
 Périphériques technologiques
IA
Lorsque vous soumettez votre article à Nature, renseignez-vous d'abord sur GPT-4 ! Stanford a en fait testé 5 000 articles, et la moitié des opinions étaient les mêmes que celles des évaluateurs humains.
Périphériques technologiques
IA
Lorsque vous soumettez votre article à Nature, renseignez-vous d'abord sur GPT-4 ! Stanford a en fait testé 5 000 articles, et la moitié des opinions étaient les mêmes que celles des évaluateurs humains.
Lorsque vous soumettez votre article à Nature, renseignez-vous d'abord sur GPT-4 ! Stanford a en fait testé 5 000 articles, et la moitié des opinions étaient les mêmes que celles des évaluateurs humains.

GPT-4 est-il capable de révision papier ?
Des chercheurs de Stanford et d’autres universités l’ont testé.
Ils ont donné à GPT-4 des milliers d'articles provenant de grandes conférences telles que Nature et ICLR, l'ont laissé générer des avis de révision (y compris des suggestions de modifications, etc.) , puis les ont comparés aux opinions données par les humains.
Après enquête, nous avons constaté que :
Plus de 50 % des avis proposés par GPT-4 sont cohérents avec au moins un évaluateur humain
Et plus de 82,4 % des auteurs ont constaté que ; les avis fournis par GPT-4 Très utiles
Quelles informations cette recherche peut-elle nous apporter ?
La conclusion est la suivante :
Il n'y a toujours pas de substitut à un retour humain de haute qualité ; mais GPT-4 peut aider les auteurs à améliorer leurs premières ébauches avant un examen formel par les pairs.

pipeline automatique utilisant GPT-4.
Il peut analyser l'intégralité de l'article au format PDF, extraire des titres, des résumés, des figures, des titres de tableaux et d'autres contenus pour créer des invites, puis laisser GPT-4 fournir des commentaires de révision. Parmi eux, les avis sont les mêmes que les standards de chaque grande conférence, et comprennent quatre parties : L'importance et la nouveauté de la recherche, ainsi que les raisons d'une éventuelle acceptation ou rejet et des suggestions d'amélioration 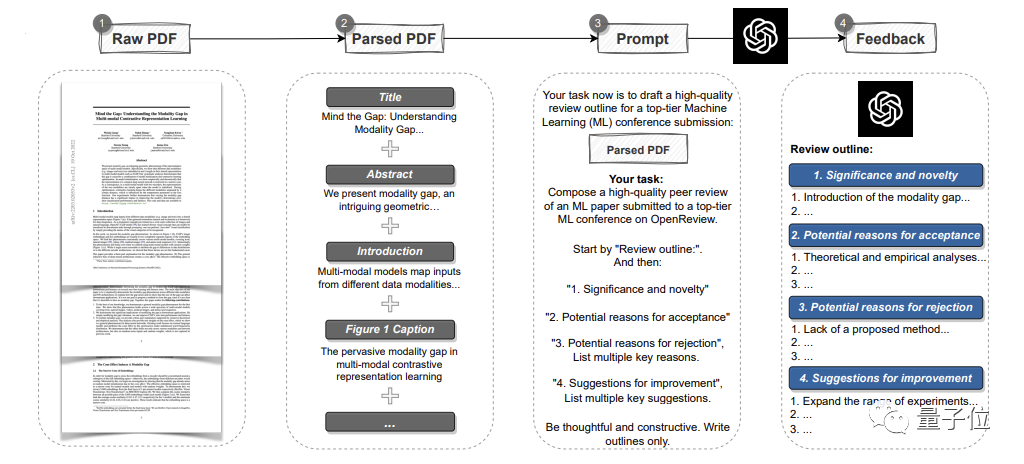
Deux aspects se dévoilent.
La première est l'expérience quantitative :
Lisez les articles existants, générez des commentaires et comparez systématiquement avec de vraies opinions humaines pour découvrir le chevauchementIci, l'équipe a collecté des données du journal principal Nature et des sous-titres majeurs. -journaux 3096 articles ont été sélectionnés, 1709 articles ont été sélectionnés lors de la conférence ICLR Machine Learning(y compris l'année dernière et cette année) , pour un total de 4805 articles.
Parmi eux, les articles Nature impliquaient un total de 8 745 commentaires d'examen humain ; les conférences ICLR impliquaient 6 506 commentaires.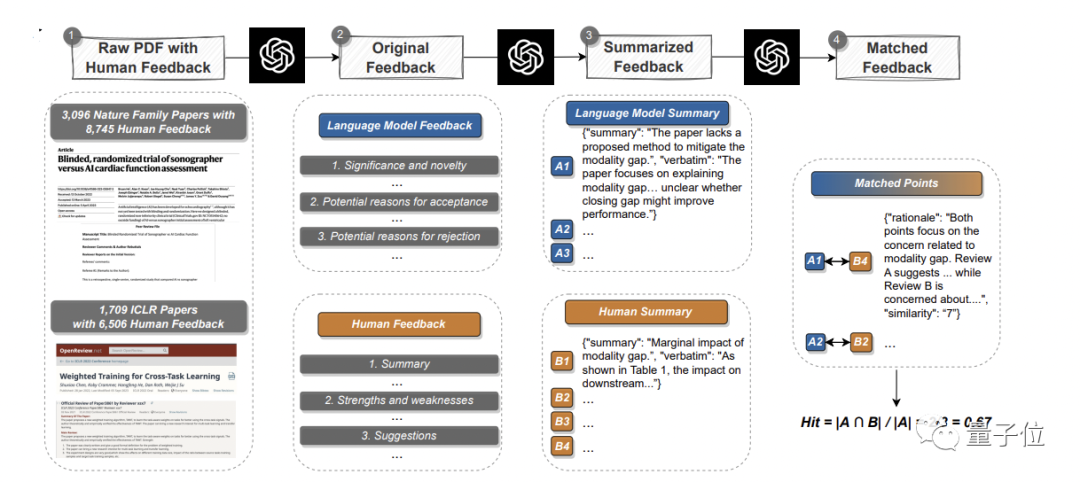
1. Les opinions GPT-4 recoupent de manière significative les opinions réelles des évaluateurs humains
Dans l'ensemble, dans les articles Nature, 57,55 % des opinions GPT-4 sont cohérentes avec au moins un évaluateur humain ; ICLR, ce chiffre atteint 77,18 %.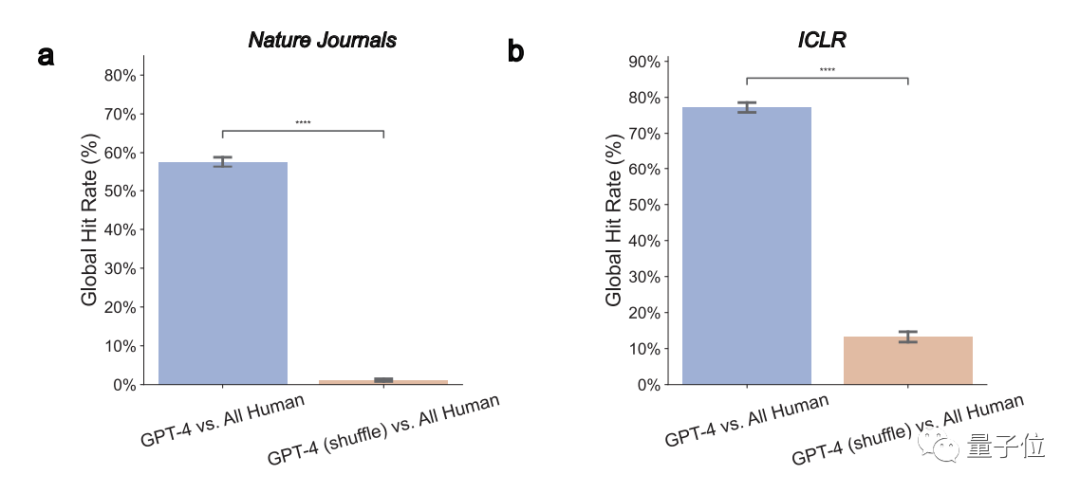
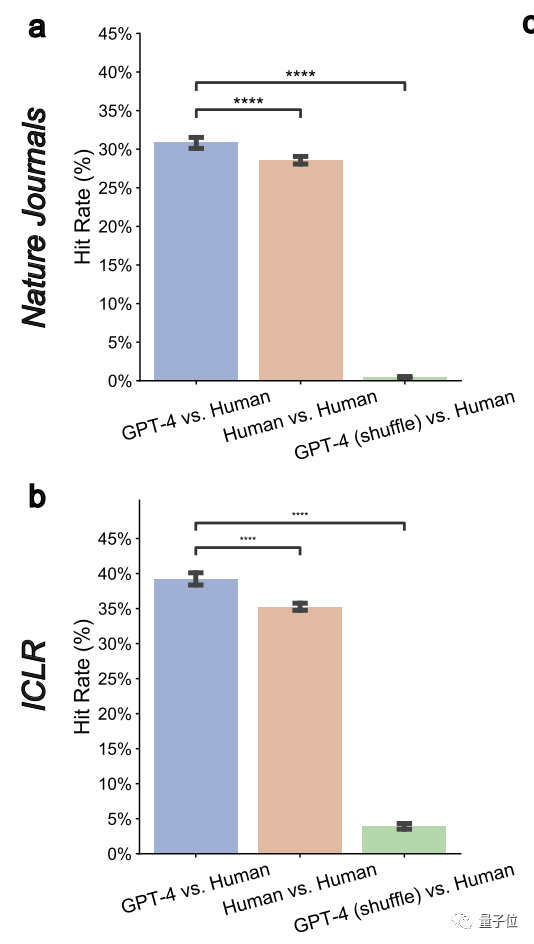
Pour les articles avec des notes plus faibles, le taux de chevauchement entre GPT-4 et les évaluateurs humains devrait augmenter. De plus de 30 % actuellement, il peut être augmenté à près de 50 %
Cela montre que GPT-4 a une grande capacité de discrimination et peut identifier les articles de mauvaise qualitéL'auteur a également déclaré que ceux qui nécessitent des modifications plus substantielles peuvent Heureusement pour les articles acceptés, tout le monde peut essayer les suggestions de révision données par GPT-4 avant de les soumettre officiellement.2. GPT-4 peut fournir des commentaires non universels
Les commentaires dits non universels signifient que GPT-4 ne donnera pas d'avis d'évaluation universel qui s'applique à plusieurs articles.
Ici, les auteurs ont mesuré une métrique de « taux de chevauchement par paire » et ont constaté qu'elle était significativement réduite à 0,43 % et 3,91 % à la fois sur Nature et ICLR. Cela montre que GPT-4 a des objectifs spécifiques3 Il peut parvenir à un accord avec les opinions humaines sur des questions majeures et universelles
.
De manière générale, les commentaires qui apparaissent les plus tôt et sont mentionnés par plusieurs évaluateurs représentent souvent des problèmes importants et courants
Ici, l'équipe a également constaté que LLM est plus susceptible d'identifier les problèmes communs qui sont unanimement reconnus par plusieurs évaluateurs. Problèmes ou défauts
.GPT-4 fonctionne globalement bien
4. Les avis donnés par GPT-4 mettent l'accent sur certains aspects qui sont différents de ceux des humains
L'étude a révélé que la fréquence des commentaires de GPT-4 sur le sens de la recherche elle-même est humaine. 7,27 fois plus susceptibles que les humains de commenter la nouveauté de la recherche.
GPT-4 et les humains recommandent souvent des expériences supplémentaires, mais les humains se concentrent davantage sur les expériences d'ablation, et GPT-4 recommande de l'essayer sur davantage d'ensembles de données.
Les auteurs ont déclaré que ces résultats indiquent que GPT-4 et les évaluateurs humains accordent une importance différente à divers aspects et que la coopération entre les deux peut apporter des avantages potentiels.
Au-delà des expériences quantitatives se trouve la recherche sur les utilisateurs.
Au total, 308 chercheurs dans les domaines de l'IA et de la biologie computationnelle de différentes institutions ont participé à cette étude. Ils ont téléchargé leurs articles sur GPT-4 pour examen
L'équipe de recherche a recueilli leurs véritables commentaires sur les commentaires de l'examen GPT-4.
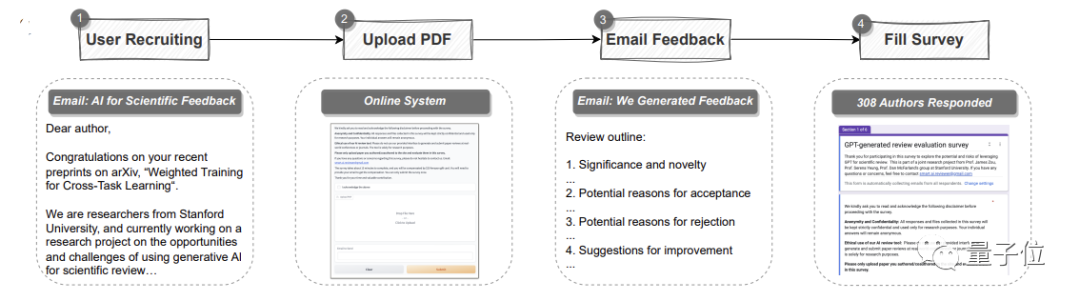
Dans l'ensemble, plus de la moitié (57,4%)des participants ont estimé que les commentaires générés par GPT-4 étaient très utiles, notamment en donnant certains points auxquels les humains ne penseraient pas.
Et 82,4 % des personnes interrogées l'ont trouvé plus bénéfique qu'au moins certains commentaires d'évaluateurs humains.
De plus, plus de la moitié (50,5 %) ont exprimé leur volonté d'utiliser davantage de grands modèles tels que GPT-4 pour améliorer le papier.
L'un d'eux a déclaré qu'il ne fallait que 5 minutes à GPT-4 pour donner les résultats. Ce retour d'information est très rapide et est très utile aux chercheurs pour améliorer leurs articles.
Bien sûr, l'auteur souligne :
Les capacités de GPT-4 ont également certaines limites
La plus évidente est qu'il se concentre davantage sur la « présentation globale » et manque de suggestions approfondies dans des domaines techniques spécifiques ( comme l'architecture modèle) .
Ainsi, comme l'indique la conclusion finale de l'auteur :
Les commentaires de haute qualité des évaluateurs humains sont très importants avant l'examen formel, mais nous pouvons d'abord tâter le terrain pour compenser les détails tels que les expériences et la construction qui peuvent être en cas de problème. omission
Bien sûr, ils rappellent également :
Lors de l'évaluation formelle, les évaluateurs doivent toujours participer de manière indépendante et ne s'appuyer sur aucun LLM.
Tous les auteurs sont chinois
Cette étude Il y a trois auteurs, tous chinois, et tous issus de la School of Computer Science de l'Université de Stanford.

Il s'agit de :
- Liang Weixin, doctorant à l'école et membre du Stanford AI Laboratory (SAIL) . Il est titulaire d'une maîtrise en génie électrique de l'Université de Stanford et d'une licence en informatique de l'Université du Zhejiang.
- Yuhui Zhang, également doctorant, effectue des recherches sur les systèmes d'IA multimodaux. Diplômé d'un baccalauréat de l'Université Tsinghua et d'une maîtrise de Stanford.
- Cao Hancheng est doctorant en cinquième année à l'école, avec une spécialisation en sciences de gestion et en ingénierie. Il a également rejoint les groupes PNL et HCI de l'Université de Stanford. Précédemment diplômé du Département de génie électronique de l'Université Tsinghua avec un baccalauréat.
Lien papier : https://arxiv.org/abs/2310.01783
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Lors de la conversion des chaînes en objets dans vue.js, JSON.Parse () est préféré pour les chaînes JSON standard. Pour les chaînes JSON non standard, la chaîne peut être traitée en utilisant des expressions régulières et réduisez les méthodes en fonction du format ou du codé décodé par URL. Sélectionnez la méthode appropriée en fonction du format de chaîne et faites attention aux problèmes de sécurité et d'encodage pour éviter les bogues.
 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Afin de définir le délai d'expiration de Vue Axios, nous pouvons créer une instance AxiOS et spécifier l'option Timeout: dans les paramètres globaux: vue.prototype. $ Axios = axios.create ({timeout: 5000}); Dans une seule demande: ce. $ axios.get ('/ api / utilisateurs', {timeout: 10000}).
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Vue.js Comment convertir un tableau de type de chaîne en un tableau d'objets?
Apr 07, 2025 pm 09:36 PM
Vue.js Comment convertir un tableau de type de chaîne en un tableau d'objets?
Apr 07, 2025 pm 09:36 PM
Résumé: Il existe les méthodes suivantes pour convertir les tableaux de chaîne Vue.js en tableaux d'objets: Méthode de base: utilisez la fonction de carte pour convenir à des données formatées régulières. Gameplay avancé: l'utilisation d'expressions régulières peut gérer des formats complexes, mais ils doivent être soigneusement écrits et considérés. Optimisation des performances: Considérant la grande quantité de données, des opérations asynchrones ou des bibliothèques efficaces de traitement des données peuvent être utilisées. MEILLEUR PRATIQUE: Effacer le style de code, utilisez des noms de variables significatifs et des commentaires pour garder le code concis.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
L'optimisation des performances MySQL doit commencer à partir de trois aspects: configuration d'installation, indexation et optimisation des requêtes, surveillance et réglage. 1. Après l'installation, vous devez ajuster le fichier my.cnf en fonction de la configuration du serveur, tel que le paramètre innodb_buffer_pool_size, et fermer query_cache_size; 2. Créez un index approprié pour éviter les index excessifs et optimiser les instructions de requête, telles que l'utilisation de la commande Explication pour analyser le plan d'exécution; 3. Utilisez le propre outil de surveillance de MySQL (ShowProcessList, Showstatus) pour surveiller la santé de la base de données, et sauvegarde régulièrement et organisez la base de données. Ce n'est qu'en optimisant en continu ces étapes que les performances de la base de données MySQL peuvent être améliorées.
