurs lidar et des capteurs radar à ondes millimétriques pour collecter des informations selon différentes modalités afin d'accomplir des tâches de perception précises. L'algorithme de perception BEV basé sur la vision pure est privilégié par l'industrie en raison de son faible coût matériel et de sa facilité de déploiement, et ses résultats peuvent être facilement appliqués à diverses tâches en aval.
 Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Les défis courants rencontrés par les algorithmes d'apprentissage automatique en C++ incluent la gestion de la mémoire, le multithread, l'optimisation des performances et la maintenabilité. Les solutions incluent l'utilisation de pointeurs intelligents, de bibliothèques de threads modernes, d'instructions SIMD et de bibliothèques tierces, ainsi que le respect des directives de style de codage et l'utilisation d'outils d'automatisation. Des cas pratiques montrent comment utiliser la bibliothèque Eigen pour implémenter des algorithmes de régression linéaire, gérer efficacement la mémoire et utiliser des opérations matricielles hautes performances.
 Explorez les principes sous-jacents et la sélection d'algorithmes de la fonction de tri C++
Apr 02, 2024 pm 05:36 PM
Explorez les principes sous-jacents et la sélection d'algorithmes de la fonction de tri C++
Apr 02, 2024 pm 05:36 PM
La couche inférieure de la fonction de tri C++ utilise le tri par fusion, sa complexité est O(nlogn) et propose différents choix d'algorithmes de tri, notamment le tri rapide, le tri par tas et le tri stable.
 L'intelligence artificielle peut-elle prédire la criminalité ? Explorez les capacités de CrimeGPT
Mar 22, 2024 pm 10:10 PM
L'intelligence artificielle peut-elle prédire la criminalité ? Explorez les capacités de CrimeGPT
Mar 22, 2024 pm 10:10 PM
La convergence de l’intelligence artificielle (IA) et des forces de l’ordre ouvre de nouvelles possibilités en matière de prévention et de détection de la criminalité. Les capacités prédictives de l’intelligence artificielle sont largement utilisées dans des systèmes tels que CrimeGPT (Crime Prediction Technology) pour prédire les activités criminelles. Cet article explore le potentiel de l’intelligence artificielle dans la prédiction de la criminalité, ses applications actuelles, les défis auxquels elle est confrontée et les éventuelles implications éthiques de cette technologie. Intelligence artificielle et prédiction de la criminalité : les bases CrimeGPT utilise des algorithmes d'apprentissage automatique pour analyser de grands ensembles de données, identifiant des modèles qui peuvent prédire où et quand les crimes sont susceptibles de se produire. Ces ensembles de données comprennent des statistiques historiques sur la criminalité, des informations démographiques, des indicateurs économiques, des tendances météorologiques, etc. En identifiant les tendances qui pourraient échapper aux analystes humains, l'intelligence artificielle peut donner du pouvoir aux forces de l'ordre.
 Algorithme de détection amélioré : pour la détection de cibles dans des images de télédétection optique haute résolution
Jun 06, 2024 pm 12:33 PM
Algorithme de détection amélioré : pour la détection de cibles dans des images de télédétection optique haute résolution
Jun 06, 2024 pm 12:33 PM
01Aperçu des perspectives Actuellement, il est difficile d'atteindre un équilibre approprié entre efficacité de détection et résultats de détection. Nous avons développé un algorithme YOLOv5 amélioré pour la détection de cibles dans des images de télédétection optique haute résolution, en utilisant des pyramides de caractéristiques multicouches, des stratégies de têtes de détection multiples et des modules d'attention hybrides pour améliorer l'effet du réseau de détection de cibles dans les images de télédétection optique. Selon l'ensemble de données SIMD, le mAP du nouvel algorithme est 2,2 % meilleur que YOLOv5 et 8,48 % meilleur que YOLOX, permettant ainsi d'obtenir un meilleur équilibre entre les résultats de détection et la vitesse. 02 Contexte et motivation Avec le développement rapide de la technologie de télédétection, les images de télédétection optique à haute résolution ont été utilisées pour décrire de nombreux objets à la surface de la Terre, notamment des avions, des voitures, des bâtiments, etc. Détection d'objets dans l'interprétation d'images de télédétection
 Pratique et réflexion sur la plateforme multimodale de grands modèles Jiuzhang Yunji DataCanvas
Oct 20, 2023 am 08:45 AM
Pratique et réflexion sur la plateforme multimodale de grands modèles Jiuzhang Yunji DataCanvas
Oct 20, 2023 am 08:45 AM
1. Le développement historique des grands modèles multimodaux. La photo ci-dessus est le premier atelier sur l'intelligence artificielle organisé au Dartmouth College aux États-Unis en 1956. Cette conférence est également considérée comme le coup d'envoi du développement de l'intelligence artificielle. pionniers de la logique symbolique (à l'exception du neurobiologiste Peter Milner au milieu du premier rang). Cependant, cette théorie de la logique symbolique n’a pas pu être réalisée avant longtemps et a même marqué le début du premier hiver de l’IA dans les années 1980 et 1990. Il a fallu attendre la récente mise en œuvre de grands modèles de langage pour découvrir que les réseaux de neurones portent réellement cette pensée logique. Les travaux du neurobiologiste Peter Milner ont inspiré le développement ultérieur des réseaux de neurones artificiels, et c'est pour cette raison qu'il a été invité à y participer. dans ce projet.
 Application d'algorithmes dans la construction de 58 plateformes de portraits
May 09, 2024 am 09:01 AM
Application d'algorithmes dans la construction de 58 plateformes de portraits
May 09, 2024 am 09:01 AM
1. Contexte de la construction de la plateforme 58 Portraits Tout d'abord, je voudrais partager avec vous le contexte de la construction de la plateforme 58 Portraits. 1. La pensée traditionnelle de la plate-forme de profilage traditionnelle ne suffit plus. La création d'une plate-forme de profilage des utilisateurs s'appuie sur des capacités de modélisation d'entrepôt de données pour intégrer les données de plusieurs secteurs d'activité afin de créer des portraits d'utilisateurs précis. Elle nécessite également l'exploration de données pour comprendre le comportement et les intérêts des utilisateurs. et besoins, et fournir des capacités côté algorithmes ; enfin, il doit également disposer de capacités de plate-forme de données pour stocker, interroger et partager efficacement les données de profil utilisateur et fournir des services de profil. La principale différence entre une plate-forme de profilage d'entreprise auto-construite et une plate-forme de profilage de middle-office est que la plate-forme de profilage auto-construite dessert un seul secteur d'activité et peut être personnalisée à la demande. La plate-forme de mid-office dessert plusieurs secteurs d'activité et est complexe ; modélisation et offre des fonctionnalités plus générales. 2.58 Portraits d'utilisateurs de l'arrière-plan de la construction du portrait sur la plate-forme médiane 58
 Ajoutez SOTA en temps réel et montez en flèche ! FastOcc : un algorithme Occ plus rapide et convivial pour le déploiement est là !
Mar 14, 2024 pm 11:50 PM
Ajoutez SOTA en temps réel et montez en flèche ! FastOcc : un algorithme Occ plus rapide et convivial pour le déploiement est là !
Mar 14, 2024 pm 11:50 PM
Écrit ci-dessus & La compréhension personnelle de l'auteur est que dans le système de conduite autonome, la tâche de perception est un élément crucial de l'ensemble du système de conduite autonome. L'objectif principal de la tâche de perception est de permettre aux véhicules autonomes de comprendre et de percevoir les éléments environnementaux environnants, tels que les véhicules circulant sur la route, les piétons au bord de la route, les obstacles rencontrés lors de la conduite, les panneaux de signalisation sur la route, etc., aidant ainsi en aval modules Prendre des décisions et des actions correctes et raisonnables. Un véhicule doté de capacités de conduite autonome est généralement équipé de différents types de capteurs de collecte d'informations, tels que des capteurs de caméra à vision panoramique, des capteurs lidar, des capteurs radar à ondes millimétriques, etc., pour garantir que le véhicule autonome peut percevoir et comprendre avec précision l'environnement environnant. éléments , permettant aux véhicules autonomes de prendre les bonnes décisions pendant la conduite autonome. Tête
