
 Périphériques technologiques
IA
L'impact de la stratégie d'échantillonnage des ensembles de données sur les performances du modèle
Périphériques technologiques
IA
L'impact de la stratégie d'échantillonnage des ensembles de données sur les performances du modèle
L'impact de la stratégie d'échantillonnage des ensembles de données sur les performances du modèle


L'impact de la stratégie d'échantillonnage des ensembles de données sur les performances du modèle nécessite des exemples de code spécifiques
Avec le développement rapide de l'apprentissage automatique et de l'apprentissage profond, l'impact de la qualité et de l'échelle des ensembles de données sur les performances du modèle est devenu de plus en plus important. Dans les applications pratiques, nous sommes souvent confrontés à des problèmes tels qu'une taille excessive d'ensemble de données, des catégories d'échantillons déséquilibrées et du bruit d'échantillon. À l’heure actuelle, un choix raisonnable de stratégie d’échantillonnage peut améliorer les performances et la capacité de généralisation du modèle. Cet article discutera de l'impact de différentes stratégies d'échantillonnage d'ensembles de données sur les performances du modèle à travers des exemples de code spécifiques.
- Échantillonnage aléatoire
L'échantillonnage aléatoire est l'une des stratégies d'échantillonnage d'ensembles de données les plus courantes. Au cours du processus de formation, nous sélectionnons au hasard une certaine proportion d'échantillons de l'ensemble de données comme ensemble de formation. Cette méthode est simple et intuitive, mais elle peut conduire à une répartition déséquilibrée des catégories d'échantillons ou à la perte d'échantillons importants. Voici un exemple de code :
import numpy as np
def random_sampling(X, y, sample_ratio):
num_samples = int(sample_ratio * X.shape[0])
indices = np.random.choice(X.shape[0], num_samples, replace=False)
X_sampled = X[indices]
y_sampled = y[indices]
return X_sampled, y_sampled- Échantillonnage stratifié
L'échantillonnage stratifié est une stratégie courante pour résoudre le problème du déséquilibre des classes d'échantillons. Dans l'échantillonnage stratifié, nous stratifions l'ensemble de données en fonction des catégories d'échantillons et sélectionnons une proportion d'échantillons dans chaque catégorie. Cette méthode peut maintenir la proportion de chaque catégorie dans l'ensemble de données, améliorant ainsi la capacité du modèle à gérer les catégories minoritaires. Voici un exemple de code :
from sklearn.model_selection import train_test_split
from sklearn.utils import resample
def stratified_sampling(X, y, sample_ratio):
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, test_size=1-sample_ratio)
X_sampled, y_sampled = resample(X_train, y_train, n_samples=int(sample_ratio * X.shape[0]))
return X_sampled, y_sampled- Edge sampling
Edge sampling est une stratégie courante pour résoudre le problème du bruit d'échantillonnage. Dans l'échantillonnage de bord, nous divisons les échantillons en échantillons fiables et en échantillons de bruit en apprenant un modèle, puis sélectionnons uniquement des échantillons fiables pour la formation. Voici un exemple de code :
from sklearn.svm import OneClassSVM
def margin_sampling(X, y, sample_ratio):
clf = OneClassSVM(gamma='scale')
clf.fit(X)
y_pred = clf.predict(X)
reliable_samples = X[y_pred == 1]
num_samples = int(sample_ratio * X.shape[0])
indices = np.random.choice(reliable_samples.shape[0], num_samples, replace=False)
X_sampled = reliable_samples[indices]
y_sampled = y[indices]
return X_sampled, y_sampledEn résumé, différentes stratégies d'échantillonnage d'ensembles de données ont des impacts différents sur les performances du modèle. L'échantillonnage aléatoire peut facilement et rapidement obtenir l'ensemble d'apprentissage, mais il peut conduire à des catégories d'échantillons déséquilibrées ; l'échantillonnage stratifié peut maintenir l'équilibre des catégories d'échantillons et améliorer la capacité du modèle à gérer les catégories minoritaires. L'échantillonnage de bord peut filtrer les échantillons bruyants et améliorer la robustesse ; du sexe modèle. Dans les applications pratiques, nous devons choisir une stratégie d'échantillonnage appropriée en fonction de problèmes spécifiques et sélectionner la stratégie optimale par le biais d'expériences et d'évaluations pour améliorer les performances et la capacité de généralisation du modèle.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Classification d'images avec apprentissage en quelques prises de vue à l'aide de PyTorch
Apr 09, 2023 am 10:51 AM
Classification d'images avec apprentissage en quelques prises de vue à l'aide de PyTorch
Apr 09, 2023 am 10:51 AM
Ces dernières années, les modèles basés sur l’apprentissage profond ont donné de bons résultats dans des tâches telles que la détection d’objets et la reconnaissance d’images. Sur des ensembles de données de classification d'images complexes comme ImageNet, qui contient 1 000 classifications d'objets différentes, certains modèles dépassent désormais les niveaux humains. Mais ces modèles s'appuient sur un processus de formation supervisé, ils sont considérablement affectés par la disponibilité de données de formation étiquetées, et les classes que les modèles sont capables de détecter sont limitées aux classes sur lesquelles ils ont été formés. Puisqu’il n’y a pas suffisamment d’images étiquetées pour toutes les classes pendant la formation, ces modèles peuvent être moins utiles dans des contextes réels. Et nous voulons que le modèle soit capable de reconnaître les classes qu'il n'a pas vues lors de l'entraînement, car il est presque impossible de s'entraîner sur des images de tous les objets potentiels. Nous apprendrons de quelques exemples
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 Implémentation d'OpenAI CLIP sur des ensembles de données personnalisés
Sep 14, 2023 am 11:57 AM
Implémentation d'OpenAI CLIP sur des ensembles de données personnalisés
Sep 14, 2023 am 11:57 AM
En janvier 2021, OpenAI a annoncé deux nouveaux modèles : DALL-E et CLIP. Les deux modèles sont des modèles multimodaux qui relient le texte et les images d’une manière ou d’une autre. Le nom complet de CLIP est Contrastive Language-Image Pre-training (ContrastiveLanguage-ImagePre-training), qui est une méthode de pré-formation basée sur des paires texte-image contrastées. Pourquoi introduire CLIP ? Parce que le StableDiffusion actuellement populaire n'est pas un modèle unique, mais se compose de plusieurs modèles. L'un des composants clés est l'encodeur de texte, qui est utilisé pour encoder la saisie de texte de l'utilisateur. Cet encodeur de texte est l'encodeur de texte CL dans le modèle CLIP.
 La vidéo Google AI est à nouveau géniale ! VideoPrism, un encodeur visuel universel tout-en-un, actualise 30 fonctionnalités de performances SOTA
Feb 26, 2024 am 09:58 AM
La vidéo Google AI est à nouveau géniale ! VideoPrism, un encodeur visuel universel tout-en-un, actualise 30 fonctionnalités de performances SOTA
Feb 26, 2024 am 09:58 AM
Après que le modèle vidéo d'IA Sora soit devenu populaire, de grandes entreprises telles que Meta et Google se sont retirées pour faire des recherches et rattraper OpenAI. Récemment, des chercheurs de l'équipe Google ont proposé un encodeur vidéo universel - VideoPrism. Il peut gérer diverses tâches de compréhension vidéo via un seul modèle figé. Adresse du papier image : https://arxiv.org/pdf/2402.13217.pdf Par exemple, VideoPrism peut classer et localiser la personne qui souffle les bougies dans la vidéo ci-dessous. Récupération d'image vidéo-texte, sur la base du contenu du texte, le contenu correspondant dans la vidéo peut être récupéré. Pour un autre exemple, décrivez la vidéo ci-dessous : une petite fille joue avec des blocs de construction. Des questions et réponses sur l’assurance qualité sont également disponibles.
 Comment diviser correctement un ensemble de données ? Résumé de trois méthodes courantes
Apr 08, 2023 pm 06:51 PM
Comment diviser correctement un ensemble de données ? Résumé de trois méthodes courantes
Apr 08, 2023 pm 06:51 PM
La décomposition de l'ensemble de données en un ensemble d'apprentissage nous aide à comprendre le modèle, ce qui est important pour la façon dont le modèle se généralise à de nouvelles données invisibles. Un modèle peut ne pas se généraliser correctement à de nouvelles données invisibles s'il est surajusté. Il n’est donc pas possible de faire de bonnes prédictions. Avoir une stratégie de validation appropriée est la première étape pour réussir à créer de bonnes prédictions et à utiliser la valeur commerciale des modèles d'IA. Cet article a compilé quelques stratégies courantes de fractionnement des données. Une simple répartition de l'entraînement et des tests divise l'ensemble de données en parties de formation et de validation, avec 80 % de formation et 20 % de validation. Vous pouvez le faire en utilisant l'échantillonnage aléatoire de Scikit. Tout d’abord, la graine aléatoire doit être corrigée, sinon la même répartition des données ne pourra pas être comparée et les résultats ne pourront pas être reproduits pendant le débogage. Si l'ensemble de données
 Exemple de code complet de formation parallèle PyTorch DistributedDataParallel
Apr 10, 2023 pm 08:51 PM
Exemple de code complet de formation parallèle PyTorch DistributedDataParallel
Apr 10, 2023 pm 08:51 PM
Le problème de la formation de grands réseaux de neurones profonds (DNN) à l’aide de grands ensembles de données constitue un défi majeur dans le domaine de l’apprentissage profond. À mesure que la taille des DNN et des ensembles de données augmente, les besoins en calcul et en mémoire pour la formation de ces modèles augmentent également. Cela rend difficile, voire impossible, la formation de ces modèles sur une seule machine avec des ressources informatiques limitées. Certains des défis majeurs liés à la formation de grands DNN à l'aide de grands ensembles de données comprennent : Longue durée de formation : le processus de formation peut prendre des semaines, voire des mois, en fonction de la complexité du modèle et de la taille de l'ensemble de données. Limites de mémoire : les DNN volumineux peuvent nécessiter de grandes quantités de mémoire pour stocker tous les paramètres du modèle, les gradients et les activations intermédiaires pendant l'entraînement. Cela peut provoquer des erreurs de mémoire insuffisante et limiter ce qui peut être entraîné sur une seule machine.
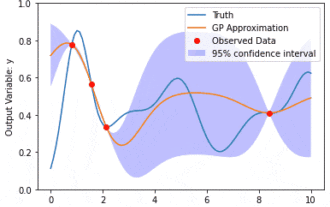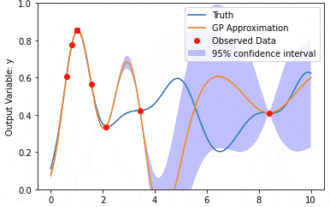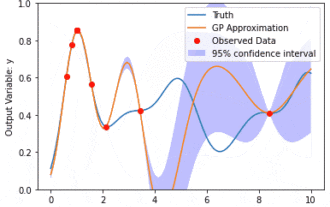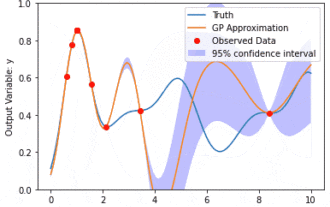 Modélisation des données à l'aide des processus gaussiens du modèle de noyau (KMGP)
Jan 30, 2024 am 11:15 AM
Modélisation des données à l'aide des processus gaussiens du modèle de noyau (KMGP)
Jan 30, 2024 am 11:15 AM
Les processus gaussiens du modèle de noyau (KMGP) sont des outils sophistiqués permettant de gérer la complexité de divers ensembles de données. Il étend le concept des processus gaussiens traditionnels à travers les fonctions du noyau. Cet article discutera en détail de la base théorique, des applications pratiques et des défis des KMGP. Le processus gaussien du modèle de noyau est une extension du processus gaussien traditionnel et est utilisé dans l'apprentissage automatique et les statistiques. Avant de comprendre kmgp, vous devez maîtriser les connaissances de base du processus gaussien, puis comprendre le rôle du modèle de noyau. Processus gaussiens (GP) Les processus gaussiens sont des ensembles de variables aléatoires, avec un nombre fini de variables distribuées conjointement par la distribution gaussienne, et sont utilisés pour définir des distributions de probabilité de fonctions. Les processus gaussiens sont couramment utilisés dans les tâches de régression et de classification en apprentissage automatique et peuvent être utilisés pour ajuster la distribution de probabilité des données. Une caractéristique importante des processus gaussiens est leur capacité à fournir des estimations et des prévisions d'incertitude.
 Calculer le coût carbone de l'intelligence artificielle
Apr 12, 2023 am 08:52 AM
Calculer le coût carbone de l'intelligence artificielle
Apr 12, 2023 am 08:52 AM
Si vous recherchez des sujets intéressants, l’Intelligence Artificielle (IA) ne vous décevra pas. L'intelligence artificielle englobe un ensemble d'algorithmes statistiques puissants et époustouflants qui peuvent jouer aux échecs, déchiffrer une écriture manuscrite bâclée, comprendre la parole, classer des images satellite, et bien plus encore. La disponibilité d’ensembles de données géants pour la formation de modèles d’apprentissage automatique a été l’un des facteurs clés du succès de l’intelligence artificielle. Mais tout ce travail informatique n’est pas gratuit. Certains experts en IA sont de plus en plus préoccupés par les impacts environnementaux associés à la création de nouveaux algorithmes, un débat qui a suscité de nouvelles idées sur la manière de permettre aux machines d'apprendre plus efficacement afin de réduire l'empreinte carbone de l'IA. De retour sur Terre Pour entrer dans les détails, il faut d'abord considérer les milliers de centres de données (disséminés dans le monde) qui traitent nos demandes informatiques 24h/24 et 7j/7.
