
 Périphériques technologiques
IA
L'impact de la rareté des données sur la formation des modèles
Périphériques technologiques
IA
L'impact de la rareté des données sur la formation des modèles
L'impact de la rareté des données sur la formation des modèles


L'impact de la rareté des données sur la formation des modèles nécessite des exemples de code spécifiques
Dans les domaines de l'apprentissage automatique et de l'intelligence artificielle, les données sont l'un des éléments essentiels de la formation des modèles. Cependant, un problème auquel nous sommes souvent confrontés dans la réalité est la rareté des données. La rareté des données fait référence à la quantité insuffisante de données d'entraînement ou au manque de données annotées. Dans ce cas, cela aura un certain impact sur l'entraînement du modèle.
Le problème de la rareté des données se reflète principalement dans les aspects suivants :
- Surajustement : lorsque la quantité de données d'entraînement n'est pas suffisante, le modèle est sujet au surajustement. Le surajustement signifie que le modèle s'adapte trop aux données d'entraînement et ne peut pas bien se généraliser aux nouvelles données. En effet, le modèle ne dispose pas de suffisamment d'échantillons de données pour connaître la distribution et les caractéristiques des données, ce qui entraîne la production de résultats de prédiction inexacts.
- Sous-ajustement : par rapport au surajustement, le sous-ajustement signifie que le modèle ne peut pas bien s'adapter aux données d'entraînement. En effet, la quantité de données d'entraînement est insuffisante pour couvrir la diversité des données, ce qui empêche le modèle de capturer la complexité des données. Les modèles sous-équipés ne parviennent souvent pas à fournir des prévisions précises.
Comment résoudre le problème de rareté des données et améliorer les performances du modèle ? Voici quelques méthodes et exemples de code couramment utilisés :
- L'augmentation des données (Data Augmentation) est une méthode courante pour augmenter le nombre d'échantillons d'entraînement en transformant ou en développant les données existantes. Les méthodes courantes d'amélioration des données incluent la rotation de l'image, le retournement, la mise à l'échelle, le recadrage, etc. Voici un exemple simple de code de rotation d'image :
from PIL import Image
def rotate_image(image, angle):
rotated_image = image.rotate(angle)
return rotated_image
image = Image.open('image.jpg')
rotated_image = rotate_image(image, 90)
rotated_image.save('rotated_image.jpg')- L'apprentissage par transfert (Transfer Learning) consiste à utiliser des modèles déjà formés pour résoudre de nouveaux problèmes. En utilisant les fonctionnalités déjà apprises des modèles existants, une meilleure formation peut être effectuée sur des ensembles de données rares. Voici un exemple de code d'apprentissage par transfert :
from keras.applications import VGG16 from keras.models import Model base_model = VGG16(weights='imagenet', include_top=False, input_shape=(224, 224, 3)) x = base_model.output x = GlobalAveragePooling2D()(x) x = Dense(1024, activation='relu')(x) predictions = Dense(num_classes, activation='softmax')(x) model = Model(inputs=base_model.input, outputs=predictions) model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
- Domain Adaptation (Domain Adaptation) est une méthode de transfert de connaissances du domaine source vers le domaine cible. De meilleures capacités de généralisation peuvent être obtenues en utilisant certaines techniques adaptatives au domaine, telles que l'apprentissage auto-supervisé, les réseaux contradictoires de domaine, etc. Voici un exemple de code d'adaptation de domaine :
import torch
import torchvision
import torch.nn as nn
source_model = torchvision.models.resnet50(pretrained=True)
target_model = torchvision.models.resnet50(pretrained=False)
for param in source_model.parameters():
param.requires_grad = False
source_features = source_model.features(x)
target_features = target_model.features(x)
class DANNClassifier(nn.Module):
def __init__(self, num_classes):
super(DANNClassifier, self).__init__()
self.fc = nn.Linear(2048, num_classes)
def forward(self, x):
x = self.fc(x)
return x
source_classifier = DANNClassifier(num_classes)
target_classifier = DANNClassifier(num_classes)
source_outputs = source_classifier(source_features)
target_outputs = target_classifier(target_features)La rareté des données a un impact non négligeable sur la formation du modèle. Grâce à des méthodes telles que l'augmentation des données, l'apprentissage par transfert et l'adaptation de domaine, nous pouvons résoudre efficacement le problème de la rareté des données et améliorer les performances et les capacités de généralisation du modèle. Dans les applications pratiques, nous devons choisir des méthodes appropriées basées sur des problèmes spécifiques et des caractéristiques des données pour obtenir de meilleurs résultats.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



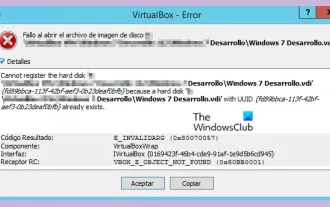 VBOX_E_OBJECT_NOT_FOUND(0x80bb0001)Erreur VirtualBox
Mar 24, 2024 am 09:51 AM
VBOX_E_OBJECT_NOT_FOUND(0x80bb0001)Erreur VirtualBox
Mar 24, 2024 am 09:51 AM
Lorsque vous essayez d'ouvrir une image disque dans VirtualBox, vous pouvez rencontrer une erreur indiquant que le disque dur ne peut pas être enregistré. Cela se produit généralement lorsque le fichier image disque de la VM que vous essayez d'ouvrir a le même UUID qu'un autre fichier image disque virtuel. Dans ce cas, VirtualBox affiche le code d'erreur VBOX_E_OBJECT_NOT_FOUND(0x80bb0001). Si vous rencontrez cette erreur, ne vous inquiétez pas, vous pouvez essayer quelques solutions. Tout d'abord, vous pouvez essayer d'utiliser les outils de ligne de commande de VirtualBox pour modifier l'UUID du fichier image disque, ce qui évitera les conflits. Vous pouvez exécuter la commande `VBoxManageinternal
 Quelle est l'efficacité de la réception d'appels téléphoniques en mode avion ?
Feb 20, 2024 am 10:07 AM
Quelle est l'efficacité de la réception d'appels téléphoniques en mode avion ?
Feb 20, 2024 am 10:07 AM
Que se passe-t-il lorsque quelqu'un appelle en mode avion ? Les téléphones portables sont devenus l'un des outils indispensables dans la vie des gens. Il s'agit non seulement d'un outil de communication, mais aussi d'un ensemble de fonctions de divertissement, d'apprentissage, de travail et autres. Avec la mise à niveau et l’amélioration continues des fonctions des téléphones mobiles, les gens deviennent de plus en plus dépendants des téléphones mobiles. Avec l’avènement du mode avion, les gens peuvent utiliser leur téléphone plus facilement pendant les vols. Cependant, certains s'inquiètent de l'impact que les appels d'autres personnes en mode avion auront sur le téléphone mobile ou sur l'utilisateur ? Cet article analysera et discutera sous plusieurs aspects. d'abord
 Pratique de formation au système de recommandation à grande échelle de WeChat basée sur PyTorch
Apr 12, 2023 pm 12:13 PM
Pratique de formation au système de recommandation à grande échelle de WeChat basée sur PyTorch
Apr 12, 2023 pm 12:13 PM
Cet article présentera la formation au système de recommandation à grande échelle de WeChat basée sur PyTorch. Contrairement à certains autres domaines du deep learning, le système de recommandation utilise toujours Tensorflow comme cadre de formation, ce qui est critiqué par la majorité des développeurs. Bien que certaines pratiques utilisent PyTorch pour la formation aux recommandations, l'échelle est petite et il n'y a pas de véritable vérification commerciale, ce qui rend difficile la promotion des premiers utilisateurs d'entreprises. En février 2022, l'équipe PyTorch a lancé la bibliothèque officielle recommandée TorchRec. Notre équipe a commencé à essayer TorchRec en interne en mai et a lancé une série de coopération avec l'équipe TorchRec. Au cours de plusieurs mois d'essais, nous avons trouvé TorchR
 Comment désactiver la fonction commentaire sur TikTok ? Que se passe-t-il après avoir désactivé la fonction de commentaire sur TikTok ?
Mar 23, 2024 pm 06:20 PM
Comment désactiver la fonction commentaire sur TikTok ? Que se passe-t-il après avoir désactivé la fonction de commentaire sur TikTok ?
Mar 23, 2024 pm 06:20 PM
Sur la plateforme Douyin, les utilisateurs peuvent non seulement partager leurs moments de vie, mais aussi interagir avec d'autres utilisateurs. Parfois, la fonction de commentaire peut provoquer des expériences désagréables, telles que de la violence en ligne, des commentaires malveillants, etc. Alors, comment désactiver la fonction commentaire de TikTok ? 1. Comment désactiver la fonction de commentaire de Douyin ? 1. Connectez-vous à l'application Douyin et accédez à votre page d'accueil personnelle. 2. Cliquez sur « I » dans le coin inférieur droit pour accéder au menu des paramètres. 3. Dans le menu des paramètres, recherchez « Paramètres de confidentialité ». 4. Cliquez sur « Paramètres de confidentialité » pour accéder à l'interface des paramètres de confidentialité. 5. Dans l'interface des paramètres de confidentialité, recherchez « Paramètres des commentaires ». 6. Cliquez sur « Paramètres des commentaires » pour accéder à l'interface de configuration des commentaires. 7. Dans l'interface des paramètres des commentaires, recherchez l'option « Fermer les commentaires ». 8. Cliquez sur l'option « Fermer les commentaires » pour confirmer les commentaires de clôture.
 Vulnérabilités d'inclusion de fichiers dans Java et leur impact
Aug 08, 2023 am 10:30 AM
Vulnérabilités d'inclusion de fichiers dans Java et leur impact
Aug 08, 2023 am 10:30 AM
Java est un langage de programmation couramment utilisé pour développer diverses applications. Cependant, tout comme les autres langages de programmation, Java présente des vulnérabilités et des risques en matière de sécurité. L'une des vulnérabilités courantes est la vulnérabilité d'inclusion de fichiers (FileInclusionVulnerability). Cet article explorera le principe, l'impact et comment éviter cette vulnérabilité. Les vulnérabilités d'inclusion de fichiers font référence à l'introduction dynamique ou à l'inclusion d'autres fichiers dans le programme, mais les fichiers introduits ne sont pas entièrement vérifiés et protégés, donc
 L'impact de la rareté des données sur la formation des modèles
Oct 08, 2023 pm 06:17 PM
L'impact de la rareté des données sur la formation des modèles
Oct 08, 2023 pm 06:17 PM
L'impact de la rareté des données sur la formation des modèles nécessite des exemples de code spécifiques. Dans les domaines de l'apprentissage automatique et de l'intelligence artificielle, les données sont l'un des éléments essentiels de la formation des modèles. Cependant, un problème auquel nous sommes souvent confrontés dans la réalité est la rareté des données. La rareté des données fait référence à la quantité insuffisante de données d'entraînement ou au manque de données annotées. Dans ce cas, cela aura un certain impact sur l'entraînement du modèle. Le problème de la rareté des données se reflète principalement dans les aspects suivants : Surajustement : lorsque la quantité de données d'entraînement est insuffisante, le modèle est sujet au surajustement. Le surajustement fait référence au modèle qui s'adapte de manière excessive aux données d'entraînement.
 Quels problèmes les secteurs défectueux du disque dur provoqueront-ils ?
Feb 18, 2024 am 10:07 AM
Quels problèmes les secteurs défectueux du disque dur provoqueront-ils ?
Feb 18, 2024 am 10:07 AM
Les secteurs défectueux sur un disque dur font référence à une panne physique du disque dur, c'est-à-dire que l'unité de stockage sur le disque dur ne peut pas lire ou écrire des données normalement. L'impact des secteurs défectueux sur le disque dur est très important et peut entraîner une perte de données, une panne du système et une réduction des performances du disque dur. Cet article présentera en détail l'impact des secteurs défectueux du disque dur et les solutions associées. Premièrement, des secteurs défectueux sur le disque dur peuvent entraîner une perte de données. Lorsqu'un secteur d'un disque dur contient des secteurs défectueux, les données de ce secteur ne peuvent pas être lues, ce qui entraîne une corruption ou une inaccessibilité des fichiers. Cette situation est particulièrement grave si des fichiers importants sont stockés dans le secteur où se trouvent les secteurs défectueux.
 Comment utiliser Python pour entraîner des modèles sur des images
Aug 26, 2023 pm 10:42 PM
Comment utiliser Python pour entraîner des modèles sur des images
Aug 26, 2023 pm 10:42 PM
Présentation de l'utilisation de Python pour entraîner des modèles sur des images : dans le domaine de la vision par ordinateur, l'utilisation de modèles d'apprentissage profond pour classer les images, la détection de cibles et d'autres tâches est devenue une méthode courante. En tant que langage de programmation largement utilisé, Python fournit une multitude de bibliothèques et d'outils, ce qui rend relativement facile l'entraînement de modèles sur des images. Cet article expliquera comment utiliser Python et ses bibliothèques associées pour entraîner des modèles sur des images et fournira des exemples de code correspondants. Préparation de l'environnement : Avant de commencer, vous devez vous assurer que vous avez installé
