

Cette semaine, la Conférence internationale sur la vision par ordinateur (ICCV) s'est ouverte à Paris, en France.

En tant que conférence universitaire la plus importante au monde dans le domaine de la vision par ordinateur, l'ICCV se tient tous les deux ans.
Comme CVPR, la popularité d’ICCV a atteint de nouveaux sommets.
Lors de la cérémonie d'ouverture d'aujourd'hui, l'ICCV a officiellement annoncé les données papier de cette année : le nombre total de soumissions à cet ICCV a atteint 8068, dont 2160 ont été acceptées, avec un taux d'acceptation de 26,8%, légèrement supérieur à celui du précédent ICCV 2021. le taux d'acceptation est de 25,9%
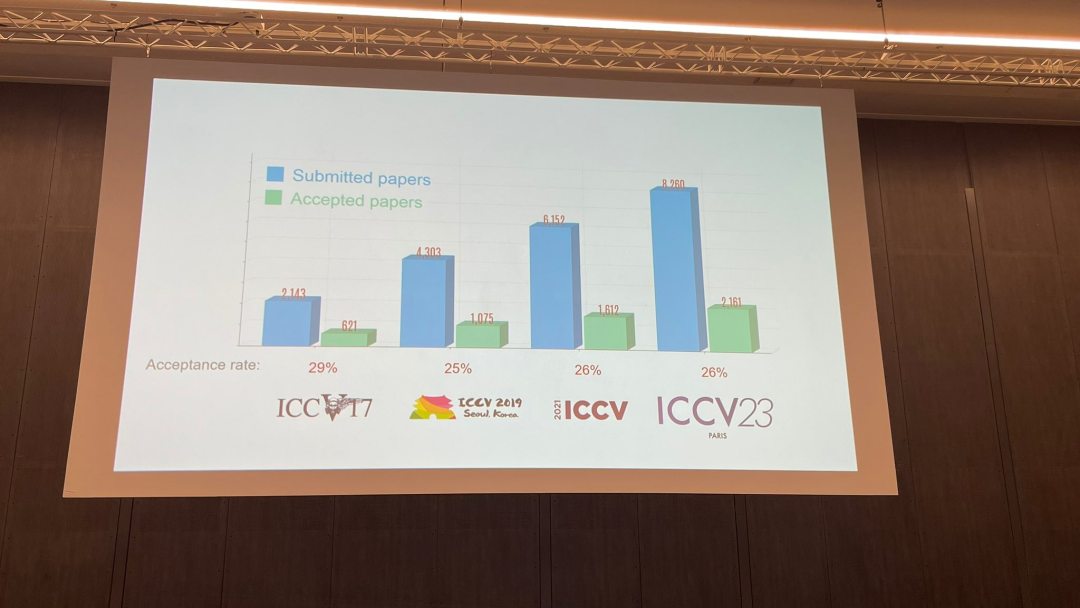
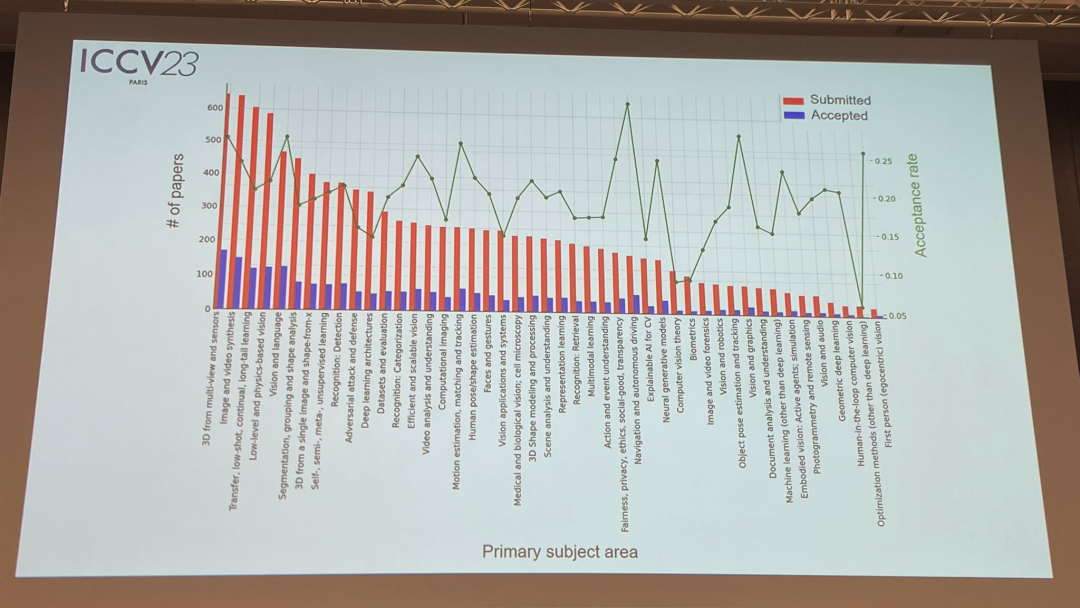
Concernant le sujet du papier, le responsable a également publié des données pertinentes : la technologie 3D avec plusieurs perspectives et capteurs est la plus populaire
Dans la cérémonie d'ouverture d'aujourd'hui, la plus importante partie Il s'agit d'annoncer les informations gagnantes. Maintenant, révélons un par un le meilleur article, la meilleure nomination d'article et le meilleur article étudiant
Au total, deux articles ont remporté le meilleur article de cette année (Prix Marr).
Le premier article provient d'un chercheur de l'Université de Toronto.

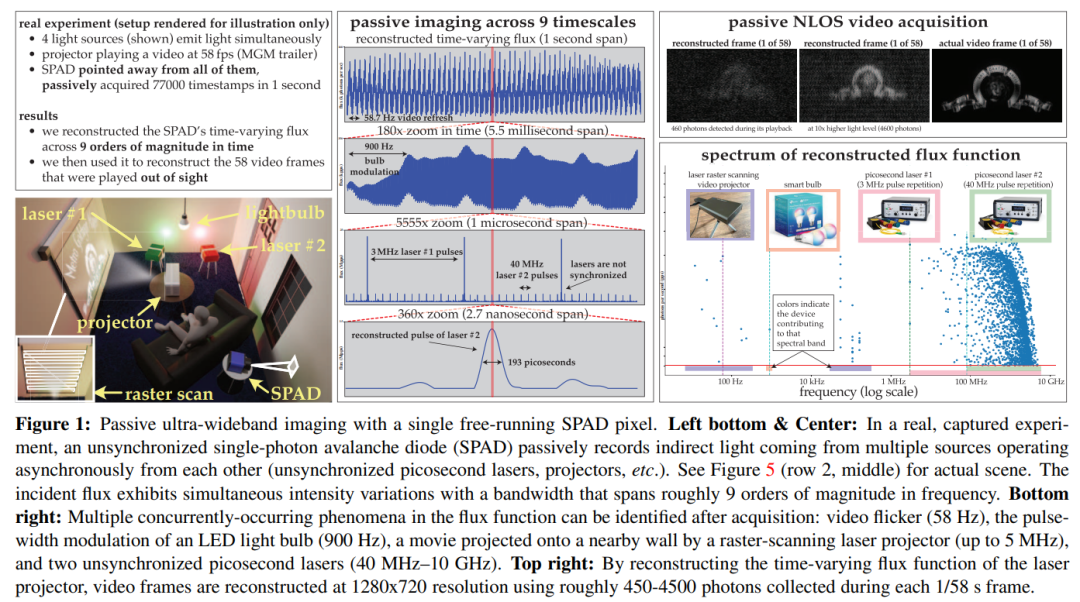
Résumé : Cet article considère le problème de l'imagerie simultanée de scènes dynamiques à des échelles de temps extrêmes (de quelques secondes à picosecondes) et est imagé passivement, sans beaucoup de lumière ni aucun signal de synchronisation provenant de la source lumineuse qui l'émet. Étant donné que les techniques d'estimation de flux existantes pour les caméras à photon unique échouent dans ce cas, nous développons une théorie de détection de flux qui tire des enseignements du calcul stochastique pour permettre le flux variable dans le temps des pixels reconstruits dans un flux d'horodatages de détection de photons.
Cet article utilise cette théorie pour montrer que les caméras SPAD passives à fonctionnement libre ont une bande passante de fréquence réalisable dans des conditions de faible flux qui peut couvrir toute la plage DC jusqu'à 31 GHz. Dans le même temps, cet article dérive également un nouvel algorithme de reconstruction de flux dans le domaine de Fourier et garantit que le modèle de bruit de cet algorithme est toujours efficace à un nombre de photons très faible ou à un temps mort non négligeable
démontré par des expériences. Le mécanisme d'imagerie asynchrone est : (1) l'imagerie de scènes éclairées simultanément par des sources de lumière (telles que des ampoules, des projecteurs, des lasers à impulsions multiples) fonctionnant à des vitesses différentes, sans avoir besoin de synchronisation (2) l'obtention d'une non-ligne de transmission passive ; Acquisition vidéo à vue ; (3) Enregistrez une vidéo ultra-large bande et lisez-la plus tard à 30 Hz pour montrer le mouvement quotidien, ou lisez-la un milliard de fois plus lentement pour montrer la propagation de la lumière elle-même
Partie 2 c'est ce que nous connaissons sous le nom de ControNet.

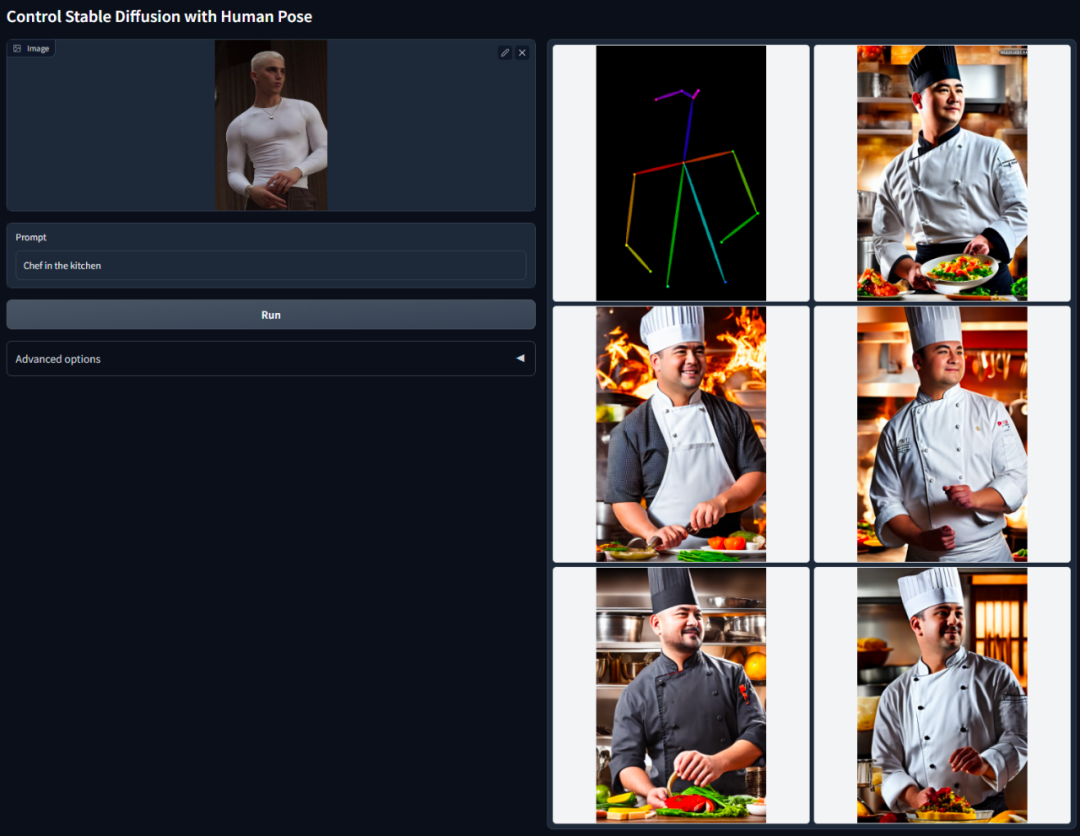
Résumé : Cette étude propose une architecture de réseau neuronal de bout en bout appelée ControlNet. Cette architecture améliore la génération d'images en ajoutant des conditions supplémentaires pour contrôler le modèle de diffusion (telles qu'une diffusion stable). Dans le même temps, ControlNet peut générer des images en couleur à partir de dessins au trait, générer des images avec la même structure de profondeur et optimiser les effets de génération de main grâce aux points clés de la main, etc.
L'idée principale de ControlNet est d'ajouter des conditions supplémentaires à la description du texte pour contrôler le modèle de diffusion (comme la diffusion stable), contrôlant ainsi mieux la pose du personnage, la profondeur, la structure de l'image et d'autres informations de l'image générée.
Les conditions supplémentaires ici sont saisies sous la forme d'une image. Le modèle peut effectuer une détection des bords Canny, une détection de profondeur, une segmentation sémantique, une détection de ligne de transformation de Hough, une détection globale des bords imbriqués (HED) et une posture humaine basée sur cela. image d'entrée, reconnaissance, etc., puis conserver ces informations dans l'image générée. En utilisant ce modèle, nous pouvons convertir directement des dessins au trait ou des graffitis en images en couleur, générer des images avec la même structure de profondeur, etc., et optimiser la génération de mains de personnages grâce aux points clés des mains.
Veuillez vous référer au rapport "La réduction de la dimensionnalité de l'IA frappe les peintres humains, les graphiques vincentiens sont introduits dans ControlNet et les informations de profondeur et de bord sont entièrement réutilisées" par Heart of the Machine pour une introduction plus détaillée
En avril de cette année, Meta a publié un modèle d'intelligence artificielle appelé "Segment Everything (SAM)", qui peut générer des masques pour les objets dans n'importe quelle image ou vidéo. Cela a fait des chercheurs dans le domaine de l'informatique. vision J'ai été très choqué, certains ont même dit "La vision par ordinateur n'existe plus"
Maintenant, cet article très attendu a été nominé pour le meilleur article.

Contenu réécrit : Avant de résoudre le problème de segmentation, il existe généralement deux méthodes. La première est la segmentation interactive, qui peut être utilisée pour segmenter n’importe quelle classe d’objets mais nécessite qu’un humain guide la méthode en affinant le masque de manière itérative. La seconde est la segmentation automatique, qui peut être utilisée pour segmenter des catégories d'objets spécifiques prédéfinies (comme des chats ou des chaises), mais nécessite un grand nombre d'objets annotés manuellement pour l'entraînement (comme des milliers, voire des dizaines de milliers d'exemples de chats segmentés). . Cependant, aucune de ces deux méthodes ne propose une méthode de segmentation universelle et entièrement automatique
Le SAM proposé par Meta résume bien ces deux méthodes. Il s'agit d'un modèle unique qui peut facilement effectuer une segmentation interactive et une segmentation automatique. L'interface d'invite du modèle permet aux utilisateurs de l'utiliser de manière flexible, en concevant simplement les bonnes invites pour le modèle (clics, sélections de zones, texte, etc.), un large éventail de tâches de segmentation peut être accompli
Pour résumer , ces fonctionnalités permettent à SAM de s'adapter à de nouvelles tâches et domaines. Cette flexibilité est unique dans le domaine de la segmentation d'images
Pour plus de détails, veuillez vous référer au rapport Machine Heart : "CV Doesn't Exist?" Meta publie un modèle d'IA « tout diviser », le CV pourrait inaugurer le moment GPT-3》
Cette recherche a été réalisée conjointement par des chercheurs de l'Université Cornell, Google Research et UC Berkeley, le premier auteur est Qianqian Wang, doctorant à Cornell Tech. Ils ont proposé conjointement OmniMotion, une représentation de mouvement complète et globalement cohérente, et ont proposé une nouvelle méthode d'optimisation du temps de test pour effectuer une estimation précise et complète du mouvement pour chaque pixel de la vidéo.

Résumé : Dans le domaine de vision par ordinateur, il existe deux méthodes d'estimation de mouvement couramment utilisées : le suivi des caractéristiques clairsemées et le flux optique dense. Cependant, les deux méthodes ont leurs propres inconvénients. Le suivi de caractéristiques éparses ne peut pas modéliser le mouvement de tous les pixels ; un flux optique dense ne peut pas capturer les trajectoires de mouvement pendant une longue période.
L'OmniMotion proposé dans cette recherche utilise un volume canonique quasi-3D pour représenter la vidéo et suit chaque pixel à travers une bijection entre espace local et espace canonique. Cette représentation permet une cohérence globale, permet le suivi de mouvement même lorsque les objets sont masqués et modélise toute combinaison de mouvement de caméra et d'objet. Cette étude démontre expérimentalement que la méthode proposée surpasse considérablement les méthodes SOTA existantes.
Veuillez vous référer au rapport Heart of Machine "L'algorithme vidéo "tracking everything" qui suit chaque pixel à tout moment, n'importe où, et n'a pas peur de l'occlusion est ici" pour une introduction plus détaillée
En plus de ces récompenses- articles gagnants, l'ICCV de cette année également. Il existe de nombreux autres excellents articles dignes de votre attention. Vous trouverez ci-dessous la liste initiale des 17 articles gagnants

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Explication détaillée du fichier de configuration du quartz
Explication détaillée du fichier de configuration du quartz
 Comment obtenir des données en HTML
Comment obtenir des données en HTML
 site officiel d'okex
site officiel d'okex
 Comment utiliser la lecture aléatoire
Comment utiliser la lecture aléatoire
 Comment utiliser la fonction countif
Comment utiliser la fonction countif
 Comment résoudre javascriptvoid(o)
Comment résoudre javascriptvoid(o)
 description de la page de référencement
description de la page de référencement
 Comment utiliser la largeur de marge
Comment utiliser la largeur de marge








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



