
 Périphériques technologiques
IA
770 millions de paramètres, dépassant les 540 milliards de PaLM ! UW Google propose une 'distillation étape par étape', qui ne nécessite que 80 % des données de formation ACL 2023 |
Périphériques technologiques
IA
770 millions de paramètres, dépassant les 540 milliards de PaLM ! UW Google propose une 'distillation étape par étape', qui ne nécessite que 80 % des données de formation ACL 2023 |
770 millions de paramètres, dépassant les 540 milliards de PaLM ! UW Google propose une 'distillation étape par étape', qui ne nécessite que 80 % des données de formation ACL 2023 |

Les grands modèles de langage excellent en termes de performances et sont capables de résoudre de nouvelles tâches avec zéro ou quelques indices. Cependant, dans le déploiement réel d'applications, LLM n'est pas très pratique car il a une faible efficacité d'utilisation de la mémoire et nécessite beaucoup de ressources informatiques. Par exemple, l'exécution d'un service de modèle de langage avec 175 milliards de paramètres nécessite au moins 350 Go de mémoire vidéo, et l'actuelle. La plupart des modèles de langage ont dépassé 500 milliards de paramètres. De nombreuses équipes de recherche ne disposent pas de suffisamment de ressources pour les exécuter et ne peuvent pas répondre aux faibles performances de latence des applications réelles.
Certaines études utilisent également des données étiquetées manuellement ou une distillation à l'aide d'étiquettes générées par LLM pour entraîner des modèles plus petits et spécifiques à des tâches, mais le réglage fin et la distillation nécessitent une grande quantité de données d'entraînement pour obtenir des performances comparables à celles de LLM.
Afin de résoudre le problème des besoins en ressources pour les grands modèles, l'Université de Washington et Google ont collaboré pour proposer un nouveau mécanisme de distillation appelé « Distilling Step-by-Step ». Grâce à la distillation étape par étape, la taille du modèle distillé est plus petite que le modèle d'origine, mais les performances sont meilleures et moins de données d'entraînement sont nécessaires pendant le processus de réglage fin et de distillation

Après avoir mené des expériences sur 4 benchmarks PNL, nous avons constaté :
1 Par rapport au réglage fin et à la distillation, ce mécanisme permet d'obtenir de meilleures performances avec moins d'échantillons d'entraînement 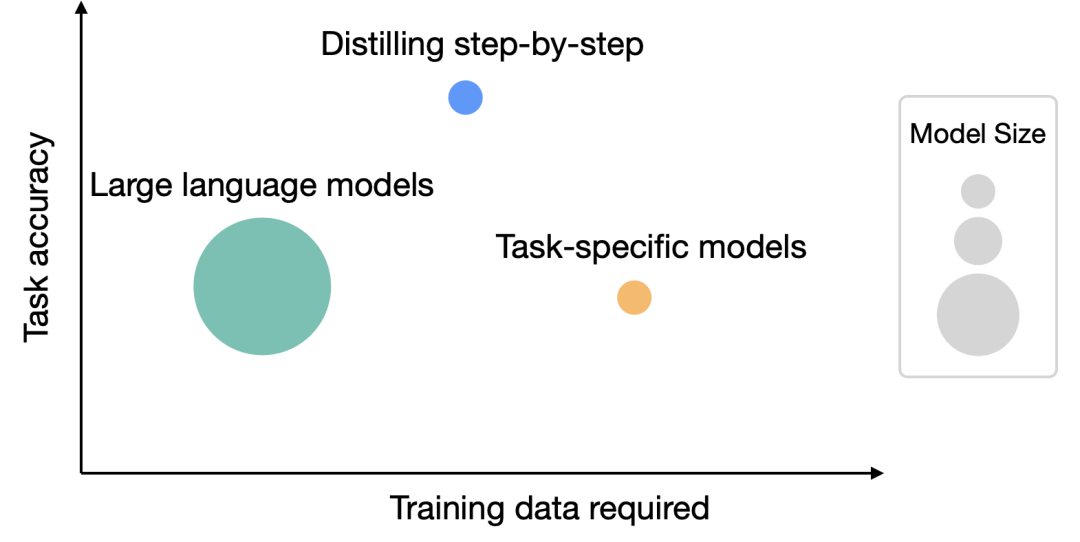
La distillation de distribution comprend principalement deux étapes :
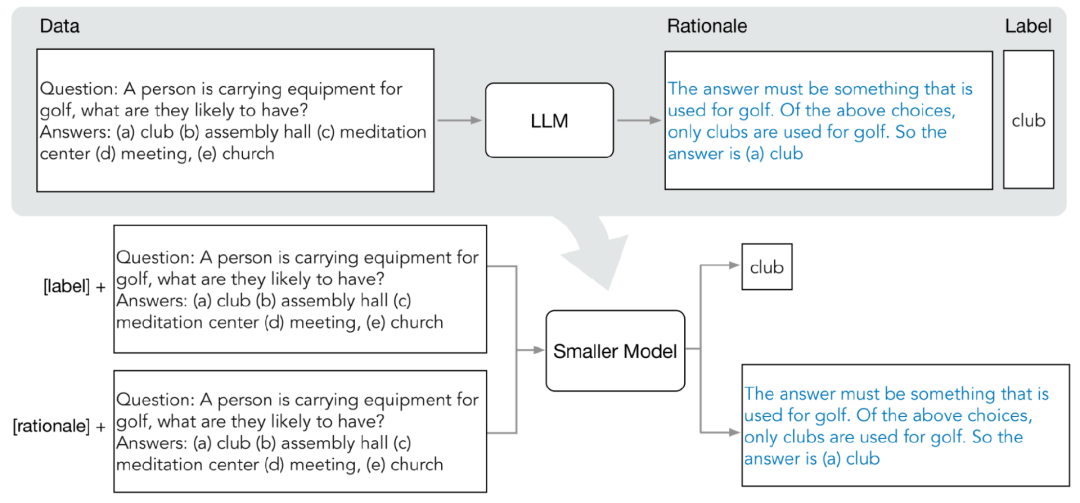
Les chercheurs utilisent une chaîne de réflexion en quelques étapes ( CoT) vous invite à extraire des étapes intermédiaires de LLM Predict. Après avoir déterminé la tâche cible, préparez d'abord quelques échantillons dans l'invite de saisie LLM. Chaque exemple se compose d'un triplet, comprenant une entrée, un principe et une sortie
Après avoir saisi les invites, LLM est capable d'imiter la démonstration du triplet pour générer des principes prédictifs pour d'autres nouvelles questions, par exemple, dans la tâche de questions et réponses de bon sens. , étant donné la
question de saisie :
Après un affinement progressif, LLM peut donner la bonne réponse à la question "(a) population "Zones densément peuplées" et donnez les raisons pour lesquelles vous avez répondu à la question "La réponse doit être un endroit avec de nombreuses personnes. Parmi les choix ci-dessus, seules les zones densément peuplées comptent de nombreuses personnes." Après un affinement progressif, LLM a pu conclure que la bonne réponse est « (a) une zone densément peuplée » et a fourni la raison pour laquelle il a répondu à la question « La réponse doit être un endroit avec de nombreuses personnes. Parmi les choix ci-dessus, seules les zones densément peuplées avoir beaucoup de monde." Des gens."
En fournissant des exemples CoT associés à une justification dans les invites, la capacité d'apprentissage contextuel permet à LLM de générer les raisons de réponse correspondantes pour les types de questions non rencontrés
2. Former de petits modèles
En construisant le processus de formation pour les problèmes multitâches, les raisons de prédiction peuvent être extraites et incorporées dans le petit modèle d'entraînement
En plus de la tâche de prédiction d'étiquette standard, les chercheurs ont également utilisé une nouvelle tâche de génération de raisons pour entraîner le petit modèle, afin que le modèle puisse apprendre à générer des utilisateurs. une étape d'inférence intermédiaire pour la prédiction et guide le modèle pour mieux prédire l'étiquette de résultat.
Distinguez les tâches de prédiction d'étiquette et de génération de raison en ajoutant les préfixes de tâche « étiquette » et « justification » à l'invite de saisie.
Résultats expérimentaux
Dans l'expérience, les chercheurs ont sélectionné le modèle PaLM avec 540 milliards de paramètres comme référence LLM et ont utilisé le modèle T5 comme petit modèle en aval lié aux tâches.
Dans cette étude, nous avons mené des expériences sur quatre ensembles de données de référence, à savoir e-SNLI et ANLI pour le raisonnement en langage naturel, CQA pour les réponses aux questions de bon sens et SVAMP pour les questions d'applications mathématiques arithmétiques. Nous avons mené des expériences sur ces trois tâches PNL différentes
Moins de données d'entraînement
La méthode de distillation par étapes surpasse le réglage standard des performances et nécessite moins de données d'entraînement
Dans l'ensemble de données e-SNLI, de meilleures performances que la norme le réglage fin est obtenu en utilisant 12,5 % de l'ensemble de données complet, et seulement 75 %, 25 % et 20 % des données de formation sont requises respectivement sur ANLI, CQA et SVAMP.
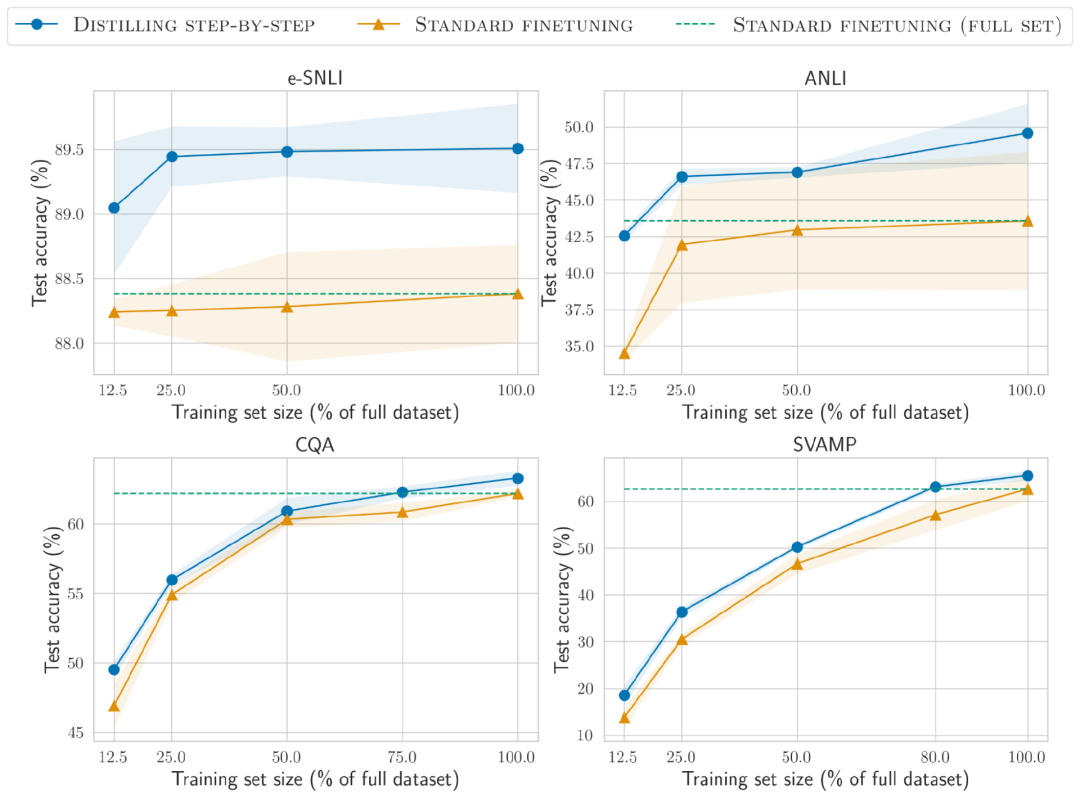
Par rapport au réglage fin standard sur des ensembles de données étiquetés par des humains de différentes tailles à l'aide d'un modèle T5 de 220 M, la distillation de distribution surpasse le réglage fin standard sur l'ensemble de données complet en utilisant moins d'exemples de formation sur tous les ensembles de données
Déploiement plus petit taille du modèle
Par rapport au LLM provoqué par CoT à quelques échantillons, la taille du modèle obtenue par distillation par distribution est beaucoup plus petite, mais les performances sont meilleures.
Sur l'ensemble de données e-SNLI, l'utilisation du modèle 220M T5 permet d'obtenir de meilleures performances que le PaLM 540B ; sur ANLI, l'utilisation du modèle 770M T5 permet d'obtenir de meilleures performances que le PaLM 540B, et la taille du modèle n'est que de 1/700
"Modèle plus petit, moins de données"
Il a été observé que le réglage fin standard ne peut pas atteindre le niveau de performance de PaLM même en utilisant l'ensemble de données complet à 100 %, ce qui montre que la distillation pas à pas peut simultanément réduire la taille du modèle et le volume des données d'entraînement, atteignant des performances au-delà du LLM
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Dans Debian Systems, la fonction ReadDir est utilisée pour lire le contenu du répertoire, mais l'ordre dans lequel il revient n'est pas prédéfini. Pour trier les fichiers dans un répertoire, vous devez d'abord lire tous les fichiers, puis les trier à l'aide de la fonction QSORT. Le code suivant montre comment trier les fichiers de répertoire à l'aide de ReadDir et QSort dans Debian System: # include # include # include # include # include // Fonction de comparaison personnalisée, utilisée pour qsortintCompare (constvoid * a, constvoid * b) {returnstrcmp (* (
 Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Dans Debian Systems, les appels du système ReadDir sont utilisés pour lire le contenu des répertoires. Si ses performances ne sont pas bonnes, essayez la stratégie d'optimisation suivante: simplifiez le nombre de fichiers d'annuaire: divisez les grands répertoires en plusieurs petits répertoires autant que possible, en réduisant le nombre d'éléments traités par appel ReadDir. Activer la mise en cache de contenu du répertoire: construire un mécanisme de cache, mettre à jour le cache régulièrement ou lorsque le contenu du répertoire change et réduire les appels fréquents à Readdir. Les caches de mémoire (telles que Memcached ou Redis) ou les caches locales (telles que les fichiers ou les bases de données) peuvent être prises en compte. Adoptez une structure de données efficace: si vous implémentez vous-même la traversée du répertoire, sélectionnez des structures de données plus efficaces (telles que les tables de hachage au lieu de la recherche linéaire) pour stocker et accéder aux informations du répertoire
 Comment définir le niveau de journal Debian Apache
Apr 13, 2025 am 08:33 AM
Comment définir le niveau de journal Debian Apache
Apr 13, 2025 am 08:33 AM
Cet article décrit comment ajuster le niveau de journalisation du serveur Apacheweb dans le système Debian. En modifiant le fichier de configuration, vous pouvez contrôler le niveau verbeux des informations de journal enregistrées par Apache. Méthode 1: Modifiez le fichier de configuration principal pour localiser le fichier de configuration: le fichier de configuration d'Apache2.x est généralement situé dans le répertoire / etc / apache2 /. Le nom de fichier peut être apache2.conf ou httpd.conf, selon votre méthode d'installation. Modifier le fichier de configuration: Ouvrez le fichier de configuration avec les autorisations racine à l'aide d'un éditeur de texte (comme Nano): Sutonano / etc / apache2 / apache2.conf
 Comment Debian OpenSSL empêche les attaques de l'homme au milieu
Apr 13, 2025 am 10:30 AM
Comment Debian OpenSSL empêche les attaques de l'homme au milieu
Apr 13, 2025 am 10:30 AM
Dans Debian Systems, OpenSSL est une bibliothèque importante pour le chiffrement, le décryptage et la gestion des certificats. Pour empêcher une attaque d'homme dans le milieu (MITM), les mesures suivantes peuvent être prises: utilisez HTTPS: assurez-vous que toutes les demandes de réseau utilisent le protocole HTTPS au lieu de HTTP. HTTPS utilise TLS (Protocole de sécurité de la couche de transport) pour chiffrer les données de communication pour garantir que les données ne sont pas volées ou falsifiées pendant la transmission. Vérifiez le certificat de serveur: vérifiez manuellement le certificat de serveur sur le client pour vous assurer qu'il est digne de confiance. Le serveur peut être vérifié manuellement via la méthode du délégué d'URLSession
 Méthode d'installation du certificat de Debian Mail Server SSL
Apr 13, 2025 am 11:39 AM
Méthode d'installation du certificat de Debian Mail Server SSL
Apr 13, 2025 am 11:39 AM
Les étapes pour installer un certificat SSL sur le serveur de messagerie Debian sont les suivantes: 1. Installez d'abord la boîte à outils OpenSSL, assurez-vous que la boîte à outils OpenSSL est déjà installée sur votre système. Si ce n'est pas installé, vous pouvez utiliser la commande suivante pour installer: Sudoapt-getUpDaSuDoapt-getInstallOpenSSL2. Générer la clé privée et la demande de certificat Suivant, utilisez OpenSSL pour générer une clé privée RSA 2048 bits et une demande de certificat (RSE): OpenSS
 Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
La fonction ReadDir dans le système Debian est un appel système utilisé pour lire le contenu des répertoires et est souvent utilisé dans la programmation C. Cet article expliquera comment intégrer ReadDir avec d'autres outils pour améliorer sa fonctionnalité. Méthode 1: combinant d'abord le programme de langue C et le pipeline, écrivez un programme C pour appeler la fonction readdir et sortir le résultat: # include # include # include # includeIntmain (intargc, char * argv []) {dir * dir; structDirent * entrée; if (argc! = 2) {
 Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
La configuration du pare-feu d'un serveur de courrier Debian est une étape importante pour assurer la sécurité du serveur. Voici plusieurs méthodes de configuration de pare-feu couramment utilisées, y compris l'utilisation d'iptables et de pare-feu. Utilisez les iptables pour configurer le pare-feu pour installer iptables (sinon déjà installé): Sudoapt-getUpDaSuDoapt-getinstalliptableView Règles actuelles iptables: Sudoiptable-L Configuration
 Comment faire Debian Hadoop Log Management
Apr 13, 2025 am 10:45 AM
Comment faire Debian Hadoop Log Management
Apr 13, 2025 am 10:45 AM
Gérer les journaux Hadoop sur Debian, vous pouvez suivre les étapes et les meilleures pratiques suivantes: l'agrégation de journal Activer l'agrégation de journaux: définir yarn.log-aggregation-inable à true dans le fichier yarn-site.xml pour activer l'agrégation de journaux. Configurer la stratégie de rétention du journal: Définissez Yarn.log-agregation.retain-secondes pour définir le temps de rétention du journal, tel que 172800 secondes (2 jours). Spécifiez le chemin de stockage des journaux: via yarn.n
