

Utiliser un seul réseau neuronal pour réaliser la manipulation est une avancée technologique majeure dans le domaine des robots quadrupèdes.
Le Parkour est un sport extrême qui oblige les participants à franchir des obstacles de manière très dynamique" Pour la plupart du temps. robots « maladroits », cela semble être une chose inaccessible, mais récemment, des tendances technologiques révolutionnaires ont été observées dans le domaine du contrôle des robots. Il y a quelques semaines, ce site faisait état d'une étude utilisant des méthodes d'apprentissage par renforcement pour permettre à des chiens robots de réaliser du parkour, et obtenant de bons résultats. Récemment, l'Université Carnegie Mellon (CMU) a mené une nouvelle étude, proposant une nouvelle méthode étonnante pour relever le défi du parkour avec des chiens robots, et l'effet a été encore amélioré, à tel point que les gens ont unanimement commenté comme "incroyable".
Le public a déclaré : "C'est comme être dans "Black Mirror""Des recherches à l'Université Carnegie Mellon permettent à un chien robot d'agir comme un concurrent dans une course d'obstacles, de franchir automatiquement des cases discontinues. et courez et sautez facilement entre des pentes inclinées sous différents angles
 , et la vitesse de franchissement de ces obstacles est également très rapide.
, et la vitesse de franchissement de ces obstacles est également très rapide. Sauter facilement par-dessus un écart de 0,8 mètre (2 fois la longueur du chien robot) :
 Grimper des obstacles de plus de 0,51 mètre de haut (2 fois la hauteur du chien robot) :
Grimper des obstacles de plus de 0,51 mètre de haut (2 fois la hauteur du chien robot) :  Personne Cette fois-ci, debout fermement, il utilisa également ses pattes postérieures pour compenser, agissant comme un vrai chien.
Personne Cette fois-ci, debout fermement, il utilisa également ses pattes postérieures pour compenser, agissant comme un vrai chien. Le chien robot peut également faire certaines choses difficiles pour les animaux du monde réel, comme marcher avec seulement deux pattes avant, ce qui équivaut à marcher la tête en bas.
 Il peut également descendre les escaliers avec seulement deux pattes avant :
Il peut également descendre les escaliers avec seulement deux pattes avant : C'est comme rencontrer un bug dans le jeu, un peu drôle, et en même temps avec un soupçon d'effet étrange vallée
C'est comme rencontrer un bug dans le jeu, un peu drôle, et en même temps avec un soupçon d'effet étrange valléeLe but de cette recherche est de permettre un petit, à faible coût chien robot pour accomplir avec succès les tâches de parkour. Le système de conduite de ce chien robot n'est pas assez précis et ne dispose que d'une caméra de profondeur frontale pour la perception, qui est basse fréquence et sujette au tremblement et aux artefacts.
L'étude propose un réseau neuronal basé sur la profondeur brute et les entrées des capteurs intégrés. Réseau pour générer directement des commandes d’angles articulaires. En effectuant une formation par simulation d'apprentissage par renforcement à grande échelle, cette méthode est capable de résoudre les défis causés par les imprécisions des capteurs et les problèmes d'actionneurs, obtenant ainsi un comportement de contrôle de haute précision de bout en bout. Ce projet de recherche a été publié sur la plateforme open source

Cette recherche utilise un système de données de bout en bout. cadre d'apprentissage par renforcement piloté pour doter le chien robot de la capacité de « parkour ». Afin de permettre au chien robot de s'auto-ajuster en fonction du type d'obstacle lors du déploiement, cette recherche propose une nouvelle méthode de double distillation. Cette stratégie peut non seulement produire des commandes de mouvement flexibles, mais également ajuster rapidement la direction en fonction de l'image de profondeur d'entrée.
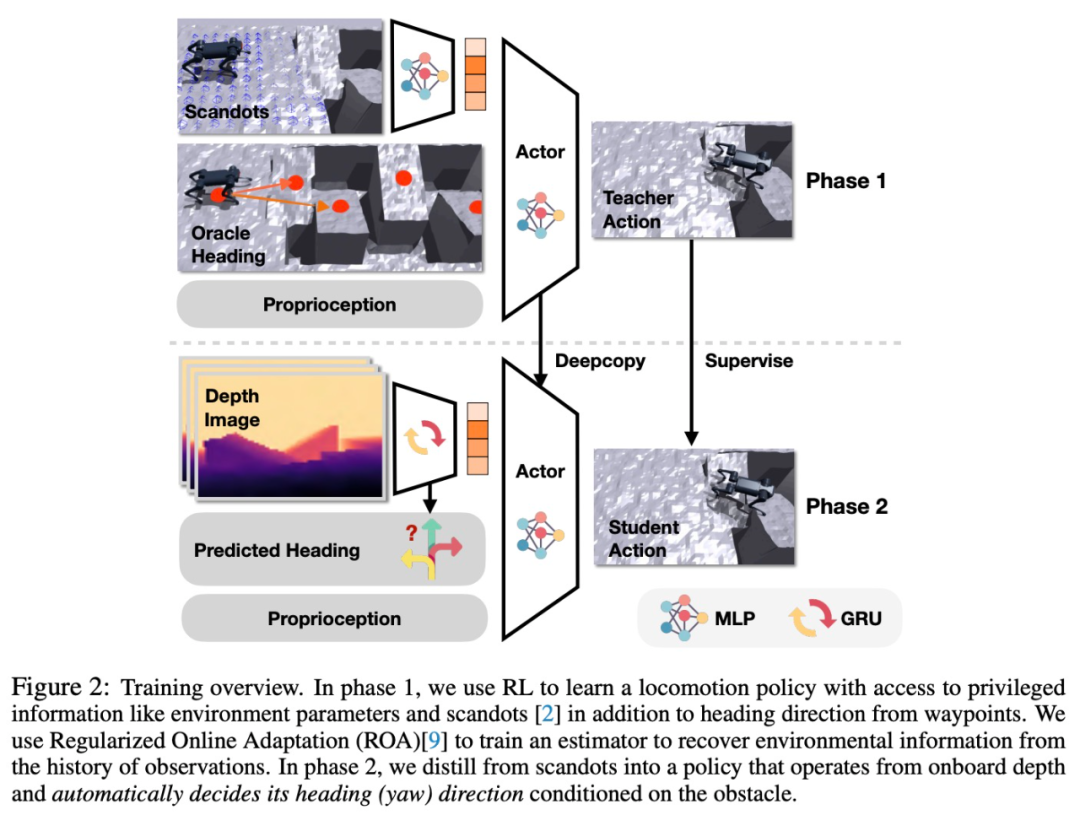 Pour permettre à un réseau neuronal unique de caractériser différents comportements liés aux compétences de parkour, cette étude propose un principe général de conception de récompense simple et efficace basé sur les produits internes.
Pour permettre à un réseau neuronal unique de caractériser différents comportements liés aux compétences de parkour, cette étude propose un principe général de conception de récompense simple et efficace basé sur les produits internes. Plus précisément, la recherche vise à former un réseau neuronal directement depuis la profondeur brute et la détection embarquée jusqu'aux commandes d'angle conjointes. Pour entraîner des stratégies de mouvement adaptatives, cette étude a adopté la méthode d'adaptation en ligne régularisée (ROA) avec des modifications clés pour les tâches de parkour extrêmes.
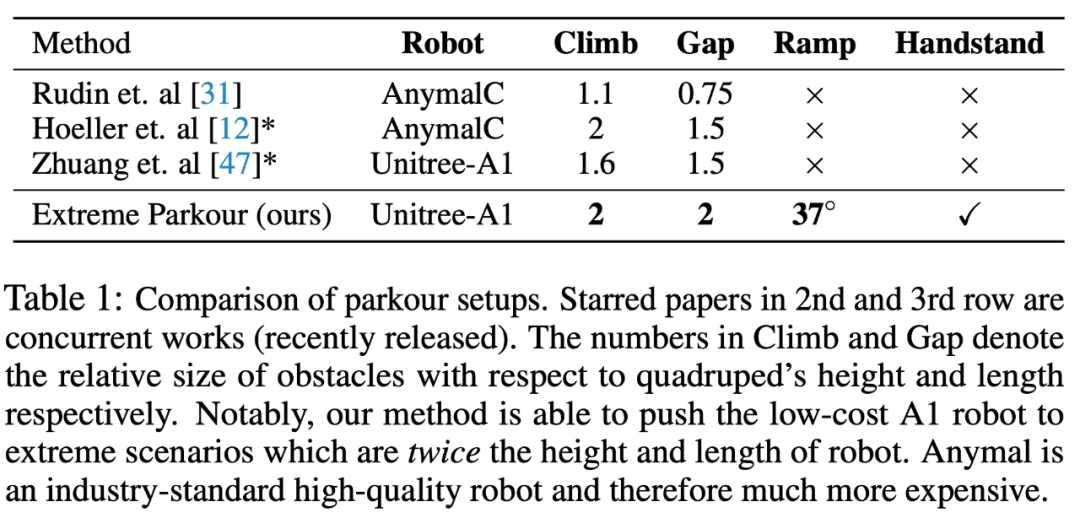
Résultats expérimentauxLe but de cette recherche est de permettre au chien robot de maîtriser 4 compétences, notamment grimper, sauter par-dessus les interstices, courir et sauter sur les pentes et se tenir la tête en bas. Le tableau 1 ci-dessous présente les résultats de la comparaison avec plusieurs autres méthodes
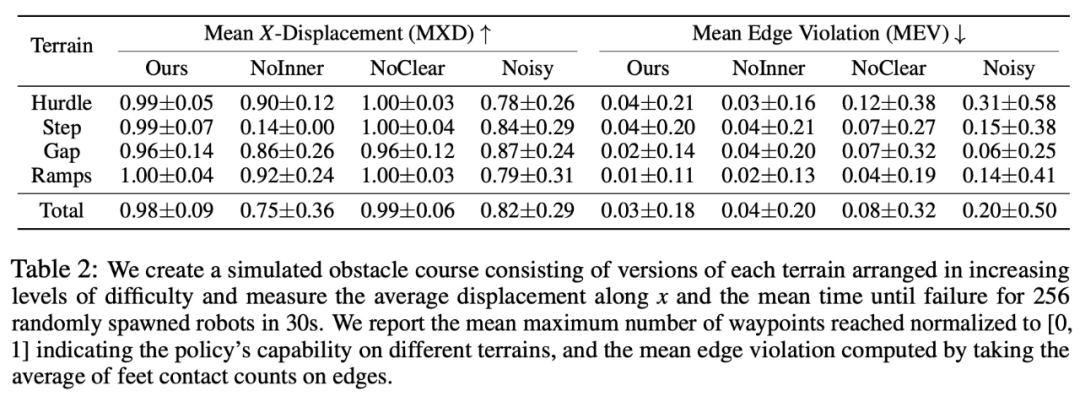
Afin de vérifier le rôle de chaque élément du système, l'étude a proposé deux ensembles de lignes de base. L'étude a d'abord testé la conception de la récompense et le processus global, et les résultats sont présentés dans le tableau 2 ci-dessous :
Le but de la deuxième série de lignes de base est de tester la configuration de distillation, qui comprend BC pour la prédiction de direction et un poignard pour actes. Les résultats expérimentaux sont présentés dans le tableau 3

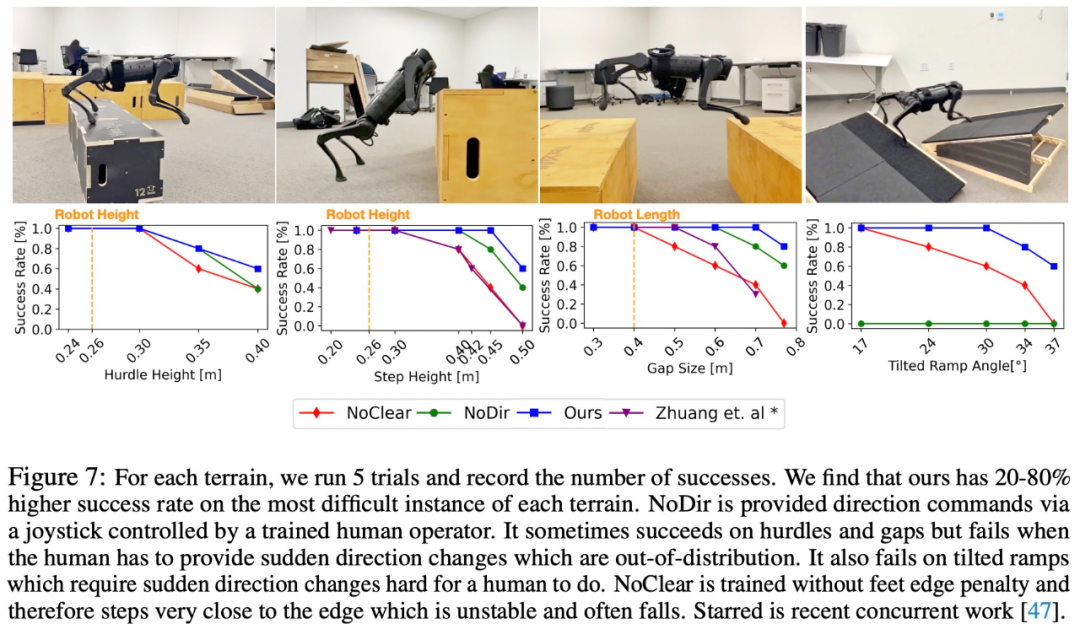
De plus, l'étude a également mené un certain nombre d'expériences réelles, enregistré le taux de réussite et l'a comparé aux lignes de base NoClear et NoDir. Les résultats expérimentaux sont présentés dans la figure 7
Les lecteurs intéressés peuvent lire le texte original de l'article pour en savoir plus sur le contenu de la recherche.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Le trading de Bitcoin est-il autorisé en Chine ?
Le trading de Bitcoin est-il autorisé en Chine ?
 Comment s'inscrire à Alipay d'entreprise
Comment s'inscrire à Alipay d'entreprise
 Dernières tendances des prix du Bitcoin
Dernières tendances des prix du Bitcoin
 Comment supprimer des pages vierges dans Word
Comment supprimer des pages vierges dans Word
 Google Earth ne parvient pas à se connecter à la solution serveur
Google Earth ne parvient pas à se connecter à la solution serveur
 Port 1433
Port 1433
 Comment accéder au site Web 404
Comment accéder au site Web 404
 Solution pour redémarrer et sélectionner le périphérique de démarrage approprié
Solution pour redémarrer et sélectionner le périphérique de démarrage approprié








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



