
 Périphériques technologiques
Industrie informatique
Nvidia et Wistron discutent de l'augmentation des commandes de substrats IA au premier trimestre de l'année prochaine
Périphériques technologiques
Industrie informatique
Nvidia et Wistron discutent de l'augmentation des commandes de substrats IA au premier trimestre de l'année prochaine
Nvidia et Wistron discutent de l'augmentation des commandes de substrats IA au premier trimestre de l'année prochaine

Selon une enquête menée par Ming-Chi Kuo, analyste de Tianfeng International, Nvidia discute avec Wistron pour augmenter les commandes de substrats d'IA au premier trimestre de l'année prochaine, considérant que l'offre de CoWoS et HBM s'améliorera considérablement au quatrième trimestre et sera bénéfique pour visibilité sur la production future
Grâce à cela, les commandes de substrats de Wistron devraient augmenter considérablement d'environ 60 % au premier trimestre 2024. Si la capacité de production est insuffisante, certaines commandes seront transférées à la production au deuxième trimestre de l'année prochaine.
(Remarque de ce site : le substrat fait principalement référence au matériau de base utilisé pour fabriquer des PCB et est également un composant principal indispensable pour la plupart des produits électroniques aujourd'hui.)

Bénéficiant de nouvelles commandes, le substrat NVIDIA AI Chip de Wistron les expéditions devraient atteindre un nouveau sommet au quatrième trimestre de cette année et continueront de croître de 10 à 20 % au premier trimestre de l'année prochaine. Wistron devrait obtenir des commandes de modules pour le B100.
Déclaration publicitaire : cet article contient des liens de saut externes (y compris, mais sans s'y limiter, des hyperliens, des codes QR, des mots de passe, etc.), qui sont conçus pour fournir plus d'informations et gagner du temps de vérification. Les résultats sont uniquement à titre de référence. Veuillez noter que tous les articles de ce site contiennent cette déclaration
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Ce site a rapporté le 27 juin que Jianying est un logiciel de montage vidéo développé par FaceMeng Technology, une filiale de ByteDance. Il s'appuie sur la plateforme Douyin et produit essentiellement du contenu vidéo court pour les utilisateurs de la plateforme. Il est compatible avec iOS, Android et. Windows, MacOS et autres systèmes d'exploitation. Jianying a officiellement annoncé la mise à niveau de son système d'adhésion et a lancé un nouveau SVIP, qui comprend une variété de technologies noires d'IA, telles que la traduction intelligente, la mise en évidence intelligente, l'emballage intelligent, la synthèse humaine numérique, etc. En termes de prix, les frais mensuels pour le clipping SVIP sont de 79 yuans, les frais annuels sont de 599 yuans (attention sur ce site : équivalent à 49,9 yuans par mois), l'abonnement mensuel continu est de 59 yuans par mois et l'abonnement annuel continu est de 59 yuans par mois. est de 499 yuans par an (équivalent à 41,6 yuans par mois) . En outre, le responsable de Cut a également déclaré que afin d'améliorer l'expérience utilisateur, ceux qui se sont abonnés au VIP d'origine
 Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Améliorez la productivité, l’efficacité et la précision des développeurs en intégrant une génération et une mémoire sémantique améliorées par la récupération dans les assistants de codage IA. Traduit de EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, auteur JanakiramMSV. Bien que les assistants de programmation d'IA de base soient naturellement utiles, ils ne parviennent souvent pas à fournir les suggestions de code les plus pertinentes et les plus correctes, car ils s'appuient sur une compréhension générale du langage logiciel et des modèles d'écriture de logiciels les plus courants. Le code généré par ces assistants de codage est adapté à la résolution des problèmes qu’ils sont chargés de résoudre, mais n’est souvent pas conforme aux normes, conventions et styles de codage des équipes individuelles. Cela aboutit souvent à des suggestions qui doivent être modifiées ou affinées pour que le code soit accepté dans l'application.
 Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Les grands modèles linguistiques (LLM) sont formés sur d'énormes bases de données textuelles, où ils acquièrent de grandes quantités de connaissances du monde réel. Ces connaissances sont intégrées à leurs paramètres et peuvent ensuite être utilisées en cas de besoin. La connaissance de ces modèles est « réifiée » en fin de formation. À la fin de la pré-formation, le modèle arrête effectivement d’apprendre. Alignez ou affinez le modèle pour apprendre à exploiter ces connaissances et répondre plus naturellement aux questions des utilisateurs. Mais parfois, la connaissance du modèle ne suffit pas, et bien que le modèle puisse accéder à du contenu externe via RAG, il est considéré comme bénéfique de l'adapter à de nouveaux domaines grâce à un réglage fin. Ce réglage fin est effectué à l'aide de la contribution d'annotateurs humains ou d'autres créations LLM, où le modèle rencontre des connaissances supplémentaires du monde réel et les intègre.
 Le modèle de dialogue NVIDIA ChatQA a évolué vers la version 2.0, avec la longueur du contexte mentionnée à 128 Ko
Jul 26, 2024 am 08:40 AM
Le modèle de dialogue NVIDIA ChatQA a évolué vers la version 2.0, avec la longueur du contexte mentionnée à 128 Ko
Jul 26, 2024 am 08:40 AM
La communauté ouverte LLM est une époque où une centaine de fleurs fleurissent et s'affrontent. Vous pouvez voir Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 et bien d'autres. excellents interprètes. Cependant, par rapport aux grands modèles propriétaires représentés par le GPT-4-Turbo, les modèles ouverts présentent encore des lacunes importantes dans de nombreux domaines. En plus des modèles généraux, certains modèles ouverts spécialisés dans des domaines clés ont été développés, tels que DeepSeek-Coder-V2 pour la programmation et les mathématiques, et InternVL pour les tâches de langage visuel.
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
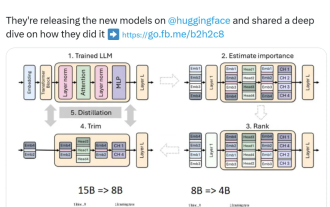 Nvidia joue avec l'élagage et la distillation : réduisant de moitié les paramètres de Llama 3.1 8B pour obtenir de meilleures performances avec la même taille
Aug 16, 2024 pm 04:42 PM
Nvidia joue avec l'élagage et la distillation : réduisant de moitié les paramètres de Llama 3.1 8B pour obtenir de meilleures performances avec la même taille
Aug 16, 2024 pm 04:42 PM
L’essor des petits modèles. Le mois dernier, Meta a publié la série de modèles Llama3.1, qui comprend le plus grand modèle Meta à ce jour, le modèle 405B, et deux modèles plus petits avec respectivement 70 milliards et 8 milliards de paramètres. Llama3.1 est considéré comme inaugurant une nouvelle ère de l'open source. Cependant, bien que les modèles de nouvelle génération soient puissants en termes de performances, ils nécessitent néanmoins une grande quantité de ressources informatiques lors de leur déploiement. Par conséquent, une autre tendance est apparue dans l’industrie, qui consiste à développer des petits modèles de langage (SLM) qui fonctionnent suffisamment bien dans de nombreuses tâches linguistiques et sont également très peu coûteux à déployer. Récemment, des recherches de NVIDIA ont montré qu'un élagage structuré combiné à une distillation des connaissances permet d'obtenir progressivement des modèles de langage plus petits à partir d'un modèle initialement plus grand. Lauréat du prix Turing, Meta Chief A
 Conforme à la spécification NVIDIA SFF-Ready, ASUS lance les cartes graphiques Prime GeForce RTX série 40
Jun 15, 2024 pm 04:38 PM
Conforme à la spécification NVIDIA SFF-Ready, ASUS lance les cartes graphiques Prime GeForce RTX série 40
Jun 15, 2024 pm 04:38 PM
Selon les informations de ce site du 15 juin, Asus a récemment lancé la carte graphique GeForce RTX40 "Ada" de la série Prime. Sa taille est conforme à la dernière spécification SFF-Ready de Nvidia, qui exige que la taille de la carte graphique ne dépasse pas 304. mm x 151 mm x 50 mm (longueur x hauteur x épaisseur). La série Prime GeForceRTX40 lancée par ASUS comprend cette fois RTX4060Ti, RTX4070 et RTX4070SUPER, mais elle n'inclut actuellement pas RTX4070TiSUPER ou RTX4080SUPER. Cette série de cartes graphiques RTX40 adopte une conception de circuit imprimé commune avec des dimensions de 269 mm x 120 mm x 50 mm. Les principales différences entre les trois cartes graphiques sont.
 Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Editeur | KX Dans le domaine de la recherche et du développement de médicaments, il est crucial de prédire avec précision et efficacité l'affinité de liaison des protéines et des ligands pour le criblage et l'optimisation des médicaments. Cependant, les études actuelles ne prennent pas en compte le rôle important des informations sur la surface moléculaire dans les interactions protéine-ligand. Sur cette base, des chercheurs de l'Université de Xiamen ont proposé un nouveau cadre d'extraction de caractéristiques multimodales (MFE), qui combine pour la première fois des informations sur la surface des protéines, la structure et la séquence 3D, et utilise un mécanisme d'attention croisée pour comparer différentes modalités. alignement. Les résultats expérimentaux démontrent que cette méthode atteint des performances de pointe dans la prédiction des affinités de liaison protéine-ligand. De plus, les études d’ablation démontrent l’efficacité et la nécessité des informations sur la surface des protéines et de l’alignement des caractéristiques multimodales dans ce cadre. Les recherches connexes commencent par "S
