
 Périphériques technologiques
IA
Déploiement pratique : réseau séquentiel dynamique pour une détection et un suivi de bout en bout
Périphériques technologiques
IA
Déploiement pratique : réseau séquentiel dynamique pour une détection et un suivi de bout en bout
Déploiement pratique : réseau séquentiel dynamique pour une détection et un suivi de bout en bout

Cet article est réimprimé avec l'autorisation du compte public Autonomous Driving Heart. Veuillez contacter la source pour la réimpression.
Je pense qu'à l'exception de quelques grands fabricants de puces auto-développées, la plupart des entreprises de conduite autonome utiliseront des puces NVIDIA, qui ne peuvent être séparées de TensorRT. TensorRT est un framework d'inférence C++ qui s'exécute sur diverses plates-formes matérielles GPU NVIDIA. Le modèle que nous avons formé à l'aide de Pytorch, TF ou d'autres frameworks peut d'abord être converti au format onnx, puis converti au format TensorRT, puis utiliser le moteur d'inférence TensorRT pour exécuter notre modèle, améliorant ainsi la vitesse d'exécution de ce modèle sur les GPU NVIDIA. .
De manière générale, onnx et TensorRT ne prennent en charge que des modèles relativement fixes (y compris des formats d'entrée et de sortie fixes à tous les niveaux, des branches uniques, etc.) et prennent en charge au plus l'entrée dynamique la plus externe (l'exportation d'onnx peut être déterminée en définissant le paramètre Dynamic_axes pour permettre des changements dynamiques de dimensions). Mais les amis qui sont actifs à la pointe des algorithmes de perception sauront qu'une tendance de développement importante est la fin-2-end, qui peut couvrir la détection de cible, le suivi de cible, la prédiction de trajectoire, la planification de décision, etc. lien de conduite, et doit être un modèle de synchronisation étroitement lié aux cadres avant et arrière. Le modèle MUTR3D qui réalise la détection de cible et le suivi de cible de bout en bout peut être utilisé comme exemple typique (pour l'introduction du modèle, veuillez vous référer à). :)
Dans MOTR/MUTR3D, nous détaillerons la théorie et les exemples du mécanisme d'attribution d'étiquettes pour obtenir un véritable suivi multi-objets de bout en bout. Veuillez cliquer sur le lien pour en savoir plus : https://zhuanlan.zhihu.com/p/609123786
La conversion de ce modèle au format TensorRT et l'obtention d'un alignement de précision, même l'alignement de précision fp16, peuvent être confrontées à une série d'éléments dynamiques, par exemple : plusieurs branches if-else, changements dynamiques dans les formes d'entrée du sous-réseau et autres opérations et opérateurs nécessitant un traitement dynamique, etc.
 Images
Images
Architecture MUTR3D Parce que l'ensemble du processus implique de nombreux détails, la situation varie. Il est difficile de trouver une solution plug-and-play en consultant les documents de référence sur l'ensemble du réseau ou même en effectuant une recherche sur Google. Cela ne peut être résolu qu'un par un grâce à un fractionnement et une expérimentation continus. pratique par le blogueur (expérience précédente avec TensorRT Pas grand-chose, je n'ai pas compris son tempérament), j'ai utilisé beaucoup de cerveaux et j'ai marché sur beaucoup d'embûches Enfin, j'ai finalement réussi à convertir et à obtenir un alignement de précision fp32/fp16, et l'augmentation du délai était très faible par rapport à une simple détection de cible. Je voudrais faire un résumé simple ici et fournir une référence pour tout le monde (oui, j'ai écrit des critiques et enfin écrit sur la pratique !)
1. Problème de format de données
Tout d'abord, le format de données de MUTR3D est assez. spécial, et tous les exemples sont utilisés. Cela est dû au fait que chaque requête est liée à de nombreuses informations et est regroupée en instances pour un accès individuel plus facile. Mais pour le déploiement, l'entrée et la sortie ne peuvent être que des tenseurs, donc les données d'instance. doit être démonté en premier, devient plusieurs variables tensorielles. Et comme la requête et les autres variables du cadre actuel sont générées dans le modèle, il vous suffit de saisir la requête et les autres variables conservées dans le cadre précédent et de fusionner les deux dans le cadre. model.
2 .padding résout le problème de la forme dynamique d'entrée
Pour la requête de cadre de pré-commande d'entrée et d'autres variables, un problème important est que la forme est incertaine. En effet, MUTR3D ne conserve que les requêtes qui ont détecté des cibles dans les images précédentes. Ce problème est relativement facile à résoudre. Le moyen le plus simple est le remplissage, c'est-à-dire le remplissage à une taille fixe. Pour la requête, vous pouvez utiliser tous les 0 pour le remplissage. Le nombre approprié peut être déterminé par des expériences basées sur vos propres données. Trop peu d’entre eux manqueront facilement la cible, trop d’entre eux gaspilleront de l’espace. Bien que le paramètre Dynamic_axes de onnx puisse réaliser une entrée dynamique, il devrait y avoir un problème car il implique la taille calculée par le transformateur suivant. Je ne l'ai pas essayé, les lecteurs peuvent l'essayer
3. L'impact du remplissage sur le module d'auto-attention dans le transformateur principal
Si vous n'utilisez pas d'opérateurs spéciaux, vous pouvez réussir la conversion en ONNX et TensorRT après le remplissage. En fait, cette situation doit être rencontrée, mais elle dépasse le cadre de cet article. Par exemple, dans MUTR3D, l'utilisation de l'opérateur torch.linalg.inv pour trouver la matrice pseudo-inverse n'est pas prise en charge lors du déplacement du point de référence entre les images. Si vous rencontrez un opérateur non pris en charge, vous pouvez uniquement essayer de le remplacer. Si cela ne fonctionne pas, il ne peut être utilisé qu'en dehors du modèle. Les personnes expérimentées peuvent également écrire leurs propres opérateurs. Mais comme cette étape peut être placée dans le pré- et post-traitement du modèle, j'ai choisi de la déplacer en dehors du modèle. Il serait plus difficile d'écrire ses propres opérateurs
Une conversion réussie ne veut pas dire que tout se passe bien, la réponse est souvent non. Nous constaterons que l’écart de précision est très important. En effet, le modèle comporte de nombreux modules, parlons d'abord de la première raison. Au cours de la phase d’auto-attention du Transformer, une interaction d’informations entre plusieurs requêtes se produit. Cependant, le modèle d'origine ne conserve que les requêtes pour lesquelles la cible a été détectée (appelées requêtes actives dans le modèle), et seules ces requêtes doivent interagir avec la requête de la frame actuelle. Et maintenant, puisque de nombreuses requêtes invalides sont remplies, si toutes les requêtes interagissent ensemble, cela affectera inévitablement les résultats
La solution à ce problème s'est inspirée de DN-DETR[1], qui consiste à utiliser attention_mask, qui correspond au paramètre 'attn_mask' dans nn.MultiheadAttention. Sa fonction est de bloquer les requêtes qui ne nécessitent pas d'interaction d'informations. en effet, en PNL, toutes les phrases sont définies avec des longueurs incohérentes, ce qui répond exactement à mes besoins actuels. Je dois juste faire attention au fait que True représente la requête qui doit être bloquée et False représente la requête valide
. 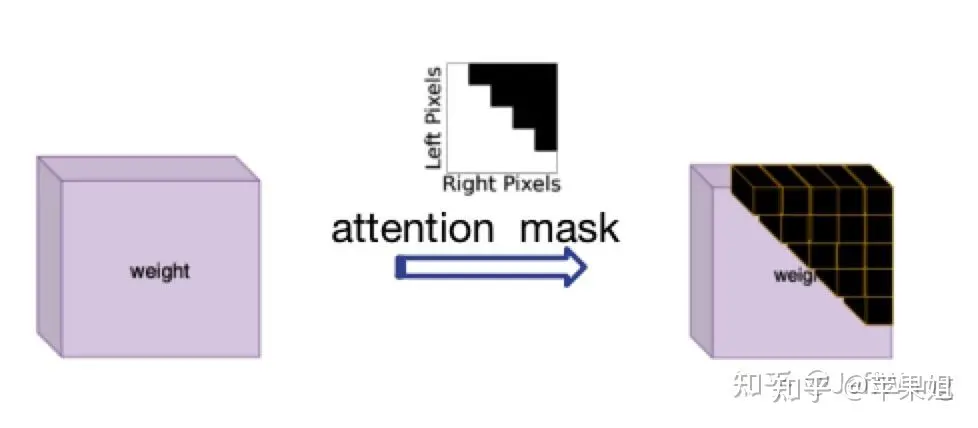 Image
Image
diagramme du masque d'attention Parce que la logique de calcul de attention_mask est un peu compliquée, de nombreux nouveaux problèmes peuvent survenir lors du fonctionnement et de la conversion de TensorRT, il doit donc être calculé en dehors du modèle et entré comme variable d'entrée dans le modèle , puis transmis au transformateur. Voici l'exemple de code :
data['attn_masks'] = attn_masks_init.clone().to(device)data['attn_masks'][active_prev_num:max_num, :] = Truedata['attn_masks'][:, active_prev_num:max_num] = True[1]DN-DETR: Accelerate DETR Training by Introducing Query DeNoising
4. L'impact du remplissage sur QIM
QIM est dans MUTR3D Le module de post-traitement de la requête générée par le transformateur est principalement divisé en trois étapes. . La première étape consiste à filtrer la requête active, c'est-à-dire à détecter la requête de la cible dans la trame actuelle, selon que obj_idxs >= 0 (cela inclut également une suppression aléatoire pendant la phase d'entraînement et un ajout aléatoire). requête fp (non impliquée dans la phase d'inférence), la deuxième étape est une requête de mise à jour, c'est-à-dire qu'une mise à jour est effectuée pour la requête filtrée dans la première étape, y compris l'auto-attention, le ffn et la valeur d'entrée de la requête de la sortie de la requête valeur. Connexion par raccourci, la troisième étape consiste à raccorder la requête mise à jour avec la requête initiale régénérée comme entrée de la trame suivante. On peut voir que le problème que nous avons mentionné au point 3 existe toujours dans la deuxième étape, c'est-à-dire le. l'auto-attention ne consiste pas à effectuer toutes les interactions entre les requêtes, mais uniquement à effectuer des interactions d'informations entre les requêtes actives. Le masque d'attention est donc utilisé ici à nouveau
Bien que le module QIM soit facultatif, les expériences montrent qu'il est utile d'améliorer la précision du modèle. . Si vous souhaitez utiliser QIM, ce masque d'attention doit être calculé dans le modèle, car le résultat de la détection de la trame actuelle ne peut pas être connu en dehors du modèle. En raison des limitations syntaxiques de tensorRT, de nombreuses opérations ne pourront pas être converties. ou vous n'obtiendrez pas ce que vous voulez. En conséquence, après de nombreuses expériences, la conclusion est que l'affectation directe de tranches d'index (similaire à l'exemple de code du point 3) n'est généralement pas prise en charge, mais il est préférable d'utiliser des calculs matriciels. en ce qui concerne les calculs, le type booléen du masque d'attention doit être converti en type flottant, et enfin le masque d'attention doit être reconverti en type booléen avant de pouvoir être utilisé. Voici l'exemple de code :
obj_mask = (obj_idxs >= 0).float()attn_mask = torch.matmul(obj_mask.unsqueeze(-1), obj_mask.unsqueeze(0)).bool()attn_mask = ~attn_mask
5. L'impact du remplissage sur les résultats de sortie
Après avoir terminé les quatre points ci-dessus, nous pouvons essentiellement nous assurer qu'il n'y a pas de problème avec la logique du tensorRT de conversion de modèle, mais une fois que les résultats de sortie ont été vérifiés à plusieurs reprises, il y a il y a encore des problèmes dans certaines images, ce qui m'a intrigué pendant un moment. Mais si vous analysez les données image par image, vous constaterez que même si la requête de remplissage dans certaines images ne participe pas au calcul du transformateur, vous pouvez obtenir un score plus élevé, puis obtenir des résultats erronés. Cette situation est en effet possible lorsque la quantité de données est importante, car la requête de remplissage n'a qu'une valeur initiale de 0, et les points de référence sont également [0,0], contrairement aux autres requêtes initialisées aléatoirement. la même opération. Mais comme il s'agit après tout d'une requête de remplissage, nous n'avons pas l'intention d'utiliser leurs résultats, nous devons donc les filtrer
Comment filtrer les résultats de la requête de remplissage ? Les jetons qui remplissent la requête ne sont que leurs positions d'index, aucune autre information n'est spécifique. Les informations d'index sont en fait enregistrées dans le masque d'attention utilisé au point 3, qui est transmis depuis l'extérieur du modèle. Ce masque est bidimensionnel, et nous pouvons utiliser l'une des dimensions (n'importe quelle ligne ou colonne) pour définir le track_score rempli directement sur 0. N'oubliez pas de toujours faire attention aux mises en garde de l'étape 4, c'est-à-dire d'essayer d'utiliser des calculs matriciels au lieu d'affectations de tranches indexées, et les calculs doivent être convertis en type flottant. Voici un exemple de code :
mask = (~attention_mask[-1]).float()track_scores = track_scores * mask
6. Comment mettre à jour dynamiquement track_id
En plus du corps du modèle, il existe en fait une étape très critique, qui consiste à mettre à jour dynamiquement track_id. C'est également un facteur important pour le modèle. être de bout en bout. Mais dans le modèle original, la façon de mettre à jour track_id est un jugement de boucle relativement complexe, c'est-à-dire que s'il est supérieur au seuil de score et qu'il s'agit d'une nouvelle cible, un nouvel obj_idx est attribué ; est inférieur au seuil du score de filtre et il s'agit d'une ancienne cible, le temps de disparition correspondant + 1, si le temps de disparition Si miss_tolerance est dépassé, l'obj idx correspondant est défini sur -1, c'est-à-dire que la cible est rejetée
Nous. sachez que tensorRT ne prend pas en charge les instructions multi-branches if-else (enfin, je ne le savais pas au début), ce qui est un casse-tête si le track_id mis à jour est également placé en dehors du modèle, cela n'affectera pas seulement la fin. -à l'architecture de bout en bout du modèle, mais rendent également impossible l'utilisation de QIM, car QIM filtre les requêtes en fonction du track_id mis à jour. Je dois donc me creuser la tête pour mettre le track_id Go mis à jour dans le modèle.
Utilisez votre ingéniosité. encore une fois (presque épuisé), les instructions if-else ne sont pas irremplaçables, comme l'utilisation d'un masque pour des opérations parallèles, par exemple, convertissez la condition en masque (par exemple, tensor[mask] = 0 Ici, heureusement, bien que les points 4 et). 5 a mentionné que tensorRT ne prend pas en charge les opérations d'affectation de tranche d'index, il prend en charge les affectations d'index booléens. Je suppose que cela peut être dû au fait que l'opération de tranche modifie implicitement la forme du tenseur. Mais après de nombreuses expériences, ce n'est pas le cas. est pris en charge dans tous les cas, mais les problèmes suivants surviennent :
需要重新写的内容是:赋值的值必须是一个,不能是多个。例如,当我更新新出现的目标时,我不会统一赋值为某个ID,而是需要为每个目标赋予连续递增的ID。我想到的解决办法是先统一赋值为一个比较大且不可能出现的数字,比如1000,以避免与之前的ID重复,然后在后续处理中将1000替换为唯一且连续递增的数字。(我真是个天才)
如果要进行递增操作(+=1),只能使用简单的掩码,即不能涉及复杂的逻辑计算。例如,对disappear_time的更新,本来需要同时判断obj_idx >= 0且track_scores = 0这个条件。虽然看似不合理,但经过分析发现,即使将obj_idx=-1的非目标的disappear_time递增,因为后续这些目标并不会被选入,所以对整体逻辑影响不大
综上,最后的动态更新track_id示例代码如下,在后处理环节要记得替换obj_idx为1000的数值.:
def update_trackid(self, track_scores, disappear_time, obj_idxs):disappear_time[track_scores >= 0.4] = 0obj_idxs[(obj_idxs == -1) & (track_scores >= 0.4)] = 1000disappear_time[track_scores 5] = -1
至此模型部分的处理就全部结束了,是不是比较崩溃,但是没办法,部署端到端模型肯定比一般模型要复杂很多.模型最后会输出固定shape的结果,还需要在后处理阶段根据obj_idx是否>0判断需要保留到下一帧的query,再根据track_scores是否>filter score thresh判断当前最终的输出结果.总体来看,需要在模型外进行的操作只有三步:帧间移动reference_points,对输入query进行padding,对输出结果进行过滤和转换格式,基本上实现了端到端的目标检测+目标跟踪.
需要重新写的内容是:以上六点的操作顺序需要说明一下。我在这里按照问题分类来写,实际上可能的顺序是1->2->3->5->6->4,因为第五点和第六点是使用QIM的前提,它们之间也存在依赖关系。另外一个问题是我没有使用memory bank,即时序融合的模块,因为经过实验发现这个模块的提升效果并不明显,而且对于端到端跟踪机制来说,已经天然地使用了时序融合(因为直接将前序帧的查询信息带到下一帧),所以时序融合并不是非常必要
好了,现在我们可以对比TensorRT的推理结果和PyTorch的推理结果,会发现在FP32精度下可以实现精度对齐,非常棒!但是,如果需要转换为FP16(可以大幅降低部署时延),第一次推理会发现结果完全变成None(再次崩溃)。导致FP16结果为None一般都是因为出现数据溢出,即数值大小超限(FP16最大支持范围是-65504~+65504)。如果你的代码使用了一些特殊的操作,或者你的数据天然数值较大,例如内外参、姿态等数据很可能超限,一般可以通过缩放等方式解决。这里再说一下和我以上6点相关的一个原因:
7.使用attention_mask导致的fp16结果为none的问题
这个问题非常隐蔽,因为问题隐藏在torch.nn.MultiheadAttention源码中,具体在torch.nn.functional.py文件中,有以下几句:
if attn_mask is not None and attn_mask.dtype == torch.bool:new_attn_mask = torch.zeros_like(attn_mask, dtype=q.dtype)new_attn_mask.masked_fill_(attn_mask, float("-inf"))attn_mask = new_attn_mask可以看到,这一步操作是对attn_mask中值为True的元素用float("-inf")填充,这也是attention mask的原理所在,也就是值为1的位置会被替换成负无穷,这样在后续的softmax操作中,这个位置的输入会被加上负无穷,输出的结果就可以忽略不记,不会对其他位置的输出产生影响.大家也能看出来了,这个float("-inf")是fp32精度,肯定超过fp16支持的范围了,所以导致结果为none.我在这里把它替换为fp16支持的下限,即-65504,转fp16就正常了,虽然说一般不要修改源码,但这个确实没办法.不要问我怎么知道这么隐蔽的问题的,因为不是我一个人想到的.但如果使用attention_mask之前仔细研究了原理,想到也不难.
好的,以下是我在端到端模型部署方面的全部经验分享,我保证这不是标题党。由于我对tensorRT的接触时间不长,所以可能有些描述不准确的地方

需要进行改写的内容是:原文链接:https://mp.weixin.qq.com/s/EcmNH2to2vXBsdnNvpo0xw
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1393
1393
 52
1207
24
52
1207
24

 Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Écrit ci-dessus et compréhension personnelle de l'auteur Le Gaussiansplatting tridimensionnel (3DGS) est une technologie transformatrice qui a émergé dans les domaines des champs de rayonnement explicites et de l'infographie ces dernières années. Cette méthode innovante se caractérise par l’utilisation de millions de gaussiennes 3D, ce qui est très différent de la méthode du champ de rayonnement neuronal (NeRF), qui utilise principalement un modèle implicite basé sur les coordonnées pour mapper les coordonnées spatiales aux valeurs des pixels. Avec sa représentation explicite de scènes et ses algorithmes de rendu différenciables, 3DGS garantit non seulement des capacités de rendu en temps réel, mais introduit également un niveau de contrôle et d'édition de scène sans précédent. Cela positionne 3DGS comme un révolutionnaire potentiel pour la reconstruction et la représentation 3D de nouvelle génération. À cette fin, nous fournissons pour la première fois un aperçu systématique des derniers développements et préoccupations dans le domaine du 3DGS.
 Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Hier, lors de l'entretien, on m'a demandé si j'avais posé des questions à longue traîne, j'ai donc pensé faire un bref résumé. Le problème à longue traîne de la conduite autonome fait référence aux cas extrêmes dans les véhicules autonomes, c'est-à-dire à des scénarios possibles avec une faible probabilité d'occurrence. Le problème perçu de la longue traîne est l’une des principales raisons limitant actuellement le domaine de conception opérationnelle des véhicules autonomes intelligents à véhicule unique. L'architecture sous-jacente et la plupart des problèmes techniques de la conduite autonome ont été résolus, et les 5 % restants des problèmes à longue traîne sont progressivement devenus la clé pour restreindre le développement de la conduite autonome. Ces problèmes incluent une variété de scénarios fragmentés, de situations extrêmes et de comportements humains imprévisibles. La « longue traîne » des scénarios limites dans la conduite autonome fait référence aux cas limites dans les véhicules autonomes (VA). Les cas limites sont des scénarios possibles avec une faible probabilité d'occurrence. ces événements rares
 Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
0. Écrit à l'avant&& Compréhension personnelle que les systèmes de conduite autonome s'appuient sur des technologies avancées de perception, de prise de décision et de contrôle, en utilisant divers capteurs (tels que caméras, lidar, radar, etc.) pour percevoir l'environnement et en utilisant des algorithmes et des modèles pour une analyse et une prise de décision en temps réel. Cela permet aux véhicules de reconnaître les panneaux de signalisation, de détecter et de suivre d'autres véhicules, de prédire le comportement des piétons, etc., permettant ainsi de fonctionner en toute sécurité et de s'adapter à des environnements de circulation complexes. Cette technologie attire actuellement une grande attention et est considérée comme un domaine de développement important pour l'avenir des transports. . un. Mais ce qui rend la conduite autonome difficile, c'est de trouver comment faire comprendre à la voiture ce qui se passe autour d'elle. Cela nécessite que l'algorithme de détection d'objets tridimensionnels du système de conduite autonome puisse percevoir et décrire avec précision les objets dans l'environnement, y compris leur emplacement,
 Le papier Stable Diffusion 3 est enfin publié, et les détails architecturaux sont révélés. Cela aidera-t-il à reproduire Sora ?
Mar 06, 2024 pm 05:34 PM
Le papier Stable Diffusion 3 est enfin publié, et les détails architecturaux sont révélés. Cela aidera-t-il à reproduire Sora ?
Mar 06, 2024 pm 05:34 PM
L'article de StableDiffusion3 est enfin là ! Ce modèle est sorti il y a deux semaines et utilise la même architecture DiT (DiffusionTransformer) que Sora. Il a fait beaucoup de bruit dès sa sortie. Par rapport à la version précédente, la qualité des images générées par StableDiffusion3 a été considérablement améliorée. Il prend désormais en charge les invites multithèmes, et l'effet d'écriture de texte a également été amélioré et les caractères tronqués n'apparaissent plus. StabilityAI a souligné que StableDiffusion3 est une série de modèles avec des tailles de paramètres allant de 800M à 8B. Cette plage de paramètres signifie que le modèle peut être exécuté directement sur de nombreux appareils portables, réduisant ainsi considérablement l'utilisation de l'IA.
 Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
La prédiction de trajectoire joue un rôle important dans la conduite autonome. La prédiction de trajectoire de conduite autonome fait référence à la prédiction de la trajectoire de conduite future du véhicule en analysant diverses données pendant le processus de conduite du véhicule. En tant que module central de la conduite autonome, la qualité de la prédiction de trajectoire est cruciale pour le contrôle de la planification en aval. La tâche de prédiction de trajectoire dispose d'une riche pile technologique et nécessite une connaissance de la perception dynamique/statique de la conduite autonome, des cartes de haute précision, des lignes de voie, des compétences en architecture de réseau neuronal (CNN&GNN&Transformer), etc. Il est très difficile de démarrer ! De nombreux fans espèrent se lancer dans la prédiction de trajectoire le plus tôt possible et éviter les pièges. Aujourd'hui, je vais faire le point sur quelques problèmes courants et des méthodes d'apprentissage introductives pour la prédiction de trajectoire ! Connaissances introductives 1. Existe-t-il un ordre d'entrée pour les épreuves de prévisualisation ? R : Regardez d’abord l’enquête, p
 Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Au cours du mois dernier, pour des raisons bien connues, j'ai eu des échanges très intensifs avec divers professeurs et camarades de classe du secteur. Un sujet inévitable dans l'échange est naturellement le populaire Tesla FSDV12 de bout en bout. Je voudrais profiter de cette occasion pour trier certaines de mes pensées et opinions en ce moment pour votre référence et votre discussion. Comment définir un système de conduite autonome de bout en bout et quels problèmes devraient être résolus de bout en bout ? Selon la définition la plus traditionnelle, un système de bout en bout fait référence à un système qui saisit les informations brutes des capteurs et génère directement les variables pertinentes pour la tâche. Par exemple, en reconnaissance d'images, CNN peut être appelé de bout en bout par rapport à la méthode traditionnelle d'extraction de caractéristiques + classificateur. Dans les tâches de conduite autonome, saisir les données de divers capteurs (caméra/LiDAR
 SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Feb 20, 2024 am 11:48 AM
SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Feb 20, 2024 am 11:48 AM
Titre original : SIMPL : ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Lien article : https://arxiv.org/pdf/2402.02519.pdf Lien code : https://github.com/HKUST-Aerial-Robotics/SIMPL Affiliation de l'auteur : Université des sciences de Hong Kong et technologie Idée DJI Paper : cet article propose une base de référence de prédiction de mouvement (SIMPL) simple et efficace pour les véhicules autonomes. Par rapport au cent agent traditionnel
 FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
La détection de cibles est un problème relativement mature dans les systèmes de conduite autonome, parmi lesquels la détection des piétons est l'un des premiers algorithmes à être déployés. Des recherches très complètes ont été menées dans la plupart des articles. Cependant, la perception de la distance à l’aide de caméras fisheye pour une vue panoramique est relativement moins étudiée. En raison de la distorsion radiale importante, la représentation standard du cadre de délimitation est difficile à mettre en œuvre dans les caméras fisheye. Pour alléger la description ci-dessus, nous explorons les conceptions étendues de boîtes englobantes, d'ellipses et de polygones généraux dans des représentations polaires/angulaires et définissons une métrique de segmentation d'instance mIOU pour analyser ces représentations. Le modèle fisheyeDetNet proposé avec une forme polygonale surpasse les autres modèles et atteint simultanément 49,5 % de mAP sur l'ensemble de données de la caméra fisheye Valeo pour la conduite autonome.
