

LeCun profondément déçu par la fraude des licornes autonomes

Pensez-vous qu'il s'agit d'une vidéo de conduite autonome ordinaire ?
 Images
Images
Ce contenu doit être réécrit en chinois sans changer le sens original
Aucune seule image n'est "réelle".
 Photos
Photos
Différentes conditions routières, diverses conditions météorologiques et plus de 20 situations peuvent être simulées, et l'effet est comme la réalité.
 Photos
Photos
Le modèle mondial a encore fait un excellent travail ! LeCun a retweeté cela avec enthousiasme après l'avoir vu.
 Photos
Photos
Selon les effets ci-dessus, ceci est apporté par la dernière version de GAIA-1
L'ampleur de ce projet a atteint 9 milliards de paramètres Grâce à 4700 heures de formation vidéo de conduite, il a réussi. la vidéo d'entrée, l'avantage le plus direct de la génération de vidéos de conduite autonome à partir de texte ou d'opérations est qu'elle peut mieux prédire les événements futurs et que plus de 20 scénarios peuvent être simulés, améliorant ainsi encore la sécurité de la conduite autonome et réduisant les coûts.
Photos Notre équipe créative a déclaré sans détour que cela changerait complètement les règles du jeu de la conduite autonome !
Notre équipe créative a déclaré sans détour que cela changerait complètement les règles du jeu de la conduite autonome !
Alors, comment GAIA-1 est-il implémenté ?
Plus l'échelle est grande, mieux c'est
GAIA-1 est un modèle mondial génératif avec plusieurs modes
En exploitant la vidéo, le texte et les actions comme entrées, le système peut générer des vidéos de scènes de conduite réalistes et contrôler de manière autonome un contrôle précis du véhicule. caractéristiques du comportement et de la scène
Les vidéos peuvent être générées en utilisant uniquement des invites textuelles
Images  Son principe de modèle est similaire aux grands modèles de langage, c'est-à-dire en prédisant le prochain jeton
Son principe de modèle est similaire aux grands modèles de langage, c'est-à-dire en prédisant le prochain jeton
Le modèle peut utiliser une représentation par quantification vectorielle Discrétisation les images vidéo, puis la prédiction des scènes futures est convertie en prédiction du prochain jeton de la séquence. Le modèle de diffusion est ensuite utilisé pour générer des vidéos de haute qualité à partir de l’espace linguistique du modèle mondial.
Les étapes spécifiques sont les suivantes :
Images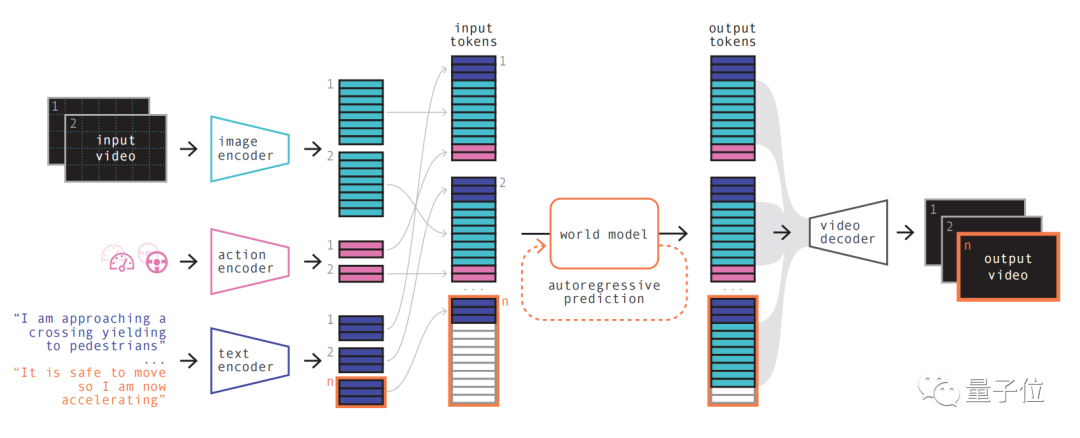 La première étape est simple à comprendre, qui consiste à recoder, organiser et combiner diverses entrées.
La première étape est simple à comprendre, qui consiste à recoder, organiser et combiner diverses entrées.
En utilisant des encodeurs spécialisés pour encoder diverses entrées et projeter différentes entrées dans une représentation partagée. Les encodeurs texte et vidéo séparent et intègrent les entrées, tandis que les représentations opérationnelles sont projetées individuellement dans une représentation partagée
Ces représentations codées sont temporellement cohérentes.
Après l'arrangement, l'élément clé du modèle mondial apparaît.
En tant que transformateur autorégressif, il peut prédire le prochain ensemble de jetons d'image dans la séquence. Et il prend non seulement en compte le jeton d'image précédent, mais prend également en compte les informations contextuelles du texte et de l'opération.
Le contenu généré par le modèle maintient non seulement la cohérence de l'image, mais est également cohérent avec le texte et les actions prédits.
L'équipe a introduit que la taille du modèle mondial dans GAIA-1 est de 6,5 milliards de paramètres et a été formée sur cela. 64 A100 pendant 15 jours.
Enfin, utilisez le modèle de décodeur vidéo et de diffusion vidéo pour reconvertir ces jetons en vidéos.
L'importance de cette étape est de garantir la qualité sémantique, la précision de l'image et la cohérence temporelle de la vidéo
Le décodeur vidéo de GAIA-1 a une échelle de 2,6 milliards de paramètres et a été entraîné pendant 15 jours à l'aide de 32 A100.
Il convient de mentionner que GAIA-1 est non seulement similaire au principe des modèles de langage à grande échelle, mais montre également les caractéristiques d'une qualité de génération améliorée à mesure que l'échelle du modèle s'étend
Photos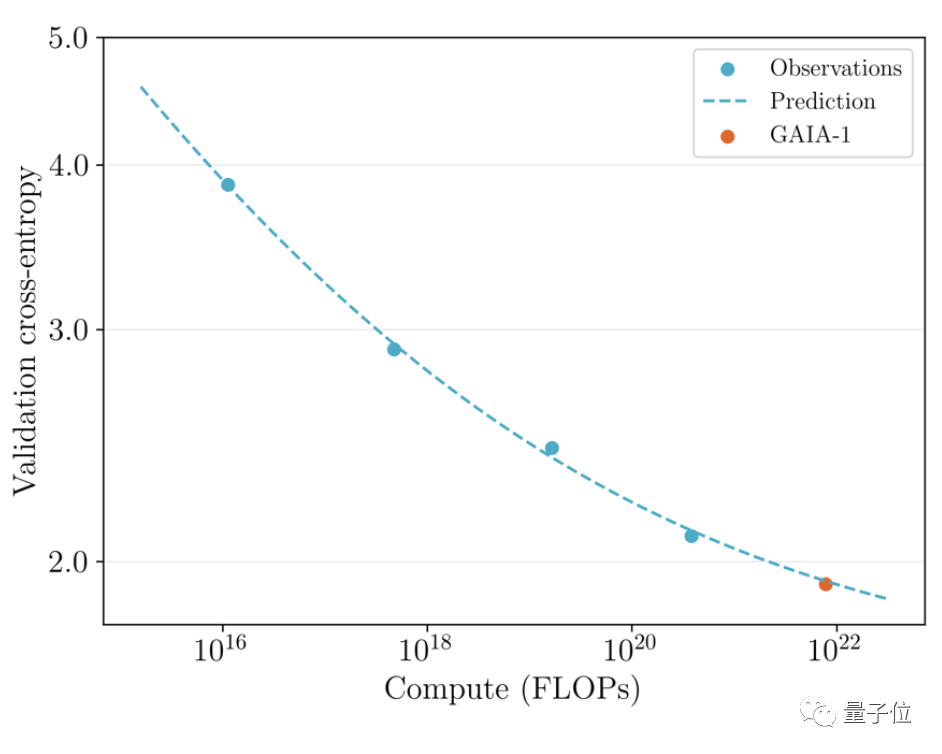 L'équipe a examiné le précédemment publié en juin La première version et le dernier effet ont été comparés
L'équipe a examiné le précédemment publié en juin La première version et le dernier effet ont été comparés
Ce dernier est 480 fois plus grand que le premier.
Vous pouvez intuitivement voir que les détails et la résolution de la vidéo ont été considérablement améliorés.
Photos Du point de vue de l'application pratique, l'émergence de GAIA-1 a également eu un certain impact. Son équipe créative a déclaré que cela changerait les règles de la conduite autonome
Du point de vue de l'application pratique, l'émergence de GAIA-1 a également eu un certain impact. Son équipe créative a déclaré que cela changerait les règles de la conduite autonome
 Photos
Photos
Les raisons peuvent être expliquées sous trois aspects :
- Sécurité
- Données de formation complètes
- Scénario longue traîne
Tout d'abord, en termes de sécurité, le modèle mondial peut simuler l'avenir, donner à l'IA la capacité de prendre vos propres décisions, ce qui est essentiel à la sécurité de la conduite autonome.
Deuxièmement, les données d'entraînement sont également très importantes pour la conduite autonome. Les données générées sont plus sécurisées, plus rentables et infiniment évolutives.
L'IA générative peut résoudre l'un des défis des scénarios à longue traîne auxquels est confrontée la conduite autonome. Il peut gérer davantage de scénarios extrêmes, comme rencontrer des piétons traversant la route par temps de brouillard. Cela améliorera encore les capacités de conduite autonome
Qui est Wayve ?
GAIA-1 a été développé par la startup britannique de conduite autonome Wayve
Wayve a été fondée en 2017. Parmi les investisseurs figurent Microsoft et d'autres, et sa valorisation a atteint la licorne.
Les fondateurs sont Alex Kendall et Amar Shah, tous deux titulaires d'un doctorat en machine learning de l'université de Cambridge
 Photos
Photos
Sur le plan technique, comme Tesla, Wayve prône l'utilisation de caméras. Solution purement visuelle, il ont abandonné très tôt les cartes de haute précision et ont suivi résolument la voie de la « perception en temps réel ».
Il n'y a pas si longtemps, un autre grand modèle LINGO-1 publié par l'équipe a également attiré l'attention
Ce modèle de conduite autonome peut générer des explications en temps réel pendant la conduite, améliorant ainsi encore l'interprétabilité du modèle
En mars de cette année, Bill Gates a également fait un essai routier avec la voiture autonome de Wayve.
 Photos
Photos
Adresse papier : https://www.php.cn/link/1f8c4b6a0115a4617e285b4494126fbf
Lien de référence :
[1]https://www.php.cn/link/8 5dca1d 270f7f9aef00c9d372f114482 [2]https://www.php.cn/link/a4c22565dfafb162a17a7c357ca9e0be
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Hier, lors de l'entretien, on m'a demandé si j'avais posé des questions à longue traîne, j'ai donc pensé faire un bref résumé. Le problème à longue traîne de la conduite autonome fait référence aux cas extrêmes dans les véhicules autonomes, c'est-à-dire à des scénarios possibles avec une faible probabilité d'occurrence. Le problème perçu de la longue traîne est l’une des principales raisons limitant actuellement le domaine de conception opérationnelle des véhicules autonomes intelligents à véhicule unique. L'architecture sous-jacente et la plupart des problèmes techniques de la conduite autonome ont été résolus, et les 5 % restants des problèmes à longue traîne sont progressivement devenus la clé pour restreindre le développement de la conduite autonome. Ces problèmes incluent une variété de scénarios fragmentés, de situations extrêmes et de comportements humains imprévisibles. La « longue traîne » des scénarios limites dans la conduite autonome fait référence aux cas limites dans les véhicules autonomes (VA). Les cas limites sont des scénarios possibles avec une faible probabilité d'occurrence. ces événements rares
 Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Écrit précédemment, nous discutons aujourd'hui de la manière dont la technologie d'apprentissage profond peut améliorer les performances du SLAM (localisation et cartographie simultanées) basé sur la vision dans des environnements complexes. En combinant des méthodes d'extraction de caractéristiques approfondies et de correspondance de profondeur, nous introduisons ici un système SLAM visuel hybride polyvalent conçu pour améliorer l'adaptation dans des scénarios difficiles tels que des conditions de faible luminosité, un éclairage dynamique, des zones faiblement texturées et une gigue importante. Notre système prend en charge plusieurs modes, notamment les configurations étendues monoculaire, stéréo, monoculaire-inertielle et stéréo-inertielle. En outre, il analyse également comment combiner le SLAM visuel avec des méthodes d’apprentissage profond pour inspirer d’autres recherches. Grâce à des expériences approfondies sur des ensembles de données publiques et des données auto-échantillonnées, nous démontrons la supériorité du SL-SLAM en termes de précision de positionnement et de robustesse du suivi.
 NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
Écrit à l'avant et point de départ Le paradigme de bout en bout utilise un cadre unifié pour réaliser plusieurs tâches dans les systèmes de conduite autonome. Malgré la simplicité et la clarté de ce paradigme, les performances des méthodes de conduite autonome de bout en bout sur les sous-tâches sont encore loin derrière les méthodes à tâche unique. Dans le même temps, les fonctionnalités de vue à vol d'oiseau (BEV) denses, largement utilisées dans les méthodes de bout en bout précédentes, rendent difficile l'adaptation à davantage de modalités ou de tâches. Un paradigme de conduite autonome de bout en bout (SparseAD) centré sur la recherche clairsemée est proposé ici, dans lequel la recherche clairsemée représente entièrement l'ensemble du scénario de conduite, y compris l'espace, le temps et les tâches, sans aucune représentation BEV dense. Plus précisément, une architecture clairsemée unifiée est conçue pour la connaissance des tâches, notamment la détection, le suivi et la cartographie en ligne. De plus, lourd
 Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Au cours du mois dernier, pour des raisons bien connues, j'ai eu des échanges très intensifs avec divers professeurs et camarades de classe du secteur. Un sujet inévitable dans l'échange est naturellement le populaire Tesla FSDV12 de bout en bout. Je voudrais profiter de cette occasion pour trier certaines de mes pensées et opinions en ce moment pour votre référence et votre discussion. Comment définir un système de conduite autonome de bout en bout et quels problèmes devraient être résolus de bout en bout ? Selon la définition la plus traditionnelle, un système de bout en bout fait référence à un système qui saisit les informations brutes des capteurs et génère directement les variables pertinentes pour la tâche. Par exemple, en reconnaissance d'images, CNN peut être appelé de bout en bout par rapport à la méthode traditionnelle d'extraction de caractéristiques + classificateur. Dans les tâches de conduite autonome, saisir les données de divers capteurs (caméra/LiDAR
 FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
La détection de cibles est un problème relativement mature dans les systèmes de conduite autonome, parmi lesquels la détection des piétons est l'un des premiers algorithmes à être déployés. Des recherches très complètes ont été menées dans la plupart des articles. Cependant, la perception de la distance à l’aide de caméras fisheye pour une vue panoramique est relativement moins étudiée. En raison de la distorsion radiale importante, la représentation standard du cadre de délimitation est difficile à mettre en œuvre dans les caméras fisheye. Pour alléger la description ci-dessus, nous explorons les conceptions étendues de boîtes englobantes, d'ellipses et de polygones généraux dans des représentations polaires/angulaires et définissons une métrique de segmentation d'instance mIOU pour analyser ces représentations. Le modèle fisheyeDetNet proposé avec une forme polygonale surpasse les autres modèles et atteint simultanément 49,5 % de mAP sur l'ensemble de données de la caméra fisheye Valeo pour la conduite autonome.
 Musk : débuts du supercalcul Tesla Dojo : la puissance de calcul de l'IA de formation d'ici la fin de l'année sera approximativement égale à 8 000 GPU NVIDIA H100
Jul 24, 2024 am 10:38 AM
Musk : débuts du supercalcul Tesla Dojo : la puissance de calcul de l'IA de formation d'ici la fin de l'année sera approximativement égale à 8 000 GPU NVIDIA H100
Jul 24, 2024 am 10:38 AM
Selon les informations de ce site du 24 juillet, le PDG de Tesla, Elon Musk, a déclaré aujourd'hui lors d'une conférence téléphonique sur les résultats que la société était sur le point d'achever le plus grand cluster de formation en intelligence artificielle à ce jour, qui sera équipé de 2 000 GPU NVIDIA H100. Musk a également déclaré aux investisseurs lors de la conférence téléphonique sur les résultats de la société que Tesla travaillerait au développement de son supercalculateur Dojo, car les GPU de Nvidia sont chers. Ce site traduit une partie du discours de Musk comme suit : Le chemin pour rivaliser avec NVIDIA via Dojo est difficile, mais je pense que nous n'avons pas le choix. Nous dépendons désormais trop de NVIDIA. Du point de vue de NVIDIA, ils augmenteront inévitablement le prix des GPU à un niveau que le marché peut supporter, mais
 Tesla passe enfin à l'action ! Les taxis autonomes seront-ils bientôt dévoilés ? !
Apr 08, 2024 pm 05:49 PM
Tesla passe enfin à l'action ! Les taxis autonomes seront-ils bientôt dévoilés ? !
Apr 08, 2024 pm 05:49 PM
Selon les informations du 8 avril, le PDG de Tesla, Elon Musk, a récemment révélé que Tesla s'était engagé à développer pleinement la technologie des voitures autonomes. Le très attendu taxi autonome sans pilote Robotaxi sera lancé le 8 août. L'éditeur de données a appris que la déclaration de Musk sur Auparavant, Reuters avait rapporté que le projet de Tesla de conduire des voitures se concentrerait sur la production de Robotaxi. Cependant, Musk a réfuté cette affirmation, accusant Reuters d'avoir annulé les projets de développement de voitures à bas prix et de publier à nouveau de faux rapports, tout en précisant que les voitures à bas prix Model 2 et Robotax
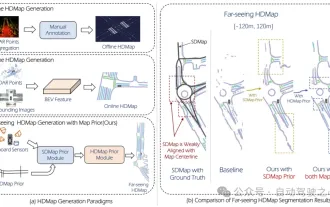 Tueur de production de masse ! P-Mapnet : En utilisant la carte de basse précision SDMap précédente, les performances de cartographie sont violemment améliorées de près de 20 points !
Mar 28, 2024 pm 02:36 PM
Tueur de production de masse ! P-Mapnet : En utilisant la carte de basse précision SDMap précédente, les performances de cartographie sont violemment améliorées de près de 20 points !
Mar 28, 2024 pm 02:36 PM
Comme indiqué ci-dessus, l'un des algorithmes utilisés par les systèmes de conduite autonome actuels pour se débarrasser de la dépendance aux cartes de haute précision consiste à tirer parti du fait que les performances de perception sur de longues distances sont encore médiocres. À cette fin, nous proposons P-MapNet, où le « P » se concentre sur la fusion des cartes a priori pour améliorer les performances du modèle. Plus précisément, nous exploitons les informations préalables dans SDMap et HDMap : d'une part, nous extrayons les données SDMap faiblement alignées d'OpenStreetMap et les encodons en termes indépendants pour prendre en charge l'entrée. Il existe un problème de faible alignement entre l'entrée strictement modifiée et la carte HD+ réelle. Notre structure basée sur le mécanisme d'attention croisée peut se concentrer de manière adaptative sur le squelette SDMap et apporter des améliorations significatives des performances ;
