

Pendant de nombreuses années, nous avons été incapables de comprendre comment l'intelligence artificielle prend des décisions et génère des résultats
Les développeurs de modèles ne peuvent décider que de l'algorithme, des données, et enfin obtenir le résultat du modèle et la partie médiane - comment le Le modèle est basé sur ces algorithmes et les résultats de sortie des données deviennent des « boîtes noires » invisibles.

Il y a donc une blague du genre "la formation de mannequins, c'est comme l'alchimie".
Mais voilà, le modèle boîte noire est enfin interprétable !
L’équipe de recherche d’Anthropic a extrait les caractéristiques interprétables des neurones unitaires les plus élémentaires du réseau neuronal du modèle.

Ce sera une étape historique pour l'humanité dans la découverte de la boîte noire de l'IA.
Anthropique exprimé avec enthousiasme :
« Si nous pouvons comprendre comment fonctionne le réseau neuronal du modèle, nous pouvons alors diagnostiquer les modes de défaillance du modèle, concevoir des correctifs et faire en sorte que le modèle soit adopté en toute sécurité par les entreprises et la société. Cela deviendra une réalité à portée de main ! »
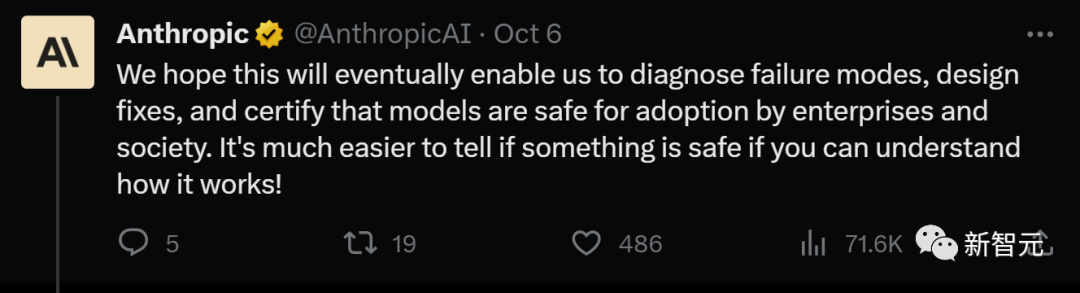
Dans le dernier rapport de recherche d'Anthropic « Vers la monosémanticité : décomposer les modèles linguistiques avec l'apprentissage par dictionnaire », les chercheurs ont utilisé des méthodes d'apprentissage par dictionnaire pour inclure avec succès La couche de 512 neurones est décomposée en plus plus de 4000 fonctionnalités interprétables

Adresse du rapport de recherche : https://transformer-circuits.pub/2023/monosemantic-features/index.html
Ces fonctionnalités représentent des séquences d'ADN, du langage juridique, des requêtes HTTP, Texte en hébreu et déclarations nutritionnelles, etc.
Nous ne pouvons pas voir la plupart de ces propriétés modèles lorsque nous examinons l'activation d'un seul neurone isolément
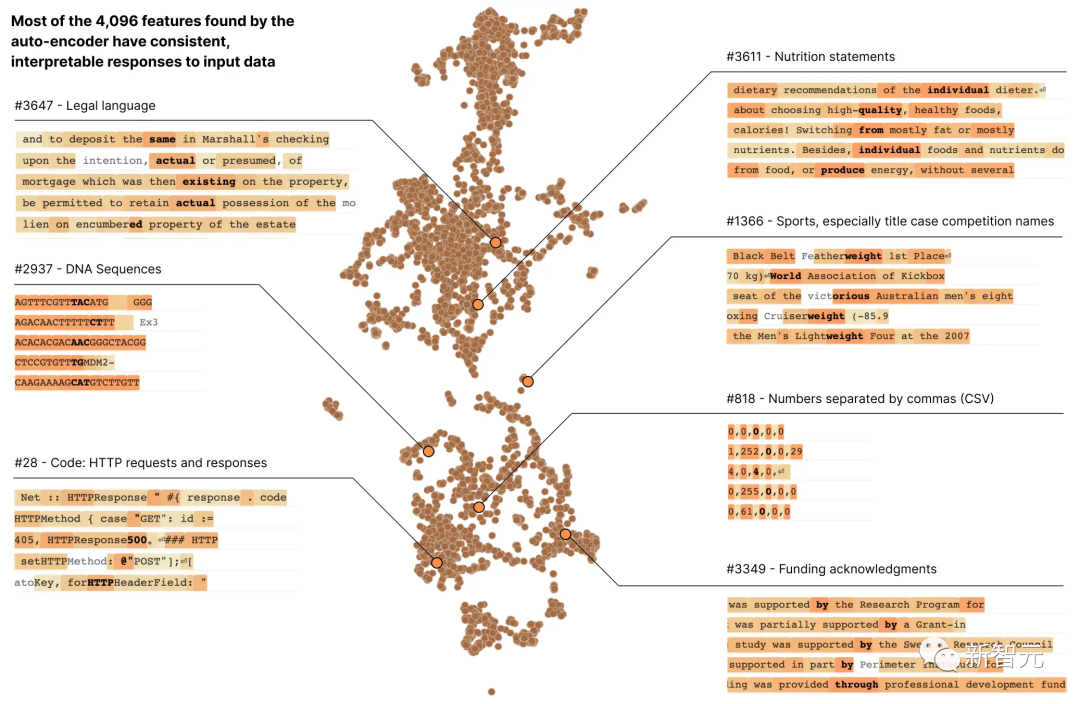
La plupart des neurones sont « polysémantiques », ce qui signifie Il n'y a pas de correspondance cohérente entre les neurones individuels et le comportement du réseau
Par exemple, dans un petit modèle de langage, un seul neurone Meta est actif dans de nombreux contextes non liés, notamment : les citations académiques, les conversations en anglais, les requêtes HTTP et le texte coréen.
Et dans le modèle de vision classique, un seul neurone répond au visage d'un chat et à l'avant d'une voiture.
Dans différents contextes, de nombreuses études ont prouvé que l'activation d'un neurone peut avoir différentes significations
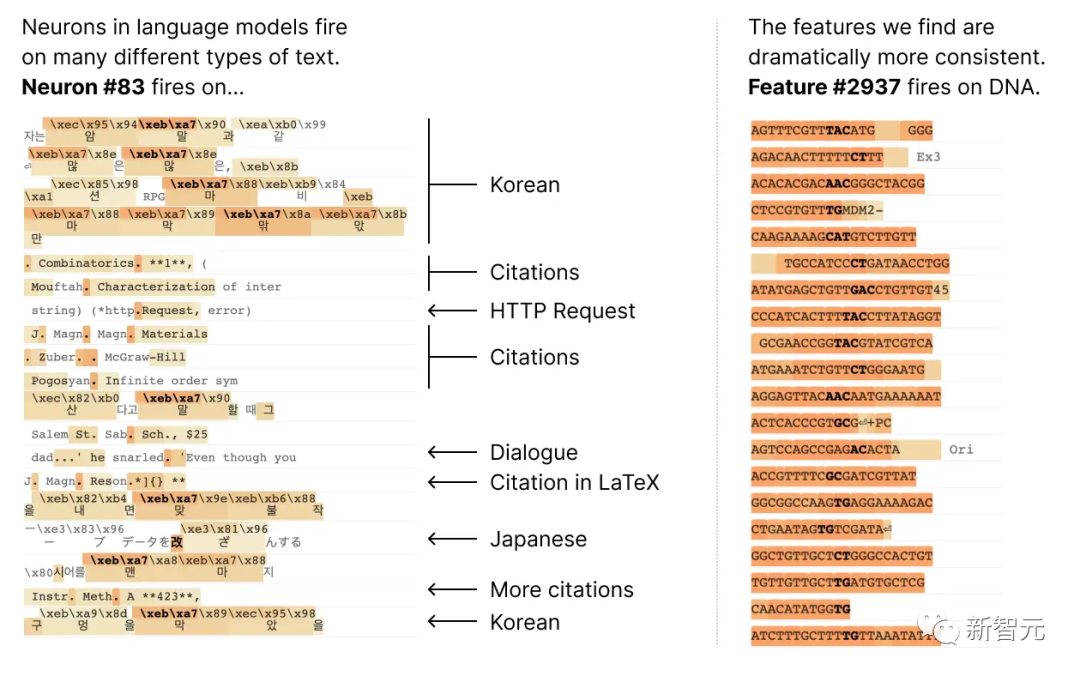
Une raison potentielle est que la nature polysémantique des neurones est due à l'effet de superposition. Il s'agit d'un phénomène hypothétique selon lequel les réseaux de neurones représentent des caractéristiques indépendantes des données en attribuant à chaque caractéristique sa propre combinaison linéaire de neurones, et le nombre de ces caractéristiques dépasse le nombre de neurones
Si chaque caractéristique est Si la caractéristique est considérée comme une vecteur sur le neurone, alors l'ensemble de fonctionnalités forme une base linéaire surcomplète pour l'activation des neurones du réseau.
Dans le précédent article d'Anthropic sur les modèles de superposition de jouets ("Superposition Toy Model"), il a été prouvé que la parcimonie peut éliminer l'ambiguïté dans la formation du réseau neuronal, aidant le modèle à mieux comprendre la relation entre les caractéristiques, réduisant ainsi l'activation. Les caractéristiques sources du vecteur rendent les prédictions et les décisions du modèle plus fiables.
Ce concept est similaire à l'idée de la détection compressée, où la rareté du signal permet de restaurer le signal complet à partir d'observations limitées.

Mais parmi les trois stratégies proposées dans Toy Models of Superposition :
(1) créer des modèles sans superposition, encourageant peut-être la parcimonie d'activation
(2) montrer la superposition Dans le modèle d'état, l'apprentissage du dictionnaire ; est utilisé pour trouver des fonctionnalités sur-complètes
(3) repose sur une méthode hybride qui combine les deux.
Ce qui doit être réécrit est : la méthode (1) ne peut pas résoudre le problème d'ambiguïté, tandis que la méthode (2) est sujette à un surapprentissage sévère
Par conséquent, cette fois, les chercheurs d'Anthropic ont utilisé un algorithme d'apprentissage de dictionnaire faible appelé un clairsemé L'auto-encodeur génère des fonctionnalités apprises à partir d'un modèle entraîné qui fournissent une seule unité d'analyse sémantique que les neurones modèles eux-mêmes.
Plus précisément, les chercheurs ont adopté un transformateur monocouche MLP avec 512 neurones et ont finalement décomposé les activations MLP en activations relativement interprétables en entraînant un auto-encodeur clairsemé sur les activations MLP à partir de 8 milliards de caractéristiques de points de données, le facteur d'expansion varie de 1. × (512 fonctionnalités) à 256 × (131 072 fonctionnalités).
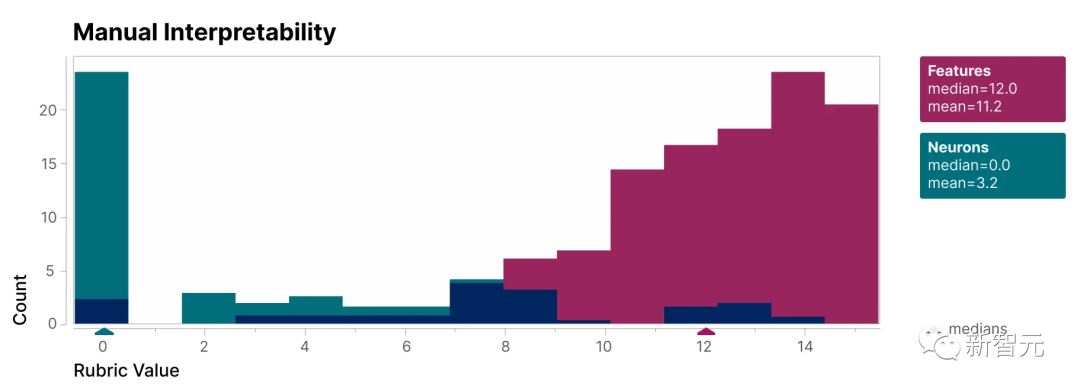
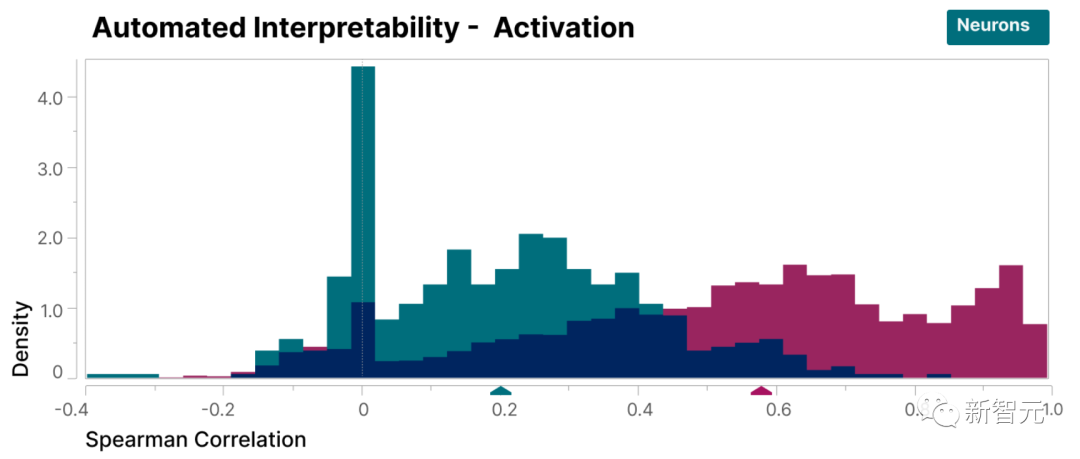
Pour vérifier que les caractéristiques trouvées dans cette étude sont plus interprétables que les neurones du modèle, nous avons effectué une évaluation à l'aveugle et avons demandé à un évaluateur humain d'évaluer leur interprétabilité
peut être vu, les caractéristiques (rouges) ont beaucoup plus élevé scores que les neurones (cyan).
Il a été prouvé que les caractéristiques découvertes par les chercheurs sont plus faciles à comprendre par rapport aux neurones à l'intérieur du modèle
De plus, les chercheurs ont également adopté une méthode « d'interprétabilité automatique » en utilisant le grand Le modèle de langage génère une brève description des fonctionnalités du petit modèle et permet à un autre modèle d'évaluer cette description en fonction de sa capacité à prédire l'activation des fonctionnalités.
De même, les fonctionnalités obtiennent des scores plus élevés que les neurones, démontrant une interprétation cohérente de l'activation des fonctionnalités et de leurs effets en aval sur le comportement du modèle.
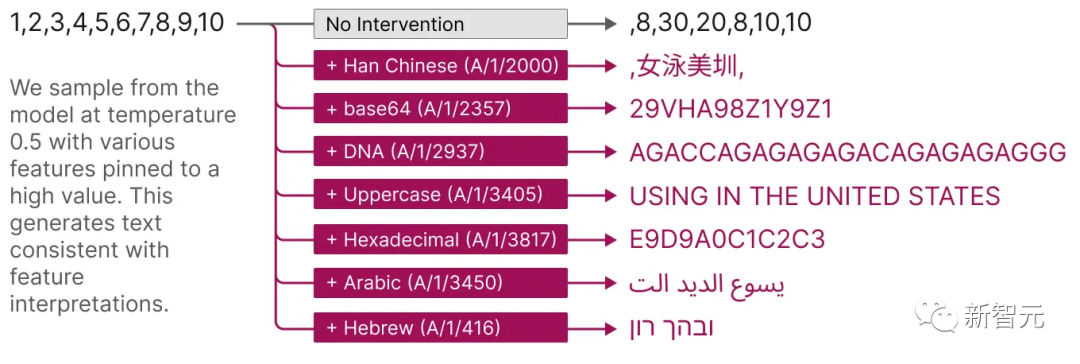
De plus, ces fonctionnalités extraites fournissent également une méthode ciblée pour guider le modèle.
Comme le montre la figure ci-dessous, l'activation artificielle de fonctionnalités peut entraîner une modification prévisible du comportement du modèle.
Ce qui suit est une visualisation des fonctionnalités d'interprétabilité extraites :
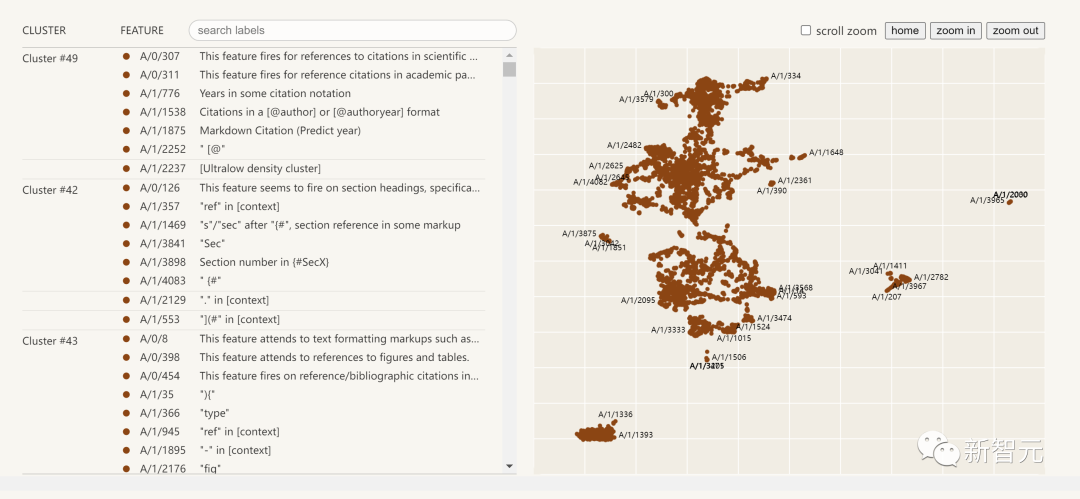
Cliquez sur la liste des fonctionnalités à gauche et vous pourrez explorer de manière interactive l'espace des fonctionnalités dans le réseau neuronal
Ce rapport de recherche d'Anthropic, Towards Monosémanticity: Decomposing Language Models With Dictionary Learning, peut être divisé en quatre parties.
Résultats du problème, les chercheurs ont présenté la motivation de la recherche et développé le transformateur formé et l'auto-encodeur clairsemé.
Enquête détaillée sur des caractéristiques individuelles, prouvant que plusieurs caractéristiques trouvées dans l'étude sont des unités causales fonctionnellement spécifiques.
Grâce à une analyse globale, nous avons conclu que les caractéristiques typiques sont interprétables et qu'elles sont capables d'expliquer des composants importants de la couche MLP
Analyse des phénomènes, décrivant plusieurs propriétés des caractéristiques, notamment la segmentation des caractéristiques, les propriétés d'universalité et comment ils forment des systèmes similaires à des « automates à états finis » pour réaliser des comportements complexes.
Les conclusions incluent les 7 suivantes :
L'auto-encodeur clairsemé a la capacité d'extraire des caractéristiques sémantiques relativement uniques
Les auto-encodeurs clairsemés sont capables de générer des caractéristiques interprétables qui sont réellement invisibles dans la base des neurones
3. Les auto-encodeurs clairsemés peuvent être utilisés pour intervenir et guider la génération de transformateurs.
4. Les auto-encodeurs clairsemés peuvent générer des fonctionnalités relativement générales.
À mesure que la taille de l'encodeur automatique augmente, les fonctionnalités ont tendance à se « diviser ». Après réécriture : à mesure que la taille de l'auto-encodeur augmente, les fonctionnalités montrent une tendance au « fractionnement »
6 Seuls 512 neurones peuvent représenter des milliers de fonctionnalités
7. "L'automate à états finis" réalise des comportements complexes, comme le montre la figure ci-dessous
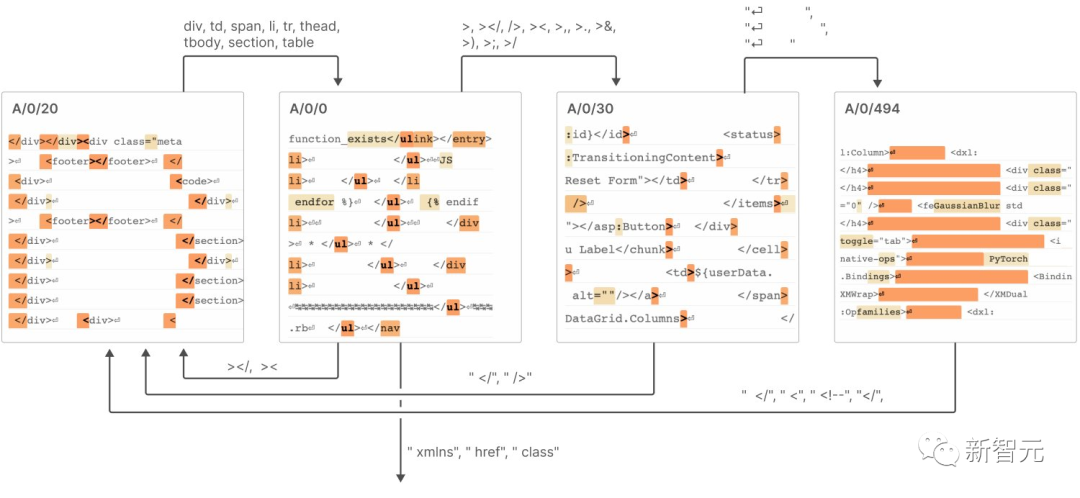
Pour plus de détails, veuillez consulter le rapport.
Anthropic estime que pour reproduire le succès du petit modèle de ce rapport de recherche sur un modèle plus grand, le défi auquel nous serons confrontés à l'avenir ne sera plus un problème scientifique, mais un problème d'ingénierie
Afin de y parvenir sur un grand modèle L'interprétabilité nécessite plus d'efforts et de ressources dans le domaine de l'ingénierie pour surmonter les défis posés par la complexité et l'échelle du modèle
Y compris le développement de nouveaux outils, techniques et méthodes pour faire face aux défis de la complexité du modèle et des données l'échelle ; comprend également la création de cadres et d'outils d'interprétation évolutifs pour répondre aux besoins des modèles à grande échelle.
Cela deviendra la dernière tendance dans le domaine de l'intelligence artificielle interprétative et de la recherche sur l'apprentissage profond à grande échelle
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



