
 Périphériques technologiques
IA
Les acteurs du numérique allument le flambeau des Jeux asiatiques, et cet article de l'ICCV révèle la technologie noire d'IA générative d'Ant.
Périphériques technologiques
IA
Les acteurs du numérique allument le flambeau des Jeux asiatiques, et cet article de l'ICCV révèle la technologie noire d'IA générative d'Ant.
Les acteurs du numérique allument le flambeau des Jeux asiatiques, et cet article de l'ICCV révèle la technologie noire d'IA générative d'Ant.

Ouvrez un humain numérique, plein d'IA générative.
Le soir du 23 septembre, lors de la cérémonie d'ouverture des Jeux asiatiques de Hangzhou, l'allumage de la torche principale a montré les « petites flammes » de centaines de millions de relayeurs numériques en ligne rassemblés sur la rivière Qiantang, formant l'image d’un humain numérique. Ensuite, le porteur de la flamme humaine numérique et le sixième porteur de la flamme sur place ont marché ensemble jusqu'à la scène de la torche et ont allumé ensemble la torche principale

Comme l'idée centrale de la cérémonie d'ouverture, le format d'éclairage de la torche numérique dans le monde réel a est devenu un sujet de recherche brûlant et a attiré l'attention des gens. Contenu réécrit : En tant qu'idée centrale de la cérémonie d'ouverture, la méthode d'allumage des flambeaux de l'Internet de réalité numérique a suscité des discussions animées et attiré l'attention des gens
L'éclairage des personnes numériques est une initiative sans précédent. Des centaines de millions de personnes y ont participé. , impliquant un grand nombre de personnes. Technologie avancée et complexe. L’une des questions les plus importantes est de savoir comment faire « bouger » les personnes numériques. On voit clairement qu'avec le développement rapide de l'intelligence artificielle générative et des modèles à grande échelle, de nouveaux changements sont apparus dans la recherche humaine numérique
Lors de la prochaine conférence mondiale sur la vision par ordinateur ICCV 2023 début octobre, nous avons prêté attention à un des recherches sur la génération de mouvements humains numériques en 3D ont été incluses dans la conférence. L'article connexe s'intitule « Génération hiérarchique d'interactions homme-objet avec des modèles probabilistes de diffusion » et a été publié conjointement par l'Université du Zhejiang et Ant Group.

Selon l'introduction, cette recherche résout dans une certaine mesure le problème des humains numériques synthétisant des mouvements complexes sur de longues distances, et peut obtenir des effets qui ne peuvent être obtenus avec des modèles originaux ou une planification de chemin. La technologie liée à la conduite humaine numérique a également été appliquée à la livraison en ligne de 100 millions d'êtres humains numériques lors des Jeux asiatiques
Pilote d'IA générative pour faire bouger les humains numériques
Souvent, nous devons synthétiser la 3D dans une 3D donnée scène Le mouvement humain permet aux humains virtuels de se déplacer naturellement autour d'une scène et d'interagir avec des objets, un effet qui a de nombreuses applications en AR/VR, en production cinématographique et en jeux vidéo.
Ici, les méthodes traditionnelles de génération de mouvements de contrôle de personnages visent à générer des mouvements à court terme ou répétitifs guidés par les signaux de contrôle de l'utilisateur, tandis que de nouvelles recherches se concentrent sur la génération de mouvements à plus long terme en fonction d'une position de départ et d'un modèle d'objet cible. contenu.
Bien que cette idée soit plus efficace, elle est évidemment plus stimulante. Premièrement, les interactions homme-objet doivent être cohérentes, ce qui nécessite la capacité de modéliser les interactions à longue portée entre les humains et les objets. Deuxièmement, dans le contexte de la génération de contenu, les modèles génératifs devraient être capables de synthétiser des mouvements de différentes tailles, car il existe de multiples façons pour des personnes réelles d'approcher et d'interagir avec des objets cibles.

En termes de méthodes de génération d'actions humaines numériques, les méthodes de synthèse existantes peuvent être grossièrement divisées en génération en ligne et génération hors ligne. La plupart des méthodes en ligne se concentrent sur le contrôle du personnage en temps réel. Étant donné un objet cible, ils utilisent généralement des modèles autorégressifs pour générer de manière cyclique un mouvement futur grâce à des prédictions de rétroaction. Bien que cette méthode ait été largement utilisée dans des scénarios interactifs tels que les jeux vidéo, sa qualité reste encore insatisfaisante pour une génération à long terme.

Afin d'améliorer la qualité du mouvement, certaines méthodes hors ligne récentes ont commencé à adopter des cadres multi-niveaux, générant d'abord des trajectoires puis synthétisant le mouvement. Bien que cette stratégie puisse produire des chemins raisonnables, la diversité des chemins est limitée
Dans cette nouvelle étude, les auteurs proposent une nouvelle méthode hors ligne pour synthétiser les relations diverses et à long terme entre les personnes et les objets. L'innovation de cette méthode réside dans la stratégie de génération hiérarchique. Tout d'abord, la stratégie prédit une série d'étapes puis génère des actions humaines entre ces étapes
Plus précisément, étant donné une position de départ et un objet cible, les auteurs ont conçu un module de génération de jalons pour synthétiser un ensemble de nœuds le long de la trajectoire du mouvement, chaque jalon codant la pose locale et indiquant le point de transition pendant le mouvement humain. Sur la base de ces jalons, l'algorithme utilise un module de génération de mouvement pour générer des séquences de mouvement complètes. Grâce à l'existence de ces jalons, nous pouvons simplifier la génération de séquences longues à la synthèse de plusieurs séquences de mouvements courtes.
La pose locale de chaque jalon est générée par un modèle de transformateur qui prend en compte les dépendances globales pour produire des résultats cohérents dans le temps, facilitant ainsi un mouvement cohérent.
En plus du cadre de génération hiérarchique, les chercheurs ont également utilisé des modèles de diffusion pour créer des objets humains synthétiques. interactions. Certains modèles de diffusion synthétique de mouvement précédents combinaient des transformateurs et des modèles probabilistes de diffusion de débruitage (DDPM).
Il convient de mentionner qu'en raison des longues séquences de mouvements, les appliquer directement à une nouvelle configuration nécessite de nombreux calculs et peut provoquer une explosion de la mémoire GPU. Étant donné que le nouveau cadre de génération hiérarchique convertit la génération à long terme en synthèse de plusieurs séquences courtes, la mémoire GPU requise est réduite au même niveau que la génération de mouvements à court terme.
Par conséquent, les chercheurs peuvent utiliser efficacement Transformer DDPM pour synthétiser des séquences de mouvement à long terme, améliorant ainsi la qualité de la génération
Pour atteindre cet objectif, les chercheurs ont conçu un cadre de génération hiérarchique, comme le montre la figure ci-dessous
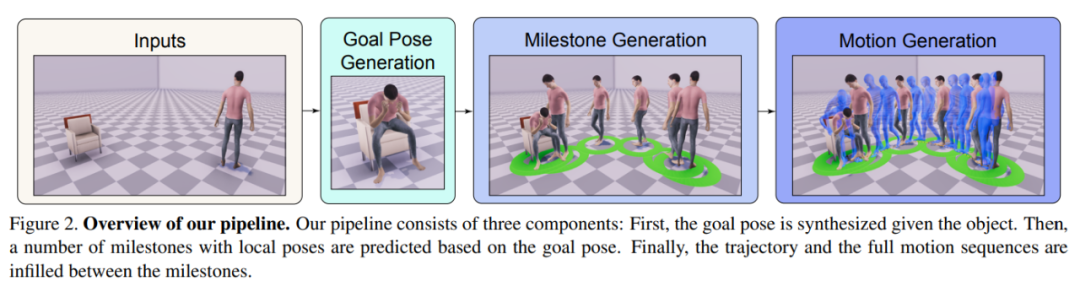
Premièrement, Ils utilisent GoalNet pour prédire les objectifs d'interaction sur les objets, puis génèrent des poses cibles pour modéliser explicitement les interactions homme-objet. Ensuite, ils utilisent le module de génération de jalon pour estimer la longueur du jalon, générant ainsi la trajectoire du jalon depuis le point de départ jusqu'à la cible, et plaçant la pose du jalon
De cette façon, la génération de mouvement longue distance est décomposée en un combinaison de plusieurs générations de mouvements à courte distance. Enfin, les auteurs ont conçu un module de génération de mouvements pour synthétiser les trajectoires entre les jalons et remplir les actions.
Génération de poses d'intelligence artificielle (IA)
Les chercheurs appellent la posture cible la posture dans laquelle une personne interagit avec un objet et reste immobile. Auparavant, la plupart des méthodes utilisaient des modèles cVAE pour générer des poses humaines, mais les chercheurs ont constaté que cette méthode fonctionnait mal dans leurs propres études.
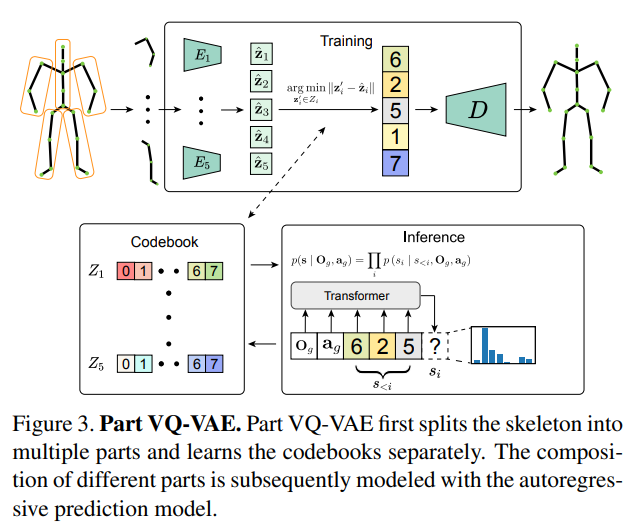
Pour relever ce défi, ils ont adopté le modèle VQ-VAE pour modéliser la distribution des données. Ce modèle utilise une représentation discrète pour regrouper les données en un ensemble limité de points. De plus, d’après les observations, différentes poses humaines peuvent avoir des propriétés similaires. Par exemple, lorsqu’une personne est assise, les mouvements des mains peuvent être différents, mais la position des jambes peut être la même. Par conséquent, ils ont divisé les articulations en L (L = 5) groupes différents qui ne se chevauchent pas
Comme le montre la figure 3, la pose cible est divisée en groupes d'articulations indépendants
Selon la pose de départ et la pose cible, Nous pouvons demander à l'algorithme de générer des trajectoires de jalons et de synthétiser des poses locales aux jalons. Puisque la longueur des données de mouvement est inconnue et peut être arbitraire (par exemple, une personne peut marcher rapidement jusqu'à la chaise et s'asseoir, ou elle peut marcher lentement autour de la chaise puis s'asseoir), il est nécessaire de prédire la longueur du jalon, représenté par N . Ensuite, N points de repère sont synthétisés et des poses locales sont placées sur ces points.
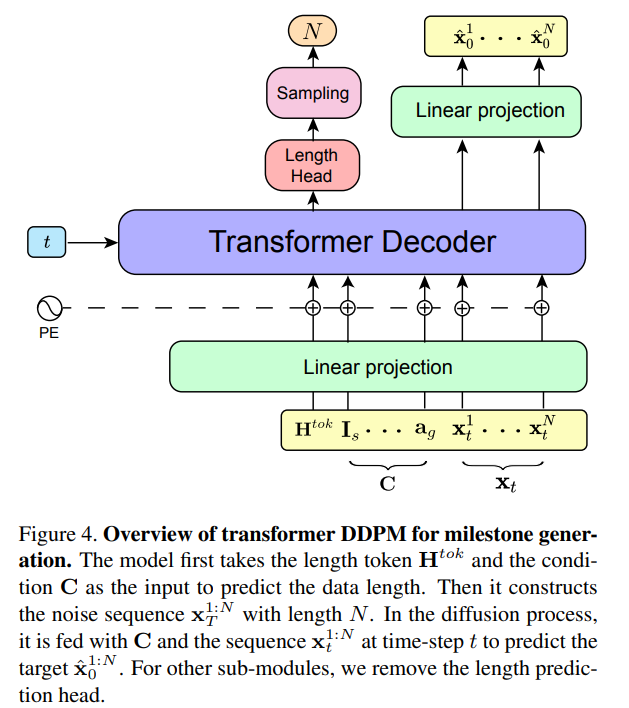
La dernière étape est la génération d'actions. La méthode utilisée par les chercheurs n'est pas de prédire les actions image par image, mais de synthétiser l'ensemble de la séquence hiérarchiquement en fonction des jalons générés. Ils génèrent d’abord des trajectoires puis synthétisent des actions. Plus précisément, en deux étapes consécutives, ils terminent le parcours en premier. Complétez ensuite le mouvement en vous guidant par des gestes jalons successifs. Ces deux étapes sont réalisées respectivement à l'aide de deux Transformer DDPM.
Les chercheurs concevront soigneusement les conditions du DDPM pour chaque étape afin de générer le résultat cible
Le contenu réécrit est : l'effet en avance sur les autres produits
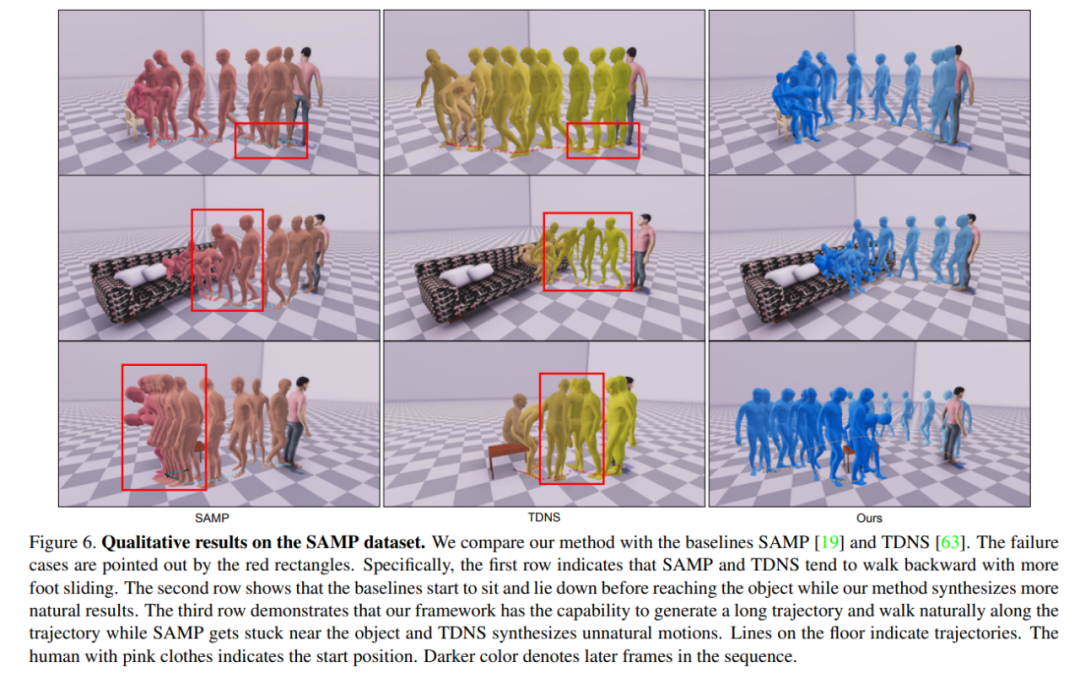
Les chercheurs ont comparé les résultats de différentes méthodes sur l'ensemble de données SAMP. On peut voir que la méthode proposée dans l’article a un FD plus faible, un score de recherche utilisateur plus élevé et un APD plus élevé. De plus, leur méthode permet d’obtenir une diversité de trajectoires plus élevée que SAMP.
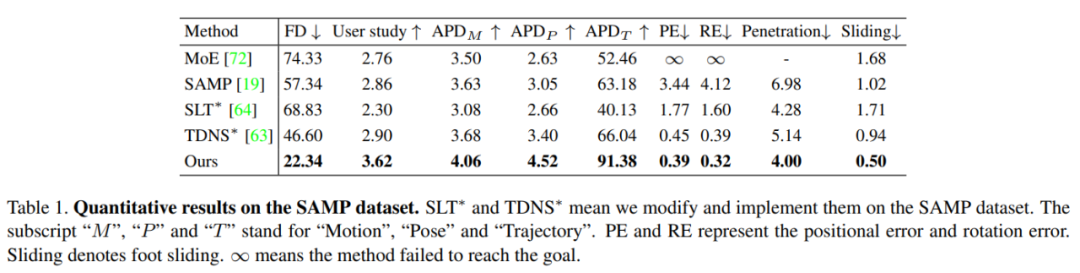
Cette nouvelle méthode peut produire des résultats satisfaisants dans des scènes complexes. Le pourcentage de frames de pénétration générés par cette méthode est de 3,8%, et celui de SAMP est de 4,9%

Sur SAMP, COUCH et d'autres ensembles de données, les méthodes mentionnées dans l'étude ont obtenu de meilleurs résultats que la méthode de base

Complétez la mise en page du lien complet
L'humain numérique est un complexe qui intègre des technologies multimodales telles que la voix, la sémantique et la vision. Alors que l'IA générative a récemment fait des percées, le domaine des humains numériques connaît un développement rapide. La modélisation, l'interaction générative, le rendu et d'autres liens qui nécessitaient auparavant un travail manuel sont désormais entièrement artificialisés. Alors que les ingénieurs continuent d'optimiser, cette expérience de. La technologie mobile s'améliore également. Le relais de la flamme des Jeux asiatiques en ligne qui vient de se terminer en est un bon exemple : si nous voulons devenir porteur de la flamme, il suffit de cliquer sur le mini-programme de l'application Alipay.
On dit que afin d'assurer le bon déroulement du projet de cérémonie d'ouverture, les ingénieurs d'Ant Group ont effectué plus de 100 000 tests sur des centaines de modèles différents de téléphones mobiles, écrit plus de 200 000 lignes de code et utilisé le logiciel développé par eux-mêmes. Moteur interactif Web3D Galacean, IA numérique, services cloud, blockchain et autres technologies combinés pour garantir que chacun puisse devenir porteur du flambeau numérique et participer au relais de la flamme. La plate-forme porte-flambeau numérique des Jeux asiatiques peut atteindre des centaines de millions d'utilisateurs et prend en charge 97 % des smartphones courants.
Afin de permettre aux porteurs du flambeau numérique de participer de manière réaliste, l’équipe technique d’Ant a développé 58 contrôleurs qui pincent le visage. En utilisant la reconnaissance faciale et des algorithmes d'IA, ils peuvent cartographier le visage d'un porteur du flambeau numérique en fonction des traits du visage de chaque personne. Dans le même temps, les utilisateurs peuvent également ajuster librement la forme du visage, la coiffure, le nez, la bouche, les sourcils et d'autres caractéristiques pour obtenir un habillage libre. Cette technologie peut fournir 2 000 milliards de choix d'images numériques différents
De plus, après la cérémonie d'éclairage de la cérémonie d'ouverture, chaque relayeur numérique peut recevoir un certificat d'allumage numérique exclusif, qui est peint avec l'image unique de chaque relayeur numérique, ce certificat sera stocké sur la blockchain grâce à la technologie distribuée.
 Il n'est pas difficile de voir à partir du contenu du document de recherche et du projet des Jeux asiatiques qu'il existe un système technologique humain numérique complet derrière lui. Il est entendu qu'Ant Group explore activement la technologie humaine numérique et a achevé la conception d'auto-recherche de la technologie de base à liaison complète de l'humain numérique.
Il n'est pas difficile de voir à partir du contenu du document de recherche et du projet des Jeux asiatiques qu'il existe un système technologique humain numérique complet derrière lui. Il est entendu qu'Ant Group explore activement la technologie humaine numérique et a achevé la conception d'auto-recherche de la technologie de base à liaison complète de l'humain numérique.
Contrairement à la plupart des entreprises du marché, Ant Group développe sa technologie humaine numérique en interne et choisit une direction de développement combinée à l'IA générative. En termes de déploiement technologique, il couvre l'ensemble du cycle de vie de la modélisation humaine numérique, du rendu, de la conduite et de l'interaction. La combinaison de l'AIGC et de grands modèles réduit considérablement le coût de production complet des humains numériques. Actuellement, il peut prendre en charge les personnes numériques 2D et 3D et fournit une variété de solutions telles que le type de diffusion et le type interactif.
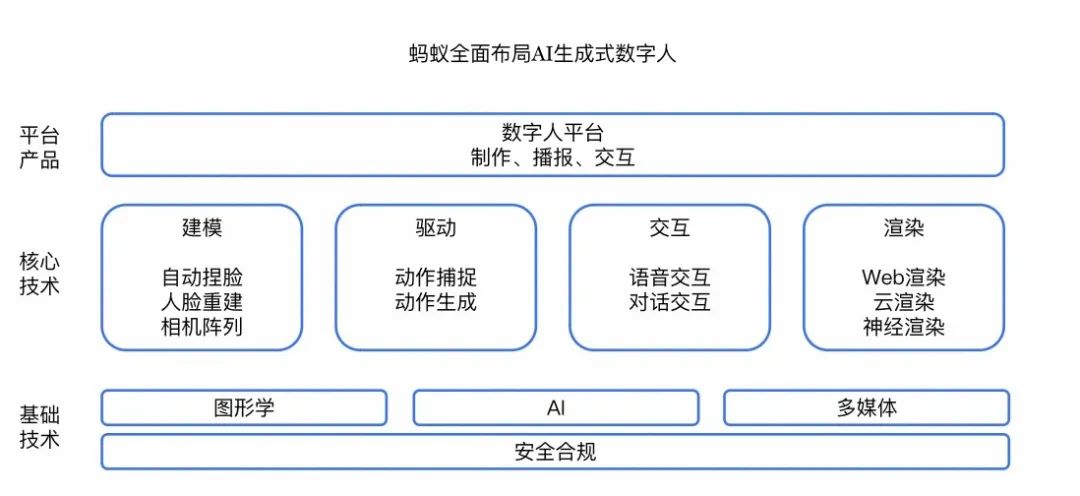 Selon les informations publiques, on peut résumer que la plateforme humaine numérique Ant présente actuellement quatre avantages et fonctionnalités techniques :
Selon les informations publiques, on peut résumer que la plateforme humaine numérique Ant présente actuellement quatre avantages et fonctionnalités techniques : - Modélisation à faible coût : coopérer avec l'Université Tsinghua pour lancer un modèle paramétrique 3D de visages asiatiques , reconstitution 3D à partir de photos Le visage humain correspond davantage aux caractéristiques des visages asiatiques.
- Pilote génératif : la combinaison de la génération de pilotes et de la capture de mouvement réduit efficacement les coûts et améliore la richesse du mouvement par rapport aux processus de production de mouvement traditionnels.
- Rendu hautement adaptable : moteur de rendu Web3D auto-développé Galacean, couvrant 97 % des terminaux de téléphonie mobile courants ; en termes de rendu neuronal, un framework NeRF qui découple les pilotes dynamiques et la modélisation statique a été construit et est appliqué au numérique ; scènes vidéo dynamiques humaines.
- Interaction intelligente : basé sur le clonage de timbres pré-entraînés, il prend en charge l'entrée audio au niveau infime pour générer un timbre humain numérique personnalisé et organise l'interaction humaine numérique basée sur de grands modèles.
- Avant la cérémonie d'ouverture des Jeux asiatiques, l'Académie chinoise des technologies de l'information et des communications a publié les derniers résultats de vérification de la conformité aux normes humaines numériques. La plate-forme humaine numérique Lingjing d'Ant Group est devenue le premier produit du secteur à passer le test humain numérique financier. évaluation et a reçu la note la plus élevée de « Niveau exceptionnel (L4) ».
En plus des Jeux asiatiques, la plate-forme Ant Digital People prend également en charge Alipay d'Ant Group, la finance numérique, les affaires gouvernementales, Wufu et d'autres entreprises, et cette année a commencé à être utilisée dans de courtes vidéos, des émissions en direct, des mini-programmes et d'autres supports. fournir des services de base aux partenaires.
On peut prédire que dans un avenir proche, à mesure que les humains numériques alimentés par l'IA générative continuent de se mettre à niveau, nous connaîtrons également de meilleures interactions dans davantage de scénarios et entrerons véritablement dans une vie intelligente intégrant les choses numériques et réelles.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le robot DeepMind joue au tennis de table, et son coup droit et son revers glissent dans les airs, battant complètement les débutants humains
Aug 09, 2024 pm 04:01 PM
Le robot DeepMind joue au tennis de table, et son coup droit et son revers glissent dans les airs, battant complètement les débutants humains
Aug 09, 2024 pm 04:01 PM
Mais peut-être qu’il ne pourra pas vaincre le vieil homme dans le parc ? Les Jeux Olympiques de Paris battent leur plein et le tennis de table suscite beaucoup d'intérêt. Dans le même temps, les robots ont également réalisé de nouvelles avancées dans le domaine du tennis de table. DeepMind vient tout juste de proposer le premier agent robot apprenant capable d'atteindre le niveau des joueurs amateurs humains de tennis de table de compétition. Adresse papier : https://arxiv.org/pdf/2408.03906 Quelle est la capacité du robot DeepMind à jouer au tennis de table ? Probablement à égalité avec les joueurs amateurs humains : tant en coup droit qu'en revers : l'adversaire utilise une variété de styles de jeu, et le robot peut également résister : recevoir des services avec des tours différents : Cependant, l'intensité du jeu ne semble pas aussi intense que le vieil homme dans le parc. Pour les robots, le tennis de table
 La première griffe mécanique ! Yuanluobao est apparu à la World Robot Conference 2024 et a lancé le premier robot d'échecs pouvant entrer dans la maison
Aug 21, 2024 pm 07:33 PM
La première griffe mécanique ! Yuanluobao est apparu à la World Robot Conference 2024 et a lancé le premier robot d'échecs pouvant entrer dans la maison
Aug 21, 2024 pm 07:33 PM
Le 21 août, la Conférence mondiale sur les robots 2024 s'est tenue en grande pompe à Pékin. La marque de robots domestiques de SenseTime, "Yuanluobot SenseRobot", a dévoilé toute sa famille de produits et a récemment lancé le robot de jeu d'échecs Yuanluobot AI - Chess Professional Edition (ci-après dénommé "Yuanluobot SenseRobot"), devenant ainsi le premier robot d'échecs au monde pour le maison. En tant que troisième produit robot jouant aux échecs de Yuanluobo, le nouveau robot Guoxiang a subi un grand nombre de mises à niveau techniques spéciales et d'innovations en matière d'IA et de machines d'ingénierie. Pour la première fois, il a réalisé la capacité de ramasser des pièces d'échecs en trois dimensions. grâce à des griffes mécaniques sur un robot domestique et effectuer des fonctions homme-machine telles que jouer aux échecs, tout le monde joue aux échecs, réviser la notation, etc.
 Claude aussi est devenu paresseux ! Internaute : apprenez à vous accorder des vacances
Sep 02, 2024 pm 01:56 PM
Claude aussi est devenu paresseux ! Internaute : apprenez à vous accorder des vacances
Sep 02, 2024 pm 01:56 PM
La rentrée scolaire est sur le point de commencer, et ce ne sont pas seulement les étudiants qui sont sur le point de commencer le nouveau semestre qui doivent prendre soin d’eux-mêmes, mais aussi les grands modèles d’IA. Il y a quelque temps, Reddit était rempli d'internautes se plaignant de la paresse de Claude. « Son niveau a beaucoup baissé, il fait souvent des pauses et même la sortie devient très courte. Au cours de la première semaine de sortie, il pouvait traduire un document complet de 4 pages à la fois, mais maintenant il ne peut même plus produire une demi-page. !" https://www.reddit.com/r/ClaudeAI/comments/1by8rw8/something_just_feels_wrong_with_claude_in_the/ dans un post intitulé "Totalement déçu par Claude", plein de
 Lors de la World Robot Conference, ce robot domestique porteur de « l'espoir des futurs soins aux personnes âgées » a été entouré
Aug 22, 2024 pm 10:35 PM
Lors de la World Robot Conference, ce robot domestique porteur de « l'espoir des futurs soins aux personnes âgées » a été entouré
Aug 22, 2024 pm 10:35 PM
Lors de la World Robot Conference qui se tient à Pékin, l'exposition de robots humanoïdes est devenue le centre absolu de la scène. Sur le stand Stardust Intelligent, l'assistant robot IA S1 a réalisé trois performances majeures de dulcimer, d'arts martiaux et de calligraphie. un espace d'exposition, capable à la fois d'arts littéraires et martiaux, a attiré un grand nombre de publics professionnels et de médias. Le jeu élégant sur les cordes élastiques permet au S1 de démontrer un fonctionnement fin et un contrôle absolu avec vitesse, force et précision. CCTV News a réalisé un reportage spécial sur l'apprentissage par imitation et le contrôle intelligent derrière "Calligraphy". Le fondateur de la société, Lai Jie, a expliqué que derrière les mouvements soyeux, le côté matériel recherche le meilleur contrôle de la force et les indicateurs corporels les plus humains (vitesse, charge). etc.), mais du côté de l'IA, les données réelles de mouvement des personnes sont collectées, permettant au robot de devenir plus fort lorsqu'il rencontre une situation forte et d'apprendre à évoluer rapidement. Et agile
 Annonce des prix ACL 2024 : l'un des meilleurs articles sur le déchiffrement Oracle par HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
Annonce des prix ACL 2024 : l'un des meilleurs articles sur le déchiffrement Oracle par HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
Les contributeurs ont beaucoup gagné de cette conférence ACL. L'ACL2024, d'une durée de six jours, se tient à Bangkok, en Thaïlande. ACL est la plus grande conférence internationale dans le domaine de la linguistique informatique et du traitement du langage naturel. Elle est organisée par l'Association internationale pour la linguistique informatique et a lieu chaque année. L'ACL s'est toujours classée première en termes d'influence académique dans le domaine de la PNL, et c'est également une conférence recommandée par le CCF-A. La conférence ACL de cette année est la 62e et a reçu plus de 400 travaux de pointe dans le domaine de la PNL. Hier après-midi, la conférence a annoncé le meilleur article et d'autres récompenses. Cette fois, il y a 7 Best Paper Awards (deux inédits), 1 Best Theme Paper Award et 35 Outstanding Paper Awards. La conférence a également décerné 3 Resource Paper Awards (ResourceAward) et Social Impact Award (
 Hongmeng Smart Travel S9 et conférence de lancement de nouveaux produits avec scénario complet, un certain nombre de nouveaux produits à succès ont été lancés ensemble
Aug 08, 2024 am 07:02 AM
Hongmeng Smart Travel S9 et conférence de lancement de nouveaux produits avec scénario complet, un certain nombre de nouveaux produits à succès ont été lancés ensemble
Aug 08, 2024 am 07:02 AM
Cet après-midi, Hongmeng Zhixing a officiellement accueilli de nouvelles marques et de nouvelles voitures. Le 6 août, Huawei a organisé la conférence de lancement de nouveaux produits Hongmeng Smart Xingxing S9 et Huawei, réunissant la berline phare intelligente panoramique Xiangjie S9, le nouveau M7Pro et Huawei novaFlip, MatePad Pro 12,2 pouces, le nouveau MatePad Air, Huawei Bisheng With de nombreux nouveaux produits intelligents tous scénarios, notamment la série d'imprimantes laser X1, FreeBuds6i, WATCHFIT3 et l'écran intelligent S5Pro, des voyages intelligents, du bureau intelligent aux vêtements intelligents, Huawei continue de construire un écosystème intelligent complet pour offrir aux consommateurs une expérience intelligente du Internet de tout. Hongmeng Zhixing : Autonomisation approfondie pour promouvoir la modernisation de l'industrie automobile intelligente Huawei s'associe à ses partenaires de l'industrie automobile chinoise pour fournir
 L'équipe de Li Feifei a proposé ReKep pour donner aux robots une intelligence spatiale et intégrer GPT-4o
Sep 03, 2024 pm 05:18 PM
L'équipe de Li Feifei a proposé ReKep pour donner aux robots une intelligence spatiale et intégrer GPT-4o
Sep 03, 2024 pm 05:18 PM
Intégration profonde de la vision et de l'apprentissage des robots. Lorsque deux mains de robot travaillent ensemble en douceur pour plier des vêtements, verser du thé et emballer des chaussures, associées au robot humanoïde 1X NEO qui a fait la une des journaux récemment, vous pouvez avoir le sentiment : nous semblons entrer dans l'ère des robots. En fait, ces mouvements soyeux sont le produit d’une technologie robotique avancée + d’une conception de cadre exquise + de grands modèles multimodaux. Nous savons que les robots utiles nécessitent souvent des interactions complexes et exquises avec l’environnement, et que l’environnement peut être représenté comme des contraintes dans les domaines spatial et temporel. Par exemple, si vous souhaitez qu'un robot verse du thé, le robot doit d'abord saisir la poignée de la théière et la maintenir verticalement sans renverser le thé, puis la déplacer doucement jusqu'à ce que l'embouchure de la théière soit alignée avec l'embouchure de la tasse. , puis inclinez la théière selon un certain angle. ce
 Testé 7 artefacts de génération vidéo « de niveau Sora ». Qui a la capacité de monter sur le « Trône de fer » ?
Aug 05, 2024 pm 07:19 PM
Testé 7 artefacts de génération vidéo « de niveau Sora ». Qui a la capacité de monter sur le « Trône de fer » ?
Aug 05, 2024 pm 07:19 PM
Editeur du Machine Power Report : Yang Wen Qui peut devenir le roi du cercle vidéo de l'IA ? Dans la série télévisée américaine "Game of Thrones", il y a un "Trône de Fer". La légende raconte qu'il a été fabriqué par le dragon géant « Black Death » qui a fait fondre des milliers d'épées abandonnées par les ennemis, symbolisant l'autorité suprême. Pour s'asseoir sur cette chaise de fer, les grandes familles ont commencé à se battre et à se battre. Depuis l'émergence de Sora, un vigoureux "Game of Thrones" a été lancé dans le cercle vidéo de l'IA. Les principaux acteurs de ce jeu incluent RunwayGen-3 et Luma de l'autre côté de l'océan, ainsi que Kuaishou Keling, ByteDream, national. et Zhimo. Spectre Qingying, Vidu, PixVerseV2, etc. Aujourd'hui, nous allons évaluer et voir qui est qualifié pour siéger sur le « Trône de fer » du cercle vidéo IA. -1-Vincent Vidéo
