
 Périphériques technologiques
IA
Ajustement efficace des paramètres des modèles de langage à grande échelle - Série de réglage fin BitFit/Prefix/Prompt
Périphériques technologiques
IA
Ajustement efficace des paramètres des modèles de langage à grande échelle - Série de réglage fin BitFit/Prefix/Prompt
Ajustement efficace des paramètres des modèles de langage à grande échelle - Série de réglage fin BitFit/Prefix/Prompt

En 2018, Google a publié BERT. Une fois publié, il a vaincu les résultats de pointe (Sota) de 11 tâches PNL d'un seul coup, devenant ainsi une nouvelle étape dans le monde de la PNL. La structure de BERT ; est illustré dans la figure ci-dessous. Sur la gauche se trouve le processus de pré-formation du modèle BERT, sur le côté droit se trouve le processus de réglage fin pour des tâches spécifiques. Parmi elles, l'étape de réglage fin est destinée au réglage fin lorsqu'il est ensuite utilisé dans certaines tâches en aval, telles que : la classification de texte, le balisage de parties de discours, le système de questions et réponses, etc. BERT peut être affiné sur différentes tâches sans ajuster la structure. Grâce à la conception des tâches d'un « modèle de langage pré-entraîné + réglage fin des tâches en aval », il a apporté de puissants effets de modèle. Depuis lors, le « modèle linguistique pré-entraîné + réglage fin des tâches en aval » est devenu le paradigme de formation dominant dans le domaine de la PNL.
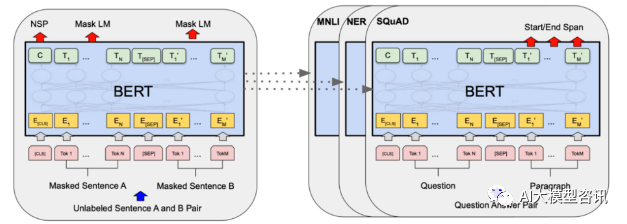 Schéma de structure BERT, la gauche est le processus de pré-formation et la droite est le processus de réglage précis des tâches spécifiques
Schéma de structure BERT, la gauche est le processus de pré-formation et la droite est le processus de réglage précis des tâches spécifiques
Cependant, avec l'augmentation de l'échelle des paramètres des modèles de langage à grande échelle (LLM) représenté par GPT3, matériel grand public Un réglage complet devient irréalisable. Le tableau suivant montre la consommation de mémoire CPU/GPU du réglage fin complet du modèle et du réglage fin efficace des paramètres sur un GPU A100 (mémoire vidéo 80G) et du matériel avec une mémoire CPU de 64 Go ou plus. Comparaison
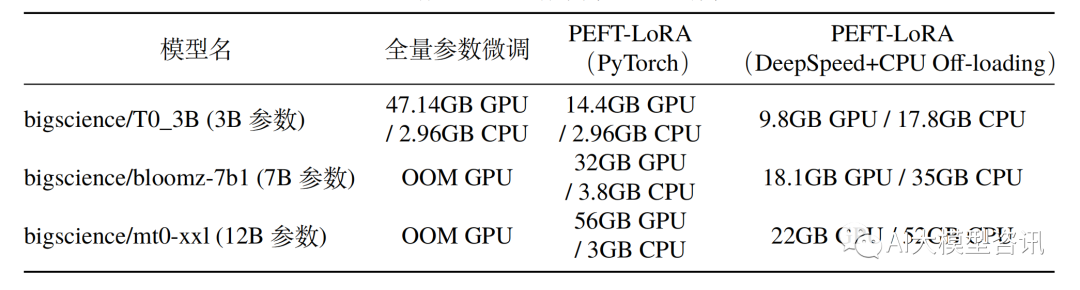 De plus, entièrement. affiner le modèle entraînera également une perte de diversité et souffrira de graves problèmes d’oubli. Par conséquent, la manière d'effectuer efficacement un réglage fin du modèle est devenue le centre de la recherche industrielle, qui fournit également un espace de recherche pour le développement rapide d'une technologie efficace de réglage fin des paramètres. Le réglage fin efficace des paramètres fait référence à un réglage fin d'une petite quantité. ou des paramètres de modèle supplémentaires et en corrigeant la plupart des paramètres de modèles pré-entraînés (LLM), réduisant ainsi considérablement les coûts de calcul et de stockage. Dans le même temps, il peut également atteindre des performances comparables à un réglage précis des paramètres. La méthode de réglage fin efficace des paramètres est encore meilleure que le réglage fin complet dans certains cas et peut être mieux généralisée aux scénarios hors domaine.
De plus, entièrement. affiner le modèle entraînera également une perte de diversité et souffrira de graves problèmes d’oubli. Par conséquent, la manière d'effectuer efficacement un réglage fin du modèle est devenue le centre de la recherche industrielle, qui fournit également un espace de recherche pour le développement rapide d'une technologie efficace de réglage fin des paramètres. Le réglage fin efficace des paramètres fait référence à un réglage fin d'une petite quantité. ou des paramètres de modèle supplémentaires et en corrigeant la plupart des paramètres de modèles pré-entraînés (LLM), réduisant ainsi considérablement les coûts de calcul et de stockage. Dans le même temps, il peut également atteindre des performances comparables à un réglage précis des paramètres. La méthode de réglage fin efficace des paramètres est encore meilleure que le réglage fin complet dans certains cas et peut être mieux généralisée aux scénarios hors domaine.
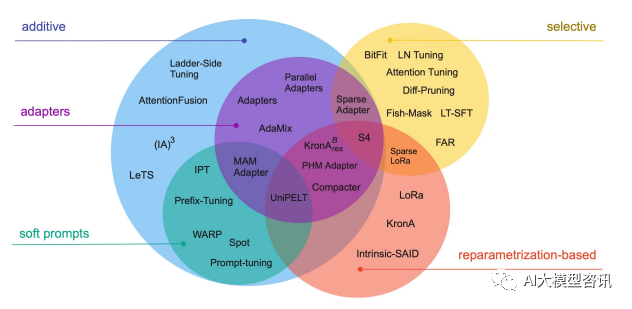
Une technologie de réglage fin efficace peut être grossièrement divisée en trois catégories suivantes, comme le montre la figure ci-dessous : ajout de paramètres supplémentaires (A), sélection d'une partie des paramètres à mettre à jour (S) et introduction d'un paramétrage lourd (R). Parmi les méthodes d'ajout de paramètres supplémentaires, elles sont principalement divisées en deux sous-catégories : les méthodes de type adaptateur et les invites logicielles.
Les technologies de réglage fin efficaces des paramètres courants incluent BitFit, Prefix Tuning, Prompt Tuning, P-Tuning, Adapter Tuning, LoRA, etc. Les chapitres suivants expliqueront en détail certaines méthodes et méthodes de réglage fin efficaces des paramètres courants
Technologies et méthodes courantes de réglage efficace des paramètres
 Série de réglage fin BitFit/Prefix/Prompt
Série de réglage fin BitFit/Prefix/Prompt
BitFitBien que pour tout le monde Un réglage fin complet pour chaque tâche est très efficace, mais il génère également un grand modèle unique pour chaque tâche pré-entraînée, ce qui rend difficile la déduction des changements survenus au cours du processus de réglage fin et difficile à déployer, d'autant plus que le nombre de tâches augmente, il est difficile à maintenir.
Idéalement, nous aimerions disposer d'une méthode de réglage fin efficace qui satisfait aux conditions suivantes :
La question ci-dessus dépend de la mesure dans laquelle le processus de réglage fin peut guider l'apprentissage de nouvelles capacités et les capacités acquises par exposition au LM pré-entraîné. Cependant, les méthodes de réglage fin efficaces précédentes, Adapter-Tuning et Diff-Pruning, peuvent également répondre partiellement aux besoins ci-dessus. BitFit, une méthode de réglage fin avec des paramètres plus petits, peut répondre à tous les besoins ci-dessus.
BitFit est une méthode de réglage fin clairsemée. Elle ne met à jour que les paramètres de biais ou une partie des paramètres de biais pendant l'entraînement. Pour le modèle Transformer, la plupart des paramètres transformateur-encodeur sont gelés et seuls les paramètres de biais et les paramètres de couche de classification de la tâche spécifique sont mis à jour. Les paramètres de biais impliqués incluent le biais impliqué dans le calcul de la requête, de la clé, de la valeur et de la fusion de plusieurs résultats d'attention dans le module d'attention, le biais dans la couche MLP, le paramètre de biais dans la couche Layernormalization et les paramètres de biais dans le modèle de pré-formation. comme le montre la figure ci-dessous. Le module
Picture
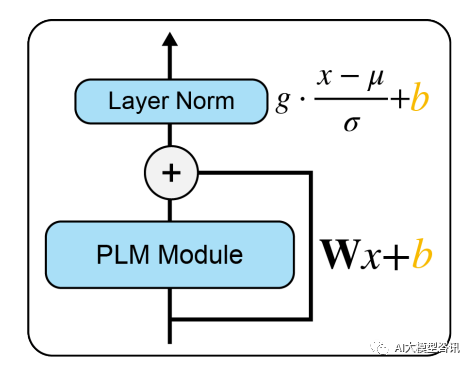 PLM représente une sous-couche PLM spécifique, telle que l'attention ou FFN. Le bloc orange dans l'image représente le vecteur d'indice pouvant être entraîné et le bloc bleu représente les paramètres du modèle pré-entraîné gelés.
PLM représente une sous-couche PLM spécifique, telle que l'attention ou FFN. Le bloc orange dans l'image représente le vecteur d'indice pouvant être entraîné et le bloc bleu représente les paramètres du modèle pré-entraîné gelés.
Dans les modèles tels que Bert-Base/Bert-Large, le paramètre de biais ne représente que 0,08 % à 0,09 % du total des paramètres du modèle. Cependant, en comparant les effets de BitFit, Adapter et Diff-Pruning sur le modèle Bert-Large basé sur l'ensemble de données GLUE, il a été constaté que BitFit a le même effet que Adapter et Diff-Pruning lorsque le nombre de paramètres est beaucoup plus petit. que celui de Adapter et Diff-Pruning , même légèrement meilleur que Adapter et Diff-Pruning dans certaines tâches.
Les résultats expérimentaux montrent que, par rapport au réglage fin complet des paramètres, le réglage fin BitFit ne met à jour qu'un très petit nombre de paramètres et a obtenu de bons résultats sur plusieurs ensembles de données. Bien que ce ne soit pas aussi efficace que le réglage fin de tous les paramètres, c'est bien mieux que la méthode Frozen pour fixer tous les paramètres du modèle. Dans le même temps, en comparant les paramètres avant et après la formation BitFit, il a été constaté que de nombreux paramètres de biais ne changeaient pas beaucoup, comme les paramètres de biais liés au calcul de la clé. Il a été constaté que les paramètres de biais de la couche FFN qui calcule la requête et agrandit la dimension des caractéristiques de N à 4N présentent les changements les plus évidents. Seule la mise à jour de ces deux types de paramètres de biais peut également obtenir de bons résultats. Au contraire, si l'un d'entre eux est corrigé, l'effet du modèle sera grandement perdu.
Prefix Tuning
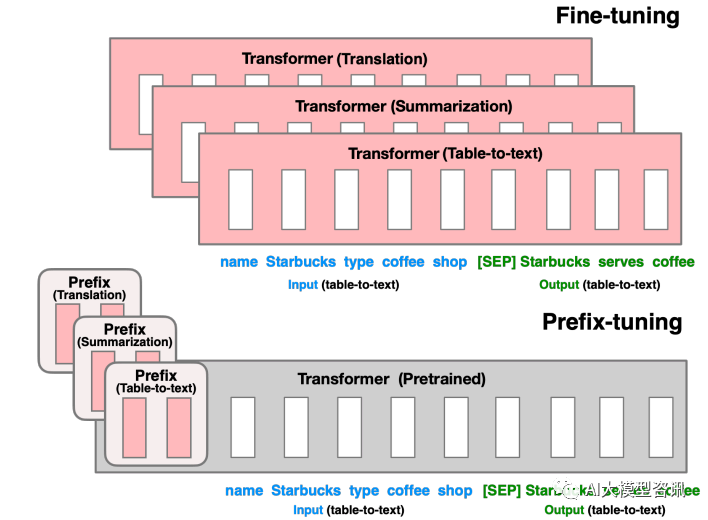
Avant Prefix Tuning, le travail consistait principalement à concevoir manuellement des modèles discrets ou à rechercher automatiquement des modèles discrets. Pour les modèles conçus manuellement, les modifications apportées au modèle sont particulièrement sensibles aux performances finales du modèle. L'ajout d'un mot, la perte d'un mot ou la modification de la position entraîneront des changements relativement importants. Pour les modèles de recherche automatisés, le coût est relativement élevé, mais les résultats des recherches précédentes de jetons discrets peuvent ne pas être optimaux. De plus, le paradigme de réglage fin traditionnel utilise des modèles pré-entraînés pour affiner différentes tâches en aval, et un poids de modèle affiné doit être enregistré pour chaque tâche. D'une part, le réglage fin de l'ensemble du modèle prend beaucoup de temps. d'un autre côté, cela prendra également beaucoup d'espace de stockage. Sur la base des deux points ci-dessus, Prefix Tuning propose un LM de pré-formation fixe, ajoutant des préfixes pouvant être entraînés et spécifiques à une tâche à LM, afin que différents préfixes puissent être enregistrés pour différentes tâches, et que le coût de réglage fin soit également faible ; en même temps, ce type de préfixe est en fait entraînable en continu. Le micro-jeton virtuel (invite douce/invite continue) est mieux optimisé et a un meilleur effet que le jeton discret.
Donc, ce qui doit être réécrit est : Alors, quelle est la signification du préfixe ? Le rôle du préfixe est de guider le modèle pour extraire les informations liées à x, afin de mieux générer y. Par exemple, si nous voulons effectuer une tâche récapitulative, après un réglage fin, le préfixe peut comprendre que la tâche actuelle est une tâche de « formulaire de synthèse », puis guider le modèle pour extraire les informations clés de x si nous voulons le faire ; une tâche de classification des émotions, un préfixe peut guider le modèle pour extraire les informations sémantiques liées à l'émotion dans x, et ainsi de suite. Cette explication n'est peut-être pas si rigoureuse, mais vous pouvez comprendre à peu près le rôle du préfixe
Le réglage du préfixe consiste à construire des jetons virtuels liés à une tâche en tant que préfixe avant de saisir le jeton, puis à mettre à jour uniquement les paramètres de la partie préfixe pendant la formation, en PLM, d'autres paramètres sont fixes. Pour différentes structures de modèles, différents préfixes doivent être construits :
- Pour les modèles d'architecture autorégressive : ajoutez un préfixe devant la phrase pour obtenir z = [PREFIX x ; contexte (par exemple : apprentissage du contexte GPT3).
- Pour le modèle d'architecture encodeur-décodeur : des préfixes sont ajoutés à l'encodeur et au décodeur, ce qui donne z = [PREFIX x ; Le préfixe est ajouté du côté de l'encodeur pour guider l'encodage de la partie d'entrée, et le préfixe est ajouté du côté du décodeur pour guider la génération ultérieure du jeton.
 Images
Images
Réécrivez le contenu sans changer le sens original et réécrivez-le en chinois : Pour le réglage fin de la partie précédente, nous mettons à jour tous les paramètres du Transformer (encadré rouge) et devons stocker une copie complète du modèle pour chaque tâche. L'ajustement du préfixe dans la partie inférieure gèlera les paramètres du transformateur et optimisera uniquement le préfixe (case rouge)
Cette méthode est en fait similaire à la construction de Prompt, sauf que Prompt est une invite "explicite" artificiellement construite et que les paramètres ne peuvent pas être mis à jour, et Prefix est un indice "implicite" qui peut être appris. Dans le même temps, afin d'éviter que la mise à jour directe des paramètres de Prefix ne provoque une formation instable et une dégradation des performances, une structure MLP est ajoutée devant la couche Prefix. Une fois la formation terminée, seuls les paramètres de Prefix sont conservés. De plus, des expériences d'ablation ont prouvé que l'ajustement de la couche d'intégration à lui seul n'est pas suffisamment expressif, ce qui entraînera une baisse significative des performances. Par conséquent, des paramètres d'invite sont ajoutés à chaque couche, ce qui constitue un changement majeur.
Bien que le réglage des préfixes semble pratique, il présente également les deux inconvénients importants suivants :Réglage rapide
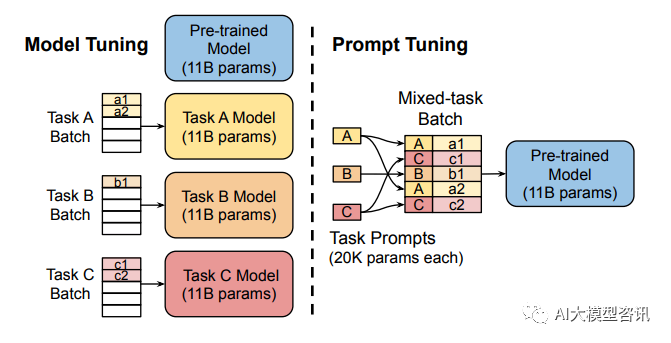
Le réglage fin complet des grands modèles entraîne un modèle pour chaque tâche, ce qui entraîne des frais généraux et des coûts de déploiement relativement élevés. Dans le même temps, la méthode des invites discrètes (faisant référence à la conception manuelle des invites et à l'ajout d'invites au modèle) est relativement coûteuse et l'effet n'est pas très bon. Prompt Tuning apprend les invites en rétropropagant les paramètres mis à jour au lieu de concevoir manuellement les invites ; en même temps, il gèle les poids d'origine du modèle et entraîne uniquement les paramètres d'invite après la formation, le même modèle peut être utilisé pour l'inférence multitâche.
 Images
Images
Le réglage du modèle nécessite de créer des copies spécifiques à une tâche de l'intégralité du modèle pré-entraîné pour chaque tâche et l'inférence doit être effectuée dans des lots séparés. Le réglage des invites nécessite uniquement le stockage d'une petite invite spécifique à chaque tâche et permet une inférence de tâches mixtes à l'aide du modèle pré-entraîné d'origine.
Prompt Tuning peut être considéré comme une version simplifiée de Prefix Tuning. Il définit sa propre invite pour chaque tâche, puis l'intègre aux données en entrée, mais ajoute uniquement des jetons d'invite à la couche d'entrée et n'a pas besoin d'ajouter du MLP. pour l'ajustement. pour résoudre des problèmes de formation difficiles.
Il a été découvert grâce à des expériences qu'à mesure que le nombre de paramètres du modèle pré-entraîné augmente, la méthode Prompt Tuning se rapprochera des résultats d'un réglage fin complet des paramètres. Dans le même temps, Prompt Tuning a également proposé le Prompt Ensembling, ce qui signifie former différentes invites pour la même tâche en même temps dans un lot (c'est-à-dire poser la même question de plusieurs manières différentes). Par exemple, le coût de l'intégration du modèle est beaucoup plus faible. En outre, le document Prompt Tuning traite également de l'impact de la méthode d'initialisation et de la longueur du jeton Prompt sur les performances du modèle. Grâce aux résultats des expériences d'ablation, il a été constaté que Prompt Tuning utilise des étiquettes de classe pour initialiser le modèle mieux que l'initialisation aléatoire et l'initialisation à l'aide d'un exemple de vocabulaire. Cependant, à mesure que l’échelle des paramètres du modèle augmente, cet écart finira par disparaître. Lorsque la longueur du jeton Prompt est d'environ 20, les performances sont déjà bonnes (après avoir dépassé 20, l'augmentation de la longueur du jeton Prompt n'améliorera pas significativement les performances du modèle. De même, cet écart diminuera également à mesure que l'échelle des paramètres du modèle augmente). augmente (c'est-à-dire que pour les modèles à très grande échelle, même si la longueur du jeton d'invite est très courte, cela n'aura pas beaucoup d'impact sur les performances).
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comprenez la tokenisation en un seul article !
Apr 12, 2024 pm 02:31 PM
Comprenez la tokenisation en un seul article !
Apr 12, 2024 pm 02:31 PM
Les modèles de langage raisonnent sur le texte, qui se présente généralement sous la forme de chaînes, mais l'entrée du modèle ne peut être que des nombres, le texte doit donc être converti sous forme numérique. La tokenisation est une tâche fondamentale du traitement du langage naturel. Elle peut diviser une séquence de texte continue (telle que des phrases, des paragraphes, etc.) en une séquence de caractères (telle que des mots, des phrases, des caractères, des signes de ponctuation, etc.) en fonction de besoins spécifiques. Les unités qu'il contient sont appelées un jeton ou un mot. Selon le processus spécifique illustré dans la figure ci-dessous, les phrases de texte sont d'abord divisées en unités, puis les éléments individuels sont numérisés (mappés en vecteurs), puis ces vecteurs sont entrés dans le modèle pour le codage, et enfin sortis vers des tâches en aval pour obtenir en outre le résultat final. La segmentation du texte peut être divisée en Toke en fonction de la granularité de la segmentation du texte.
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 Ajustement efficace des paramètres des modèles de langage à grande échelle - Série de réglage fin BitFit/Prefix/Prompt
Oct 07, 2023 pm 12:13 PM
Ajustement efficace des paramètres des modèles de langage à grande échelle - Série de réglage fin BitFit/Prefix/Prompt
Oct 07, 2023 pm 12:13 PM
En 2018, Google a publié BERT. Une fois publié, il a vaincu les résultats de pointe (Sota) de 11 tâches PNL d'un seul coup, devenant ainsi une nouvelle étape dans le monde de la PNL. dans la figure ci-dessous, à gauche se trouve le préréglage du modèle BERT, à droite le processus de réglage fin pour des tâches spécifiques. Parmi eux, l'étape de réglage fin est destinée au réglage fin lorsqu'il est ensuite utilisé dans certaines tâches en aval, telles que la classification de texte, le balisage de parties de discours, les systèmes de questions et réponses, etc. BERT peut être affiné sur différents tâches sans ajuster la structure. Grâce à la conception des tâches d'un « modèle de langage pré-entraîné + réglage fin des tâches en aval », il apporte de puissants effets de modèle. Depuis lors, le « modèle linguistique de pré-formation + réglage fin des tâches en aval » est devenu la formation dominante dans le domaine de la PNL.
 Trois secrets pour déployer de grands modèles dans le cloud
Apr 24, 2024 pm 03:00 PM
Trois secrets pour déployer de grands modèles dans le cloud
Apr 24, 2024 pm 03:00 PM
Compilation|Produit par Xingxuan|51CTO Technology Stack (ID WeChat : blog51cto) Au cours des deux dernières années, j'ai été davantage impliqué dans des projets d'IA générative utilisant de grands modèles de langage (LLM) plutôt que des systèmes traditionnels. Le cloud computing sans serveur commence à me manquer. Leurs applications vont de l’amélioration de l’IA conversationnelle à la fourniture de solutions d’analyse complexes pour diverses industries, ainsi que de nombreuses autres fonctionnalités. De nombreuses entreprises déploient ces modèles sur des plates-formes cloud, car les fournisseurs de cloud public fournissent déjà un écosystème prêt à l'emploi et constituent la voie de moindre résistance. Cependant, cela n’est pas bon marché. Le cloud offre également d'autres avantages tels que l'évolutivité, l'efficacité et des capacités informatiques avancées (GPU disponibles sur demande). Il existe certains aspects peu connus du déploiement de LLM sur les plateformes de cloud public
 RoSA : une nouvelle méthode pour un réglage fin efficace des paramètres de grands modèles
Jan 18, 2024 pm 05:27 PM
RoSA : une nouvelle méthode pour un réglage fin efficace des paramètres de grands modèles
Jan 18, 2024 pm 05:27 PM
À mesure que les modèles de langage évoluent à une échelle sans précédent, un réglage précis des tâches en aval devient prohibitif. Afin de résoudre ce problème, les chercheurs ont commencé à s’intéresser à la méthode PEFT et à l’adopter. L'idée principale de la méthode PEFT est de limiter la portée du réglage fin à un petit ensemble de paramètres afin de réduire les coûts de calcul tout en atteignant des performances de pointe sur les tâches de compréhension du langage naturel. De cette manière, les chercheurs peuvent économiser des ressources informatiques tout en maintenant des performances élevées, ouvrant ainsi la voie à de nouveaux points chauds de recherche dans le domaine du traitement du langage naturel. RoSA est une nouvelle technique PEFT qui, grâce à des expériences sur un ensemble de références, s'est avérée surpasser les précédentes méthodes adaptatives de bas rang (LoRA) et de réglage fin clairsemé pur utilisant le même budget de paramètres. Cet article approfondira
 Meta lance le modèle de langage IA LLaMA, un modèle de langage à grande échelle avec 65 milliards de paramètres
Apr 14, 2023 pm 06:58 PM
Meta lance le modèle de langage IA LLaMA, un modèle de langage à grande échelle avec 65 milliards de paramètres
Apr 14, 2023 pm 06:58 PM
Selon les informations du 25 février, Meta a annoncé vendredi, heure locale, qu'elle lancerait un nouveau modèle de langage à grande échelle basé sur l'intelligence artificielle (IA) pour la communauté des chercheurs, rejoignant ainsi Microsoft, Google et d'autres sociétés stimulées par ChatGPT pour rejoindre l'intelligence artificielle. .Concurrence intelligente. LLaMA de Meta est l'abréviation de « Large Language Model MetaAI » (LargeLanguageModelMetaAI), qui est disponible sous une licence non commerciale pour les chercheurs et les entités du gouvernement, de la communauté et du monde universitaire. La société mettra le code sous-jacent à la disposition des utilisateurs, afin qu'ils puissent modifier eux-mêmes le modèle et l'utiliser pour des cas d'utilisation liés à la recherche. Meta a déclaré que les exigences du modèle en matière de puissance de calcul
 Idéalement formé le plus grand ViT de l'histoire ? Google met à niveau le modèle de langage visuel PaLI : prend en charge plus de 100 langues
Apr 12, 2023 am 09:31 AM
Idéalement formé le plus grand ViT de l'histoire ? Google met à niveau le modèle de langage visuel PaLI : prend en charge plus de 100 langues
Apr 12, 2023 am 09:31 AM
Les progrès du traitement du langage naturel ces dernières années proviennent en grande partie de modèles de langage à grande échelle. Chaque nouveau modèle publié pousse la quantité de paramètres et de données d'entraînement vers de nouveaux sommets, et en même temps, les classements de référence existants seront abattus ! Par exemple, en avril de cette année, Google a publié le modèle de langage PaLM (Pathways Language Model) composé de 540 milliards de paramètres, qui a surpassé avec succès les humains dans une série de tests de langage et de raisonnement, en particulier ses excellentes performances dans des scénarios d'apprentissage sur petits échantillons. PaLM est considéré comme la direction de développement du modèle de langage de nouvelle génération. De la même manière, les modèles de langage visuel font des merveilles et les performances peuvent être améliorées en augmentant la taille du modèle. Bien sûr, s'il ne s'agit que d'un modèle de langage visuel multitâche
 BLOOM peut créer une nouvelle culture pour la recherche sur l'IA, mais des défis demeurent
Apr 09, 2023 pm 04:21 PM
BLOOM peut créer une nouvelle culture pour la recherche sur l'IA, mais des défis demeurent
Apr 09, 2023 pm 04:21 PM
Traducteur | Révisé par Li Rui | Sun Shujuan Le projet de recherche BigScience a récemment publié un grand modèle de langage BLOOM. À première vue, cela ressemble à une autre tentative de copie du GPT-3 d'OpenAI. Mais ce qui distingue BLOOM des autres modèles de langage naturel (LLM) à grande échelle, ce sont ses efforts pour rechercher, développer, former et publier des modèles d'apprentissage automatique. Ces dernières années, les grandes entreprises technologiques ont caché des modèles de langage naturel (LLM) à grande échelle comme de stricts secrets commerciaux, et l'équipe BigScience a placé la transparence et l'ouverture au centre de BLOOM dès le début du projet. Le résultat est un modèle linguistique à grande échelle qui peut être étudié et étudié et mis à la disposition de tous. B
