
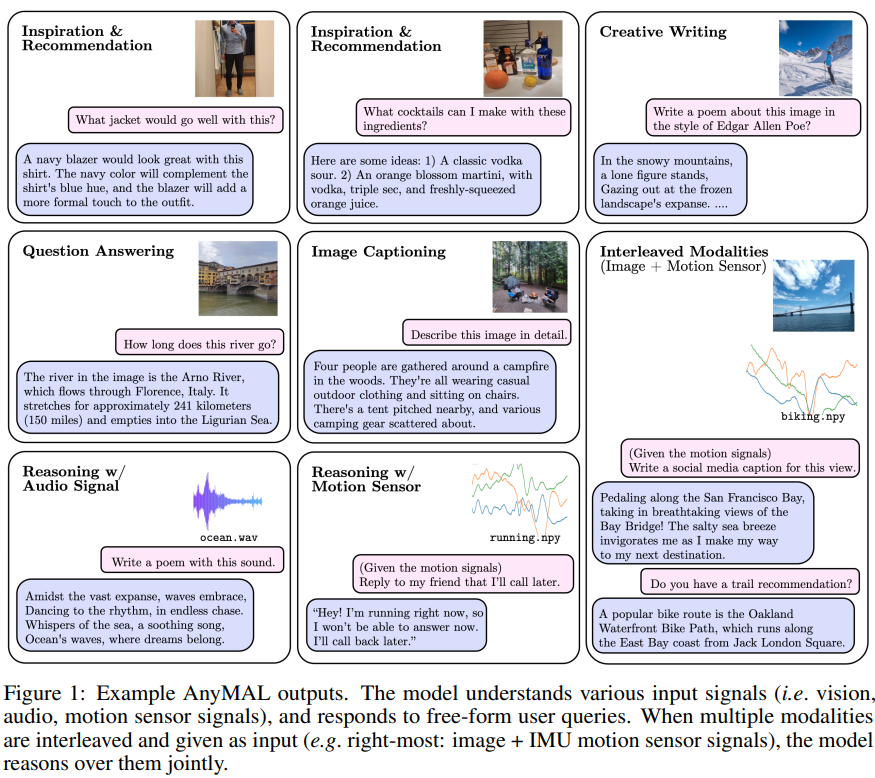
 Périphériques technologiques
IA
La version multimodale Llama2 est en ligne, Meta lance AnyMAL
Périphériques technologiques
IA
La version multimodale Llama2 est en ligne, Meta lance AnyMAL
La version multimodale Llama2 est en ligne, Meta lance AnyMAL

Actualisation des meilleures performances zéro tir de l'industrie dans plusieurs tests de référence.
Un modèle unifié qui peut comprendre différents contenus d'entrée modale (texte, image, vidéo, audio, données du capteur de mouvement IMU) et générer des réponses textuelles. La technologie est basée sur Llama 2 et vient de Meta.
Hier, la recherche sur le grand modèle multimodal AnyMAL a attiré l'attention de la communauté des chercheurs en IA.
Les grands modèles linguistiques (LLM) sont connus pour leur taille et leur complexité énormes, qui améliorent considérablement la capacité des machines à comprendre et à exprimer le langage humain. Les progrès des LLM ont permis des avancées significatives dans le domaine du langage visuel, comblant le fossé entre les encodeurs d'images et les LLM, en combinant leurs capacités d'inférence. Les précédentes recherches LLM multimodales se sont concentrées sur des modèles combinant du texte avec une autre modalité, tels que des modèles de texte et d'image, ou sur des modèles de langage propriétaires qui ne sont pas open source.
S'il existe une meilleure façon d'obtenir une fonctionnalité multimodale et d'intégrer diverses modalités dans LLM, cela nous apportera-t-il une expérience différente ?
Adresse papier : https://huggingface. co/papers/2309.16058
Selon la description, les principales contributions de cette recherche sont les suivantes :

- Le meilleur modèle de cet article a obtenu de bons résultats dans les évaluations automatiques et humaines sur diverses tâches et modalités. Par rapport aux modèles de la littérature existante, la précision relative de VQAv2 est augmentée de 7,0 %, le CIDEr des sous-titres d'images COCO sans erreur est augmenté de 8,4 % et le CIDEr d'AudioCaps est augmenté de 14,5 %. Méthode SOTA
Présentation de la méthode
Le contenu de l'alignement modal pré-entraîné doit être réécrit 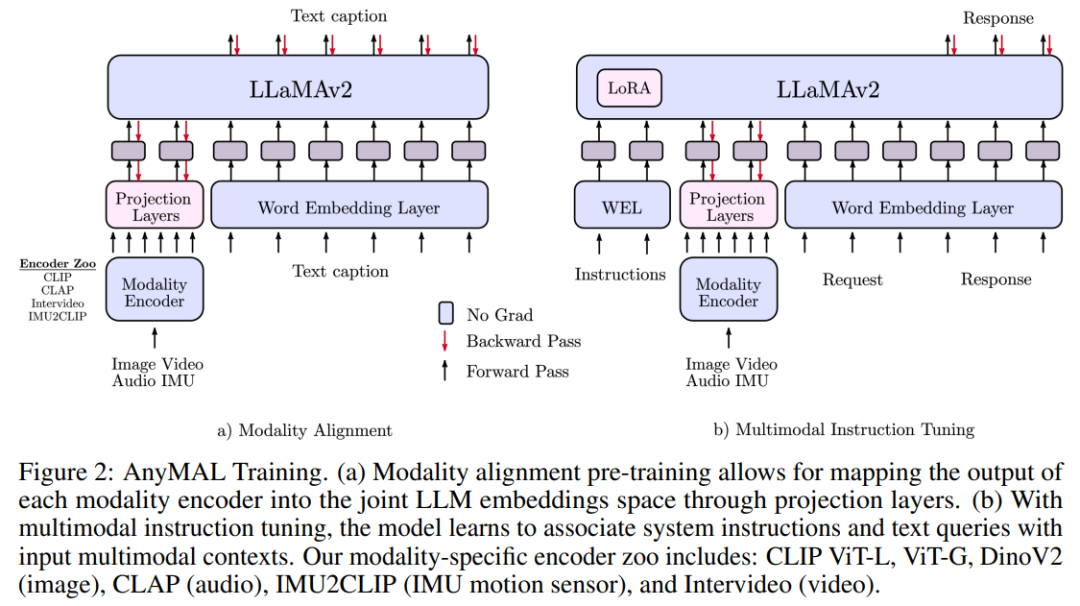 en utilisant des données multimodales appariées, y compris un signal modal spécifique et un récit textuel), cette étude LLM pré-entraîné pour atteindre des capacités de compréhension multimodale, comme le montre la figure 2. Plus précisément, nous formons un adaptateur léger pour chaque modalité qui projette le signal d'entrée dans l'espace d'intégration de jeton de texte d'un LLM spécifique. De cette façon, l'espace d'intégration de jetons de texte de LLM devient un espace d'intégration de jetons commun, où les jetons peuvent représenter du texte ou d'autres modalités
en utilisant des données multimodales appariées, y compris un signal modal spécifique et un récit textuel), cette étude LLM pré-entraîné pour atteindre des capacités de compréhension multimodale, comme le montre la figure 2. Plus précisément, nous formons un adaptateur léger pour chaque modalité qui projette le signal d'entrée dans l'espace d'intégration de jeton de texte d'un LLM spécifique. De cette façon, l'espace d'intégration de jetons de texte de LLM devient un espace d'intégration de jetons commun, où les jetons peuvent représenter du texte ou d'autres modalités
Pour les grands ensembles de données, la mise à l'échelle du pré-entraînement vers un modèle de paramètres de 70 B nécessite beaucoup de ressources, nécessitant souvent l'utilisation de wrappers FSDP sur plusieurs GPU. est fragmenté. Pour faire évoluer efficacement la formation, nous mettons en œuvre une stratégie de quantification (4 bits et 8 bits) dans un cadre multimodal, où la partie LLM du modèle est figée et seul le tokenizer modal peut être entraîné. Cette approche réduit les besoins en mémoire d'un ordre de grandeur. Par conséquent, 70B AnyMAL peut effectuer une formation sur un seul GPU VRAM de 80 Go avec une taille de lot de 4. Par rapport à FSDP, la méthode de quantification proposée dans cet article n'utilise que la moitié des ressources GPU, mais atteint le même débit
Utiliser des ensembles de données d'instructions multimodales pour un réglage fin signifie utiliser des ensembles de données d'instructions multimodales pour un réglage fin
Afin d'améliorer encore la capacité du modèle à suivre des instructions pour différentes modalités de saisie, nous étudions le utilisation d'ensembles de données d'instructions multimodales Des ajustements supplémentaires ont été effectués sur l'ensemble de données de réglage d'instructions (MM-IT) de pointe. Plus précisément, nous concaténons l'entrée sous la forme [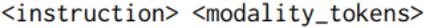 ] afin que la cible de réponse soit basée à la fois sur l'instruction textuelle et sur l'entrée modale. La recherche est menée sur les deux situations suivantes : (1) entraîner la couche de projection sans modifier les paramètres LLM ou (2) utiliser une adaptation de bas niveau (Low-Rank Adaptation) pour ajuster davantage le comportement du LM ; L’étude utilise à la fois des ensembles de données collectées manuellement et des données synthétiques.
] afin que la cible de réponse soit basée à la fois sur l'instruction textuelle et sur l'entrée modale. La recherche est menée sur les deux situations suivantes : (1) entraîner la couche de projection sans modifier les paramètres LLM ou (2) utiliser une adaptation de bas niveau (Low-Rank Adaptation) pour ajuster davantage le comportement du LM ; L’étude utilise à la fois des ensembles de données collectées manuellement et des données synthétiques.
Expériences et résultats
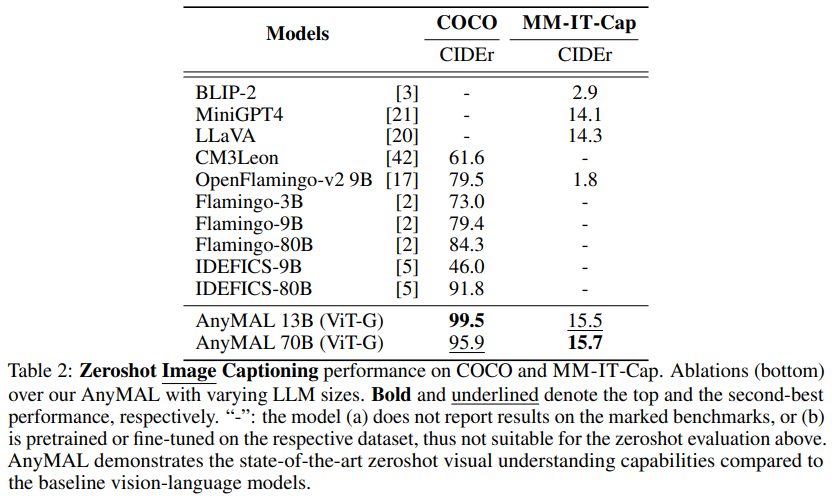
La génération de légendes d'images est une technologie d'intelligence artificielle utilisée pour générer automatiquement les légendes correspondantes pour les images. Cette technologie combine des méthodes de vision par ordinateur et de traitement du langage naturel pour générer des légendes descriptives liées à l'image en analysant le contenu et les caractéristiques de l'image, ainsi qu'en comprenant la sémantique et la syntaxe. La génération de légendes d'images a de nombreuses applications dans de nombreux domaines, notamment la recherche d'images, l'annotation d'images, la récupération d'images, etc. En générant automatiquement des titres, la compréhensibilité des images et la précision des moteurs de recherche peuvent être améliorées, offrant aux utilisateurs une meilleure expérience de récupération d'images et de navigation
Le tableau 2 montre les résultats dans COCO et les tâches marquées d'une « Description détaillée » (MM- Performances de génération de légendes d'images Zero-shot sur un sous-ensemble de l'ensemble de données MM-IT d'IT-Cap). Comme on peut le constater, la variante AnyMAL fonctionne nettement mieux que la ligne de base sur les deux ensembles de données. Notamment, il n'y a pas d'écart significatif en termes de performances entre les variantes AnyMAL-13B et AnyMAL-70B. Ce résultat démontre que la capacité sous-jacente du LLM pour la génération de légendes d’images est une technique d’intelligence artificielle utilisée pour générer automatiquement les légendes correspondantes des images. Cette technologie combine des méthodes de vision par ordinateur et de traitement du langage naturel pour générer des légendes descriptives liées à l'image en analysant le contenu et les caractéristiques de l'image, ainsi qu'en comprenant la sémantique et la syntaxe. La génération de légendes d'images a de nombreuses applications dans de nombreux domaines, notamment la recherche d'images, l'annotation d'images, la récupération d'images, etc. En automatisant la génération de sous-titres, la compréhensibilité des images et la précision des moteurs de recherche peuvent être améliorées, offrant ainsi aux utilisateurs une meilleure expérience de récupération et de navigation des images. La tâche a moins d'impact, mais dépend fortement de la taille des données et de la méthode d'enregistrement.
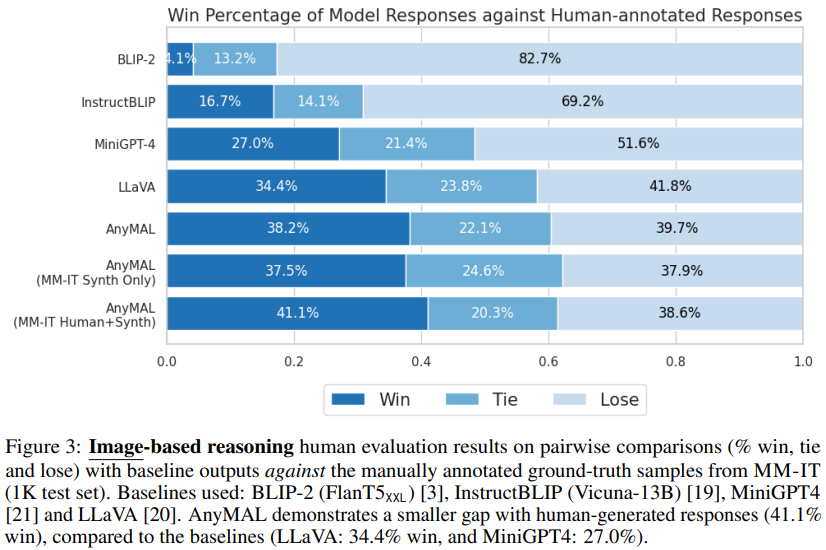
La réécriture requise est : Évaluation humaine sur la tâche d'inférence multimodale
La figure 3 montre qu'AnyMAL se compare à la ligne de base (LLaVA : 34,4 % de taux de victoire et MiniGPT4 : 27,0 % de taux de victoire) La performance est fort et l’écart avec les échantillons réels annotés par des humains est faible (taux de victoire de 41,1 %). Notamment, les modèles affinés avec le jeu d’instructions complet ont montré le taux de victoire prioritaire le plus élevé, démontrant des capacités de compréhension visuelle et de raisonnement comparables aux réponses annotées par l’homme. Il convient également de noter que BLIP-2 et InstructBLIP fonctionnent mal sur ces requêtes ouvertes (taux de victoire prioritaire de 4,1 % et 16,7 %, respectivement), bien qu'ils fonctionnent bien sur le benchmark public VQA (voir tableau 4).
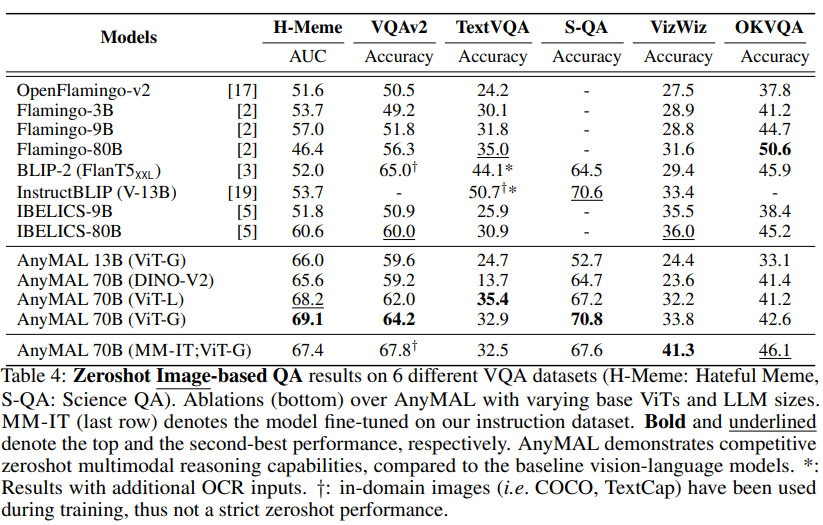
Benchmarks VQA
Dans le tableau 4, nous montrons les performances zéro-shot sur l'ensemble de données Hateful Meme, VQAv2, TextVQA, ScienceQA, VizWiz et OKVQA par rapport aux benchmarks respectifs rapportés dans la littérature. les résultats des échantillons ont été comparés. Notre recherche se concentre sur l'évaluation zéro-shot pour estimer le plus précisément possible les performances du modèle sur les requêtes ouvertes au moment de l'inférence. benchmarks d’assurance qualité vidéo.
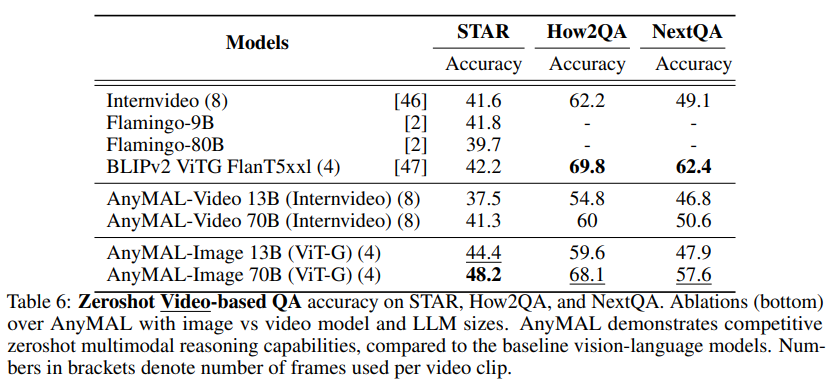
Régénération des sous-titres audio
Le tableau 5 montre les résultats de la régénération des sous-titres audio sur l'ensemble de données de référence AudioCaps. AnyMAL surpasse considérablement les autres modèles de sous-titres audio de pointe dans la littérature (par exemple, CIDEr +10,9pp, SPICE +5,8pp), indiquant que la méthode proposée est non seulement applicable à la vision mais également à diverses modalités. Le modèle text 70B présente des avantages évidents par rapport aux variantes 7B et 13B.
Fait intéressant, sur la base de la méthode, du type et du calendrier de soumission de l'article AnyMAL, Meta semble prévoir de collecter des données multimodales via son nouveau casque de réalité mixte/métaverse. Ces résultats de recherche pourraient être intégrés à la gamme de produits Metaverse de Meta, ou bientôt appliqués à des applications grand public
Veuillez lire l'article original pour plus de détails.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 L'auteur de ControlNet a encore un succès ! L'ensemble du processus de génération d'une peinture à partir d'une image, gagnant 1,4k étoiles en deux jours
Jul 17, 2024 am 01:56 AM
L'auteur de ControlNet a encore un succès ! L'ensemble du processus de génération d'une peinture à partir d'une image, gagnant 1,4k étoiles en deux jours
Jul 17, 2024 am 01:56 AM
Il s'agit également d'une vidéo Tusheng, mais PaintsUndo a emprunté une voie différente. L'auteur de ControlNet, LvminZhang, a recommencé à vivre ! Cette fois, je vise le domaine de la peinture. Le nouveau projet PaintsUndo a reçu 1,4kstar (toujours en hausse folle) peu de temps après son lancement. Adresse du projet : https://github.com/lllyasviel/Paints-UNDO Grâce à ce projet, l'utilisateur saisit une image statique et PaintsUndo peut automatiquement vous aider à générer une vidéo de l'ensemble du processus de peinture, du brouillon de ligne au suivi du produit fini. . Pendant le processus de dessin, les changements de lignes sont étonnants. Le résultat vidéo final est très similaire à l’image originale : jetons un coup d’œil à un dessin complet.
 Un nouveau casque VR Meta Quest 3S abordable apparaît sur FCC, suggérant un lancement imminent
Sep 04, 2024 am 06:51 AM
Un nouveau casque VR Meta Quest 3S abordable apparaît sur FCC, suggérant un lancement imminent
Sep 04, 2024 am 06:51 AM
L'événement Meta Connect 2024 est prévu du 25 au 26 septembre et lors de cet événement, la société devrait dévoiler un nouveau casque de réalité virtuelle abordable. Selon la rumeur, il s'agirait du Meta Quest 3S, le casque VR serait apparemment apparu sur la liste FCC. Cela suggère
 En tête de liste des ingénieurs logiciels d'IA open source, la solution sans agent de l'UIUC résout facilement les problèmes de programmation réels du banc SWE.
Jul 17, 2024 pm 10:02 PM
En tête de liste des ingénieurs logiciels d'IA open source, la solution sans agent de l'UIUC résout facilement les problèmes de programmation réels du banc SWE.
Jul 17, 2024 pm 10:02 PM
La colonne AIxiv est une colonne où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com Les auteurs de cet article font tous partie de l'équipe de l'enseignant Zhang Lingming de l'Université de l'Illinois à Urbana-Champaign (UIUC), notamment : Steven Code repair ; doctorant en quatrième année, chercheur
 Travail posthume de l'équipe OpenAI Super Alignment : deux grands modèles jouent à un jeu et le résultat devient plus compréhensible
Jul 19, 2024 am 01:29 AM
Travail posthume de l'équipe OpenAI Super Alignment : deux grands modèles jouent à un jeu et le résultat devient plus compréhensible
Jul 19, 2024 am 01:29 AM
Si la réponse donnée par le modèle d’IA est incompréhensible du tout, oseriez-vous l’utiliser ? À mesure que les systèmes d’apprentissage automatique sont utilisés dans des domaines de plus en plus importants, il devient de plus en plus important de démontrer pourquoi nous pouvons faire confiance à leurs résultats, et quand ne pas leur faire confiance. Une façon possible de gagner confiance dans le résultat d'un système complexe est d'exiger que le système produise une interprétation de son résultat qui soit lisible par un humain ou un autre système de confiance, c'est-à-dire entièrement compréhensible au point que toute erreur possible puisse être trouvé. Par exemple, pour renforcer la confiance dans le système judiciaire, nous exigeons que les tribunaux fournissent des avis écrits clairs et lisibles qui expliquent et soutiennent leurs décisions. Pour les grands modèles de langage, nous pouvons également adopter une approche similaire. Cependant, lorsque vous adoptez cette approche, assurez-vous que le modèle de langage génère
 Le premier modèle open source à dépasser le niveau GPT4o ! Llama 3.1 fuite : 405 milliards de paramètres, liens de téléchargement et cartes de modèles sont disponibles
Jul 23, 2024 pm 08:51 PM
Le premier modèle open source à dépasser le niveau GPT4o ! Llama 3.1 fuite : 405 milliards de paramètres, liens de téléchargement et cartes de modèles sont disponibles
Jul 23, 2024 pm 08:51 PM
Préparez votre GPU ! Llama3.1 est finalement apparu, mais la source n'est pas officielle de Meta. Aujourd'hui, la nouvelle divulguée du nouveau grand modèle Llama est devenue virale sur Reddit. En plus du modèle de base, elle comprend également des résultats de référence de 8B, 70B et le paramètre maximum de 405B. La figure ci-dessous montre les résultats de comparaison de chaque version de Llama3.1 avec OpenAIGPT-4o et Llama38B/70B. On peut voir que même la version 70B dépasse GPT-4o sur plusieurs benchmarks. Source de l'image : https://x.com/mattshumer_/status/1815444612414087294 Évidemment, version 3.1 de 8B et 70
 La formation Axiom permet au LLM d'apprendre le raisonnement causal : le modèle à 67 millions de paramètres est comparable au niveau de mille milliards de paramètres GPT-4.
Jul 17, 2024 am 10:14 AM
La formation Axiom permet au LLM d'apprendre le raisonnement causal : le modèle à 67 millions de paramètres est comparable au niveau de mille milliards de paramètres GPT-4.
Jul 17, 2024 am 10:14 AM
Montrez la chaîne causale à LLM et il pourra apprendre les axiomes. L'IA aide déjà les mathématiciens et les scientifiques à mener des recherches. Par exemple, le célèbre mathématicien Terence Tao a partagé à plusieurs reprises son expérience de recherche et d'exploration à l'aide d'outils d'IA tels que GPT. Pour que l’IA soit compétitive dans ces domaines, des capacités de raisonnement causal solides et fiables sont essentielles. La recherche présentée dans cet article a révélé qu'un modèle Transformer formé sur la démonstration de l'axiome de transitivité causale sur de petits graphes peut se généraliser à l'axiome de transitivité sur de grands graphes. En d’autres termes, si le Transformateur apprend à effectuer un raisonnement causal simple, il peut être utilisé pour un raisonnement causal plus complexe. Le cadre de formation axiomatique proposé par l'équipe est un nouveau paradigme pour l'apprentissage du raisonnement causal basé sur des données passives, avec uniquement des démonstrations.
 Les articles arXiv peuvent être publiés sous forme de 'barrage', la plateforme de discussion alphaXiv de Stanford est en ligne, LeCun l'aime
Aug 01, 2024 pm 05:18 PM
Les articles arXiv peuvent être publiés sous forme de 'barrage', la plateforme de discussion alphaXiv de Stanford est en ligne, LeCun l'aime
Aug 01, 2024 pm 05:18 PM
acclamations! Qu’est-ce que ça fait lorsqu’une discussion sur papier se résume à des mots ? Récemment, des étudiants de l'Université de Stanford ont créé alphaXiv, un forum de discussion ouvert pour les articles arXiv qui permet de publier des questions et des commentaires directement sur n'importe quel article arXiv. Lien du site Web : https://alphaxiv.org/ En fait, il n'est pas nécessaire de visiter spécifiquement ce site Web. Il suffit de remplacer arXiv dans n'importe quelle URL par alphaXiv pour ouvrir directement l'article correspondant sur le forum alphaXiv : vous pouvez localiser avec précision les paragraphes dans. l'article, Phrase : dans la zone de discussion sur la droite, les utilisateurs peuvent poser des questions à l'auteur sur les idées et les détails de l'article. Par exemple, ils peuvent également commenter le contenu de l'article, tels que : "Donné à".
 Une avancée significative dans l'hypothèse de Riemann ! Tao Zhexuan recommande fortement les nouveaux articles du MIT et d'Oxford, et le lauréat de la médaille Fields, âgé de 37 ans, a participé
Aug 05, 2024 pm 03:32 PM
Une avancée significative dans l'hypothèse de Riemann ! Tao Zhexuan recommande fortement les nouveaux articles du MIT et d'Oxford, et le lauréat de la médaille Fields, âgé de 37 ans, a participé
Aug 05, 2024 pm 03:32 PM
Récemment, l’hypothèse de Riemann, connue comme l’un des sept problèmes majeurs du millénaire, a réalisé une nouvelle avancée. L'hypothèse de Riemann est un problème mathématique non résolu très important, lié aux propriétés précises de la distribution des nombres premiers (les nombres premiers sont les nombres qui ne sont divisibles que par 1 et par eux-mêmes, et jouent un rôle fondamental dans la théorie des nombres). Dans la littérature mathématique actuelle, il existe plus d'un millier de propositions mathématiques basées sur l'établissement de l'hypothèse de Riemann (ou sa forme généralisée). En d’autres termes, une fois que l’hypothèse de Riemann et sa forme généralisée seront prouvées, ces plus d’un millier de propositions seront établies sous forme de théorèmes, qui auront un impact profond sur le domaine des mathématiques et si l’hypothèse de Riemann s’avère fausse, alors parmi eux ; ces propositions qui en font partie perdront également de leur efficacité. Une nouvelle percée vient du professeur de mathématiques du MIT, Larry Guth, et de l'Université d'Oxford
