
 Périphériques technologiques
IA
Loin devant ! BEVHeight++ : Une nouvelle solution de détection visuelle de cibles 3D en bordure de route !
Périphériques technologiques
IA
Loin devant ! BEVHeight++ : Une nouvelle solution de détection visuelle de cibles 3D en bordure de route !
Loin devant ! BEVHeight++ : Une nouvelle solution de détection visuelle de cibles 3D en bordure de route !

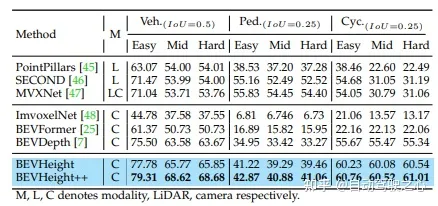
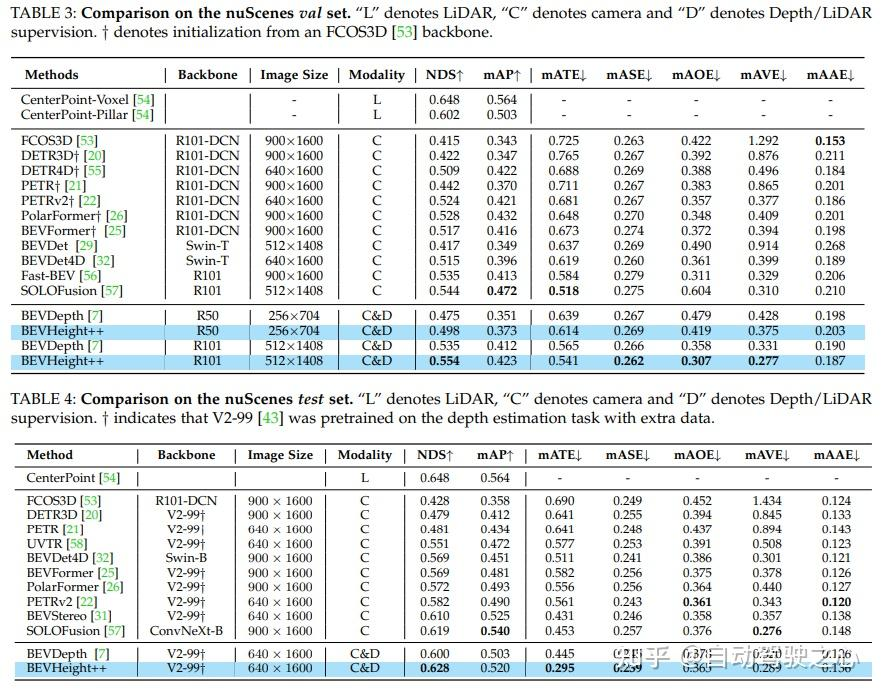
Régressez à la hauteur du sol pour obtenir une formulation indépendante de la distance, simplifiant ainsi le processus d'optimisation pour les méthodes uniquement compatibles avec la caméra. Sur le benchmark de détection 3D des caméras routières, la méthode dépasse largement toutes les méthodes précédentes centrées sur la vision. Il génère des améliorations significatives de +1,9 % NDS et +1,1 % mAP par rapport à BEVDepth. Sur l'ensemble de tests nuScenes, la méthode a réalisé des progrès substantiels, avec NDS et mAP augmentant respectivement de +2,8 % et +1,7 %.
Titre : BEVHeight++ : Vers une détection robuste d'objets 3D centrée sur la vision
Lien papier : https://arxiv.org/pdf/2309.16179.pdf
Affiliation de l'auteur : Université Tsinghua, Université Sun Yat-sen, Réseau Cainiao, Pékin Université
De la première communauté de conduite autonome en Chine : a finalement achevé la construction de plus de 20 itinéraires d'apprentissage de la direction technique (perception BEV/détection 3D/fusion multicapteur/SLAM et planification, etc.)
Bien que la récente Le système de conduite se concentre sur le développement de méthodes de détection pour les capteurs des véhicules, mais une alternative souvent négligée est l'utilisation de caméras routières intelligentes pour étendre les capacités de détection au-delà de la portée visuelle. Les auteurs ont constaté que les méthodes de détection BEV de pointe, centrées sur la vision, fonctionnent mal sur les caméras routières. En effet, ces méthodes se concentrent principalement sur la récupération de la profondeur autour du centre de la caméra, où la différence de profondeur entre la voiture et le sol diminue rapidement avec la distance. Dans cet article, l'auteur propose une méthode simple mais efficace, appelée BEVHeight++, pour résoudre ce problème. Essentiellement, les auteurs régressent à la hauteur du sol pour obtenir une formulation indépendante de la distance, simplifiant ainsi le processus d'optimisation pour les méthodes prenant uniquement en compte la caméra. En combinant des techniques de codage en hauteur et en profondeur, une projection plus précise et plus robuste de l'espace 2D vers l'espace BEV est obtenue. La méthode surpasse considérablement toutes les méthodes précédentes centrées sur la vision sur le test de détection 3D populaire pour les caméras routières. Pour les scènes de véhicules autonomes, BEVHeight++ surpasse les méthodes de profondeur uniquement
Plus précisément, il génère des améliorations significatives de +1,9 % NDS et +1,1 % mAP par rapport à BEVDepth lorsqu'il est évalué sur l'ensemble de validation nuScenes. De plus, sur l'ensemble de tests nuScenes, la méthode réalise des progrès substantiels, avec NDS et mAP augmentant respectivement de +2,8 % et +1,7 %.
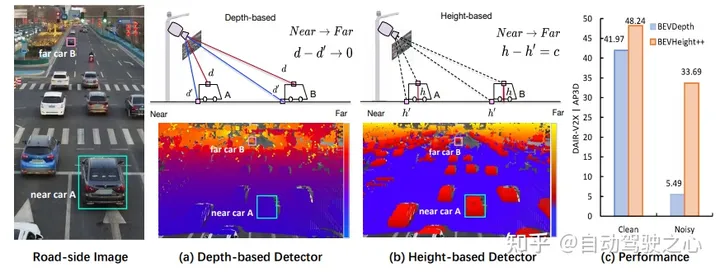
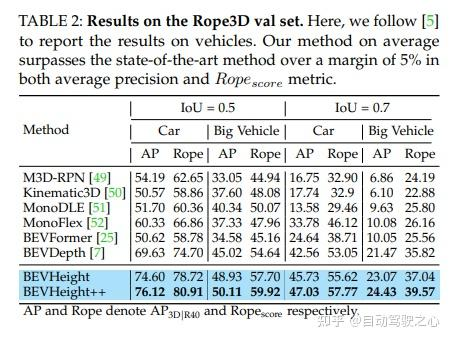
Figure 1 : (a) Pour générer des cadres de délimitation 3D à partir d'images monoculaires, les méthodes de pointe prédisent d'abord la profondeur par pixel, explicitement ou implicitement, pour déterminer la position 3D des objets de premier plan par rapport à la arrière-plan. Cependant, lorsque nous avons tracé la profondeur par pixel sur l'image, nous avons remarqué que la différence entre les points sur le toit et le sol environnant diminue rapidement à mesure que la voiture s'éloigne de la caméra, ce qui rend l'optimisation sous-optimale, en particulier pour les objets éloignés. . (b) Au lieu de cela, nous traçons la hauteur par pixel par rapport au sol et observons que cette différence est indépendante de la distance et est visuellement plus adaptée au réseau pour détecter des objets. Cependant, la position 3D ne peut pas être directement régressée en prédisant uniquement la hauteur. (c) À cette fin, nous proposons un nouveau framework BEVHeight++ pour résoudre ce problème. Les résultats empiriques montrent que notre méthode surpasse la meilleure méthode de 5,49 % sur les paramètres propres et de 28,2 % sur les paramètres bruyants.
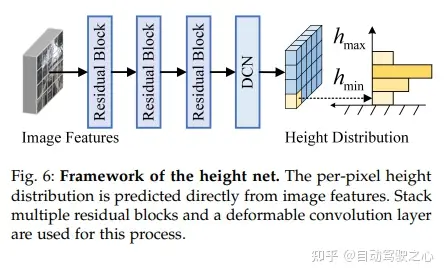
Structure du réseau
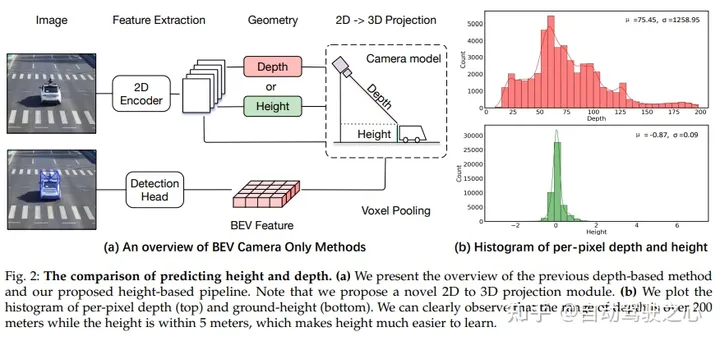
Comparaison de la hauteur et de la profondeur de prédiction. (a) Aperçu des méthodes précédentes basées sur la profondeur et de notre proposition de pipeline basé sur la hauteur. Veuillez noter que cet article propose un nouveau module de projection 2D vers 3D. (b) En traçant des histogrammes de profondeur par pixel (en haut) et de hauteur du sol (en bas), on peut clairement observer que la plage de profondeur est supérieure à 200 mètres, tandis que la hauteur est inférieure à 5 mètres, ce qui rend la hauteur plus facile à apprendre.
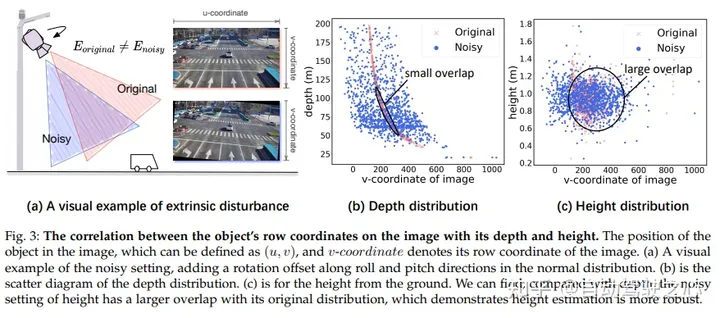
Dans l'image, il existe une corrélation entre les coordonnées de ligne de la cible et sa profondeur et sa hauteur. La position de la cible dans l'image peut être définie par (u, v), où v représente la coordonnée de ligne de l'image. Dans (a), nous montrons un exemple visuel d’introduction de bruit en ajoutant des décalages de rotation dans les directions de roulis et de tangage à une distribution normale. En (b), nous montrons un nuage de points de la distribution de profondeur. En (c) nous montrons la hauteur au-dessus du sol. Nous pouvons observer que le réglage du bruit pour la hauteur chevauche davantage sa distribution d'origine par rapport à la profondeur, ce qui indique que l'estimation de la hauteur est plus robuste
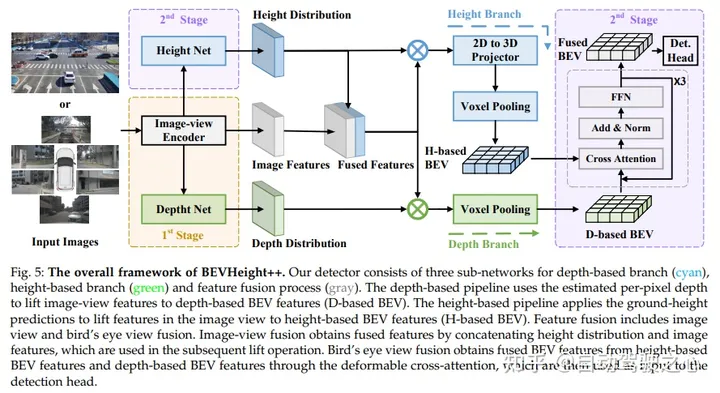
Le cadre global de BEVHeight++ contient trois sous-réseaux, à savoir la branche basée sur la profondeur (cyan), la branche basée sur la hauteur (vert) et le processus de fusion de fonctionnalités (gris). Le pipeline basé sur la profondeur convertit les fonctionnalités d'affichage d'image en fonctionnalités BEV basées sur la profondeur (BEV basé sur D) en utilisant la profondeur estimée par pixel. Le pipeline basé sur la hauteur génère des caractéristiques BEV basées sur la hauteur (BEV basée sur H) à l'aide de prédictions de hauteur au sol des caractéristiques de levage dans des vues d'image. La fusion de fonctionnalités inclut la fusion d’images et la fusion de vues à vol d’oiseau. La fusion image-vue obtient des caractéristiques de fusion en mettant en cascade la distribution de hauteur et les caractéristiques d'image, qui sont utilisées pour les opérations de mise à niveau ultérieures. La fusion avec vue à vol d'oiseau obtient des caractéristiques BEV fusionnées à partir de caractéristiques BEV basées sur la hauteur et de caractéristiques BEV basées sur la profondeur grâce à une attention croisée déformable, puis l'utilise comme entrée de la tête de détection
Résultats expérimentaux

Le contenu qui doit être réécrit est : Lien original : https://mp.weixin.qq.com/s/AdCXYzHIy2lTfAHk2AZ4_w
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 La multiplication matricielle universelle de CUDA : de l'entrée à la maîtrise !
Mar 25, 2024 pm 12:30 PM
La multiplication matricielle universelle de CUDA : de l'entrée à la maîtrise !
Mar 25, 2024 pm 12:30 PM
La multiplication matricielle générale (GEMM) est un élément essentiel de nombreuses applications et algorithmes, et constitue également l'un des indicateurs importants pour évaluer les performances du matériel informatique. Une recherche approfondie et l'optimisation de la mise en œuvre de GEMM peuvent nous aider à mieux comprendre le calcul haute performance et la relation entre les systèmes logiciels et matériels. En informatique, une optimisation efficace de GEMM peut augmenter la vitesse de calcul et économiser des ressources, ce qui est crucial pour améliorer les performances globales d’un système informatique. Une compréhension approfondie du principe de fonctionnement et de la méthode d'optimisation de GEMM nous aidera à mieux utiliser le potentiel du matériel informatique moderne et à fournir des solutions plus efficaces pour diverses tâches informatiques complexes. En optimisant les performances de GEMM
 Le système de conduite intelligent Qiankun ADS3.0 de Huawei sera lancé en août et sera lancé pour la première fois sur Xiangjie S9
Jul 30, 2024 pm 02:17 PM
Le système de conduite intelligent Qiankun ADS3.0 de Huawei sera lancé en août et sera lancé pour la première fois sur Xiangjie S9
Jul 30, 2024 pm 02:17 PM
Le 29 juillet, lors de la cérémonie de lancement de la 400 000e nouvelle voiture d'AITO Wenjie, Yu Chengdong, directeur général de Huawei, président de Terminal BG et président de la BU Smart Car Solutions, a assisté et prononcé un discours et a annoncé que les modèles de la série Wenjie seraient sera lancé cette année En août, la version Huawei Qiankun ADS 3.0 a été lancée et il est prévu de pousser successivement les mises à niveau d'août à septembre. Le Xiangjie S9, qui sortira le 6 août, lancera le système de conduite intelligent ADS3.0 de Huawei. Avec l'aide du lidar, la version Huawei Qiankun ADS3.0 améliorera considérablement ses capacités de conduite intelligente, disposera de capacités intégrées de bout en bout et adoptera une nouvelle architecture de bout en bout de GOD (identification générale des obstacles)/PDP (prédictive prise de décision et contrôle), fournissant la fonction NCA de conduite intelligente d'une place de stationnement à l'autre et mettant à niveau CAS3.0
 Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Hier, lors de l'entretien, on m'a demandé si j'avais posé des questions à longue traîne, j'ai donc pensé faire un bref résumé. Le problème à longue traîne de la conduite autonome fait référence aux cas extrêmes dans les véhicules autonomes, c'est-à-dire à des scénarios possibles avec une faible probabilité d'occurrence. Le problème perçu de la longue traîne est l’une des principales raisons limitant actuellement le domaine de conception opérationnelle des véhicules autonomes intelligents à véhicule unique. L'architecture sous-jacente et la plupart des problèmes techniques de la conduite autonome ont été résolus, et les 5 % restants des problèmes à longue traîne sont progressivement devenus la clé pour restreindre le développement de la conduite autonome. Ces problèmes incluent une variété de scénarios fragmentés, de situations extrêmes et de comportements humains imprévisibles. La « longue traîne » des scénarios limites dans la conduite autonome fait référence aux cas limites dans les véhicules autonomes (VA). Les cas limites sont des scénarios possibles avec une faible probabilité d'occurrence. ces événements rares
 Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
La prédiction de trajectoire joue un rôle important dans la conduite autonome. La prédiction de trajectoire de conduite autonome fait référence à la prédiction de la trajectoire de conduite future du véhicule en analysant diverses données pendant le processus de conduite du véhicule. En tant que module central de la conduite autonome, la qualité de la prédiction de trajectoire est cruciale pour le contrôle de la planification en aval. La tâche de prédiction de trajectoire dispose d'une riche pile technologique et nécessite une connaissance de la perception dynamique/statique de la conduite autonome, des cartes de haute précision, des lignes de voie, des compétences en architecture de réseau neuronal (CNN&GNN&Transformer), etc. Il est très difficile de démarrer ! De nombreux fans espèrent se lancer dans la prédiction de trajectoire le plus tôt possible et éviter les pièges. Aujourd'hui, je vais faire le point sur quelques problèmes courants et des méthodes d'apprentissage introductives pour la prédiction de trajectoire ! Connaissances introductives 1. Existe-t-il un ordre d'entrée pour les épreuves de prévisualisation ? R : Regardez d’abord l’enquête, p
 SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Feb 20, 2024 am 11:48 AM
SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Feb 20, 2024 am 11:48 AM
Titre original : SIMPL : ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Lien article : https://arxiv.org/pdf/2402.02519.pdf Lien code : https://github.com/HKUST-Aerial-Robotics/SIMPL Affiliation de l'auteur : Université des sciences de Hong Kong et technologie Idée DJI Paper : cet article propose une base de référence de prédiction de mouvement (SIMPL) simple et efficace pour les véhicules autonomes. Par rapport au cent agent traditionnel
 NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
Écrit à l'avant et point de départ Le paradigme de bout en bout utilise un cadre unifié pour réaliser plusieurs tâches dans les systèmes de conduite autonome. Malgré la simplicité et la clarté de ce paradigme, les performances des méthodes de conduite autonome de bout en bout sur les sous-tâches sont encore loin derrière les méthodes à tâche unique. Dans le même temps, les fonctionnalités de vue à vol d'oiseau (BEV) denses, largement utilisées dans les méthodes de bout en bout précédentes, rendent difficile l'adaptation à davantage de modalités ou de tâches. Un paradigme de conduite autonome de bout en bout (SparseAD) centré sur la recherche clairsemée est proposé ici, dans lequel la recherche clairsemée représente entièrement l'ensemble du scénario de conduite, y compris l'espace, le temps et les tâches, sans aucune représentation BEV dense. Plus précisément, une architecture clairsemée unifiée est conçue pour la connaissance des tâches, notamment la détection, le suivi et la cartographie en ligne. De plus, lourd
 Quelle version du système Apple 16 est la meilleure ?
Mar 08, 2024 pm 05:16 PM
Quelle version du système Apple 16 est la meilleure ?
Mar 08, 2024 pm 05:16 PM
La meilleure version du système Apple 16 est iOS16.1.4. La meilleure version du système iOS16 peut varier d'une personne à l'autre. Les ajouts et améliorations de l'expérience d'utilisation quotidienne ont également été salués par de nombreux utilisateurs. Quelle version du système Apple 16 est la meilleure ? Réponse : iOS16.1.4 La meilleure version du système iOS 16 peut varier d'une personne à l'autre. Selon les informations publiques, iOS16, lancé en 2022, est considéré comme une version très stable et performante, et les utilisateurs sont plutôt satisfaits de son expérience globale. De plus, l'ajout de nouvelles fonctionnalités et les améliorations de l'expérience d'utilisation quotidienne dans iOS16 ont également été bien accueillies par de nombreux utilisateurs. Surtout en termes de durée de vie de la batterie mise à jour, de performances du signal et de contrôle du chauffage, les retours des utilisateurs ont été relativement positifs. Cependant, compte tenu de l'iPhone14
 Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Au cours du mois dernier, pour des raisons bien connues, j'ai eu des échanges très intensifs avec divers professeurs et camarades de classe du secteur. Un sujet inévitable dans l'échange est naturellement le populaire Tesla FSDV12 de bout en bout. Je voudrais profiter de cette occasion pour trier certaines de mes pensées et opinions en ce moment pour votre référence et votre discussion. Comment définir un système de conduite autonome de bout en bout et quels problèmes devraient être résolus de bout en bout ? Selon la définition la plus traditionnelle, un système de bout en bout fait référence à un système qui saisit les informations brutes des capteurs et génère directement les variables pertinentes pour la tâche. Par exemple, en reconnaissance d'images, CNN peut être appelé de bout en bout par rapport à la méthode traditionnelle d'extraction de caractéristiques + classificateur. Dans les tâches de conduite autonome, saisir les données de divers capteurs (caméra/LiDAR
