
 Périphériques technologiques
IA
MVDiffusion : obtenez une génération d'images multi-vues de haute qualité et une reproduction précise des matériaux de la scène
Périphériques technologiques
IA
MVDiffusion : obtenez une génération d'images multi-vues de haute qualité et une reproduction précise des matériaux de la scène
MVDiffusion : obtenez une génération d'images multi-vues de haute qualité et une reproduction précise des matériaux de la scène

La génération d'images réalistes est largement utilisée dans des domaines tels que la réalité virtuelle, la réalité augmentée, les jeux vidéo et la production cinématographique.
Avec le développement rapide des modèles de diffusion au cours des deux dernières années, des avancées majeures ont été réalisées dans le domaine de la génération d'images. Une série de modèles open source ou commerciaux dérivés de Stable Diffusion pour générer des images basées sur des descriptions textuelles ont eu un impact énorme sur le design, les jeux et d'autres domaines.
Cependant, comment générer des images de haute qualité basées sur un texte donné ou autre conditions ? Les images multi-vues restent un défi. Les méthodes existantes présentent des défauts évidents dans la cohérence multi-vues
Les méthodes actuellement courantes peuvent être grossièrement divisées en deux catégories
La première catégorie de méthodes est dédiée à la génération d'images et de cartes de profondeur d'une scène, et à l'obtention du maillage correspondant. , tels que Text2Room, SceneScape - utilisez d'abord la diffusion stable pour générer la première image, puis utilisez la méthode autorégressive de déformation d'image et d'inpainting d'image pour générer des images et des cartes de profondeur ultérieures.
Cependant, une telle solution peut facilement provoquer une accumulation progressive d'erreurs lors de la génération de plusieurs images, et il existe généralement des problèmes en boucle fermée (par exemple, lorsque la caméra tourne et revient près de la position de départ, l'image générée le contenu est différent de la première image) Les images ne sont pas complètement cohérentes), ce qui entraîne des performances médiocres lorsque la scène est grande ou que l'angle de vision change de manière significative entre les images.
Le deuxième type de méthode génère plusieurs images en même temps en étendant l'algorithme de génération du modèle de diffusion pour produire un contenu plus riche qu'une seule image (comme générer un panorama à 360 degrés ou déplacer le contenu d'une image des deux côtés, extrapolation infinie), comme MultiDiffusion et DiffCollage. Cependant, le modèle de caméra n'étant pas pris en compte, les résultats générés par ce type de méthode ne sont pas de véritables panoramas. Le but de MVDiffusion est de générer des images multi-vues conformes à un modèle de caméra donné, et ces images sont strictement cohérentes dans leur contenu. et avoir une sémantique globale unifiée. L'idée principale de cette méthode est de débruiter et d'apprendre simultanément la correspondance entre les images pour maintenir la cohérence
Veuillez cliquer sur le lien suivant pour consulter l'article : https://arxiv.org/abs/2307.01097
Veuillez visiter le site Web du projet : https://mvdiffusion.github.io/
Démo : https://huggingface.co/spaces/tangshitao/MVDiffusion
Code : https://github. com/Tangshitao/ MVDiffusion
Conférence publiée : NeurIPS (Points clés)
L'objectif de MVDiffusion est de générer des images multi-vues avec un contenu hautement cohérent et une sémantique globale unifiée grâce à un débruitage simultané et une prise de conscience globale basée sur la correspondance entre images
Plus précisément, les chercheurs ont étendu le modèle de diffusion texte-image existant (tel que la diffusion stable), lui permettant d'abord de traiter plusieurs images en parallèle, et ont en outre ajouté un mécanisme supplémentaire d'"attention consciente de la correspondance" à l'original. UNet Pour apprendre la cohérence entre de multiples perspectives et l'unité mondiale.
En affinant une petite quantité de données d'entraînement d'images multi-vues, le modèle résultant peut générer simultanément des images multi-perspectives avec un contenu hautement cohérent.
MVDiffusion a obtenu de bons résultats dans trois scénarios d'application différents :
Générer plusieurs vues basées sur du texte, puis les assembler pour obtenir un panorama
2 Extrapoler l'image en perspective (surpeinture) ) Obtenir. un panorama complet à 360 degrés ;
3.
Affichage du scénario d'applicationApplication 1 : Le processus de génération de panorama consiste à assembler plusieurs photos ou vidéos pour créer une image ou une vidéo en perspective panoramique. Ce processus implique généralement l’utilisation de logiciels ou d’outils spéciaux pour aligner, mélanger et réparer automatiquement ou manuellement ces images ou vidéos. Grâce à la génération de panoramas, les utilisateurs peuvent apprécier et découvrir des scènes, telles que des paysages, des bâtiments ou des espaces intérieurs, avec une vue plus large. Cette technologie a un large éventail d'applications dans le tourisme, l'immobilier, la réalité virtuelle et d'autres domaines (selon le texte)
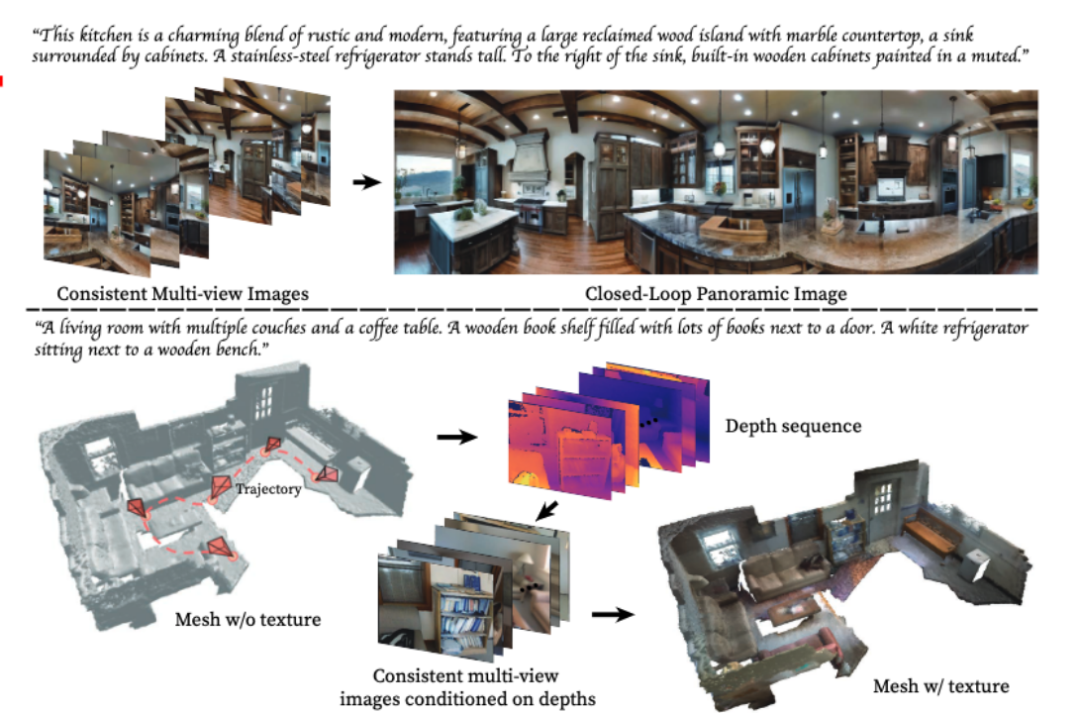
Prenons l'exemple de la génération d'un panorama, saisissez un texte décrivant la scène, MVDIffusion peut générer une image multi-perspectives de la scèneEntrez ce qui suit pour obtenir 8 images multi-vues : "Cette cuisine est un charmant mélange de rustique et de moderne, comprenant un grand îlot en bois de récupération avec des comptoirs en marbre et un évier entouré d'armoires. À gauche de l'îlot est un grand réfrigérateur en acier inoxydable. À droite de l'évier se trouvent des armoires encastrées en bois peintes dans des couleurs pastel."

Ces 8 images peuvent être fusionnées dans un panorama :

MVDiffusion prend également en charge la fourniture de descriptions textuelles différentes pour chaque image, mais la cohérence sémantique doit être maintenue entre ces descriptions.
Application 2 : Le processus de génération de panorama consiste à assembler plusieurs photos ou vidéos pour créer une image ou une vidéo en perspective panoramique. Ce processus implique généralement l’utilisation de logiciels ou d’outils spéciaux pour aligner, mélanger et réparer automatiquement ou manuellement ces images ou vidéos. Grâce à la génération de panoramas, les utilisateurs peuvent apprécier et découvrir des scènes, telles que des paysages, des bâtiments ou des espaces intérieurs, avec une vue plus large. Cette technologie a de nombreuses applications dans le tourisme, l'immobilier, la réalité virtuelle et d'autres domaines (basés sur une image en perspective)
MVDiffusion peut extrapoler (peinturer) une image en perspective dans un panorama complet à 360 degrés.
Par exemple, supposons que nous saisissions la perspective suivante :

MVDiffusion peut en outre générer le panorama suivant :

Comme vous pouvez le voir, le panorama généré est sémantiquement L'image d'entrée est développé et les contenus les plus à gauche et les plus à droite sont connectés (il n'y a pas de problème de boucle fermée).
Application 3 : Génération de matériaux de scène
Utilisation de MVDiffusion pour générer des matériaux (textures) pour un maillage de scène sans matériau donné
Plus précisément, nous obtenons d'abord une carte de profondeur multi-vues en rendant le maillage), via la caméra carte de pose et de profondeur, nous pouvons obtenir la correspondance entre les pixels de l'image multi-vue.
Ensuite, MVDiffusion utilise la carte de profondeur multi-vues comme condition pour générer simultanément des images RVB multi-vues cohérentes.
Étant donné que les images multi-vues générées peuvent maintenir le contenu très cohérent, puis les renvoyer dans le maillage, vous pouvez obtenir un maillage texturé de haute qualité (maillage texturé).
Voici d'autres exemples d'effets :
Le processus de génération de panorama consiste à assembler plusieurs photos ou vidéos pour créer une vue panoramique de l'image ou de la vidéo. Ce processus implique généralement l’utilisation de logiciels ou d’outils spéciaux pour aligner, mélanger et réparer automatiquement ou manuellement ces images ou vidéos. Grâce à la génération de panoramas, les utilisateurs peuvent apprécier et découvrir des scènes, telles que des paysages, des bâtiments ou des espaces intérieurs, avec une vue plus large. Cette technologie a un large éventail d'applications dans le tourisme, l'immobilier, la réalité virtuelle et d'autres domaines Dans ces scénarios d'application , spécial Il est mentionné que bien que les données d'image multi-vues utilisées dans la formation MVDiffusion proviennent toutes de panoramas de scènes d'intérieur et que les styles soient tous uniques
 , cependant, MVDiffusion ne modifie pas les paramètres de diffusion stables d'origine, mais seulement L'attention consciente de la correspondance nouvellement ajoutée a été formée
, cependant, MVDiffusion ne modifie pas les paramètres de diffusion stables d'origine, mais seulement L'attention consciente de la correspondance nouvellement ajoutée a été formée
Enfin, le modèle peut toujours générer des images multi-vues de différents styles (comme l'extérieur, le dessin animé, etc.) en fonction du texte donné.
Le contenu à réécrire est : extrapolation à vue unique



Scène génération de matériaux
 Nous allons d'abord Cet article présente le processus de génération d'images spécifique de MVDiffusion dans trois tâches différentes, et introduit enfin la partie centrale de la méthode, à savoir le module « Attention consciente de la correspondance ». La figure 1 montre un aperçu de MVDiffusion
Nous allons d'abord Cet article présente le processus de génération d'images spécifique de MVDiffusion dans trois tâches différentes, et introduit enfin la partie centrale de la méthode, à savoir le module « Attention consciente de la correspondance ». La figure 1 montre un aperçu de MVDiffusion
1. Le processus de génération de panorama consiste à assembler plusieurs photos ou vidéos pour créer une image ou une vidéo en perspective panoramique. Ce processus implique généralement l’utilisation de logiciels ou d’outils spéciaux pour aligner, mélanger et réparer automatiquement ou manuellement ces images ou vidéos. Grâce à la génération de panoramas, les utilisateurs peuvent apprécier et découvrir des scènes, telles que des paysages, des bâtiments ou des espaces intérieurs, avec une vue plus large. Cette technologie a de nombreuses applications dans le tourisme, l'immobilier, la réalité virtuelle et d'autres domaines (selon le texte)
MVDiffusion génère simultanément 8 images superposées (images en perspective), puis assemble ces 8 images (point) en un panorama. Dans ces 8 images en perspective, une matrice homographique 3x3 détermine la correspondance des pixels entre chacune des deux images.Dans le processus de génération spécifique, MVDiffusion utilise d'abord l'initialisation aléatoire gaussienne pour générer 8 vues d'images
Ensuite, ces 8 images sont entrées dans un réseau Unet pré-entraîné à diffusion stable avec plusieurs branches pour effectuer un débruitage synchrone. obtenir les résultats générés.
Un nouveau module "Correspondence-aware Attention" (partie bleu clair dans l'image ci-dessus) a été ajouté au réseau UNet, qui permet d'apprendre la cohérence géométrique entre les vues croisées, afin que ces 8 images puissent être assemblé en un seul Un panorama cohérent.
2. Le processus de génération de panorama consiste à assembler plusieurs photos ou vidéos pour créer une image ou une vidéo en perspective panoramique. Ce processus implique généralement l’utilisation de logiciels ou d’outils spéciaux pour aligner, mélanger et réparer automatiquement ou manuellement ces images ou vidéos. Grâce à la génération de panoramas, les utilisateurs peuvent apprécier et découvrir des scènes, telles que des paysages, des bâtiments ou des espaces intérieurs, avec une vue plus large. Cette technologie a de nombreuses applications dans le tourisme, l'immobilier, la réalité virtuelle et d'autres domaines (basés sur une image en perspective)
MVDiffusion peut également compléter une image en perspective unique en un panorama. Le processus de génération de panorama consiste à assembler plusieurs photos ou vidéos pour créer une vue panoramique de l'image ou de la vidéo. Ce processus implique généralement l’utilisation de logiciels ou d’outils spéciaux pour aligner, mélanger et réparer automatiquement ou manuellement ces images ou vidéos. Grâce à la génération de panoramas, les utilisateurs peuvent apprécier et découvrir des scènes, telles que des paysages, des bâtiments ou des espaces intérieurs, avec une vue plus large. Cette technologie a un large éventail d'applications dans le tourisme, l'immobilier, la réalité virtuelle et d'autres domaines. MVDiffusion introduit de manière aléatoire 8 images en perspective (y compris les perspectives correspondant aux vues en perspective) dans le réseau UNet pré-entraîné à plusieurs branches Stable Diffusion Inpainting. Dans le modèle Stable Diffusion Inpainting, la différence est que UNet utilise un masque de saisie supplémentaire pour distinguer l'image comme condition et l'image à générer
La perspective correspondant à la perspective, masque Si le code est mis à 1, l'UNet de cette branche restaurera directement la perspective. Pour les autres perspectives, le masque est mis à 0, et l'UNet de la branche correspondante générera une nouvelle vue en perspective
De même, MVDiffusion utilise le module "Correspondence-aware Attention" pour apprendre la cohérence géométrique entre l'image générée et l'image conditionnelle.
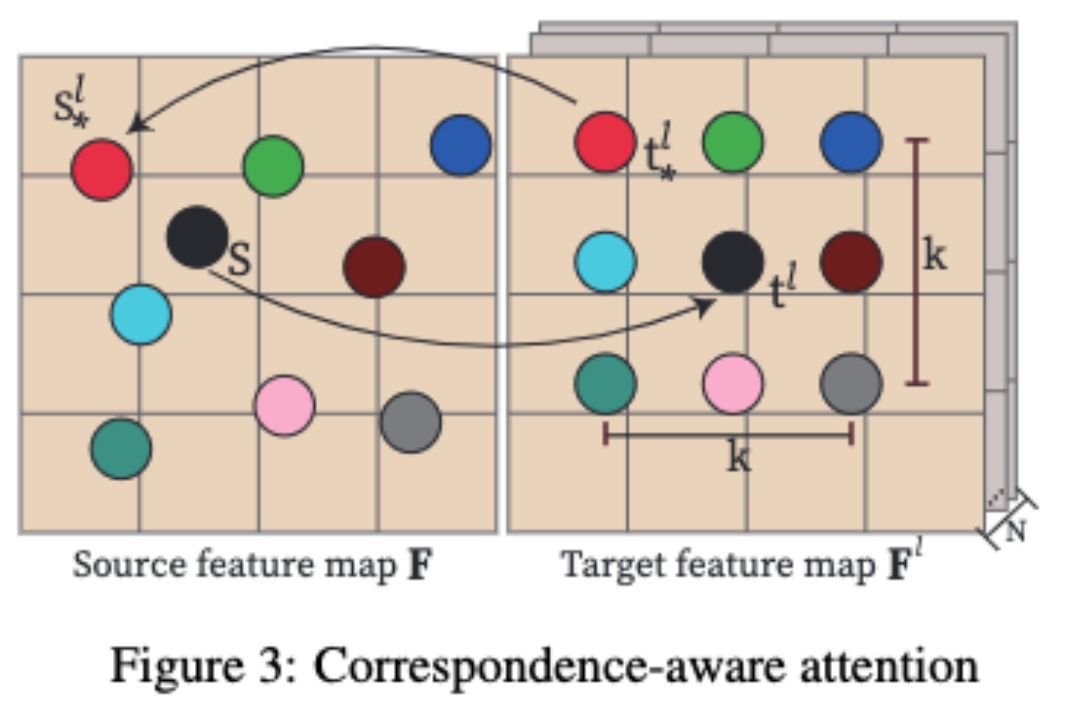
MVDiffusion génère d'abord une image RVB sur une trajectoire basée sur la carte de profondeur et la pose de la caméra, puis utilise la fusion TSDF pour synthétiser l'image RVB générée avec la carte de profondeur donnée dans un maillage. La correspondance des pixels des images RVB peut être obtenue grâce à la carte de profondeur et à la pose de la caméra. Le processus de génération de panorama consiste à assembler plusieurs photos ou vidéos pour créer une vue panoramique de l'image ou de la vidéo. Ce processus implique généralement l’utilisation de logiciels ou d’outils spéciaux pour aligner, mélanger et réparer automatiquement ou manuellement ces images ou vidéos. Grâce à la génération de panoramas, les utilisateurs peuvent apprécier et découvrir des scènes, telles que des paysages, des bâtiments ou des espaces intérieurs, avec une vue plus large. Cette technologie a un large éventail d'applications dans le tourisme, l'immobilier, la réalité virtuelle et d'autres domaines. Nous utilisons UNet multibranche et insérons « Attention consciente de la correspondance » pour apprendre la cohérence géométrique entre les perspectives. "L'attention consciente de la correspondance" (CAA) est au cœur de MVDiffusion et est utilisée pour apprendre la cohérence géométrique et l'unité sémantique entre plusieurs vues. MVDiffusion insère le bloc "Correspondence-aware Attention" après chaque bloc UNet dans Stable Diffusion UNet. CAA fonctionne en considérant une carte de fonctionnalités source et N cartes de fonctionnalités cibles. Pour un emplacement dans la carte des caractéristiques source, nous calculons la sortie d'attention en fonction du pixel correspondant et de son voisinage dans la carte des caractéristiques cible. Plus précisément, pour chaque pixel cible t^l, MVDiffusion considérera un voisinage K x K en ajoutant un déplacement entier (dx/dy) aux coordonnées (x/y), où |dx| représente le déplacement dans la direction x, |dy| représente le déplacement dans la direction y Dans les applications pratiques, l'algorithme MVDiffusion utilise K=3 et sélectionne des voisinages de 9 points pour améliorer la qualité du panorama. Cependant, lors de la génération d'images multi-vues soumises à des conditions géométriques, afin d'améliorer l'efficacité opérationnelle, nous choisissons d'utiliser K=1 Le calcul du module CAA suit le mécanisme d'attention standard, comme indiqué dans le formule ci-dessus, où W_Q, W_K et W_V sont les poids apprenables des matrices de requête, de clé et de valeur ; les caractéristiques cibles ne sont pas situées à des positions entières mais sont obtenues par interpolation bilinéaire ; La principale différence est que l'encodage de position est ajouté à l'entité cible en fonction du déplacement 2D (panorama) ou de l'erreur de profondeur 1D (géométrie) entre les positions correspondantes s^l et s dans l'image source. Dans la génération de panorama (Application 1 et Application 2), ce déplacement fournit la position relative dans le voisinage local. Et dans la génération profondeur-image (Application 3), la disparité fournit des indices sur les discontinuités ou les occlusions de profondeur, ce qui est très important pour la génération d'images haute fidélité. Veuillez noter que le déplacement est un concept contenant un vecteur 2D (déplacement) ou 1D (erreur de profondeur). MVDiffusion applique un codage de fréquence standard aux coordonnées x et y du déplacement
3. Génération de matériau de scène
4. Mécanisme d'attention consciente de la correspondance
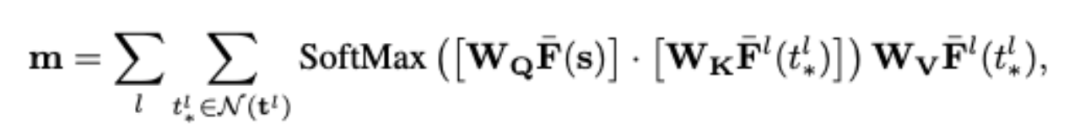
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Clause SQLLIMIT: Contrôlez le nombre de lignes dans les résultats de la requête. La clause limite dans SQL est utilisée pour limiter le nombre de lignes renvoyées par la requête. Ceci est très utile lors du traitement de grands ensembles de données, des affichages paginés et des données de test, et peut améliorer efficacement l'efficacité de la requête. Syntaxe de base de la syntaxe: selectColumn1, Column2, ... FromTable_NamelimitNumber_Of_Rows; Number_OF_ROWS: Spécifiez le nombre de lignes renvoyées. Syntaxe avec décalage: selectColumn1, Column2, ... FromTable_Namelimitoffset, numéro_of_rows; décalage: sauter
 Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Guide d'optimisation des performances de la base de données MySQL dans les applications à forte intensité de ressources, la base de données MySQL joue un rôle crucial et est responsable de la gestion des transactions massives. Cependant, à mesure que l'échelle de l'application se développe, les goulots d'étranglement des performances de la base de données deviennent souvent une contrainte. Cet article explorera une série de stratégies efficaces d'optimisation des performances MySQL pour garantir que votre application reste efficace et réactive dans des charges élevées. Nous combinerons des cas réels pour expliquer les technologies clés approfondies telles que l'indexation, l'optimisation des requêtes, la conception de la base de données et la mise en cache. 1. La conception de l'architecture de la base de données et l'architecture optimisée de la base de données sont la pierre angulaire de l'optimisation des performances MySQL. Voici quelques principes de base: sélectionner le bon type de données et sélectionner le plus petit type de données qui répond aux besoins peut non seulement économiser un espace de stockage, mais également améliorer la vitesse de traitement des données.
 Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Il est impossible de visualiser le mot de passe MongoDB directement via NAVICAT car il est stocké sous forme de valeurs de hachage. Comment récupérer les mots de passe perdus: 1. Réinitialiser les mots de passe; 2. Vérifiez les fichiers de configuration (peut contenir des valeurs de hachage); 3. Vérifiez les codes (May Code Hardcode).
 Master la clause Order Order by dans SQL: Trier efficacement les données
Apr 08, 2025 pm 07:03 PM
Master la clause Order Order by dans SQL: Trier efficacement les données
Apr 08, 2025 pm 07:03 PM
Explication détaillée de la clause SqlorderBy: le tri efficace de la clause de données d'ordre de données est une déclaration clé de SQL utilisée pour trier les ensembles de résultats de requête. Il peut être organisé en ordre ascendant (ASC) ou ordre décroissant (DESC) dans des colonnes uniques ou plusieurs colonnes, améliorant considérablement la lisibilité des données et l'efficacité de l'analyse. OrderBy Syntax selectColumn1, Column2, ... FromTable_NameOrderByColumn_Name [ASC | DESC]; Column_name: Triez par colonne. ASC: Ascendance Order Sort (par défaut). DESC: Trier en ordre décroissant. ORDERBY Fonctionnalités principales: Tri multi-colonnes: prend en charge le tri de plusieurs colonnes et l'ordre des colonnes détermine la priorité du tri. depuis
 Navicat se connecte au code et à la solution d'erreur de base de données
Apr 08, 2025 pm 11:06 PM
Navicat se connecte au code et à la solution d'erreur de base de données
Apr 08, 2025 pm 11:06 PM
Erreurs et solutions courantes Lors de la connexion aux bases de données: nom d'utilisateur ou mot de passe (erreur 1045) Blocs de pare-feu Connexion (erreur 2003) Délai de connexion (erreur 10060) Impossible d'utiliser la connexion à socket (erreur 1042) Erreur de connexion SSL (erreur 10055) Trop de connexions Résultat de l'hôte étant bloqué (erreur 1129)
 Comment rédiger le dernier tutoriel sur la déclaration d'insertion SQL
Apr 09, 2025 pm 01:48 PM
Comment rédiger le dernier tutoriel sur la déclaration d'insertion SQL
Apr 09, 2025 pm 01:48 PM
L'instruction INSERT SQL est utilisée pour ajouter de nouvelles lignes à une table de base de données, et sa syntaxe est: Insérer dans Table_Name (Column1, Column2, ..., Columnn) VALEUR (VALEUR1, Value2, ..., Valuen);. Cette instruction prend en charge l'insertion de plusieurs valeurs et permet d'insérer des valeurs nulles dans des colonnes, mais il est nécessaire de s'assurer que les valeurs insérées sont compatibles avec le type de données de la colonne pour éviter de violer les contraintes d'unicité.
 Y a-t-il une procédure stockée dans MySQL
Apr 08, 2025 pm 03:45 PM
Y a-t-il une procédure stockée dans MySQL
Apr 08, 2025 pm 03:45 PM
MySQL fournit des procédures stockées, qui sont un bloc de code SQL précompilé qui résume la logique complexe, améliore la réutilisabilité du code et la sécurité. Ses fonctions principales incluent des boucles, des instructions conditionnelles, des curseurs et un contrôle des transactions. En appelant des procédures stockées, les utilisateurs peuvent effectuer des opérations de base de données en entrant et en sortie, sans prêter attention aux implémentations internes. Cependant, il est nécessaire de prêter attention à des problèmes communs tels que les erreurs de syntaxe, les problèmes d'autorisation et les erreurs logiques, et de suivre les principes d'optimisation des performances et de meilleures pratiques.
